") 賽靈思解讀異構(gòu)計算
賽靈思解讀異構(gòu)計算
什么是異構(gòu)計算?
異構(gòu)計算,可能在很多人看來感覺高深莫測,我們可以先用一個比喻來簡單的解釋一下。比如在做簡單的整數(shù)算數(shù)時,知道算法口訣的人,心算即可,但遇到比較復(fù)雜的算數(shù)問題時,就得需要一個計算器了,而在這個運算過程中,一些簡單的計算可以提前由心算完成再輸入計算器,比如計算“(5+2)÷26”,可能我們直接就輸入“7÷26”了。又或者是完全交給計算器進(jìn)行計算,但這也需要人腦控制手指進(jìn)行計算器的數(shù)值輸入,此時你的大腦與計算器就構(gòu)成了完成這道數(shù)學(xué)計算任務(wù)的“異構(gòu)計算系統(tǒng)”。
日常生活中最常見的異構(gòu)計算——人腦+計算器
就像你的大腦的結(jié)構(gòu)與計算器完全不一樣,異構(gòu)計算,顧名思義就是在系統(tǒng)內(nèi),參與計算的執(zhí)行單元在指令集架構(gòu)(ISA, Instruction Set Architectures)層面是不同的。最為典型的例子,就是通用計算圖形處理器(GPGPU,General-Purpose computing on Graphics Processing Units),與現(xiàn)場可編程門陣列 (FPGA,F(xiàn)ield-Programmable Gate Array)和傳統(tǒng)CPU平臺組成的異構(gòu)計算系統(tǒng)。從嚴(yán)格意義上講,ISA相同,只是不同大小的處理核心的組合,并不算是異構(gòu)計算,比如英特爾的x86處理器+MIC(集成眾核加速器),以及ARM處理器的big.LITTLE大小核心的混合設(shè)計。
異構(gòu)計算簡史
為什么要用異構(gòu)計算,想想開頭的例子就清楚了,如果人腦就是主流的通用處理器的話,那么異構(gòu)計算就是為這個處理器額外配備的“計算器”或工具,用來執(zhí)行更高復(fù)雜度的計算或應(yīng)用,而這種復(fù)雜度主要指的就是超大規(guī)模的并行處理,對于更擅長串行處理的CPU來說是一個極大的互補。
異構(gòu)計算的概念本身其實并不新鮮,最早可以追溯到30年前(在某些定義中,則是以指令集的處理模式來區(qū)分異構(gòu)與否,但基本上已并非是主流概念),可要談到異構(gòu)計算的真正崛起,則要從2001年用GPU實現(xiàn)通用矩陣計算開始,而標(biāo)志性事件發(fā)生在2005年,GPU終于在執(zhí)行LU分解(用于解線性方程組)的性能方面戰(zhàn)勝了CPU,從那之后,基于GPU的大規(guī)模并行計算方案開始嶄露頭角。
CPU+GPGPU是目前最為知名的異構(gòu)計算組合,也是第一代異構(gòu)計算的典型代表
2007年,NVIDIA推出了專門用于簡化GPU應(yīng)用編程的統(tǒng)一計算設(shè)備架構(gòu)(CUDA,Compute Unified Device Architecture),它標(biāo)志著GPU的通用計算應(yīng)用開發(fā)開始走向易用、成熟。時至今日,GPU+CPU的異構(gòu)計算平臺已經(jīng)越來越多的出現(xiàn)在高性能計算系統(tǒng)中(HPC),大大彌補了CPU在浮點運算方面的能力。
當(dāng)然,在GPGPU之前其實還有多種芯片在向通用計算領(lǐng)域邁進(jìn),其中之一就是FPGA,它是最可匹敵GPGPU的異構(gòu)計算技術(shù)。
2012年英特爾發(fā)布的Atom E6x5C嵌入式處理器,就已經(jīng)在單Socket封裝上整合了Altera的FPGA,但這個FPGA的主要任務(wù)不是計算,而是針對不同應(yīng)用場景的I/O定制化與指定的信號處理,很難用于通用場合
FPGA于1985年誕生,很快就開始嘗試在通用計算領(lǐng)域的運用,可以說比GPGPU的出現(xiàn)還要早。GPGPU所擅長的浮點運算,F(xiàn)PGA同樣也在積極參與,但成果遠(yuǎn)沒有GPGPU顯著(看看超級計算機全球TOP500的排名配置就知道了)。在整數(shù)型運算方面,雖然FPGA更有優(yōu)勢,可惜那時的計算量除非個別應(yīng)用,普遍并不大,CPU自己就能搞定,所以FPGA加速更多用于細(xì)分應(yīng)用市場,應(yīng)用規(guī)模相對來說并不大。不過,隨著物聯(lián)網(wǎng)、大數(shù)據(jù)、人工智能、機器學(xué)習(xí)等新興的大規(guī)模數(shù)據(jù)處理需求的不斷涌現(xiàn),現(xiàn)在它的機會要來了,而且底層互聯(lián) 技術(shù)也比當(dāng)前的異構(gòu)系統(tǒng)更為先進(jìn),它就是由OpenPOWER CAPI所開辟的新一代異構(gòu)計算平臺,主打CAPI+FPGA的組合。
