 簡化版的XLNet在PyTorch Wrapper實現
簡化版的XLNet在PyTorch Wrapper實現
XLNet雖然好用,但實在太費錢了!近日,一位韓國小哥成功將簡化版的XLNet在PyTorch Wrapper實現,批規模僅為1,不再依賴谷歌爸爸的巨額算力,讓“窮人”也能用得起。
不久前,谷歌大腦和CMU聯合團隊提出面向NLP預訓練新方法XLNet,性能全面超越此前NLP領域的黃金標桿BERT,在20個任務上實現了性能的大幅提升,刷新了18個任務上的SOTA結果,可謂全面屠榜。
論文地址:
https://arxiv.org/pdf/1906.08237.pdf
XLNet性能確實強大,不過還是要背靠谷歌TPU平臺的巨額算力資源。有網友做了一下簡單統計,按照論文中的實驗設計,XL-Large用512 TPU chips訓練了4天,也就是說,訓練時的總計算量是BERT的5倍。語料規模是BERT-large的10倍。

要知道BERT作為谷歌的親兒子,其訓練量和對計算資源的需求已經讓很多人望塵莫及。現在XLNet又來了個5倍,讓人直呼用不起。
這么強勁的XLNet,只能看著流口水卻用不起,豈不是太遺憾了?
土豪有土豪的用法,窮人有窮人的訣竅。最近有個韓國小哥就成功將XLNet挪到了Pytorch框架上,可以在僅使用小規模訓練數據(批規模=1)的情況下,實現一個簡單的XLNet實例,并弄清XLNet架構的預訓練機制。他將實現方案放在了GitHub上。
要使用這個實現很簡單,只需導入如下代碼:
$ git clone https://github.com/graykode/xlnet-Pytorch && cd xlnet-Pytorch# To use Sentence Piece Tokenizer(pretrained-BERT Tokenizer)$ pip install pytorch_pretrained_bert$ python main.py --data ./data.txt --tokenizer