") 詳解神經(jīng)網(wǎng)絡(luò)嵌入的概念
詳解神經(jīng)網(wǎng)絡(luò)嵌入的概念
深度學(xué)習(xí)的一個(gè)顯著成功應(yīng)用是嵌入,這是一種將離散變量表示為連續(xù)向量的方法。這項(xiàng)技術(shù)已經(jīng)有了實(shí)際的應(yīng)用,其中有在機(jī)器翻譯中使用詞嵌入和類別變量中使用實(shí)體嵌入。
近年來,神經(jīng)網(wǎng)絡(luò)在圖像分割、自然語言處理、時(shí)間序列預(yù)測等方面的應(yīng)用有了很大的發(fā)展。深度學(xué)習(xí)的一個(gè)顯著成功應(yīng)用是嵌入,這是一種將離散變量表示為連續(xù)向量的方法。這項(xiàng)技術(shù)已經(jīng)有了實(shí)際的應(yīng)用,其中有在機(jī)器翻譯中使用詞嵌入和類別變量中使用實(shí)體嵌。
在本文中,我將解釋什么是神經(jīng)網(wǎng)絡(luò)嵌入,為什么要使用它們,以及如何學(xué)習(xí)它們。我們會(huì)在真正的問題的上下文中討論這些概念:將Wikipedia上的所有圖書表示為向量,并創(chuàng)建圖書推薦系統(tǒng)。
Wikipedia上所有書的神經(jīng)網(wǎng)絡(luò)嵌入
嵌入
嵌入是一個(gè)從離散變量到連續(xù)數(shù)字向量的映射。在神經(jīng)網(wǎng)絡(luò)的上下文中,embeddings是低維的, 離散變量用學(xué)習(xí)到的連續(xù)向量表示。神經(jīng)網(wǎng)絡(luò)嵌入是有用的,因?yàn)樗鼈兛梢詼p少類別變量的維數(shù),并有意義地在轉(zhuǎn)換空間中表示類別。
神經(jīng)網(wǎng)絡(luò)嵌入有3個(gè)主要目的:
① 在嵌入空間中查找最近的鄰居。這些鄰居可以用于根據(jù)用戶興趣或聚類類別提出建議。
② 作為監(jiān)督任務(wù)的機(jī)器學(xué)習(xí)模型的輸入。
③ 用于概念的可視化和類別之間的關(guān)系的可視化。
這意味著在圖書項(xiàng)目中,使用神經(jīng)網(wǎng)絡(luò)嵌入,我們可以把維基百科上所有的37000篇圖書文章,用一個(gè)具有50個(gè)數(shù)字的向量來表示每一篇文章。此外,由于嵌入式是學(xué)習(xí)的,在我們的學(xué)習(xí)問題上下文中更相似的書籍在嵌入式空間中更接近。
神經(jīng)網(wǎng)絡(luò)嵌入克服了用獨(dú)熱編碼表示分類變量的兩個(gè)局限性:
獨(dú)熱編碼的局限性
獨(dú)熱編碼類別變量的操作實(shí)際上是一個(gè)簡單的嵌入,其中每個(gè)類別都映射到一個(gè)不同的向量。這個(gè)過程采用離散實(shí)體,并將每個(gè)觀察結(jié)果映射到一個(gè)只有一個(gè)1的向量中。
獨(dú)熱編碼技術(shù)有兩個(gè)主要缺點(diǎn):
① 對于高基數(shù)變量—那些具有許多類別的變量—轉(zhuǎn)換之后向量的維數(shù)變得太大了。
② 這種映射是完全沒有監(jiān)督的:“相似”的類別在嵌入空間中并沒有彼此放置得更靠近。
第一個(gè)問題很好理解:對于每個(gè)額外的類別(稱為實(shí)體),我們必須向一個(gè)熱編碼向量添加另一個(gè)數(shù)字。如果我們在Wikipedia上有37000本書,那么表示這些書需要為每本書提供37000維的向量,這使得針對這種表示的任何機(jī)器學(xué)習(xí)模型的訓(xùn)練都是不可行的。
第二個(gè)問題同樣是有局限的:獨(dú)熱編碼不會(huì)將相似的實(shí)體彼此靠近的放在向量空間中。如果我們使用余弦距離來度量向量之間的相似性,那么經(jīng)過獨(dú)熱編碼后,實(shí)體之間的相似性為0。