而在我看來,它們其實是開啟了第二代異構(gòu)計算的時代。
FPGA如何為應(yīng)用加速?
從第一款FPGA芯片于1985年由Xilinx(賽靈思)正式推出至今,已經(jīng)有30年了,它是在可編程陣列邏輯(PAL,Programmable Array Logic)、通用陣列邏輯(GAL,Generic Array Logic)、復(fù)雜可編程邏輯器件(CPLD,Complex Programmable Logic Device) 等技術(shù)的基礎(chǔ)上進(jìn)一步發(fā)展的產(chǎn)物。與CPU不同的是,它的邏輯是硬件可編程的,而CPU則是通過軟件編程來執(zhí)行相應(yīng)的計算,和專用集成電路(ASIC,Application Specific Integrated Circuit)相比,它又相當(dāng)于一種半成品的邏輯芯片,ASIC則是針對某類應(yīng)用進(jìn)行專門的固化設(shè)計,以達(dá)到最優(yōu)的性能。
從字面意思上就可以想像得到FPGA是一個可隨意定制內(nèi)部邏輯的陣列,并且可以在用戶現(xiàn)場進(jìn)行即時編程,以修改內(nèi)部的硬件邏輯,這一點是CPU和ASIC都無法做到的。要想明白FPGA的原理,的確需要一定的數(shù)字電路基礎(chǔ),在此只做簡要的介紹,以解釋為什么FPGA可以在某些工作上比CPU更為出色。
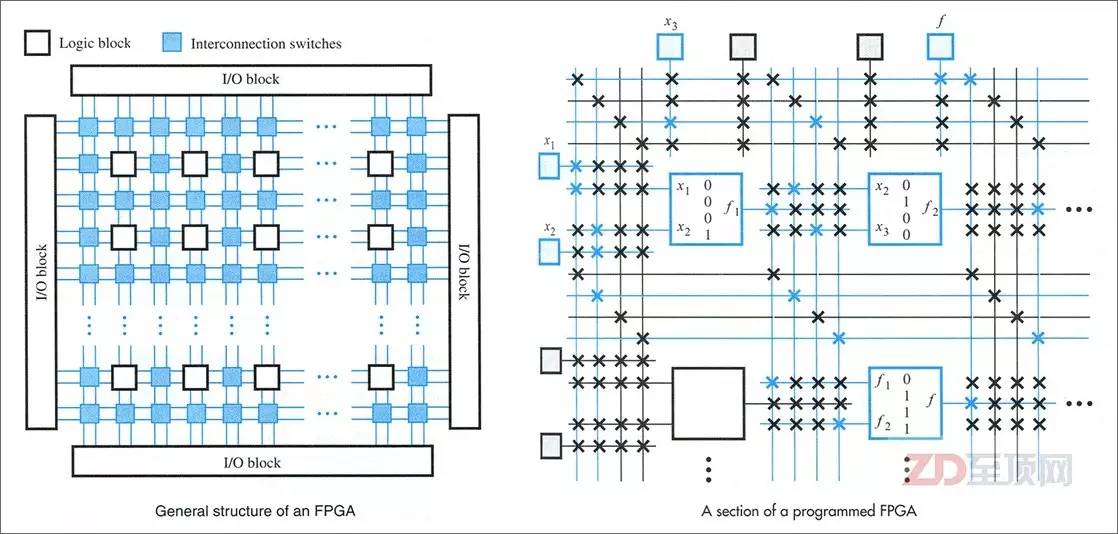
FPGA的內(nèi)部主要是由用于實現(xiàn)硬件邏輯的邏輯塊(LB,Logic Block)、負(fù)責(zé)LB互聯(lián)的內(nèi)部互聯(lián)交換節(jié)點(IS,Interconnection Switch)以及負(fù)責(zé)輸入輸出的I/O Block組成,它們都是可編程的,而隨著技術(shù)的進(jìn)步,F(xiàn)PGA芯片里也越來越多的集成相關(guān)的固定器件與硬核(IP)電路,如乘法器、數(shù)字信號處理器(Digital Signal Processor)等,以進(jìn)一步加速相關(guān)的運算,并完善相關(guān)的功能(比如I/O)
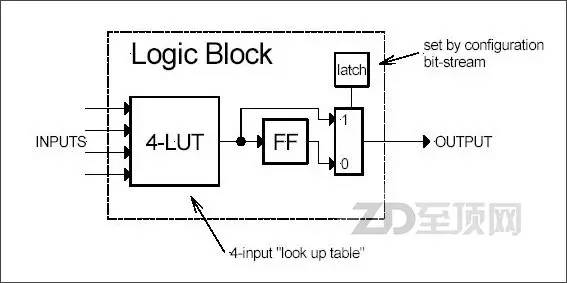
LB是FPGA內(nèi)的基本邏輯單元,是FPGA可實現(xiàn)邏輯編程的基礎(chǔ),而在LB中最常用的邏輯編程器件就是查找表(LUT,Look Up Table,又稱直譯表),通過編程它可以實現(xiàn)輸入與輸出的直接對應(yīng)關(guān)系,從而實現(xiàn)了輸入與輸出的硬邏輯,在應(yīng)用時,直接根據(jù)輸入的值,通過LUT給出相應(yīng)的輸出值。輸入的組合根據(jù)輸入端口數(shù)量而定,比如4個端口就可實現(xiàn)16種輸入組合(2的4次方),而一個LB可以包含有多個LUT,實現(xiàn)更復(fù)雜的邏輯組合
FPGA的內(nèi)部總體架構(gòu),主要是由實現(xiàn)硬件邏輯的邏輯塊(LB)、負(fù)責(zé)LB互聯(lián)的內(nèi)部互聯(lián)交換節(jié)點(IS)以及負(fù)責(zé)輸入輸出的I/O Block組成。由于幾乎所有的邏輯電路都是通過不同門電路的組合來實現(xiàn)的,所以FPGA其實就是提供了數(shù)量眾多的門電路,讓用戶用硬件描述語言(HDL,Hardware Description Language)自行設(shè)計它們各自的邏輯狀態(tài)與相互之間的邏輯關(guān)系,從而讓被編程的FPGA變成為某種專用芯片,所以說FPGA是ASIC的半成品,不無道理。
