 你的照片居然可以存儲在氨基酸分子溶液里!
你的照片居然可以存儲在氨基酸分子溶液里!
上周,新智元報道了DNA數據存儲的新聞,不僅16G的維基百科能夠存儲到一個DNA分子上,就連存儲全球的數據也只需要1kg DNA。
而近期,布朗大學的研究人員受此啟發并發現:DNA并不是唯一可以用于數字存儲的分子。事實證明,含有糖、氨基酸和其他小分子的溶液也可以取代硬盤。
在DNA的下游,代謝組(metabolome)是一個信息豐富的分子系統,它具有不同的化學維度,可以用來存儲和處理信息。
為了證明小分子后基因組( small-molecule postgenomic)數據存儲的原理,研究人員利用機器人液體處理將數字信息寫入化學混合物,并利用質樸分析提取數據。
研究人員還提出了幾個存儲在合成代謝體中的千字節(kilobyte-scale)級圖像數據集,使用多質量邏輯回歸可以對其進行解碼,其精度超過99%。
布朗大學工程學院教授、該研究的高級作者Jacob Rosenstein說:
這是一個概念驗證,我們希望讓人們考慮使用更廣泛的分子來存儲信息,在某些情況下,我們在這個研究中使用的小分子可以比DNA擁有更大的信息密度。
另一個潛在的優勢在于,多種小分子可以相互反應形成新的化合物。這為分子系統創造了潛力,不僅可以存儲數據,還可以操縱數據——在代謝物混合物中執行計算。
縮略圖大小的圖像,存儲在比DNA還小的分子上
為了上述的想法,研究人員用常見代謝物做了一種混合物——含有糖、氨基酸和其他小分子的溶液,人類和其他生物利用這些小分子來消化食物和執行其他重要的化學功能。
他們的想法是利用混合物中特定代謝物的存在或不存在作為二進制的1和0來編碼數字信息。
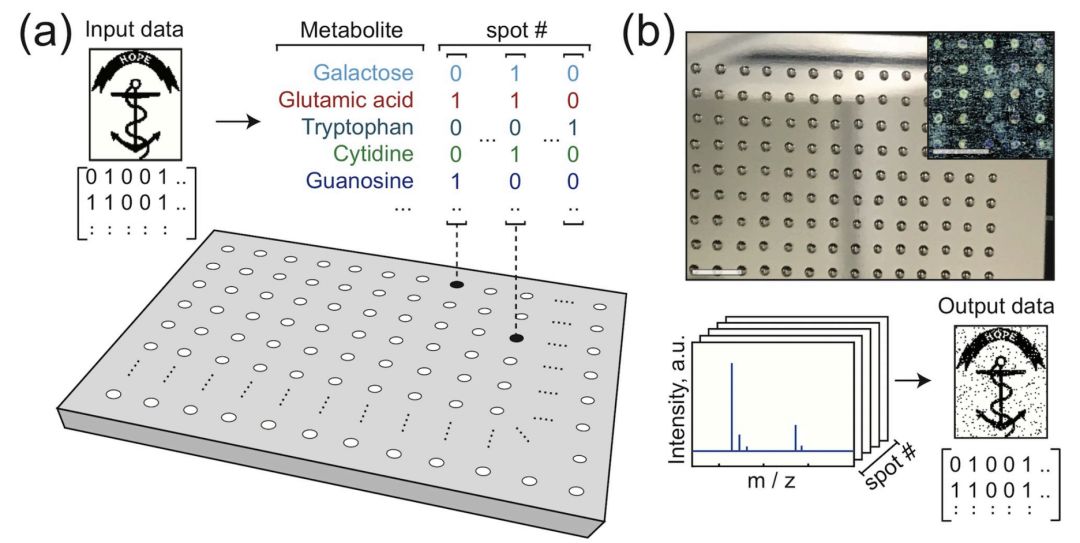
圖1 該方法將數字數據的1和0映射到溶液中特定分子的存在或不存在。研究人員使用該方案對圖像文件進行了編碼。
例如,為了生成北山羊的圖像,研究小組使用了6種不同代謝物的混合物,這些混合物由液體處理機器人點綴在一個小金屬板上。他們總共制作了1024個液滴,每個液滴中6種代謝物或缺失或存在,提供了足夠的二進制信息來編碼6142像素的圖像。
然后,金屬板被烘干,留下微小的代謝物分子點,每個點都保存著數字信息。
然后,這些數據可以用質譜儀讀出,質譜儀可以識別存在于板上每個點的代謝物,并對數據進行解碼。
研究人員將這張貓的圖像保存在小分子溶液中
研究人員通過用質譜儀分析每個點的化學成分,能夠以99%的準確率檢索到這些數據。他們還用12種代謝物的混合物,解碼了一張分辨率更高的貓的照片。
密集數據
他們使用手掌大小的標準板來編碼縮略圖大小的圖像。但是據Rosenstein介紹,代謝物存儲設備的物理尺寸可以更小。
代謝物分子比DNA和蛋白質小得多,而且種類繁多。他說,這意味著它們可以比DNA更密集地表示少量數據。
Rosenstein說:“一旦數據被記錄下來,它們就不需要任何能量了。根據分子和環境條件的不同,這些數據可以保存數月或數年。”事實上,在極端溫度、壓力和機械力等條件下,分子存儲可能比電子存儲更穩定,這取決于分子的特性。