bert-base-uncased --seq_len 512 --reuse_len 256 --perm_size 256 --bi_data True --mask_alpha 6 --mask_beta 1 --num_predict 85 --mem_len 384 --num_step 100
接下來對實現方法和超參數設置的簡單介紹,首先貼出XLNet論文中給出的預訓練超參數:
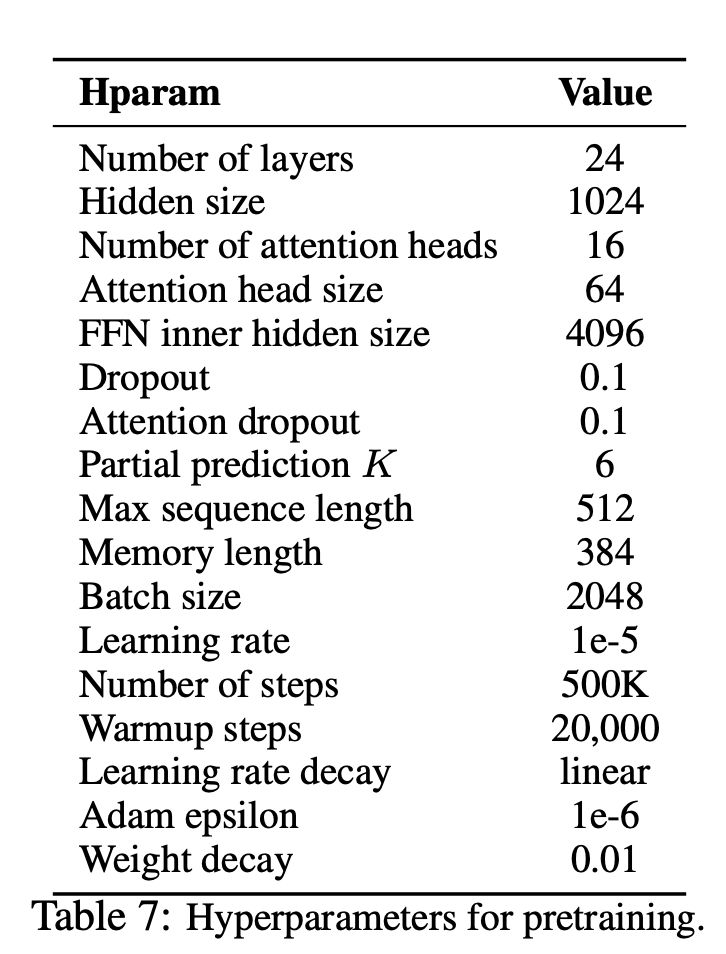
然后,作者給出了PyTorch框架下XLNet實現的超參數調節選項如下:
—data(String): 使用文本文件訓練,多行文本也可以。另外,將一個文件視為一個批張量。默認值: data.txt
—tokenizer(String):目前僅使用【這里】的Tokenizer作為子詞的Tokenizer(即將編入句子部分),這里可以選擇bert-base-uncased/bert-large-uncased/bert-base-cased/bert-large-cased四種Tokenizer。
默認值:bert-base-uncased
—seq_len(Integer): 序列長度。
默認值 :512
—reuse_len(Interger): 可作為記憶重復使用的token數量。可能是序列長度的一半。
默認值 :256
—perm_size(Interger): 最長排列長度。
默認值:256
--bi_data(Boolean): 是否設立雙向數據,如設置為“是”,biz(batch size) 參數值應為偶數。
默認值:否
—mask_alpha(Interger): 多少個token構成一個group。
默認值:6
—mask_beta(Integer):在每個group中需要mask的token數量。
默認值:1
—num_predict(Interger) :
要預測的token數量。在XLNet論文中, 這表示部分預測。
默認值:85