事實上,F(xiàn)PGA在早期的一個重要的用途就是為了更好的設(shè)計ASIC,畢竟等ASIC生產(chǎn)出來再實驗的成本太高。而通過FPGA可以進(jìn)行復(fù)雜的邏輯測試,來驗證ASIC的設(shè)計,并通過可編程進(jìn)行反復(fù)的優(yōu)化。當(dāng)邏輯優(yōu)化到相當(dāng)水平后,再以更為直接的邏輯實現(xiàn)方法形成ASIC電路,以達(dá)到更好的性能。隨著FPGA自身的性能、能力與可實現(xiàn)邏輯的復(fù)雜度的不斷提升,現(xiàn)在FPGA已經(jīng)逐漸可以直接代替一些中等規(guī)模的ASIC來使用,并在整體功耗上,保持對CPU的明顯優(yōu)勢。
在國內(nèi)率先開發(fā)CAPI+FPGA加速卡解決方案的,恒揚科技股份有限公司大數(shù)據(jù)采集與分析產(chǎn)品經(jīng)理張軍,這樣形容FPGA,“FPGA就是一張白紙,(最終的邏輯電路)想畫什么完全由設(shè)計師決定,而 CPU等軟件編程的器件就像鉛筆畫(已經(jīng)有了框架),設(shè)計師是在上面涂色彩。” 事實上,F(xiàn)PGA可以實現(xiàn)怎樣的能力,主要就取決于它所提供的門電路的規(guī)模。
現(xiàn)在主流的FPGA內(nèi)部均采用了SRAM編程方式(SRAM本身就是一個邏輯部件可用于LUT,而SRAM晶體管可用于內(nèi)部互聯(lián)鏈路的選通組合),可以實現(xiàn)快速的硬件編程,并能無限次的重復(fù)使用。雖然SRAM的特性決定了關(guān)機后內(nèi)部邏輯組合就會消失,但基于SRAM的編程在每次開機時都可以從外部的Flash芯片即時加載FPGA配置文章,加載(編程)速度為毫秒級,所以完全不影響使用。在處理性能上,由于FPGA的邏輯實現(xiàn)是通過硬件編程來獲得,所以開發(fā)人員可以將指定的算法邏輯,直接以FPGA內(nèi)部不同門電路的硬邏輯組合來實現(xiàn),而且現(xiàn)在越來越多的FPGA內(nèi)部都增加了固化的乘法器、DSP等處理單元,進(jìn)一步加快了相關(guān)運算的處理速度。
從某種角度上說,F(xiàn)PGA內(nèi)部其實并沒有所謂的“計算”,最終結(jié)果幾乎是“電路直給”,因此執(zhí)行效率就大幅提高。當(dāng)然,由于采用的是通用的門電路組合,在某些處理效率上FPGA仍然不及ASIC極致,但是可重復(fù)更新內(nèi)部邏輯的靈活性,再加上在固定算法上遠(yuǎn)高于CPU的執(zhí)行效率,讓FPGA在應(yīng)用領(lǐng)域迅速得到重視。然而需要指出的是,用FPGA的門電路實現(xiàn)整數(shù)運算邏輯,要比實現(xiàn)浮點運算邏輯簡單得多,所以FPGA的加速優(yōu)勢也更多的體現(xiàn)在整數(shù)性運算,而整數(shù)運算正是當(dāng)前主流企業(yè)級應(yīng)用的主要運算方式,而這也是為什么GPGPU更多的用于浮點運算領(lǐng)域(如HPC),F(xiàn)PGA更多用于整數(shù)加速領(lǐng)域的一大原因。
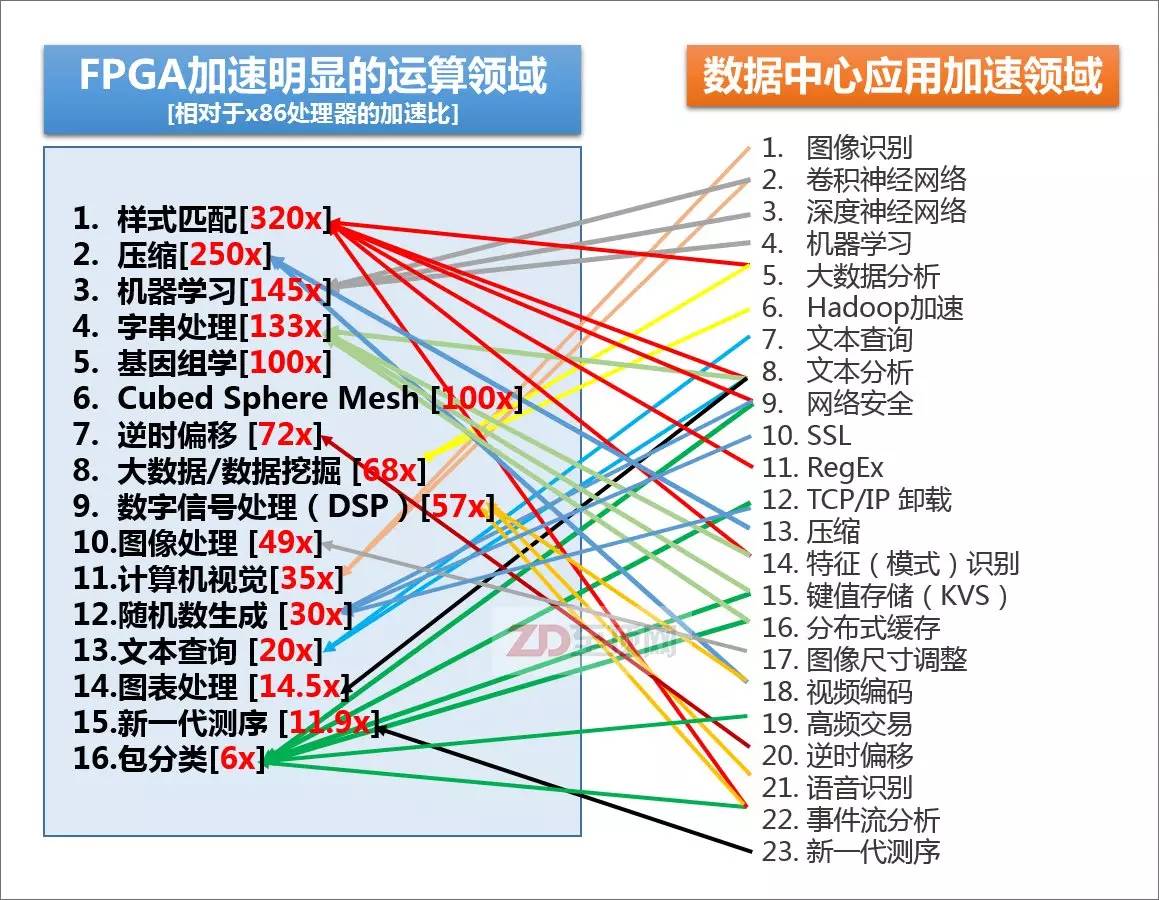
賽靈思總結(jié)的,目前FPGA相對于主流的x86處理器,在某些領(lǐng)域里的加速比,以及目前數(shù)據(jù)中心里可用到FPGA加速的領(lǐng)域,可以說80-90%的大規(guī)模并行密集應(yīng)用都可以被FPGA加速,尤其是以整數(shù)型運算為主的應(yīng)用,加速效果更為明顯。當(dāng)然,并不是說FPGA不能用于浮點運算,但相對來說,整數(shù)型加速對于FPGA更容易實現(xiàn),相較GPGPU也有更明顯的優(yōu)勢。另外,請注意很多IT基礎(chǔ)設(shè)施的底層信息處理方面,如安全、加密、網(wǎng)絡(luò)加速、鍵值存儲也在FPGA的應(yīng)用范疇之內(nèi),其“實用性”顯然比GPGPU更為廣泛
但是,傳統(tǒng)的FPGA加速設(shè)計,均是以I/O總線與CPU平臺相連,比如常見的PCIe,在系統(tǒng)內(nèi)部以一個I/O設(shè)備存在,所以在實際的應(yīng)用中,對于應(yīng)用開發(fā)者本身來說仍然有較大的難度。這次CAPI的出現(xiàn),則從根本上解決了這個難題,從而讓FPGA的加速優(yōu)勢得以獲得更充分的發(fā)揮。
OpenPOWER CAPI簡介
OpenPOWER是以IBM、NVIDIA、Mellanox、Google、TYAN為首的5家公司,于2013年8月發(fā)起的一個技術(shù)推廣聯(lián)盟,截止到2015年6月,OpenPOWER會員數(shù)量超過了130家,來自于中國的廠商就超過了20家。