分子存儲還可以使離線存儲大量數據成為可能,而不是存儲在云中,從而防止黑客入侵。
到目前為止,Rosenstein和他的同事們發明的技術與電子計算機相比速度還比較慢。
研究人員指出,這種技術也有一些局限。例如,當多種代謝物分子被放在同一溶液中時,它們之間會發生化學反應,這可能導致錯誤或數據丟失。但這個bug最終可能成為一個功能。也許可以利用這些反應來操縱執行數據的計算。
Rosenstein表示:
與DNA相比,我們的代謝物數據具有較低的延遲,從而可以從頭到尾快速地讀寫數據集。”他也補充說 DNA 目前在編碼大型數據集方面有優勢。
這些想法在研究實驗室中使用已經可行,但我們需要加快速度,縮小分析硬件的尺寸,然后才能在實驗室外實施。
這類研究挑戰了人們在分子數據系統中所看到的可能性。DNA不是唯一可以用來存儲和處理信息的分子。認識到還有其他潛力巨大的可能性是令人興奮的。
實驗原料和方法
化學庫的制備
將36種不同代謝化合物的試劑級樣品(S1文件中的表A)在二甲基亞砜(DMSO,無水)中稀釋,標稱濃度均為25mM。將一些代謝物首先溶解在替代溶劑(去離子水,可選擇加入0.5M或1M的鹽酸)中,以促進化合物在DMSO中的溶解。將10μL每種化合物等分到384孔的微量培養板(Labcyte384LDV)上。
數據混合物的準備
在規格為76mm×120mm不銹鋼MALDI板上制備化學數據混合物。使用聲學液體處理器(LabcyteEcho 550型)將化合物從培養板轉移到MALDI板上。儀器標稱的單液滴體積為2.5nL,但為了降低液滴體積變化對結果的影響,通常每種化合物使用2滴(5nL)。液滴以標準的2.25mm點距排布,共計1536個位置(32×48)。
將化合物按編好的位置滴到MALDI板上之后,需要將MALDI基質材料添加到每個位置上。我們選擇9-氨基吖啶作為基質材料,因為它與代謝物庫能夠共存,它在小分子體系中具備低背景(low background)特征,同時支持正離子和負離子模式。將MALDI板放置在干燥環境中,大約在一夜時間即可完成結晶(最多10小時)。干燥后,可將板儲存在濕度控制柜中,或進行MALDI-FT-ICR質譜分析。
數據板的質譜分析
實驗中使用傅里葉變換離子回旋共振(FT-ICR)質譜儀(SolariX 7T,Bruker)分析結晶代謝物數據混合物。精確的成分結果是每個頻譜上的測量時間的函數。這些實驗中通常耗時0.5-1秒,產生的分辨精度<0.001Da。該儀器將連續測量48x32網格上的每種混合物的質譜。測定全部樣本只需要不到2個小時。
為了從質譜中讀取編碼數據,將代謝物存在的概率建模為多個預測質量的組合。利用多項邏輯回歸方法,考慮偏移量的自然指數,加上所有識別質譜信噪比之和,每個信噪比均與訓練的權重系數相乘。在給定每種代謝物的n個最佳峰值輸入的情況下,使用有限記憶BFGS算法來預測邏輯精度評分。
在實驗中,對所有代謝組合成分重復以上過程。
實驗結果:檢索準確率高達99%!