這意味著,《戰(zhàn)爭與和平》和《安娜?卡列尼娜》(這兩本書都是列夫?托爾斯泰(Leo Tolstoy)的經(jīng)典著作)這樣的實(shí)體彼此之間的距離,并不比《戰(zhàn)爭與和平》與《銀河系漫游指南》之間的距離更近。
# One Hot Encoding Categoricals
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded = [[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
Similarity (dot product) between First and Second = 0
Similarity (dot product) between Second and Third = 0
Similarity (dot product) between First and Third = 0
考慮到這兩個(gè)問題,表示類別變量的理想解決方案是需要更少的數(shù)字,而不是類別的數(shù)量,并且將類似的類別放在更靠近的位置。
# Idealized Representation of Embedding
books = ["War and Peace", "Anna Karenina",
"The Hitchhiker's Guide to the Galaxy"]
books_encoded_ideal = [[0.53, 0.85],
[0.60, 0.80],
[-0.78, -0.62]]
Similarity (dot product) between First and Second = 0.99
Similarity (dot product) between Second and Third = -0.94
Similarity (dot product) between First and Third = -0.97
為了更好地表示類別實(shí)體,我們可以使用嵌入神經(jīng)網(wǎng)絡(luò)和監(jiān)督任務(wù)來學(xué)習(xí)嵌入。
學(xué)習(xí)嵌入
使用one-hot編碼的主要問題是轉(zhuǎn)換不依賴于任何監(jiān)督。我們可以通過在有監(jiān)督的任務(wù)中使用神經(jīng)網(wǎng)絡(luò)來學(xué)習(xí)嵌入,從而大大改進(jìn)嵌入。嵌入形成參數(shù)—網(wǎng)絡(luò)的權(quán)重—經(jīng)過調(diào)整以最小化任務(wù)上的損失。得到的嵌入向量表示類別,其中相似的類別(相對于任務(wù))彼此更接近。
例如,如果我們有一個(gè)包含50,000個(gè)單詞的電影評論集合,我們可以使用一個(gè)訓(xùn)練好的嵌入式神經(jīng)網(wǎng)絡(luò)來預(yù)測評論是的情感,從而為每個(gè)單詞學(xué)習(xí)100維的嵌入。詞匯表中與正面評價(jià)相關(guān)的單詞,如“brilliant”或“excellent”,將在嵌入空間中出現(xiàn)得更近,因?yàn)榫W(wǎng)絡(luò)已經(jīng)了解到它們都與正面評價(jià)相關(guān)。
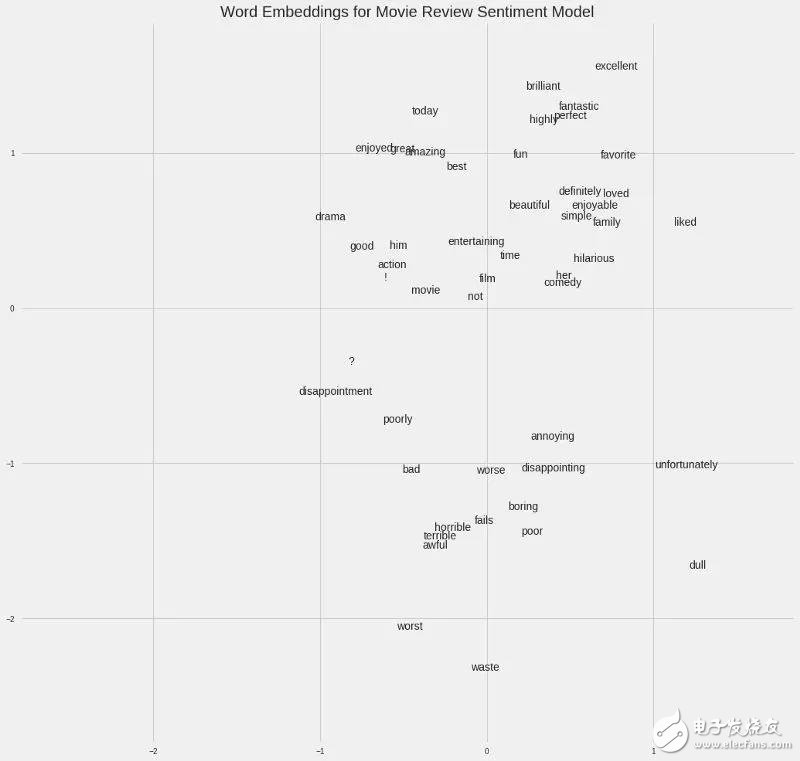
電影句子中的詞嵌入
在上面給出的書的例子中,我們的監(jiān)督任務(wù)可以是“確定一本書是否是列夫·托爾斯泰寫的”,由此產(chǎn)生的嵌入將使托爾斯泰寫的書彼此更接近。解決如何創(chuàng)建監(jiān)督任務(wù)來生成相關(guān)表示的問題是嵌入過程中最困難的部分。
實(shí)現(xiàn)
在Wikipedia book項(xiàng)目中,監(jiān)督學(xué)習(xí)任務(wù)被設(shè)置為預(yù)測一本書的文章中是否出現(xiàn)了指向Wikipedia頁面的給定鏈接。我們提供成對的(書名、鏈接)訓(xùn)練示例,其中混合了正樣本對和負(fù)樣本對。這種設(shè)置基于這樣的假設(shè),即鏈接到類似Wikipedia頁面的書籍彼此相似。因此,由此產(chǎn)生的嵌入應(yīng)該將類似的書籍更緊密地放置在向量空間中。
