 GitHub上現在托管有超過300種編程語言
GitHub上現在托管有超過300種編程語言
OctoLingua的目標是提供一種服務,支持從多個粒度級別(從文件級別或片段級別到潛在的行級語言檢測和分類)進行強大可靠的語言檢測。最終,該服務可以支持代碼搜索和共享、語法高亮顯示和差異渲染等,旨在支持開發人員進行日常開發工作,同時幫助編寫高質量的代碼。
GitHub上現在托管有超過300種編程語言。從最廣泛使用的語言比如Python,Java、Javascript等,到一些非常非常小眾的語言例如Befunge,應有盡有。
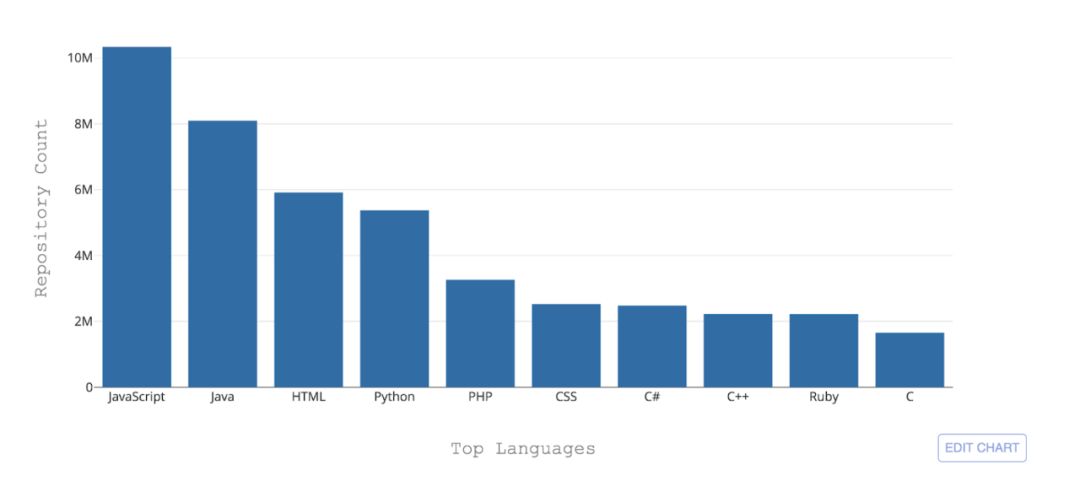
但豐富的語種帶來的一個挑戰就是,如何即時鑒別它們?這影響到如何更好的搜索、發現其中的安全漏洞或者采取什么樣的語法高亮。
而且編程語言識別起來,看似簡單實則非常困難。文件擴展名是一個非常重要的區分標準,但很多時候非常混亂。比如“.pl”, “.pm”, “.t”, “.pod”,都跟Perl有關系;而“.h”,C、C++、Objective-C也都有在用。
甚至還會出現沒有擴展名的情況,例如一些可執行腳本(curl,get,makefile等)。
Linguist已經可以完成84%的語言檢測
那么GitHub是怎么解決上述問題呢?GitHub高級數據科學家Kavita Ganesan首先介紹了目前GitHub官方使用的語言鑒別工具:Linguist。
Linguist是一個基于Ruby的應用程序,它使用多種策略進行語言檢測。比如利用命名約定和文件擴展名,考慮Vim或Emacs模型,以及文件頂部的內容(shebang)等。
Linguist通過啟發式方法,通過一個小樣本數據訓練的樸素貝葉斯分類器來進行語言消歧義。
雖然Linguist在文件級語言預測方面做得很好(準確率為84%),但是當文件使用非常特殊的命名約定時,準確率就大幅下降了。更重要的是,當遇到沒有提供文件擴展名的情況比如Gist、README文件、issue或者拉取請求中的代碼片段,Linguist就無能為力了。
人工智能幫助完成剩下的語言檢測工作
為了使語言檢測能夠更加健壯和可維護,GitHub又開發了一款名為OctoLingua的機器學習分類器,它基于人工神經網絡(ANN)架構,可以處理棘手場景中的語言預測。
該模型的當前版本能夠對GitHub托管的前50種語言進行預測,并在準確性和性能方面超越Linguist。
OctoLingua從頭開始使用Python + Keras,以及TensorFlow后端進行構建,非常準確、健壯且易于維護。
數據源
OctoLingua的當前版本使用了從Rosetta Code檢索的文件和內部眾包的一組質量庫的訓練。語言集限制為GitHub上托管的Top 50。