編寫合成代謝組分
我們的合成代謝組由36種化合物組成,包括維生素、核苷、核苷酸、氨基酸、糖和代謝途徑中間體。為了將數據寫入代謝物混合物中,我們使用聲學液體處理器以2.5nL的增量將純代謝物溶液傳輸到鋼制MALDI板上預先定義的位置。選擇2.25 mm節距網格,以與標準wellplate協議兼容。這產生了一個不同代謝物混合物的空間陣列,其中每種混合物中每個化合物的存在(或不存在)編碼一位信息。
在蒸發溶劑后,每個數據板包含多達1536個干燥點(圖1b),我們可以使用基質輔助激光解吸電離(MALDI)質譜(MS)進行分析。為了預先篩選合成代謝組中的每種化合物,在1400個獨特的點上,用36種代謝物的組合混合物寫出圖版。由于MALDI方案具有化學特異性,因此我們不希望在一組條件下,整個化合物庫具有相同的鑒定準確度。我們使用此預篩選來確定具有相同方案的每種代謝物的MS鑒定準確度。
代謝物混合物的離子回旋加速器質譜
使用傅里葉變換離子回旋共振(FT-ICR)質譜儀(SolariX 7T,Bruker)分析結晶混合物陣列。在FT-ICR MS中,脈沖RF激發離子進入周期軌道,其頻率由磁場強度和離子質量決定,這使得質量分辨率比飛行時間(ToF)更精細。