OpenPOWER所推廣的技術(shù)就是基于IBM POWER8及以后的處理器與平臺技術(shù),這其中POWER8處理器所具備的一致性加速處理器接口(CAPI,Coherent Accelerator Processor Interface)就是一個重要的技術(shù)點,也正是它讓FPGA迅速成為了新一代異構(gòu)計算的亮點。
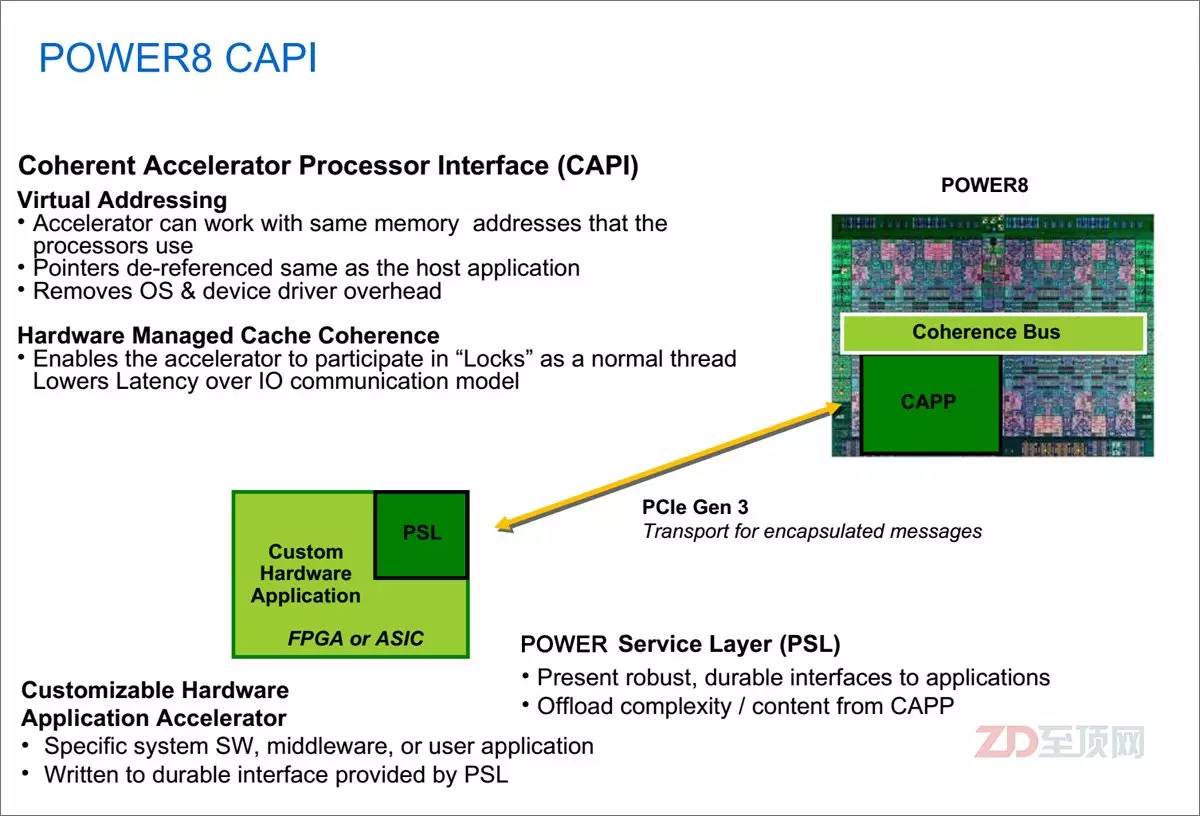
CAPI的基本原理就是通過在POWER處理器(從POWER8開始)內(nèi)部設(shè)置一致性加速處理器代理(CAPP,Coherent Accelerator Processor Proxy),而在外置的加速卡上,則內(nèi)置POWER處理器服務(wù)層(PSL,POWER Service Layer),其與CAPP配合,為加速卡在CPU上打通了一個“后門”。加速卡(PSL)與CPU(CAPP)之間采用成熟的PCIe總線+CAPI協(xié)議進(jìn)行數(shù)據(jù)傳輸,但不用走復(fù)雜的PCIe I/O模式,并獲得了與CPU對等訪問虛擬內(nèi)存地址的能力。目前POWER8內(nèi)部共有兩個CAPP,每個CPU可外接兩個CAPI加速卡
CAPI最為關(guān)鍵的重點就在于一致性(Coherent),確切的說它包含兩個概念,它們之間是相輔相成的。第一個就是虛擬地址空間訪問的一致性,這與傳統(tǒng)的總線地址或物理地址訪問的模式有了本質(zhì)的區(qū)別。虛擬地址空間訪問的一致性,是CAPI加速器實現(xiàn)與CPU對等訪問的根本體現(xiàn),否則在應(yīng)用編程上仍然要有較大的調(diào)整。
一致性的第二個含義就是緩存一致性,在IBM提供的PSL硬核模塊(可以集成于合作伙伴的芯片,或?qū)懭隖PGA)中包含有256KB的緩存,而在CPU內(nèi)部,CAPP則負(fù)責(zé)維護(hù)CAPI一側(cè)的緩存行目錄,以保證CPU級的緩存一致性(CC,Cache Coherency )。這就相當(dāng)于在CPU內(nèi)部額外增加了一個特殊的處理核心(給CPU開了一個外掛),其對于內(nèi)存的訪問能力與其他“正常的”CPU核心是一致的,納入到統(tǒng)一的CC體系,這就與傳統(tǒng)的通過PCIe插卡實現(xiàn)加速的方式有了本質(zhì)的不同。
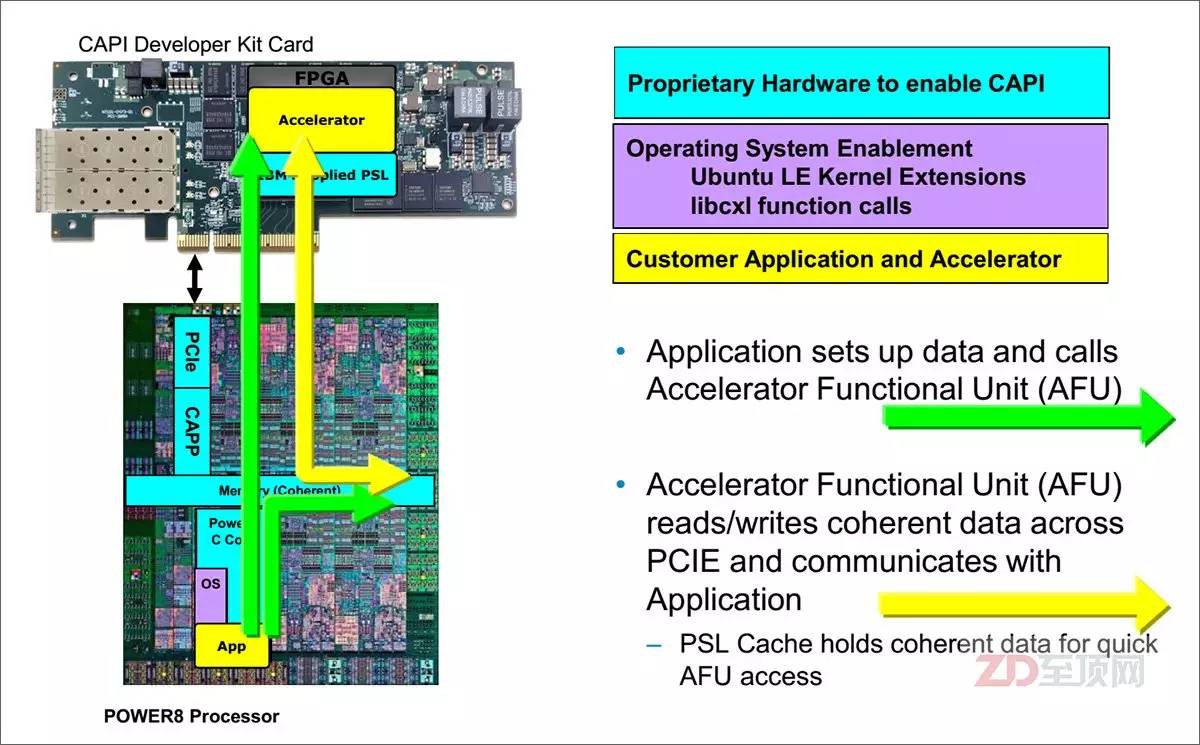
在具體的FPGA加速應(yīng)用中,應(yīng)用透過CAPP與PSL的連接,掛載(綁定)加速卡,PSL與CAPP一起協(xié)同,讓FPGA里的加速功能單元(AFU,Accelerator Functional Unit)實現(xiàn)與CPU的對等訪問——可直接看到應(yīng)用所指向的虛擬內(nèi)存地址,并通過PCIe總線與應(yīng)用溝通
在CAPI+FPGA的應(yīng)用中,用戶先將相關(guān)應(yīng)用的加速算法,以HDL(目前主要是Verilog HDL和VHDL)寫入FPGA,構(gòu)成加速功能單元(AFU),它就是上文提到的那個“外掛的特殊CPU核心”。然后再通過PSL與CAPP的協(xié)同,將AFU“嵌入”到CPU里,被應(yīng)用發(fā)現(xiàn)并直接調(diào)用。AFU可以直接讀寫應(yīng)用所管理的虛擬內(nèi)存空間,以一種嵌入式的外掛處理模式實現(xiàn)應(yīng)用的加速。從某種意義上說,“外掛”的AFU的作用有點像CPU的加速指令集(比如SSE、MMX等),但可靈活變換且效率明顯更高。
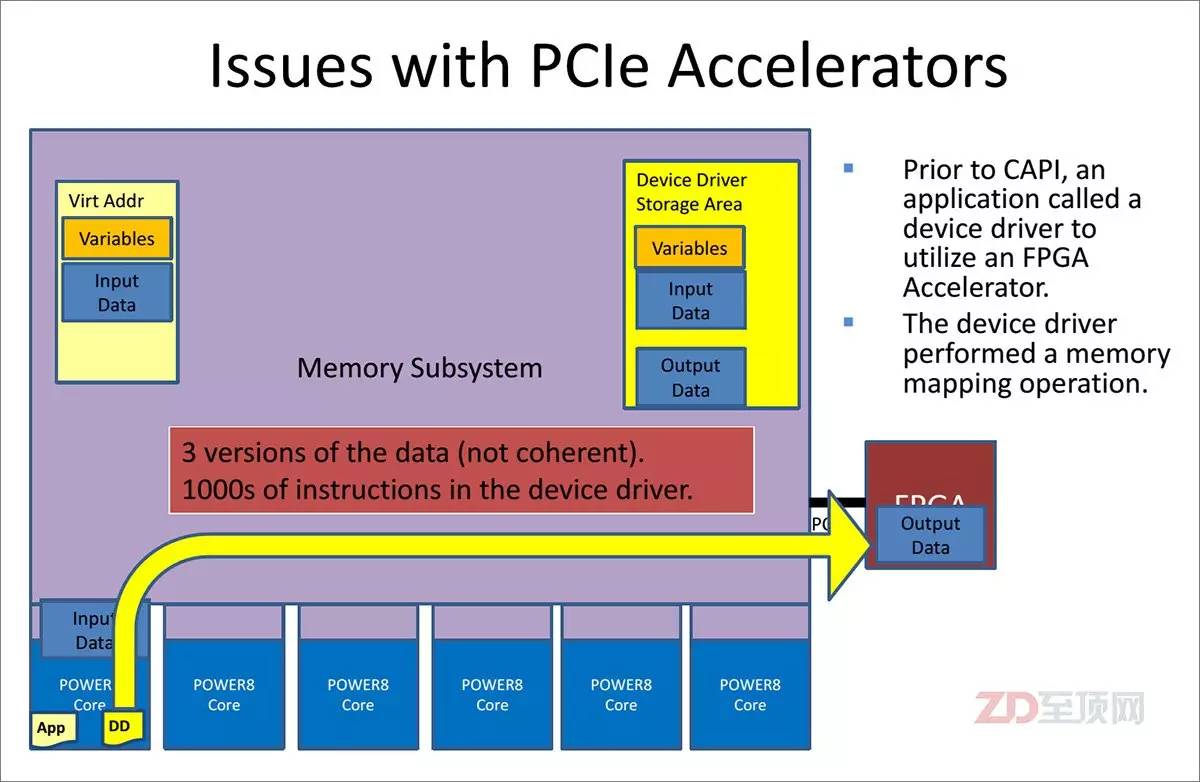
在非CAPI加速體系中,傳統(tǒng)的加速卡是以一個I/O設(shè)備存在的,這必然需要虛擬地址的重新影射,從而在內(nèi)存中會生成3個數(shù)據(jù)副本,并需要大量的驅(qū)動訪問指令,后果就是延遲的增加
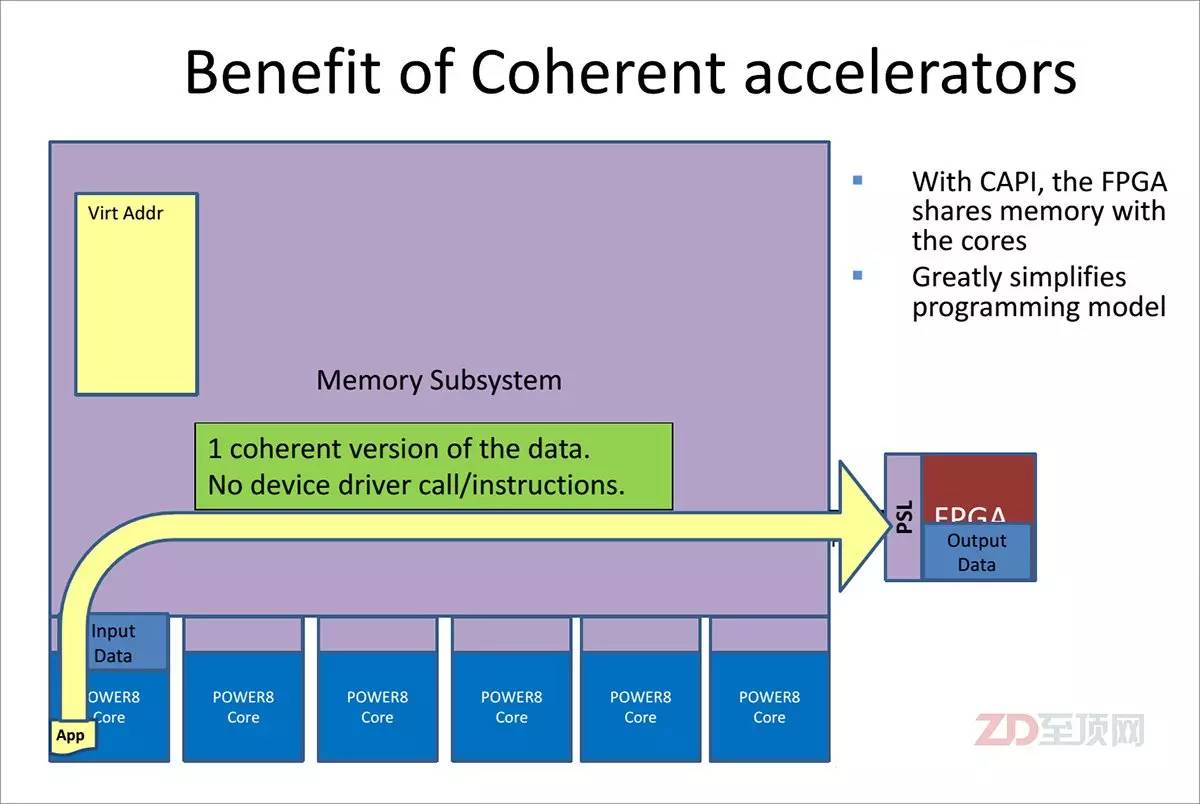
在CAPI體系下,CAPI加速器與CPU實現(xiàn)了對等訪問,共享虛擬地址,數(shù)據(jù)無需轉(zhuǎn)手,直接在加速器與應(yīng)用之間進(jìn)行溝通。在實際使用時也很簡單,CAPI加速卡可以安裝在任何提供PCIe3.0接口的OpenPOWER Linux服務(wù)器上。應(yīng)用軟件只需要調(diào)用一個CAPI函數(shù),即可直接利用CAPI加速,而在對Linux更新驅(qū)動后,即可直接調(diào)用原有IM/GM等兼容接口函數(shù)
