

近日,眾多全球頂級機器人學研究人員帶著他們的前沿成果,亮相ICRA 2019。麻省理工學院、紐約大學和賓夕法尼亞大學等NVAIL(NVIDIA AI實驗室)合作伙伴也參與其中,展示其各自的研究成果——基于NVIDIA平臺進行實時推理。
麻省理工學院——變分端到端導航和本地化
作者稱,這篇論文靈感來自于人類駕駛員所具有的三個主要特征:(1)在陌生路況中的駕駛能力;(2)在環境中本地化的能力;以及(3)當所感知的內容與地圖所示不一致時的推理能力。
人類可以從地圖中了解潛在的道路拓撲,并通過基于環境信息的視覺輸入來定位。因此,當人們的視覺感知與從定位傳感器觀察到的信息不一致時,人們可以做出決策。
受人類能力的啟發,作者著手開發一種深度學習系統,使自動駕駛汽車能夠學習如何使用端到端自動駕駛系統來導航信息。導航信息采用路由和未路由地圖的形式,與原始傳感數據一起使用,以便在復雜的駕駛環境中進行導航和定位,如下圖所示:
該算法從前方、右方和左方的三個攝像頭拍攝到的圖像,以及無路由的地圖圖像中獲取輸入補丁。這些圖像被反饋到并行卷積管道,然后合并成完全連接的層,因此該層用于學習高斯混合模型(GMM)而不是轉向控制。當可用時,路由地圖被反饋到單獨的卷積管道中,并與中間完全連接的層合并,以學習用于導航的確定性控制信號。
作者表示,他們的算法能夠在不同復雜程度的環境中輸出控制,包括直線道路行駛、交叉口以及環形交叉口。該算法被證明可以在車輛遇到未經訓練的新道路和交叉路口時發揮作用。
作者還表明,基于GMM的概率控制輸出可用于定位車輛,從而減少姿勢不確定性并增加其定位置信度。他們首先利用從GPS中獲得的姿勢進行計算,然后基于該計算結果以及額外的不確定性,計算該姿勢的后驗概率。根據作者得出結論,如果后驗分布的不確定性低于先前分布中的不確定性,則該模型能夠增加其定位的置信度。這種預測姿勢和降低不確定性的能力,讓車輛即使在完全失去GPS信號的情況下也能獲得更精確的定位。
該算法在NVIDIA V100 GPU上進行訓練,訓練一個模型需要3小時。推理則是在安裝于配備了線控驅動功能的Toyota Prius中的DRIVE PX2上實時進行的。算法在ROS中實現,并利用NVIDIA DriveWorks SDK與車輛傳感器連接。
未來,作者計劃以多種方式推動自主化的界限。示例包括讓車輛行駛在更多未經明確訓練的情況下,理解傳感器或模型何時失效,以及發現人何時應該幫助或接管控制。
麻省理工學院是ICRA 2019年度最佳會議論文獎的三名候選人之一。有關本文的概述,您可以查看此視頻。
紐約大學——用于自動駕駛高效推理的可重構網絡
由于配備大量傳感器,自動駕駛車輛會收集到海量的數據,處理這些數據需要大量的計算并訓練一個大型網絡。為了應對這一挑戰,作者引入了一個可重構網絡,可以在線預測,在既定的時間內,哪個傳感器會提供最相關的數據。這種方法依賴于直覺,即在特定時刻只收集一小部分具有相關性的數據。
可重構網絡包括門控網絡,該門控網絡基于將學習劃分為子任務的概念,每個子任務由一位專家(expert)執行。門控網絡決定在給定時間點使用哪個專家,這意味著算法將決定使用哪個傳感器收集數據。進而,門控網絡為避免大量計算成本提供了一種方法。
作者分三個步驟訓練可重構網絡。首先,專家組件被訓練為傳感器融合網絡,門控網絡把它們作為特征提取器,用于選擇最相關傳感器。其次,創建一個單獨但小得多的門控網絡,以模擬第一門控網絡的行為,并在訓練期間在門控網絡的輸出上實施稀疏性,以使其僅在任何給定時刻只選擇一個專家。第三,通過微調專家和完全連接的層來訓練可重構網絡,同時參考了前一步驟中估計的門控網絡的權重。
研究人員訓練了兩個版本的可重構網絡,如下圖所示。請注意,Reconf_Select所需的計算較少,因為它使用逐點求和來代替級聯,從而將來自專家的特征向量進行合并。
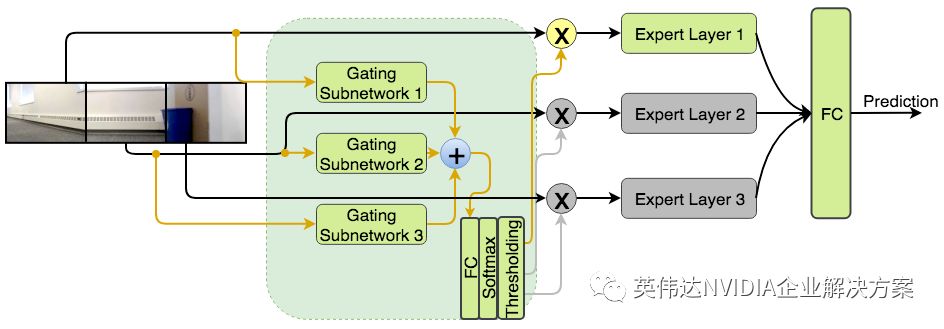