儀器。在這些實驗中,質量分辨率通常為0.001Da。使用FT-ICR MS,即使它們的質量僅相差milli-Daltons ,也可以區分代謝物。
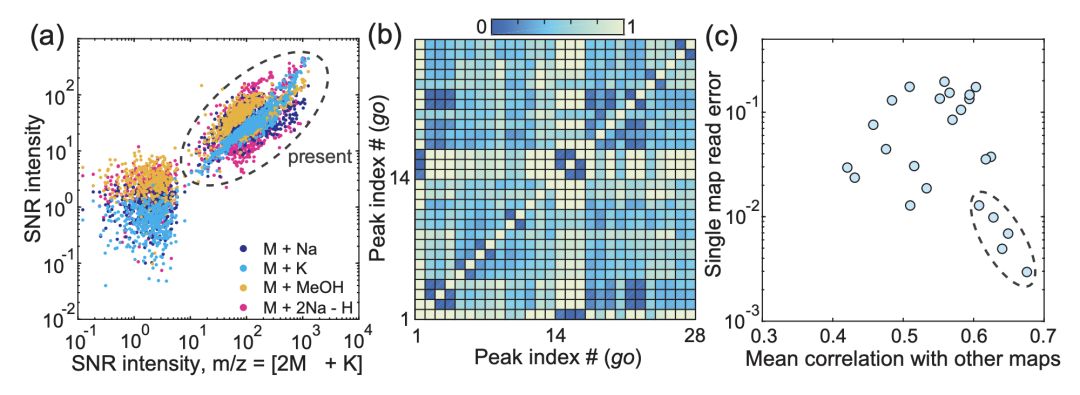
在圖2(a)中,顯示了包含鳥苷(go)和9-氨基吖啶(9A)基質的斑點的一個正離子MALDI-FT-ICR質譜。質子化的基質加合物在峰1和6(藍色)處鑒定,連同鳥苷的加合物,標記為(2:Na,3:K,4:2K-H和5:異丙醇(IPA)+ H)。觀察到的強度因加合物和種類而異,在圖2(b)中,在1024個點上顯示了第一個峰值(m / z = 195.0916±0.001處的質子化基質)的強度。
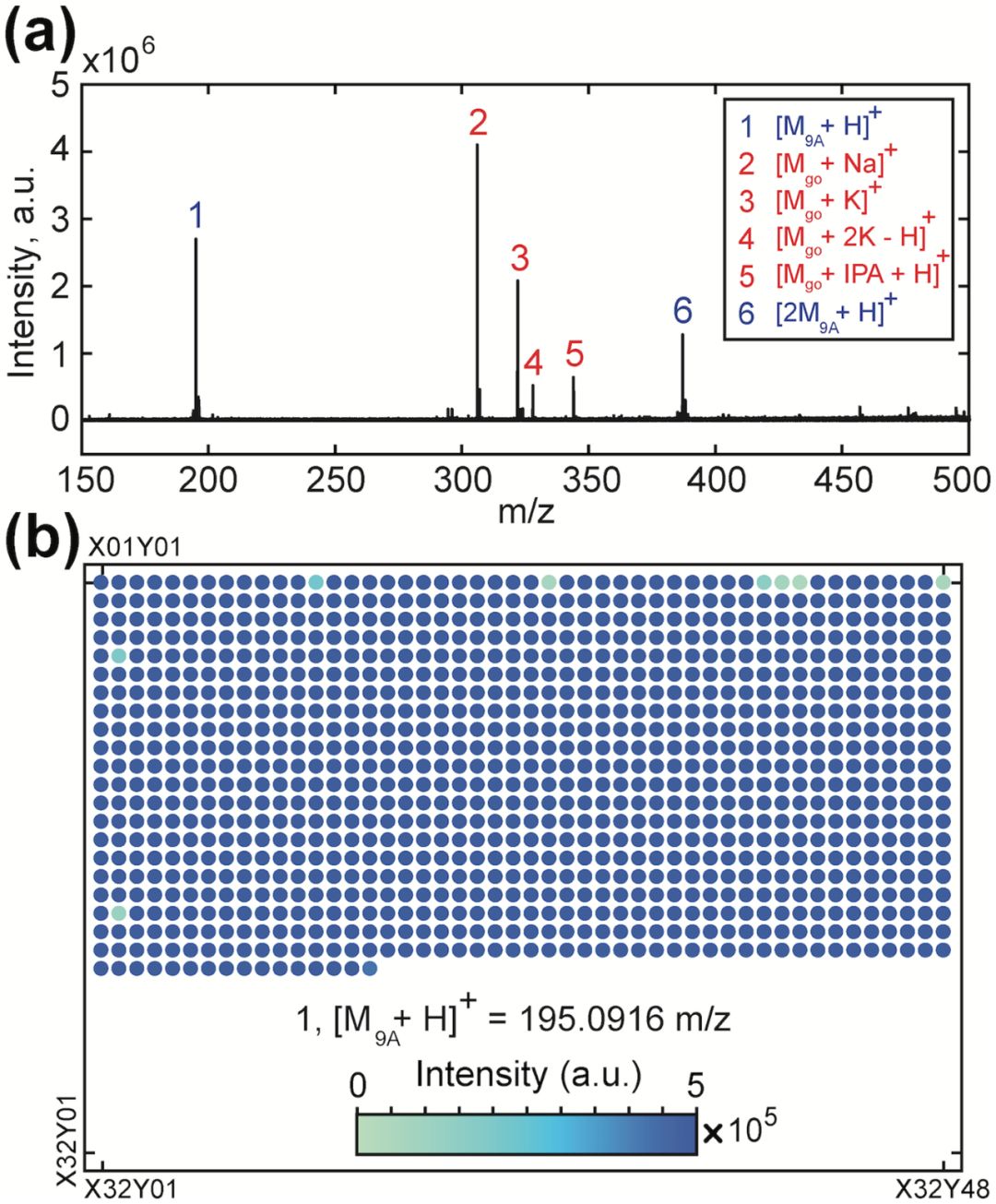
圖2.用質譜分析化學數據板。
許多開放獲取工具可用于代謝峰的檢測和MS質譜的分配。為了清楚地將質譜與二進制數據聯系起來,我們考慮了一個基本的檢測方案:如果代謝物的質量強度高于某個特定的閾值,則聲明它存在,并且其地址的二進制狀態設置為1(或0,如果它的質量峰值不存在)。該方法在圖2(b)中的1024個斑點中識別出1020個基質質子化峰(≈99.6%)。