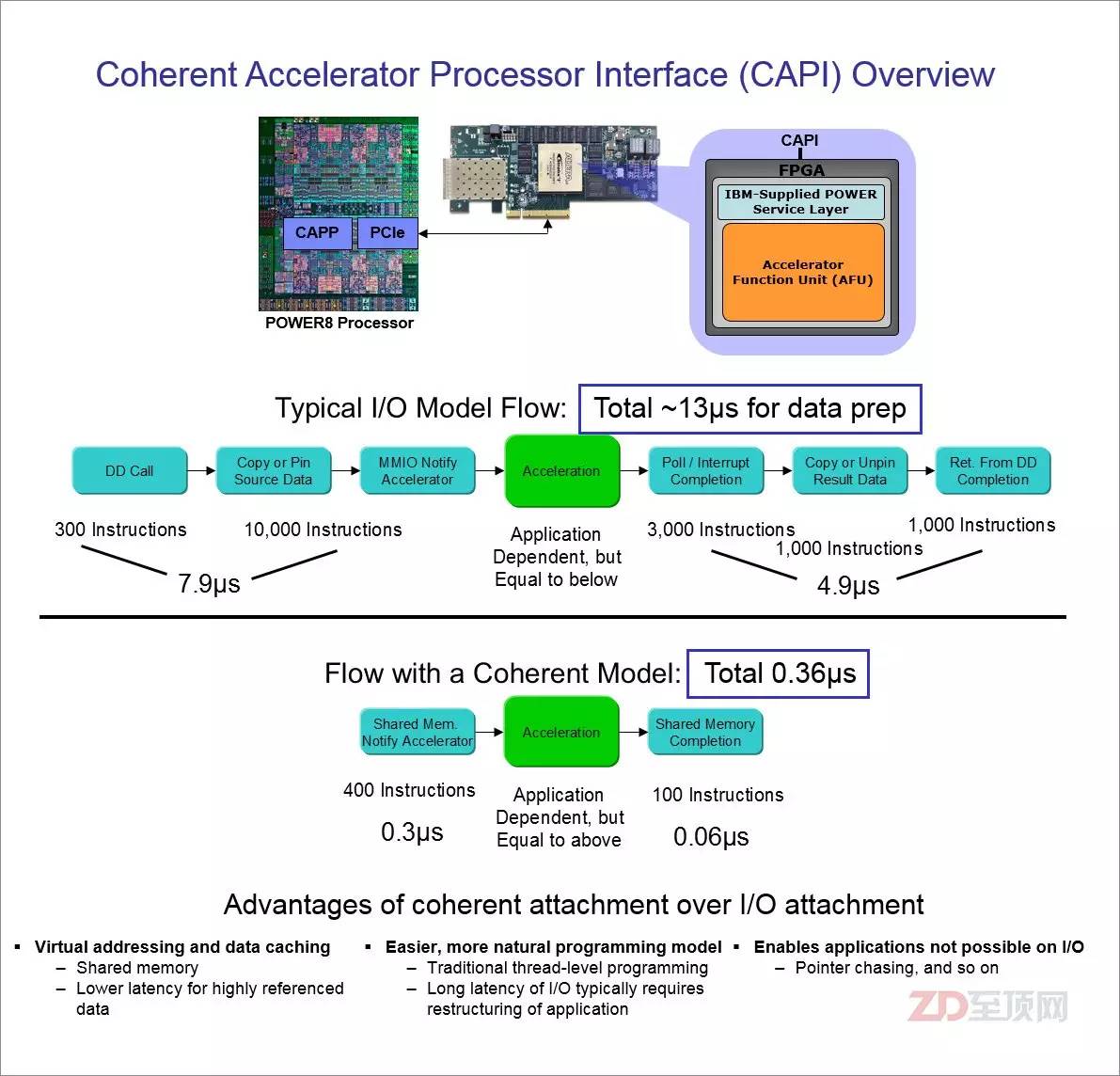
由于CAPI接口并非傳統(tǒng)意義上的I/O驅(qū)動模式,直接走硬件代理與CPU溝通,所以從應(yīng)用的全局視角,數(shù)據(jù)的訪問步驟明顯減少(FPGA與CPU對等訪問),讓數(shù)據(jù)訪問效率大幅度提高,總延遲約是傳統(tǒng)模式的1/36,同時這種應(yīng)用加速設(shè)計,對于應(yīng)用的編程修改影響最小
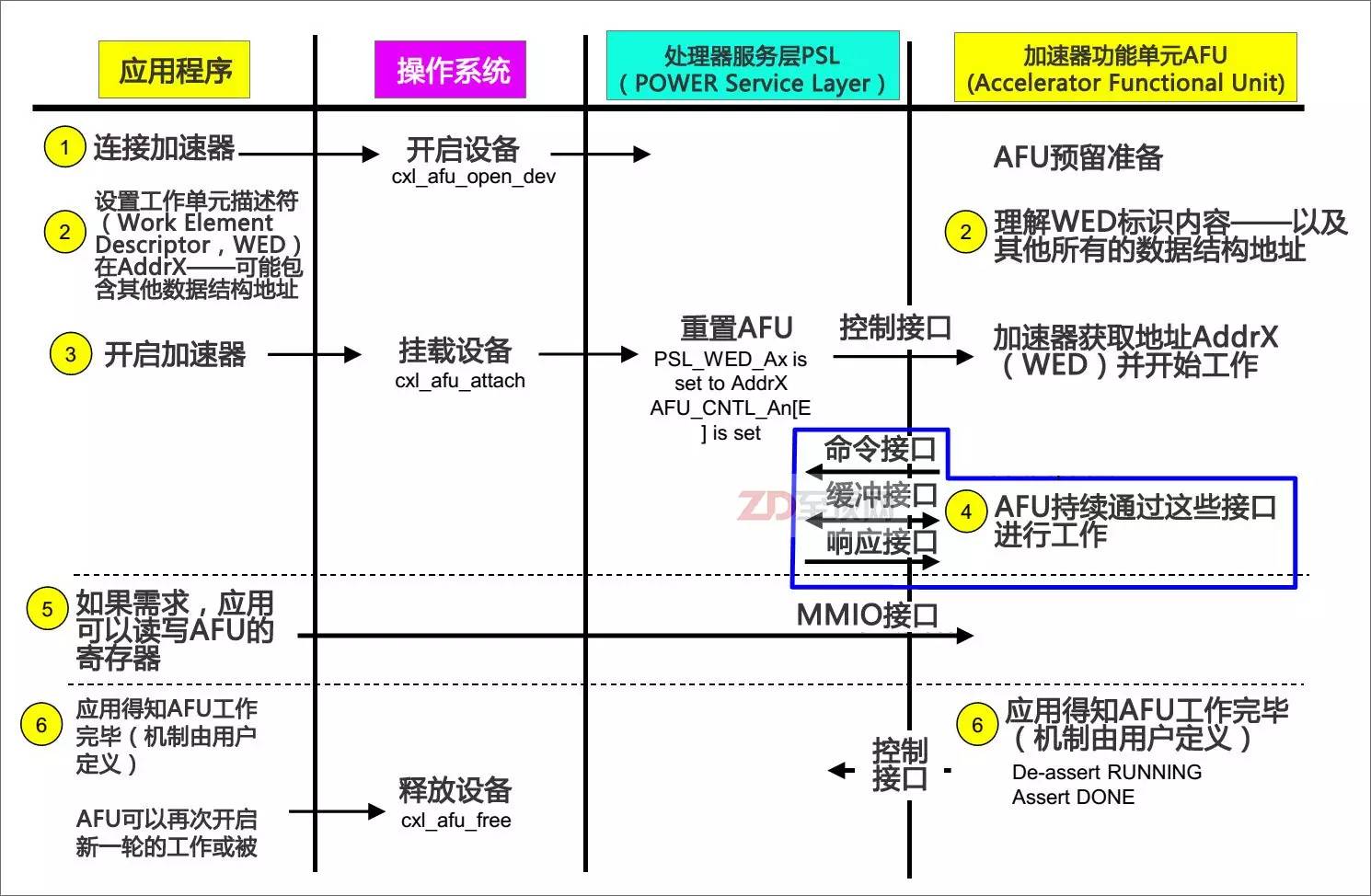
CAPI加速器從準(zhǔn)備加速到完成加速的溝通流程相當(dāng)?shù)暮啙嵜髁耍梢曰究偨Y(jié)為——應(yīng)用:CAPI加速器,我看到你了;CAPI加速器:應(yīng)用,我已經(jīng)為你準(zhǔn)備好了;應(yīng)用:我要處理的數(shù)據(jù)在內(nèi)存地址AddrX處,剩下的工作就交給你了;CAPI加速器:好的,沒問題;(開始循環(huán)加速)……CAPI加速器:報告應(yīng)用,已經(jīng)處理完畢;應(yīng)用:好的,你先休息吧,有事我再叫你
從以上圖片可以看出,由于一致性特色的加入,讓CAPI加速卡避開了傳統(tǒng)I/O設(shè)備的驅(qū)動模式,直接以“硬件代理”的方式嵌入應(yīng)用的執(zhí)行,因此在總體的命令開銷方面有明顯的減少。這直接帶來的效果就是延遲大幅降低——總延遲約只有傳統(tǒng)加速模式的1/36,并且?guī)砹烁蟮暮锰帯捎跊]有了傳統(tǒng)I/O設(shè)備層,應(yīng)用平臺為了適配加速器的編程修改非常小,應(yīng)用開發(fā)者完全可以將應(yīng)用做成自適應(yīng)模式,在非CAPI平臺上采用傳統(tǒng)的處理模式,當(dāng)發(fā)現(xiàn)系統(tǒng)有CAPI加速器則自動打開CAPI模式,這顯然非常有利于CPAI加速模式在相關(guān)應(yīng)用領(lǐng)域里的普及。
在具體的應(yīng)用環(huán)境中,目前CAPI還不能用于虛擬化平臺(比如KVM),但完全支持基于Linux核心的Docker容器平臺(現(xiàn)在的CAPI全面支持Ubuntu 14.10)。按照IBM未來的發(fā)展規(guī)劃,新一代CAPI正在路上,它將基于PCIe 4.0規(guī)格(也可能會采用新的總線接口),并稍加改動,連接帶寬較PCIe 4.0稍微提高,以抵銷CAPI協(xié)議的開銷,從而讓加速器可以充分利用到PCIe的帶寬。另外,CAPI的虛擬化(多個應(yīng)用可以分時復(fù)用加速器)也將是必然的,融入云計算平臺的統(tǒng)一管理也將水到渠成。并且單一PSL未來可以掛載多個AFU,在FPGA內(nèi)部最多可以同時具備4個AFU,PSL分別為它們保存各自的虛擬空間地址,并與CAPP一起保持緩存一致性,這就相當(dāng)于給系統(tǒng)同時配備了4個外掛核心。在操作系統(tǒng)方面,未來還將支持AIX、RedHat等OS,這將意味著除了PowerLinux平臺,傳統(tǒng)的AIX POWER服務(wù)器上的應(yīng)用也將能享受到CAPI加速。
OpenPOWER CAPI+FPGA應(yīng)用實戰(zhàn)
借助于OpenPOWER聯(lián)盟,很多廠商都投入到了CAPI+FPGA的加速卡設(shè)計中,中國的恒揚科技(Semptian)即是其中之一,其最新推出的Semptian NSA-120是一款基于XILINX Kintex UltraScale FPGA的CAPI PCIe板卡,采用PCIE x8 Gen3 接口規(guī)格,支持兩路DDR3 1600 SODIMM(容量為2x8GB),而首先投入的AFU,是針對大數(shù)據(jù)存儲中常用的糾刪碼(Erasure Code)的編/解碼加速。
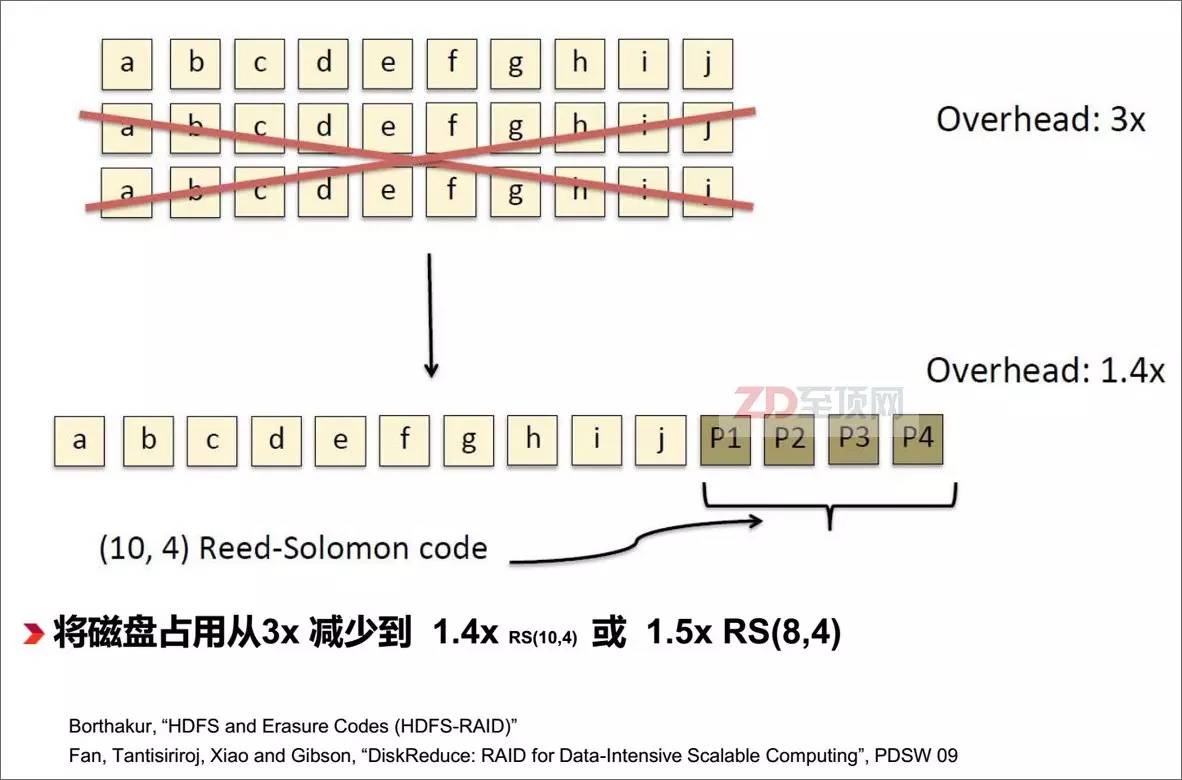
糾刪碼是應(yīng)對降低海量分布式存儲占用空間的常用手段,相對于傳統(tǒng)的3復(fù)本冗余的存儲模式(相當(dāng)于3x容量占用),糾刪碼冗余的存儲容量只相當(dāng)于原數(shù)據(jù)量的1.4x,降低了超過50%的存儲空間需求,但在大規(guī)模數(shù)據(jù)讀寫過程中,糾刪碼的實時編/解碼運算對于服務(wù)器CPU來說將是一個比較大的占用,在分布式應(yīng)用架構(gòu)中,這意味著將影響應(yīng)用本身的性能