我使用的網(wǎng)絡(luò)有兩個(gè)平行的嵌入層,分別映射書和wikilink,用來區(qū)分50維向量,還有一個(gè)點(diǎn)積層,將嵌入的內(nèi)容組合成一個(gè)數(shù)字,用于預(yù)測。嵌入是網(wǎng)絡(luò)的參數(shù)或權(quán)重,在訓(xùn)練過程中進(jìn)行調(diào)整,以最小化監(jiān)督任務(wù)的損失。
在Keras代碼中,這看起來像這樣(如果你不完全理解代碼,不要擔(dān)心,直接跳到圖像):
# Both inputs are 1-dimensional
book = Input(name = 'book', shape = [1])
link = Input(name = 'link', shape = [1])
# Embedding the book (shape will be (None, 1, 50))
book_embedding = Embedding(name = 'book_embedding',
input_dim = len(book_index),
output_dim = embedding_size)(book)
# Embedding the link (shape will be (None, 1, 50))
link_embedding = Embedding(name = 'link_embedding',
input_dim = len(link_index),
output_dim = embedding_size)(link)
# Merge the layers with a dot product along the second axis (shape will be (None, 1, 1))
merged = Dot(name = 'dot_product', normalize = True, axes = 2)([book_embedding, link_embedding])
# Reshape to be a single number (shape will be (None, 1))
merged = Reshape(target_shape = [1])(merged)
# Output neuron
out = Dense(1, activation = 'sigmoid')(merged)
model = Model(inputs = [book, link], outputs = out)
# Minimize binary cross entropy
model.compile(optimizer = 'Adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
雖然在有監(jiān)督的機(jī)器學(xué)習(xí)任務(wù)中,目標(biāo)通常是訓(xùn)練一個(gè)模型對新數(shù)據(jù)進(jìn)行預(yù)測,但在這個(gè)嵌入模型中,預(yù)測只是達(dá)到目的的一種手段。我們想要的是嵌入權(quán)值,將書籍和鏈接表示為連續(xù)向量。
嵌入本身并不那么有趣,它們只是數(shù)字的向量:

來自書籍推薦嵌入模型的示例嵌入
然而,嵌入可以用于前面列出的3個(gè)目的,對于這個(gè)項(xiàng)目,我們主要感興趣的是推薦基于最近鄰的書籍。為了計(jì)算相似性,我們?nèi)∫槐緯M(jìn)行查詢,找到它的向量與其他所有圖書向量的點(diǎn)積。(如果我們的嵌入是標(biāo)準(zhǔn)化的,那么這個(gè)點(diǎn)積就是向量之間的cos距離,范圍從-1(最不相似)到+1(最相似)。我們也可以用歐氏距離來度量相似性。
這是我建立的圖書嵌入模型的輸出:
Books closest to War and Peace.