Rosetta Code是一個出色的入門數據集,因為它包含用不同編程語言表示的相同任務的源碼。例如,生成Fibonacci序列的任務可以用C、C ++、CoffeeScript、D、Java、Julia等表示。
但是,跨語言的覆蓋范圍并不統一,其中某些語言只有少量文件而某些文件的填充程度過于稀疏。因此,需要增加一些額外來源的訓練集,以提高語言覆蓋率和性能。
目前添加新語言的流程現已完全自動化,以編程方式從GitHub上的公共倉庫收集源碼。選擇滿足最低資格標準的倉庫,例如具有最小數量的分支,以及涵蓋目標語言和涵蓋特定文件擴展名。
對于此階段的數據收集,使用Linguist的分類確定倉庫的主要語言。
特點:利用先驗知識
傳統上,對于神經網絡的文本分類問題,通常采用基于存儲器的體系結構,例如遞歸神經網絡(RNN)和長短期記憶網絡(LSTM)。
但是,鑒于編程語言在詞匯、評論風格、文件擴展名、結構、庫導入風格和其他微小差異,GitHub選擇了一種更簡單的方法:通過以表格形式提取某些相關功能來利用所有這些信息,并投喂給分類器。目前提取的功能如下:
每個文件的前五個特殊字符
每個文件前20個令牌
文件擴展名
存在源碼文件中常用的某些特殊字符如冒號、花括號和分號
人工神經網絡(ANN)模型
上述特征作為使用具有Tensorflow后端的Keras構建的雙層人工神經網絡的輸入。
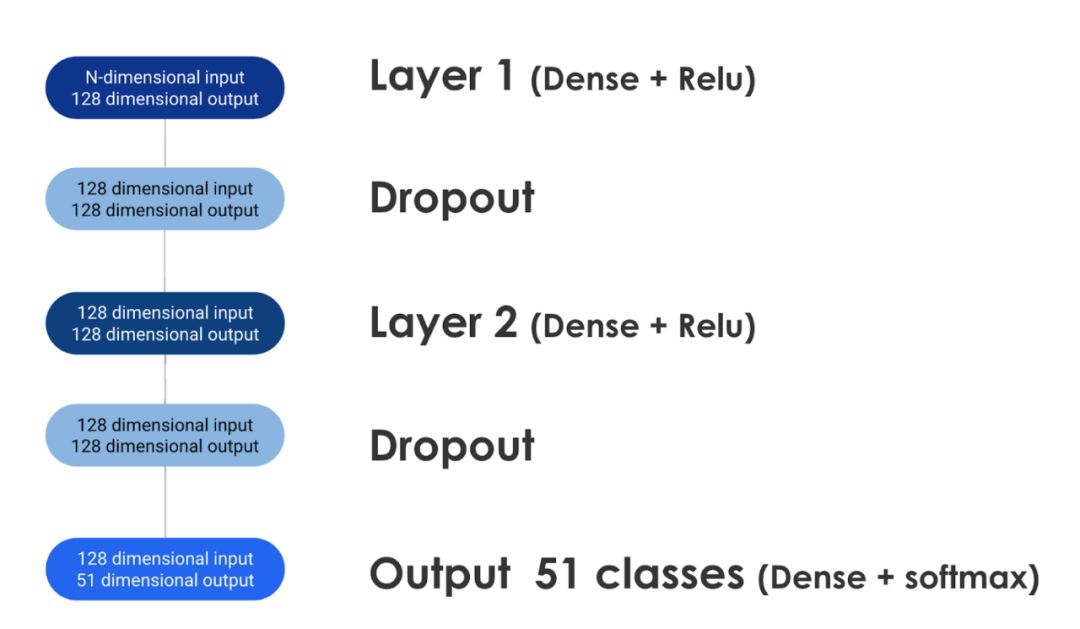
下圖顯示特征提取步驟為分類器生成n維表格輸入。當信息沿著網絡層移動時,它通過dropout正則化并最終產生51維輸出,該輸出表示給定代碼在前50種GitHub語言中每一種寫入的預測概率加不寫入的概率。
GitHub使用90%的數據集進行大約8個epochs的訓練。此外,在訓練步驟中從訓練數據中刪除了一定百分比的文件擴展名,以鼓勵模型從文件的詞匯表中學習,而不是過度填充文件擴展功能。
基準
下圖顯示了在同一測試集上計算的OctoLingua和Linguist的F1得分(精確度和召回之間的調和平均值)。
這里展示三個測試。第一個是測試集不受任何干預;第二個測試使用同一組測試文件,刪除了文件擴展名信息;第三個測試也使用相同的文件集,但這次文件擴展名被加擾,以便混淆分類器(例如,Java文件可能有“.txt”擴展名、Python文件可能具有“.java”)擴展名。
在測試集中加擾或刪除文件擴展名的目的是評估OctoLingua在刪除關鍵功能或誤導時對文件進行分類的穩健性。不嚴重依賴擴展的分類器對要點和片段進行分類非常有用,因為在這些情況下,人們通常不提供準確的擴展信息(例如,許多與代碼相關的文件具有.txt擴展名)。