作為初始演示,我們選擇了6種代謝物的庫子集,用于將Nubian ibex的6,142像素二進制圖像編碼為1024個混合物的陣列。偽隨機交織后,將數據映射到存在或不存在山梨醇(SO)、谷氨酸(GA)、色氨酸(TP)、胞苷(CD)、鳥苷(GO)和2-脫氧鳥苷水合物(GH)中。如方法中所述,使用FT-ICR-MS對板進行書寫和分析。
圖3a顯示了240個獨立點觀測到的質譜背景噪聲的空間圖和直方圖。在進一步分析之前,我們將每個質譜除以其背景σ,這樣可以更直接地比較多個位置的信號強度。信號強度是樣品制備、分析物和加合物的復雜函數。歸一化后,6種代謝物的目標峰顯示在圖3b中。第一行是其數據包含六位[1 0 0 0 0 0]的點,因此僅存在與第一代謝物(山梨糖醇)相關的m / z峰。類似地,顯示了五個其他“一次觸發”模式,可以無錯誤地解碼。
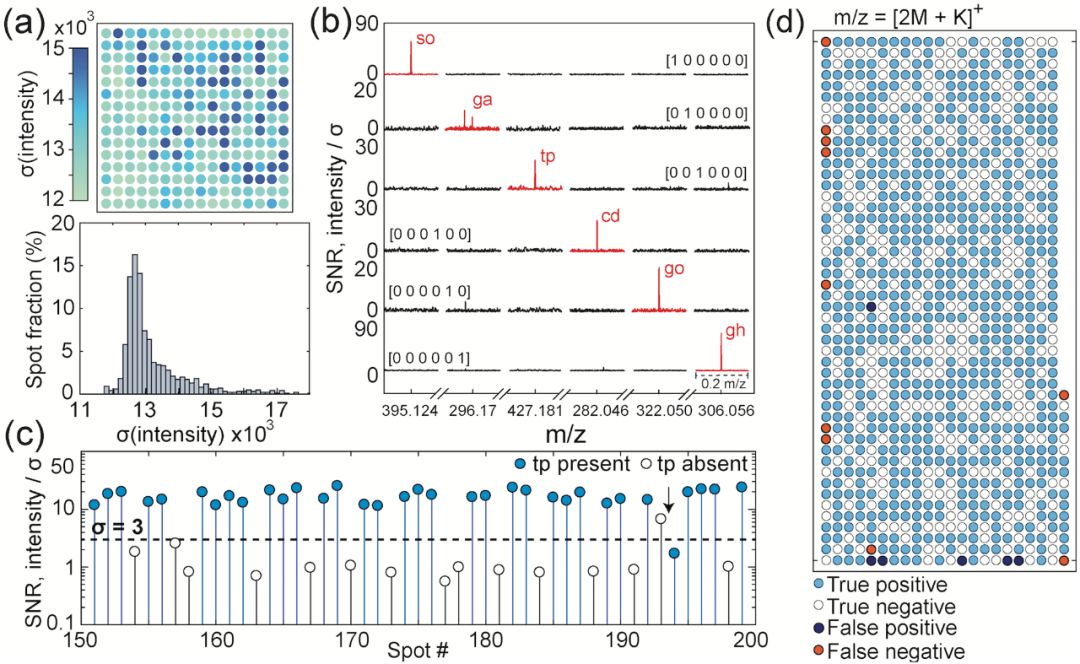
圖3.質譜背景和噪聲考慮因素。