Book: War and Peace Similarity: 1.0
Book: Anna Karenina Similarity: 0.79
Book: The Master and Margarita Similarity: 0.77
Book: Doctor Zhivago (novel) Similarity: 0.76
Book: Dead Souls Similarity: 0.75
(向量與自身的余弦相似度必須為1.0)。經(jīng)過降維(見下圖),可以得到如下圖:
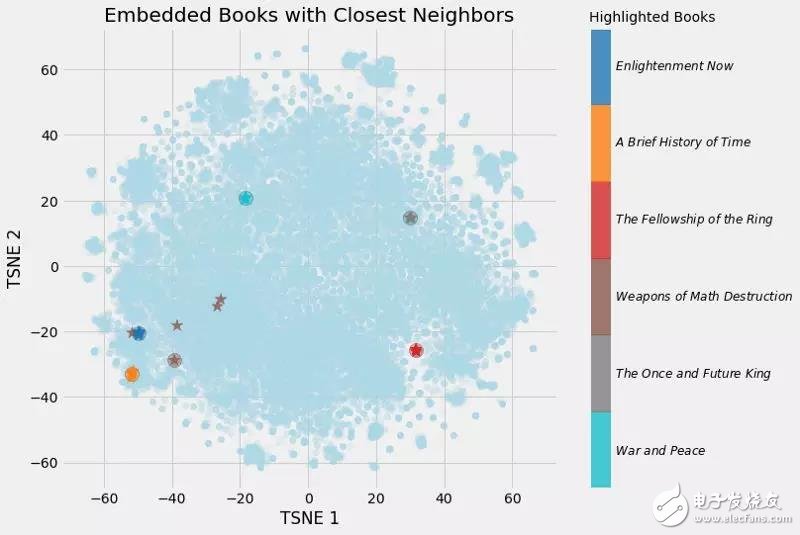
書的嵌入以及最近的鄰居
我們可以清楚地看到學(xué)習(xí)嵌入的價(jià)值!現(xiàn)在,維基百科上每一本書都有一個(gè)50個(gè)數(shù)字的向量表示,相似的書彼此之間距離更近。
嵌入可視化
嵌入的最酷的部分之一是,它們可以用來可視化概念,例如“小說”或“非小說”之間的關(guān)系。這需要進(jìn)一步的降維技術(shù)來將維度降為2或3。最常用的約簡方法本身就是一種嵌入方法:t分布隨機(jī)鄰接嵌入(TSNE)。
我們可以把維基百科上所有書籍的37000個(gè)原始維度,用神經(jīng)網(wǎng)絡(luò)嵌入將它們映射到50個(gè)維度,然后用TSNE將它們映射到2個(gè)維度。結(jié)果如下:
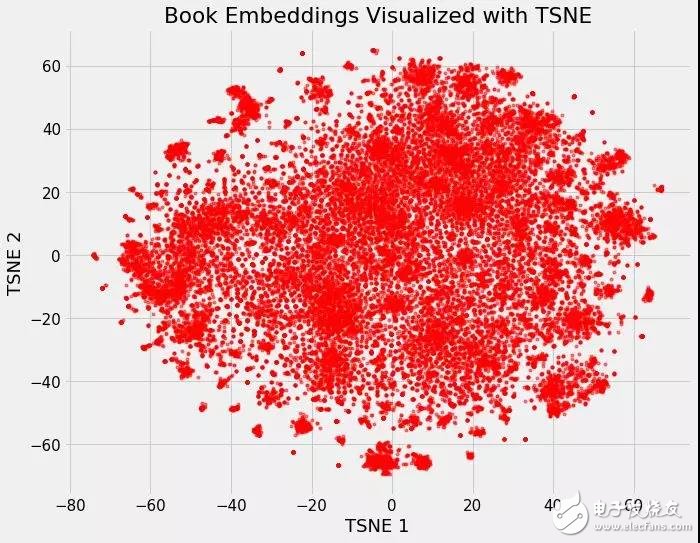
在Wikipedia上的所有37000本書的嵌入
(TSNE是一種流形學(xué)習(xí)技術(shù),這意味著它試圖將高維數(shù)據(jù)映射到低維流形,創(chuàng)建一個(gè)試圖維護(hù)數(shù)據(jù)內(nèi)部局部結(jié)構(gòu)的嵌入。它幾乎只用于可視化,因?yàn)檩敵鍪请S機(jī)的,不支持轉(zhuǎn)換新數(shù)據(jù)。一個(gè)正在興起的替代方案是統(tǒng)一流形近似和投影,UMAP,它更快,并且支持將新數(shù)據(jù)轉(zhuǎn)換到嵌入空間中)。
這本身并不是很有用,但是一旦我們開始根據(jù)不同的書的特點(diǎn)給它上色,它就會(huì)變得很有洞察力。
用流派對嵌入上色
我們可以清楚地看到屬于同一類型的書籍的分組。這并不完美,但仍然令人印象深刻的是,我們可以用兩個(gè)數(shù)字來表示維基百科上的所有書籍,這兩個(gè)數(shù)字仍然能夠捕捉到不同類型之間的差異。
書的例子(即將發(fā)表的完整文章)展示了神經(jīng)網(wǎng)絡(luò)嵌入的價(jià)值:我們有一個(gè)類別對象的向量表示,它是低維的,并且在嵌入空間中將相似的實(shí)體彼此放置得更近。