通過Semptian NSA-120的加速,獲得了明顯的糾刪碼的性能提升,如果再多加一塊Semptian NSA-120(雙CPU配置時最多可插4塊),性能還會加倍提高
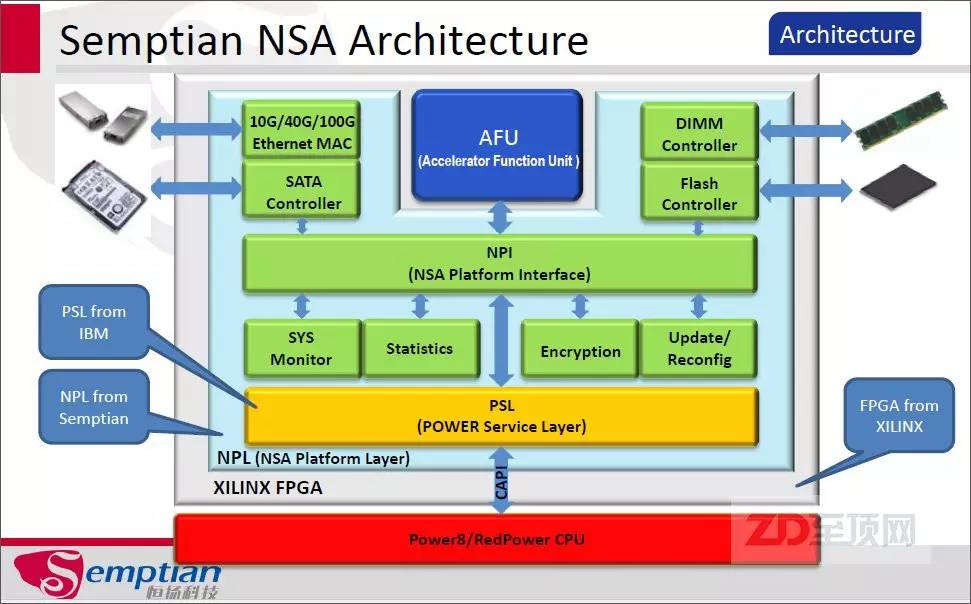
為了進(jìn)一步方便ISV與AFU的開發(fā)者,恒揚科技專門提供了NPL(NSA Platform Layer),即FPGA基礎(chǔ)平臺,幫助AFU開發(fā)者硬件無感知的開發(fā)AFU算法單元
根據(jù)恒揚科技大數(shù)據(jù)采集與分析產(chǎn)品經(jīng)理張軍的介紹,目前FPGA的編程環(huán)境已經(jīng)有了很大的改善,這其中OpenCL開發(fā)平臺的發(fā)展起到了重要的推進(jìn)作用。雖然現(xiàn)在仍然很初級,但對于傳統(tǒng)的應(yīng)用開發(fā)者來說,借助OpenCL開放的標(biāo)準(zhǔn)化平臺,已經(jīng)可以相對較為容易的上手,而在底層編程部分,仍然會通過FPGA廠商的專用工具進(jìn)行HDL編譯,再寫入FPGA。此外,F(xiàn)PGA廠商也在像NVIDIA那樣,提供自己的集成開發(fā)環(huán)境(IDE),它的作用相當(dāng)于CUDA之于GPGPU,為開發(fā)者提供更完整的工具包,加速FPGA的編程。比如賽靈思的 SDAccel開發(fā)環(huán)境,就可為賽靈思的FPGA加速OpenCL、C和C++內(nèi)核的開發(fā)與部署。相應(yīng)的CAPI-FPGA加速卡廠商,也會提供底層平臺,方便開發(fā)者基于自己的板卡進(jìn)行AFU開發(fā)。比如恒揚科技就提供了NPL和相關(guān)的SDK,可以讓開發(fā)者專心于AFU的算法實現(xiàn)。
另一個典型的CAPI加速實例則是外置存儲加速,IBM基于CAPI控制卡+自己的FlashSystem全閃存陣列,提供了一套NoSQL數(shù)據(jù)引擎,由于CAPI將傳統(tǒng)的PCIe控制卡的I/O開銷省去,大大降低了系統(tǒng)延遲,成為KVS數(shù)據(jù)平臺更好的選擇。
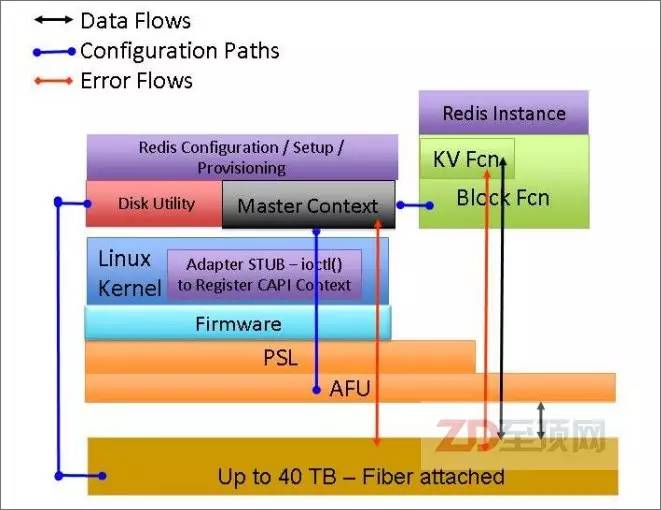
IBM基于支持CAPI+全閃存陣列而推出NoSQL數(shù)據(jù)加速引擎,配套全閃存陣列可以通過CAPI加速卡直接訪問應(yīng)用內(nèi)存空間,大大降低了數(shù)據(jù)傳輸?shù)难舆t,非常有利于單筆數(shù)據(jù)訪問量少,但I(xiàn)O密集的鍵值存儲(KVS,Key-Value Store)平臺

通過與非CAPI控制卡連接的性能相對比,可以看出由于CAPI連接不是傳統(tǒng)的I/O驅(qū)動模式,而近似于CPU直聯(lián),所以在IOPS性能與延遲性能上較傳統(tǒng)的PCIe控制卡有明顯的提升,不過如果是大數(shù)據(jù)塊傳輸,CAPI控制卡在總帶寬上可能會有一定劣勢,但到下一代CAPI這將不再是問題
第二代異構(gòu)計算與未來應(yīng)用愿景
如果說以GPGPU為主,大幅度提高系統(tǒng)浮點運算能力是第一代異構(gòu)加速計算的典型特征的話,我們現(xiàn)在可以基本總結(jié)出以FPGA為主,所謂的第二代異構(gòu)計算的一些重要特征:第一:具備緩存一致性和對等的內(nèi)存訪問能力,這是最為重要的特征,與第一代異構(gòu)計算有了本質(zhì)的不同,并對應(yīng)用編程具備了明顯的友好性;第二:基于FPGA可靈活配置加速模塊,毫無疑問,在第二代異構(gòu)計算中,F(xiàn)PGA將是一大主角,它本身靈活的可編程性為應(yīng)用加速提供了豐富的應(yīng)用場景;第三、它將隆重開啟整數(shù)運算加速的大門,隨著FPGA編程的便利性進(jìn)一步提高,F(xiàn)PGA的整數(shù)型加速將會迅速普及(當(dāng)然絕不是說FPGA不能用于浮點加速,只是看應(yīng)用比例),這對于當(dāng)前的大數(shù)據(jù)、海量視頻處理、圖像匹配等新興需求不謀而合,就像當(dāng)初GPGPU與科學(xué)計算的發(fā)展相得益彰一樣,第二代異構(gòu)計算將把相應(yīng)的整數(shù)型應(yīng)用的性能帶到新的高度。