選擇閾值3σ作為說明代謝物存在所需的強度。例如,如果我們檢查色氨酸[2Mtp+K]+質量(圖3c),我們發現該閾值產生96%的正確分類。如圖3d所示,還可以對板上的每個點顯示該檢測方案。板邊緣的誤差聚類表明MALDI激光位置和液滴點位置之間的微小偏差是誤差的來源。
數據板統計分析
在實踐中,一個化合物將與多個峰相關聯,并且具有不同的信噪比和用途。對于給定的代謝組,研究人員需要確定哪種m/z峰值最適合識別每個庫的元素。
每個高分辨率FT-ICR質譜包含?2×106 m/z 點。由于質譜空間的大部分是背景,因此首先將特征的數量減少到統計上有用的特征數量。而后研究人員測試了所有質譜的系綜平均值(ensemble average)中發現的1444個候選峰,用來確定m/z處的強度對編碼數據值的分類精度(圖 4a)。
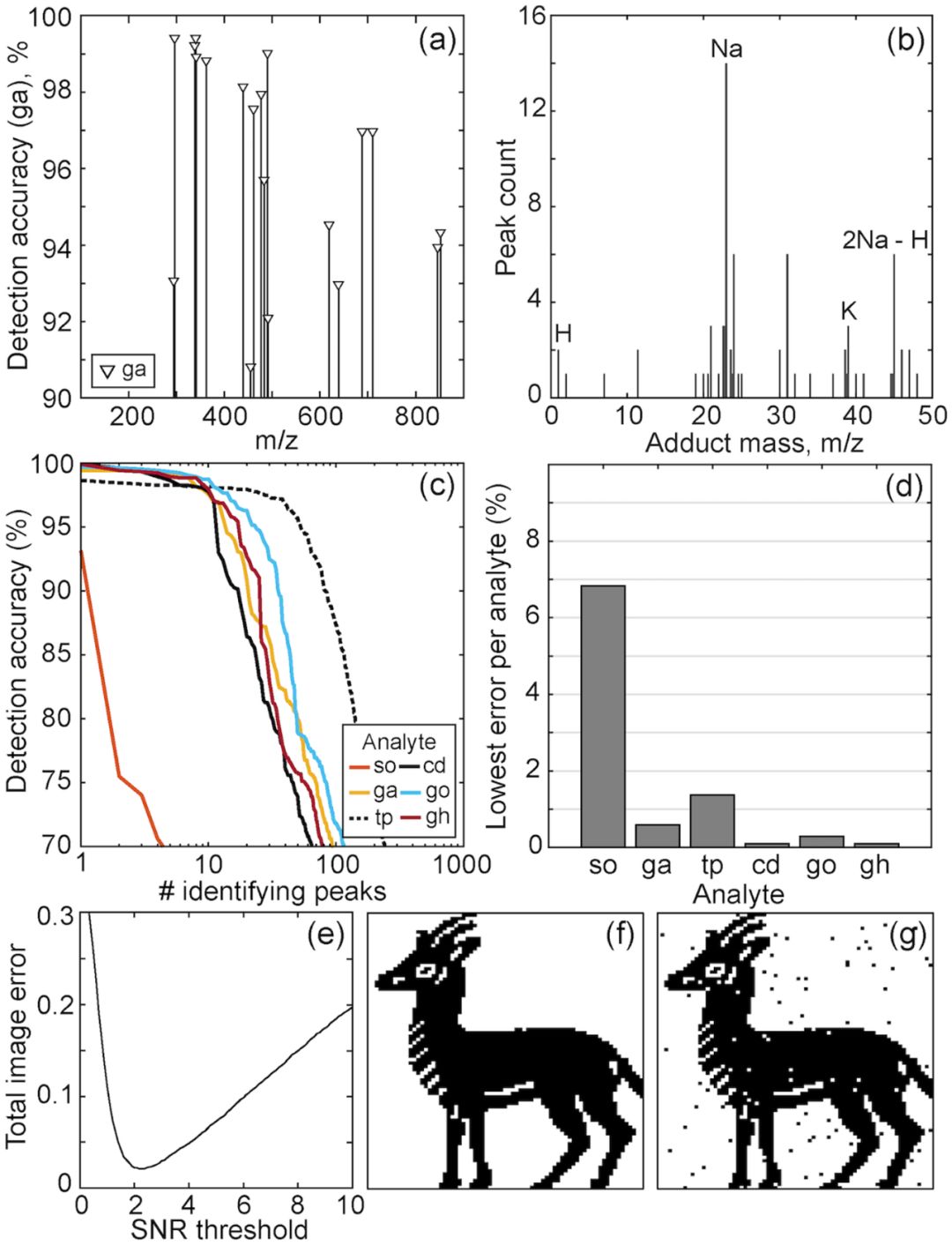
圖4
雖然這些峰值的識別沒有化學偏差,但許多特征可以歸因于已知的代謝物加合物離子。相關加合物質量的直方圖如圖4b所示。
達到70-100%范圍內檢測精度的峰數如圖4c所示。選擇每種代謝物的最佳表現峰值,并應用2.5σ的檢測閾值,足以恢復約2%累積讀/寫錯誤的數據(圖4e)。相應的輸入和輸出數據圖像如圖4f和4g所示。
利用邏輯回歸對多峰數據進行解碼
