 關于深度學習 vs 機器學習 vs 模式識別三種技術的性能分析對比
關于深度學習 vs 機器學習 vs 模式識別三種技術的性能分析對比
本文我們來關注下三個非常相關的概念(深度學習、機器學習和模式識別),以及他們與2015年最熱門的科技主題(機器人和人工智能)的聯系。
圖1 人工智能并非將人放入一臺計算機中(圖片來源于 WorkFusion 的博客)
環繞四周,你會發現不缺乏一些初創的高科技公司招聘機器學習專家的崗位。而其中只有一小部分需要深度學習專家。我敢打賭,大多數初創公司都可以從最基本的數據分析中獲益。那如何才能發現未來的數據科學家?你需要學習他們的思考方式。
三個與“學習”高度相關的流行詞匯
模式識別(Pattern recognition)、機器學習(machine learning)和深度學習(deep learning)代表三種不同的思想流派。模式識別是最古老的(作為一個術語而言,可以說是很過時的)。機器學習是最基礎的(當下初創公司和研究實驗室的熱點領域之一)。而深度學習是非常嶄新和有影響力的前沿領域,我們甚至不會去思考后深度學習時代。我們可以看下圖所示的谷歌趨勢圖。可以看到:
1)機器學習就像是一個真正的冠軍一樣持續昂首而上;
2)模式識別一開始主要是作為機器學習的代名詞;
3)模式識別正在慢慢沒落和消亡;
4)深度學習是個嶄新的和快速攀升的領域。
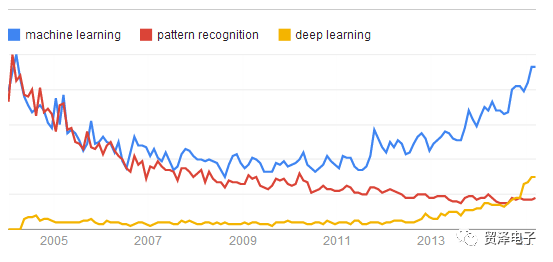
2004年至今三個概念的谷歌搜索指數(圖來源于 谷歌趨勢 )
1. 模式識別:智能程序的誕生
模式識別是70年代和80年代非常流行的一個術語。它強調的是如何讓一個計算機程序去做一些看起來很“智能”的事情,例如識別“3”這個數字。而且在融入了很多的智慧和直覺后,人們也的確構建了這樣的一個程序。例如,區分“3”和“B”或者“3”和“8”。早在以前,大家也不會去關心你是怎么實現的,只要這個機器不是由人躲在盒子里面偽裝的就好(圖2)。不過,如果你的算法對圖像應用了一些像濾波器、邊緣檢測和形態學處理等等高大上的技術后,模式識別社區肯定就會對它感興趣。光學字符識別就是從這個社區誕生的。因此,把模式識別稱為70年代,80年代和90年代初的“智能”信號處理是合適的。決策樹、啟發式和二次判別分析等全部誕生于這個時代。而且,在這個時代,模式識別也成為了計算機科學領域的小伙伴搞的東西,而不是電子工程。從這個時代誕生的模式識別領域最著名的書之一是由Duda & Hart執筆的“模式識別(Pattern Classification)”。對基礎的研究者來說,仍然是一本不錯的入門教材。不過對于里面的一些詞匯就不要太糾結了,因為這本書已經有一定的年代了,詞匯會有點過時。
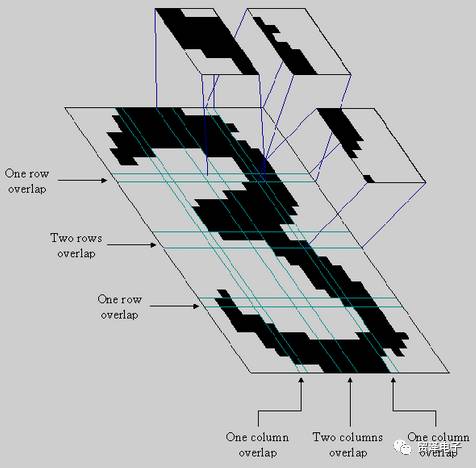
圖2 一個字符“3”的圖像被劃分為16個子塊。
自定義規則、自定義決策,以及自定義“智能”程序在這個任務上,曾經都風靡一時(更多信息,可以查看這個 OCR 網頁)
小測試:計算機視覺領域最著名的會議叫CVPR,這個PR就是模式識別。你能猜出第一屆CVPR會議是哪年召開的嗎?