交互式可視化
靜態(tài)圖的問題是,我們不能真正地研究數(shù)據(jù)并研究變量之間的分組或關(guān)系。為了解決這個(gè)問題,TensorFlow開發(fā)了projector,這是一個(gè)在線應(yīng)用程序,可以讓我們可視化并與嵌入進(jìn)行交互。我將很快發(fā)布一篇關(guān)于如何使用這個(gè)工具的文章,但是現(xiàn)在,結(jié)果如下:
使用projector交互式探索書籍嵌入
結(jié)論
神經(jīng)網(wǎng)絡(luò)嵌入是學(xué)習(xí)離散數(shù)據(jù)作為連續(xù)向量的低維表示。這些嵌入克服了傳統(tǒng)編碼方法的限制,可以用于查找最近的鄰居、輸入到另一個(gè)模型和可視化。
雖然很多深度學(xué)習(xí)的概念都是在學(xué)術(shù)術(shù)語中討論的,但是神經(jīng)網(wǎng)絡(luò)嵌入既直觀又相對容易實(shí)現(xiàn)。我堅(jiān)信任何人都可以學(xué)習(xí)深度學(xué)習(xí)并使用Keras這樣的庫構(gòu)建深度學(xué)習(xí)解決方案。嵌入是處理離散變量的有效工具,是深度學(xué)習(xí)的一個(gè)有用應(yīng)用。
-
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4777瀏覽量
100973 -
深度學(xué)習(xí)
+關(guān)注
關(guān)注
73文章
5511瀏覽量
121353
發(fā)布評論請先 登錄
相關(guān)推薦
【PYNQ-Z2試用體驗(yàn)】神經(jīng)網(wǎng)絡(luò)基礎(chǔ)知識(shí)
卷積神經(jīng)網(wǎng)絡(luò)如何使用
【案例分享】ART神經(jīng)網(wǎng)絡(luò)與SOM神經(jīng)網(wǎng)絡(luò)
如何構(gòu)建神經(jīng)網(wǎng)絡(luò)?
輕量化神經(jīng)網(wǎng)絡(luò)的相關(guān)資料下載
卷積神經(jīng)網(wǎng)絡(luò)一維卷積的處理過程
人工神經(jīng)網(wǎng)絡(luò)基礎(chǔ)描述詳解
從概念到結(jié)構(gòu)、算法解析卷積神經(jīng)網(wǎng)絡(luò)
什么是模糊神經(jīng)網(wǎng)絡(luò)_模糊神經(jīng)網(wǎng)絡(luò)原理詳解





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論