—mem_len(Interger): 在Transformer-XL架構中緩存的步驟數量。
默認值:384
—number_step(Interger):步驟(即Epoch)數量.。
默認值:100
XLNet:克服BERT固有局限,20項任務性能強于BERT
XLNet是一種基于新型廣義置換語言建模目標的新型無監督語言表示學習方法。此外,XLNet采用Transformer-XL作為骨架模型,在長時間環境下的語言任務中表現出非常出色的性能,在多項NLP任務性能上超越了BERT,成為NLP領域的新標桿。

關于XLNet中的一些關鍵詞
1、自回歸模型與自動編碼模型
自回歸(AR)模型
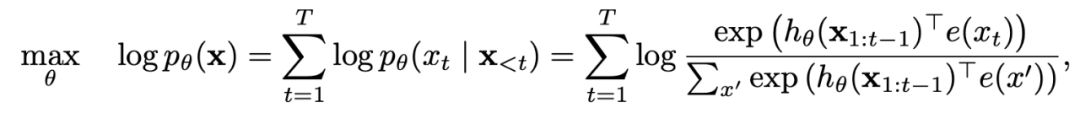
自動編碼(AE)模型
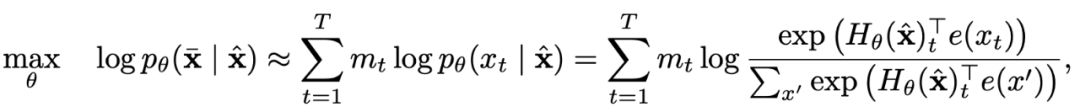
2、部分預測的排列語言建模
排列語言建模
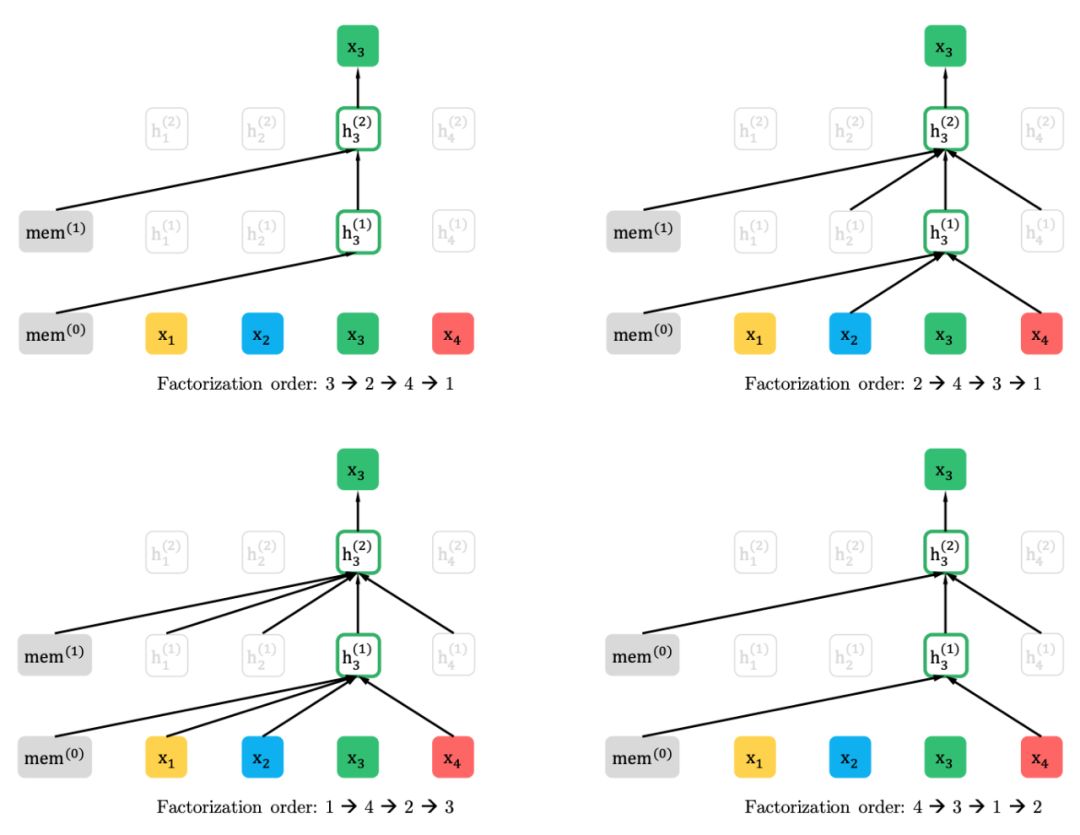
部分預測
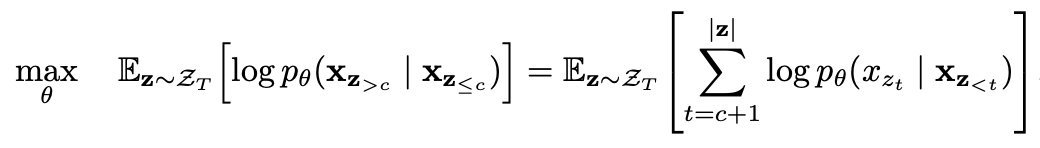
3、具有目標感知表示的雙向自注意力模型
雙向自注意力模型
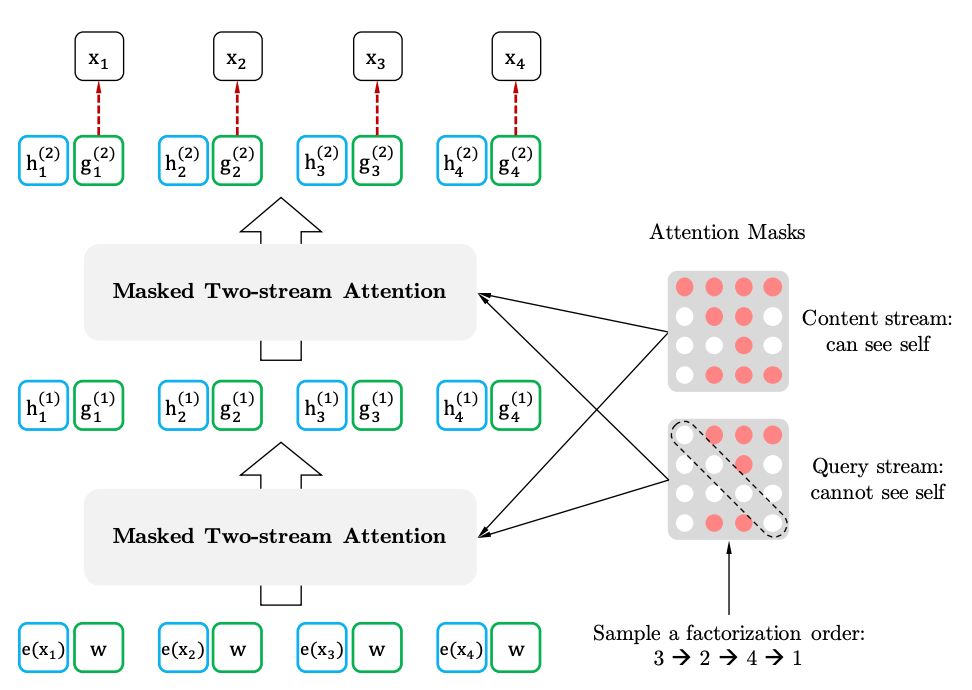
目標感知表示
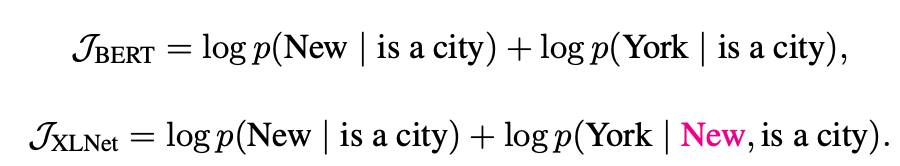
-
谷歌
+關注
關注
27文章
6176瀏覽量
105678 -
nlp
+關注
關注
1文章
489瀏覽量
22064 -
pytorch
+關注
關注
2文章
808瀏覽量
13283
原文標題:XLNet太貴?這位小哥在PyTorch Wrapper上做了個微縮版的
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
利用Arm Kleidi技術實現PyTorch優化

PyTorch 數據加載與處理方法
使用PyTorch在英特爾獨立顯卡上訓練模型






 工商網監
工商網監
評論