當(dāng)然,看到這一趨勢的不僅僅是IBM與OpenPOWER,CPU巨頭英特爾以167億美元收購FPGA第二大廠Altera的用意也不言自明。在不久前結(jié)束的IDF15上(英特爾信息技術(shù)峰會2015美國站),英特爾正式發(fā)布了CPU通過QPI直聯(lián)FPGA的方案設(shè)計。
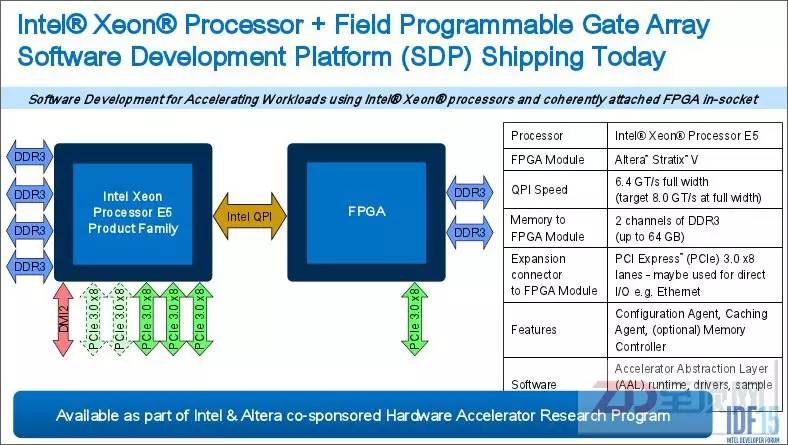
采用QPI接口與CPU互聯(lián),明擺著是沖著緩存一致性而來,這與CAPI的思路異曲同工,并且在服務(wù)器的配置上給出了新的可能(比如FPGA芯片Socket化或直接板載),這與CAPI有了明顯的不同,可謂各有利弊,但共同點都是開啟了第二代異構(gòu)計算的時代
當(dāng)越來越多的FPGA加速芯片以各種緩存一致性的方式接入系統(tǒng)之后,由于FPGA的SRAM高速編程模式,理論上講FPGA可以迅速的且無限次的更新內(nèi)置的AFU,以應(yīng)對不同的應(yīng)用加速需求。這就給我們打開了一個想像空間——能否像Docker管理容器鏡像那樣,基于云+端的概念建立起一個AFU鏡像的集散中心呢?事實上,OpenPOWER聯(lián)盟已經(jīng)在這么做了——建立AFU鏡像商店,并已經(jīng)落戶SuperVessel Cloud(超能云)之上,目前已經(jīng)有多個AUF鏡像可用選擇( https://crl.ptopenlab.com:8800/acceleration )。
OpenPOWER CAPI-FPGA加速卡AFU鏡像商店的更新流程(筆者猜想繪制,謹(jǐn)供參考)
屆時,任何相關(guān)的開發(fā)者、ISV都可以將自己針對某些具體的FPGA卡(經(jīng)CAPI認(rèn)證)所編寫的AFU鏡像(其實就是FPGA的編程配置文件),上傳至AFU商店供其他用戶免費或有償使用。相關(guān)的AFU用戶則可以像Docker那樣,根據(jù)自己應(yīng)用加速的需求與FPGA加速卡的型號,免費或付費下載相應(yīng)的AFU鏡像,通過全局的管理平臺,分發(fā)給指定服務(wù)器上的CAPI更新控制器,由后者與指定的FPGA加速卡(一臺服務(wù)器可以有多塊加速卡,選擇更新)PSL內(nèi)的AFU更新模塊一起加載AFU鏡像。加載的方式有兩種,一種是完整的FPGA重寫(所有的門電路重寫,包括PSL),另一種則是AFU單獨更新。前者需要重起服務(wù)器,而后者則可以在線動態(tài)更新。目前100萬門的FPGA的完整配置文件容量也就在50MB左右,由于是基于SRAM的硬件編程,100ms內(nèi)即可更新完畢,用戶幾乎沒有察覺,但服務(wù)器的加速功能就已經(jīng)完全改變了。
我們可以試想一下這樣的場景,對于某個內(nèi)置CAPI+FPGA加速器的服務(wù)器集群,可以靈活的根據(jù)工作負(fù)載的需求改變FPGA中的AFU模塊,讓這個集群迅速具備針對新負(fù)載的加速能力,這對于集群高效的多場景靈活復(fù)用顯然是很有幫助的,而這種模式也是GPGPU、DSP、ASIC等加速方式很難做到的。
展望未來,從某種角度上講,GPGPU與FPGA在未來的應(yīng)用系統(tǒng)中,將根據(jù)自身的特長有所側(cè)重。如果將CPU比作人的話,GPGPU更像是高級計算器,為人類提供強大的科學(xué)計算的能力,做好學(xué)術(shù)研究,而FPGA更像是為某類工作定制的效率工具,執(zhí)行大量固定而高度重復(fù)化的工作,大幅度提高人類的日常生活與工作效率(比如洗衣機、生產(chǎn)機器人),而人在未來更多的就是負(fù)責(zé)管理,用好計算器與效率工具——CPU的角色相信也會如此,隨著技術(shù)的不斷發(fā)展,更多的浮點與整數(shù)運算任務(wù)將會被GPGPU、FPGA、DSP、ASIC等不同的加速器所分擔(dān)。
進(jìn)化至第二代分布式計算?
基于上文所分析的CAPI+FPGA所展現(xiàn)出來的能力,如果我們進(jìn)一步從單服務(wù)器延展至整個分布式計算的架構(gòu),就可以從一個更為廣闊的全局視角來分析第二代異構(gòu)計算所帶來的關(guān)鍵影響。不久前,IBM提出的“第二代分布式計算”理念也正是基于這一全局的層次來建立的(據(jù)說在9月16日會召開發(fā)布會進(jìn)行專門的闡述 )。