可重構網絡的兩種架構:Reconf_Concat (上方) 和Reconf_Select (下方)
使用NVIDIA GeForce GTX 1080 GPU在70,000個場景上對網絡進行訓練,大約需要6個小時。該網絡在5,738個測試場景上進行了評估,使用相同的GPU進行推理,基于一張圖像只需要1秒。從定量分析來看,如測試損失所證明,從同一攝像頭選擇輸入的兩個網絡版本,可實現與使用來自所有攝像頭的輸入相同的性能,同時減少三倍的FLOPS計算。
對于車輛測試的實時性,作者在Traxxas X-Maxx遙控卡車上安裝了NVIDIA Jetson TX1和三臺Logitech HD Pro攝像頭。網絡必須選擇三個攝像頭中的一個,來收集室內環境的圖像,以用于實時轉向命令估計。該算法的在線處理能力超過20幀/秒。
賓夕法尼亞大學——用于移動機器人的集成傳感和計算系統
此前,賓夕法尼亞大學在Open Vision Computer (OVC)上發表了一篇論文。OVC是一個開源計算平臺,支持高速、視覺引導、GPS拒止和輕量級自主飛行機器人。OVC是與開源機器人基金會合作開發的,它將傳感器和計算元素集成到一個軟件包中。OVC旨在支持一系列計算機視覺算法,包括視覺慣性測距和立體聲,以及包括路徑規劃和控制在內的自主學習相關算法。
OVC的第一個版本OVC1包含通過PCIe總線連接到計算模塊的傳感器子系統。傳感器子系統包括一對CMOS圖像傳感器和慣性測量單元(IMU)。計算模塊是NVIDIA Jetson TX2,專為計算密集型嵌入式應用而設計,PCIe總線為TX2的統一CPU和GPU內存系統提供直接、高速的接口。
在圖像以原始圖像從傳感器傳輸到CPU和GPU的一瞬間,系統就可以提取特征。作者表示,該系統還能夠處理基于深度學習的應用,如用于目標檢測的單發多盒檢測器(SSD512)和用于語義分割的ERFNet架構的變體。
搭載TX2模塊的OVC1重量不到200克,總功耗低于20瓦。隨后,OVC1被安裝在重達1.3千克的Falcon 250自主飛行機器人上。該系統能夠成功地穿越數百米,避開包括樹木和建筑物在內的障礙物,并返回其起始位置,無需GPS信號并基于最小指令。 Falcon 250上的OVC1如下圖所示。
Falcon 250自主飛行機器人,配備第一版Open Vision Computer的OVC1
作者還提出了OVC的第二種設計OVC2,旨在縮小外形尺寸并提高性能,如下圖所示。OVC2基于TX2,但作者正在考慮使用比TX2性能更優的Jetson Xavier。
基于NVIDIA Jetson TX2的第二版Open Vision Computer OVC2
賓夕法尼亞大學還發表了另一篇論文,展示了一種實時立體深度估計和稀疏深度融合算法,該算法在OVC1上進行處理,并且可實現GPU加速。該算法可將從激光雷達傳感器或測距相機獲得的稀疏深度信息引入立體深度估計,其基于Middlebury 2014和KITTI 2015基準數據集所表現出的性能優于現有技術水平。
-
人工智能
+關注
關注
1801文章
48259瀏覽量
243421 -
自動駕駛
+關注
關注
788文章
14058瀏覽量
168249
原文標題:NVAIL合作伙伴攜最新機器人研究成果亮相ICRA 2019
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業解決方案】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
揭曉英偉達最強芯片!Blackwell Ultra、Rubin芯片亮相,新機器人壓軸

卡諾普第二屆海外合作伙伴大會隆重召開
達明機器人攜合作伙伴亮相上海三展,以科技賦能智能制造升級

軟通動力攜手鴻湖萬聯亮相華為中國合作伙伴大會2025
誠邁科技亮相華為中國合作伙伴大會2025
軟通動力攜全棧智能產品閃耀亮相華為中國合作伙伴大會

宇樹科技攜兩款機器人亮相2025GDC
新型復眼結構有望革新機器人視覺系統
NVIDIA合作伙伴精彩亮相ROSCon China 2024
NVIDIA在ICRA展示最新機器人研究
地瓜機器人與廣和通深度合作,共驅智能機器人商用落地

地瓜機器人與廣和通深度合作,共驅智能機器人商用落地

智煥新生 共創AI+時代丨利爾達將攜多款明星產品亮相中國移動全球合作伙伴大會

軟通動力與智元機器人攜手亮相世界機器人大會

入圍全球機器人頂會ICRA 2024!毫末在RoboDrive2024挑戰賽嶄露頭角






 工商網監
工商網監

評論