假設鑒別峰值是部分不相關的(如圖D所示),利用每個代謝組的多個m/z峰來尋求改進是合理的。這樣的策略將在更復雜的代謝組中變得越來越重要。
圖D
研究人員使用類似6kb ibex圖像類似的技術,從埃及墳墓中編碼了17424位的貓圖像(使用了1452個點),其中包含庫中12個代謝物子集的數據混合物(圖5a)。他們使用這些數據來擴展解碼方案,使其包含多個m/z特性。
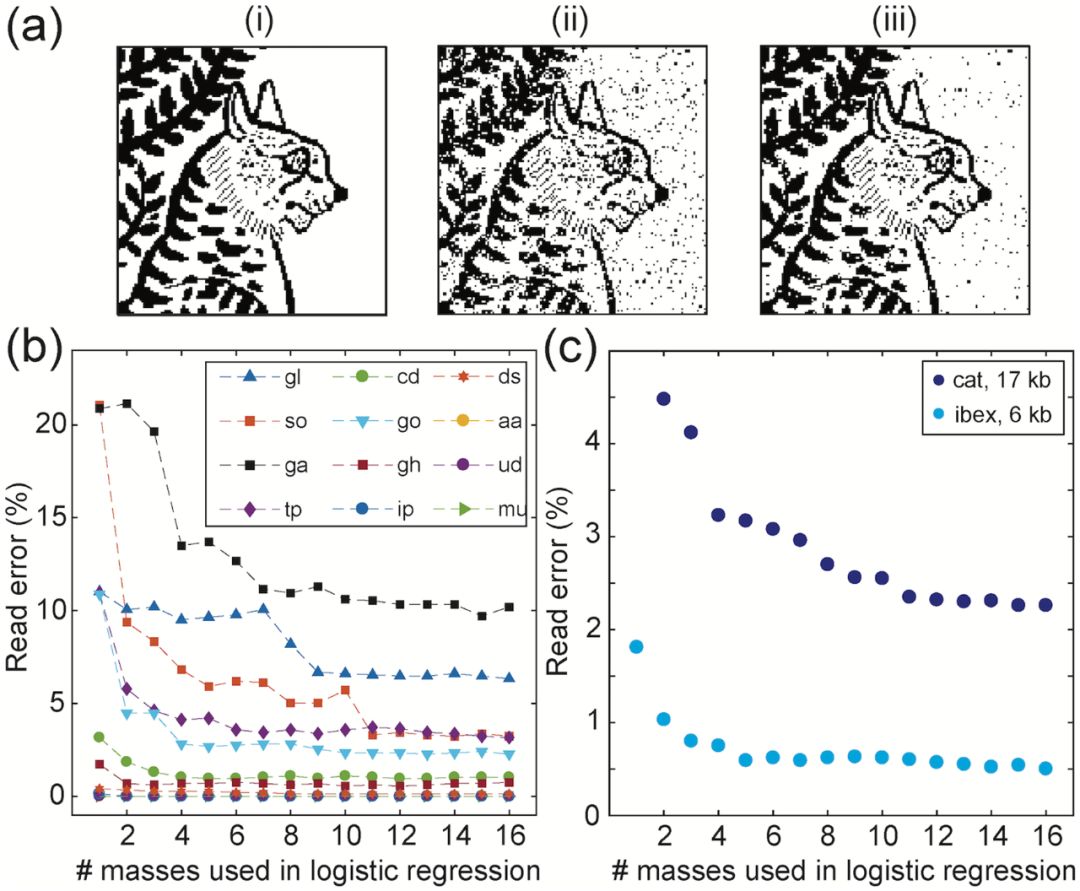
圖5
在確定一組統計鑒別峰之后,研究人員使用1到16個表現最好的峰進行邏輯回歸。多質量回歸對整個cat圖像的讀取準確率為97.7%(圖5c)。
圖4和圖5中的數據的累積讀取錯誤率顯示為邏輯回歸中使用的質量數的函數。
將這些技術應用于早期的ibex數據集,可以實現<0.5%的錯誤率。但是,重復測量斑點會導致數據丟失。研究人員還發現,每次連續讀取數據板都會增加<1%的誤差(圖E)。
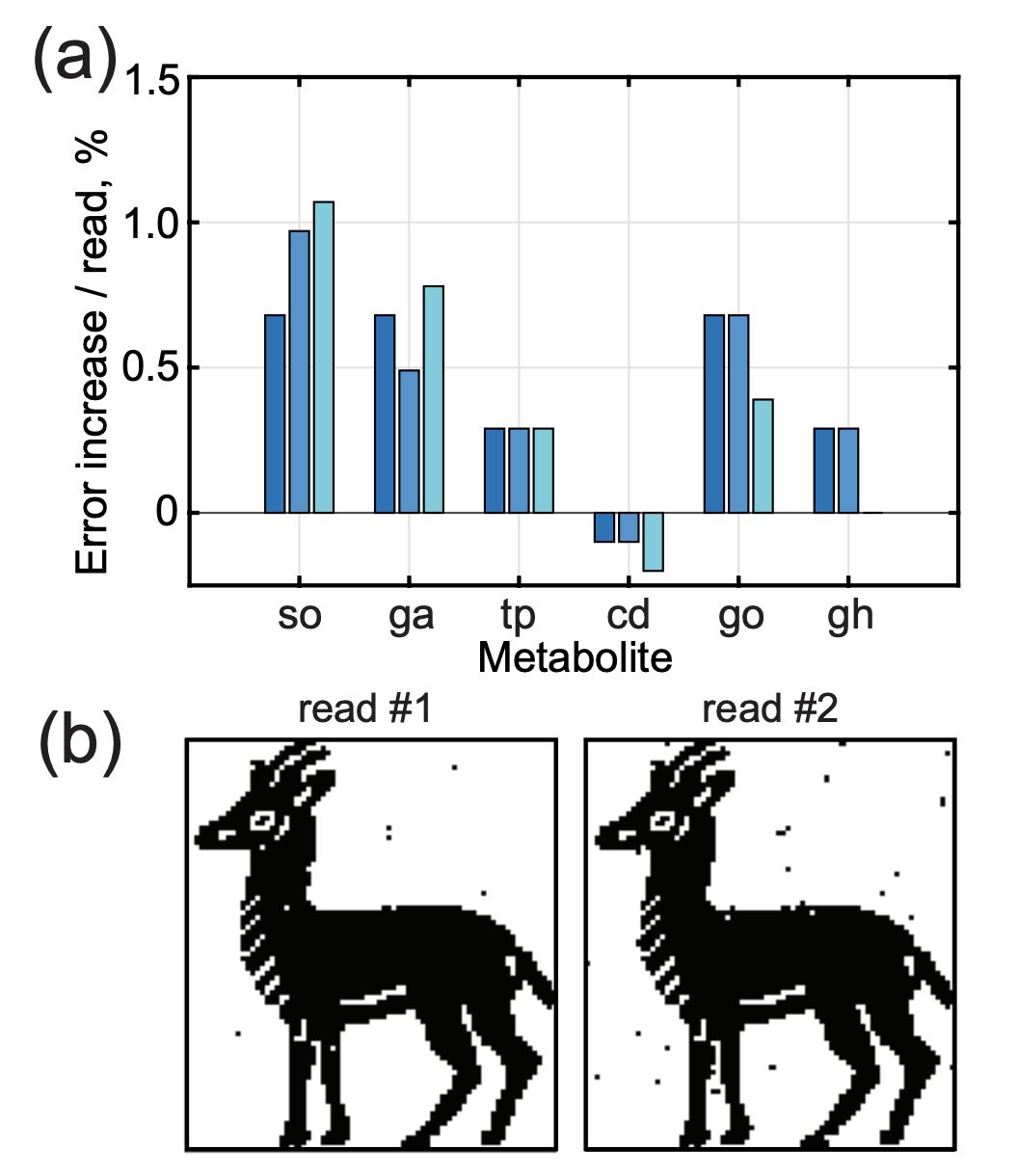
圖E
使用不同的板進行訓練可以獲得相同的精度而不會過度擬合(圖F)。
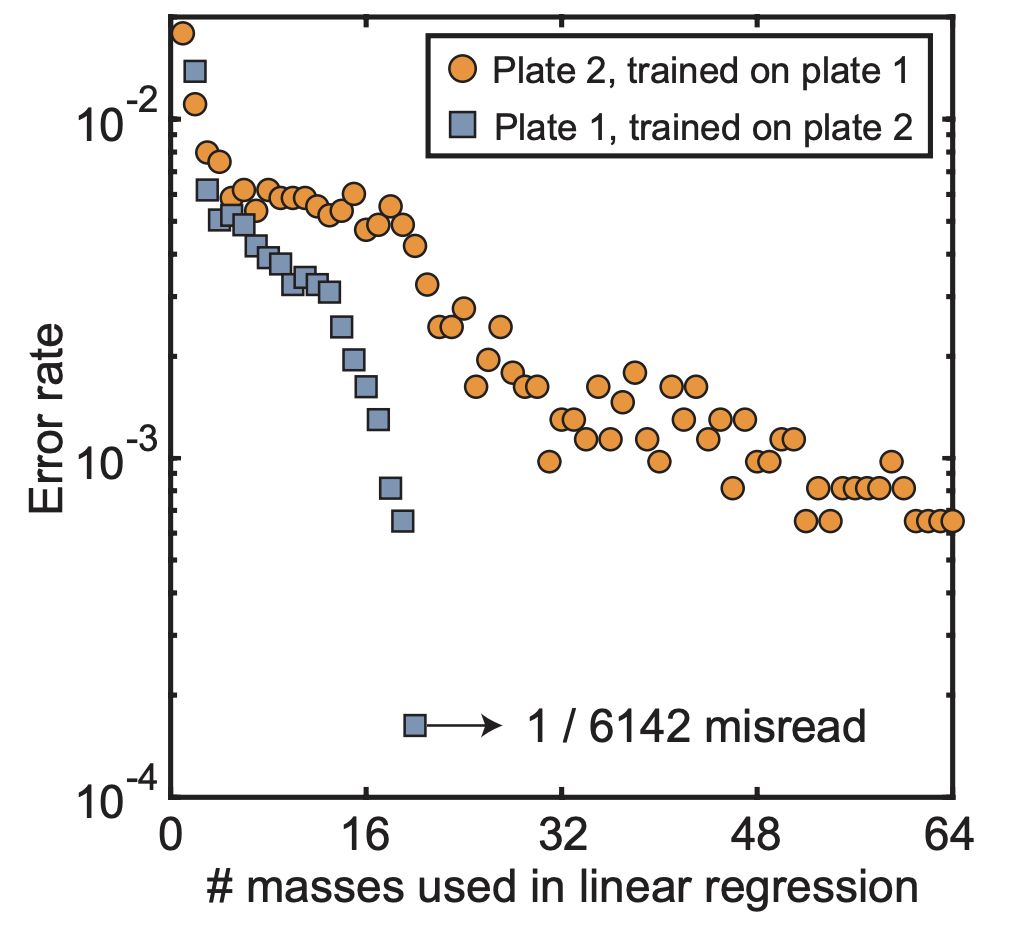
圖F
總而言之,上述實驗表明:代謝組是一種可行且強大的表示數字信息的媒介。
-
數據存儲
+關注
關注
5文章
971瀏覽量
50908 -
DNA
+關注
關注
0文章
243瀏覽量
31034
原文標題:比DNA存儲更可怕!你的照片居然可以存儲在氨基酸分子溶液里
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦

高分子半導體的特性與創新應用探索

EEPROM存儲器可以擦除指定區域嗎?
如何阻止氨水溶液換熱器管板腐蝕?新型防腐技術讓設備遠離腐蝕

ESP32S2可以在GPIO中斷里進行WIFI的數據發送操作嗎?
用于單分子無標記定量檢測的數字膠體增強拉曼光譜技術

洪亮團隊在生信期刊JCIM發布最新成果,蛋白質工程邁入通用人工智能時代
基于薄膜鈮酸鋰的高性能集成光子學研究

鈮酸鋰芯片與精密劃片機:科技突破引領半導體制造新潮流

如何估算S7-1500 CPU的裝載存儲區在SIMATIC存儲卡上的大小?
居然智慧家戰略發布,力合微PLC技術為智能家居革新

分子束外延(MBE)工藝及設備原理介紹





 工商網監
工商網監
評論