IBM中國研究院的高級研究員陳飛表示,IBM提出的第二代分布式計算有四個重要的特征,第一個特征:加速器的軟硬件接口有統(tǒng)一的接口規(guī)范,以便于更好的協(xié)同管理與普適(第一代分布式計算的接口標(biāo)準(zhǔn)較為統(tǒng)一,畢竟只有CPU本身,相對更標(biāo)準(zhǔn)化),這方面CAPI就是一個標(biāo)準(zhǔn)化接口的嘗試。第二個特征:加速器可以動態(tài)地在線發(fā)現(xiàn)以及加載。比如不需要系統(tǒng)的重啟,但現(xiàn)在的加速器如果要改變功能,一般都要要求重啟,或者是重啟一些軟件服務(wù),但CAPI+FPGA則沒有這個顧慮。第三個特征:分布式的系統(tǒng)要具備全局異構(gòu)資源的調(diào)度能力,也就是說它能決定應(yīng)用是運行在一個具有加速器的計算節(jié)點上,還是跑在一個普通的純CPU的計算節(jié)點上。第四個特征:應(yīng)該軟件本身,具備兼容CPU運行模式和異構(gòu)硬件運行模式的能力。

NVIDIA推出NVLINK互聯(lián)總線,除了可作為GPU之間的互聯(lián)外,還可用于CPU與GPU的互聯(lián),并也將具備緩存一致性的內(nèi)存訪問能力。IBM的POWER9處理器(預(yù)計2017年下半年發(fā)布)將具備這一接口,這就意味著在POWER9平臺上NVIDIA的GPU也會獲得與CAPI同樣的對等訪問能力,這樣的GPGPU加速能力也將是POWER9獨有的(在英特爾x86平臺上,與CPU的互聯(lián)連接仍然是傳統(tǒng)的PCIe模式,NVLINK僅用于NVIDIA GPU之間的互聯(lián)),對IBM所提出的第二代分布式計算理念無疑是一個有力支撐
從以上定義中,我們可以看出,正是CAPI+FPGA所具備的一些關(guān)鍵特性(緩存一致性、在線更新性、AFU替換能力等)為IBM所提出的第二代分布式計算打下了理論基礎(chǔ)。當(dāng)然,對于這個定義,我仍然有一些異議,畢竟從總體上講,這個分布式處理的基礎(chǔ)架構(gòu)與應(yīng)用分布處理的模式,和第一代相比并沒有本質(zhì)的不同,更多是分布式節(jié)點上處理模式的創(chuàng)新,并且由于加速體系標(biāo)準(zhǔn)的更加多樣化,也讓其普適性受到懷疑,除非有非常強大的全局管理平臺來屏蔽掉底層的硬件差異性,否則全局上的“加速孤島”現(xiàn)象不可避免(雖然對于具體的用戶來說,這可能不是問題)。
但是不管怎樣,第二代異構(gòu)計算的模式,的確打開了我們的想像空間,它是否真的帶來理想中的第二代分布式計算體系,還有賴于IBM、英特爾以及加速器、方案集成等前沿廠商的共同努力!不過,可以肯定的是,不管這種新興的處理模式將如何稱謂,它對于新時代下的信息處理平臺(大數(shù)據(jù)分析、物聯(lián)網(wǎng)、人工智能、機器學(xué)習(xí)等)所帶來的明顯幫助,以及為最終用戶所創(chuàng)造的巨大價值,都將是毋庸置疑的!
-
處理器
+關(guān)注
關(guān)注
68文章
19396瀏覽量
230722 -
賽靈思
+關(guān)注
關(guān)注
32文章
1794瀏覽量
131423 -
異構(gòu)計算
+關(guān)注
關(guān)注
2文章
102瀏覽量
16323
發(fā)布評論請先 登錄
相關(guān)推薦
【一文看懂】什么是異構(gòu)計算?

【AD新聞】賽靈思新CEO訪華繪藍(lán)圖,7nm ACAP平臺要讓CPU/GPU難企及
異構(gòu)計算在人工智能什么作用?
什么是異構(gòu)并行計算
異構(gòu)計算的前世今生
異構(gòu)計算芯片的機遇與挑戰(zhàn)
異構(gòu)計算的兩大派別 為什么需要異構(gòu)計算?
異構(gòu)計算,你準(zhǔn)備好了么?
賽靈思將在中國高峰論壇上展示自適應(yīng)加速卡--Alveo
賽靈思公司宣布了采用HBM和CCIX技術(shù)的細(xì)節(jié)
賽靈思將與英偉達(dá)英特爾展開FPGA芯片大戰(zhàn)
揭秘賽靈思計算平臺ACAP技術(shù)細(xì)節(jié)
賽靈思最新SmartLynq+模塊,讓秒級迭代成為現(xiàn)實
異構(gòu)平臺設(shè)計方法 探索賽靈思Versal ACAP設(shè)計方法論





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論