2. 機器學習:從樣本中學習的智能程序
在90年代初,人們開始意識到一種可以更有效地構建模式識別算法的方法,那就是用數據(可以通過廉價勞動力采集獲得)去替換專家(具有很多圖像方面知識的人)。因此,我們搜集大量的人臉和非人臉圖像,再選擇一個算法,然后沖著咖啡、曬著太陽,等著計算機完成對這些圖像的學習。這就是機器學習的思想。“機器學習”強調的是,在給計算機程序(或者機器)輸入一些數據后,它必須做一些事情,那就是學習這些數據,而這個學習的步驟是明確的。相信我,就算計算機完成學習要耗上一天的時間,也會比你邀請你的研究伙伴來到你家然后專門手工得為這個任務設計一些分類規則要好。
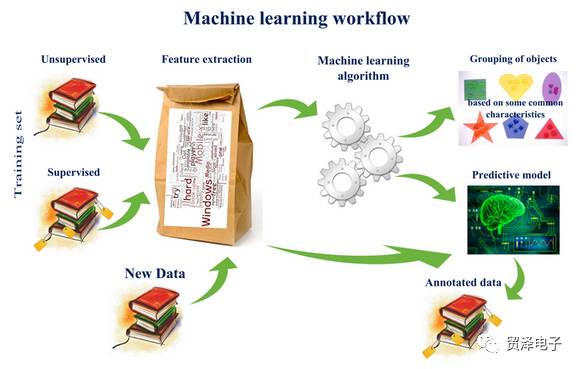
圖3 典型的機器學習流程(圖來源于 Natalia Konstantinova 博士的博客)。
在21世紀中期,機器學習成為了計算機科學領域一個重要的研究課題,計算機科學家們開始將這些想法應用到更大范圍的問題上,不再限于識別字符、識別貓和狗或者識別圖像中的某個目標等等這些問題。研究人員開始將機器學習應用到機器人(強化學習,操控,行動規劃,抓取)、基因數據的分析和金融市場的預測中。另外,機器學習與圖論的聯姻也成就了一個新的課題---圖模型。每一個機器人專家都“無奈地”成為了機器學習專家,同時,機器學習也迅速成為了眾人渴望的必備技能之一。然而,“機器學習”這個概念對底層算法只字未提。我們已經看到凸優化、核方法、支持向量機和Boosting算法等都有各自輝煌的時期。再加上一些人工設計的特征,那在機器學習領域,我們就有了很多的方法,很多不同的思想流派,然而,對于一個新人來說,對特征和算法的選擇依然一頭霧水,沒有清晰的指導原則。但,值得慶幸的是,這一切即將改變……
延伸閱讀:要了解更多關于計算機視覺特征的知識,可以看看原作者之前的博客文章:“ 從特征描述子到深度學習:計算機視覺的20年 ”。
3. 深度學習:一統江湖的架構
快進到今天,我們看到的是一個奪人眼球的技術---深度學習。而在深度學習的模型中,受寵愛最多的就是被用在大規模圖像識別任務中的卷積神經網絡(Convolutional Neural Nets,CNN),簡稱ConvNets。
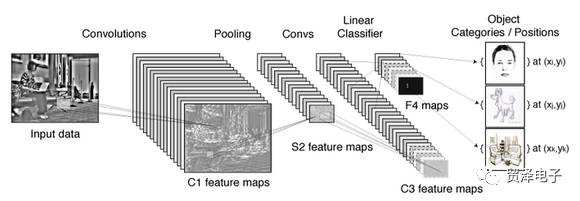
圖4 ConvNet框架(圖來源于 Torch的教程 )
深度學習強調的是你使用的模型(例如深度卷積多層神經網絡),模型中的參數通過從數據中學習獲得。然而,深度學習也帶來了一些其他需要考慮的問題。因為你面對的是一個高維的模型(即龐大的網絡),所以你需要大量的數據(大數據)和強大的運算能力(圖形處理器,GPU)才能優化這個模型。卷積被廣泛用于深度學習(尤其是計算機視覺應用中),而且它的架構往往都是非淺層的。
如果你要學習Deep Learning,那就得先復習下一些線性代數的基本知識,當然了,也得有編程基礎。我強烈推薦Andrej Karpathy的博文:“ 神經網絡的黑客指南 ”。另外,作為學習的開端,可以選擇一個不用卷積操作的應用問題,然后自己實現基于CPU的反向傳播算法。
對于深度學習,還存在很多沒有解決的問題。既沒有完整的關于深度學習有效性的理論,也沒有任何一本能超越機器學習實戰經驗的指南或者書。另外,深度學習不是萬能的,它有足夠的理由能日益流行,但始終無法接管整個世界。不過,只要你不斷增加你的機器學習技能,你的飯碗無憂。但也不要對深度框架過于崇拜,不要害怕對這些框架進行裁剪和調整,以得到和你的學習算法能協同工作的軟件框架。未來的Linux內核也許會在Caffe(一個非常流行的深度學習框架)上運行,然而,偉大的產品總是需要偉大的愿景、領域的專業知識、市場的開發,和最重要的:人類的創造力。
其他相關術語
1)大數據(Big-data):大數據是個豐富的概念,例如包含大量數據的存儲,數據中隱含信息的挖掘等。對企業經營來說,大數據往往可以給出一些決策的建議。對機器學習算法而言,它與大數據的結合在早幾年已經出現。研究人員甚至任何一個日常開發人員都可以接觸到云計算、GPU、DevOps和PaaS等等這些服務。
2)人工智能(Artificial Intelligence):人工智能應該是一個最老的術語了,同時也是最含糊的。它在過去50年里經歷了幾度興衰。當你遇到一個說自己是做人工智能的人,你可以有兩種選擇:要么擺個嘲笑的表情,要么抽出一張紙,記錄下他所說的一切。
延伸閱讀:原作者2011的博客:“ 計算機視覺當屬人工智能 ”。
結論
關于機器學習的討論在此停留(不要單純的認為它是深度學習、機器學習或者模式識別中的一個,這三者只是強調的東西有所不同),然而,研究會繼續,探索會繼續。我們會繼續構建更智能的軟件,我們的算法也將繼續學習,但我們只會開始探索那些能真正一統江湖的框架。
-
模式識別
+關注
關注
3文章
45瀏覽量
14347 -
人工智能
+關注
關注
1792文章
47497瀏覽量
239211 -
機器學習
+關注
關注
66文章
8428瀏覽量
132835 -
深度學習
+關注
關注
73文章
5510瀏覽量
121337
發布評論請先 登錄
相關推薦
模式識別中三種字符識別的方法
干貨:深度學習 vs 機器學習 vs 模式識別三種技術對比
深度學習的三種基本結構及原理詳解
深度學習的三種學習模式介紹





 工商網監
工商網監
評論