下表顯示了OctoLingua如何在各種條件下保持良好的性能,表明該模型主要從代碼的詞匯表中學習,而不是從元信息(即文件擴展名)中學習。但是沒有擴展名的話Linguist完全無法鑒別。

上圖是OctoLingua與Linguist在同一測試集上的表現。
在訓練期間刪除文件擴展名的效果
如前所述,在訓練期間,從訓練數據中刪除了一定百分比的文件擴展名,以鼓勵模型從文件的詞匯表中學習。下表顯示了模型在訓練期間刪除了不同分數的文件擴展名的性能。

上圖在三個測試變體中刪除了不同百分比的文件擴展名后,OctoLingua的表現
請注意,在訓練期間沒有刪除文件擴展名的情況下,OctoLingua對沒有擴展名和隨機擴展名的測試文件的性能與常規測試數據相比差距很大。而一旦在刪除某些文件擴展名的數據集上訓練模型時,模型性能在修改的測試集上的差距就沒有那么大。
這證實了在訓練時從一小部分文件中刪除文件擴展名,會使分類器從詞匯表中學到更多。它還表明,文件擴展功能雖然具有高度預測性,但卻傾向于支配并阻止將更多權重分配給內容。
添加新語言支持
在OctoLingua中添加新語言非常簡單。它首先獲取新語言的大量文件,這些文件分為訓練和測試集,然后通過預處理器和特征提取器運行。這個新的訓練和測試裝置被添加到現有的訓練和測試數據庫中。新的測試裝置允許驗證模型的準確性是否仍然可以接受。

上圖使用OctoLingua添加新語言、
未來計劃
截至目前,OctoLingua正處于“先進的原型設計階段”。我們的語言分類引擎已經強大且可靠,但還不支持我們平臺上的所有編碼語言。除了擴大語言支持 - 這將是相當簡單的 - 我們的目標是在各種粒度級別啟用語言檢測。我們當前的實現已經允許我們通過對機器學習引擎的一些小修改來對代碼片段進行分類。將模型帶到可以可靠地檢測和分類嵌入式語言的階段并不是太遙遠。
我們也在考慮開源我們模型的可能性,如果您有興趣,我們很樂意聽取社區的意見。
-
編程語言
+關注
關注
10文章
1947瀏覽量
34848 -
人工智能
+關注
關注
1792文章
47497瀏覽量
239214 -
GitHub
+關注
關注
3文章
473瀏覽量
16503
原文標題:GitHub機器學習代碼分類器:僅憑代碼輕松鑒別300種編程語言
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
gitee 支持的編程語言有哪些
gitee 與 GitHub 的比較
Triton編譯器支持的編程語言
Gitee:玩轉代碼托管與協作的高效指南
超級干貨!本地搭建代碼托管平臺Gitea






 工商網監
工商網監
評論