") 半小時(shí)學(xué)會PyTorch快速圖片分類
半小時(shí)學(xué)會PyTorch快速圖片分類
通過本教程,讀者將能夠在選擇的任何圖像數(shù)據(jù)集上,構(gòu)建和訓(xùn)練圖像識別器,同時(shí)充分了解底層模型架構(gòu)和訓(xùn)練過程。教程內(nèi)容包括數(shù)據(jù)提取、數(shù)據(jù)可視化、CNN、ResNets、遷移學(xué)習(xí)、結(jié)果解釋、微調(diào)等。
這是一篇長文教程,建議大家讀不完的話一定要收藏,利用閑暇時(shí)光將其讀完!更加歡迎將本文轉(zhuǎn)發(fā)給同學(xué)、朋友、同事等。
本文的目標(biāo)是能夠讓你可以在任何圖像數(shù)據(jù)集上構(gòu)建和訓(xùn)練圖像識別器,同時(shí)充分了解底層模型架構(gòu)和培訓(xùn)過程。
目標(biāo)讀者:任何研究圖像識別、或?qū)Υ祟I(lǐng)域感興趣的初學(xué)者
教程目錄:
數(shù)據(jù)提取
數(shù)據(jù)可視化
模型訓(xùn)練
結(jié)果解釋
模型層的凍結(jié)和解凍
微調(diào)
教程所使用的Jupyter notebook:
https://github.com/SalChem/Fastai-iNotes-iTutorials/blob/master/Image_Recognition_Basics.ipynb
更簡單直接的方式是登錄Google Colab:
https://colab.research.google.com/github/SalChem/Fastai-iNotes-iTutorials/blob/master/Image_Recognition_Basics.ipynb
注意:使用Google Colab之前,確保你做了如下設(shè)置
Runtime -> Change runtime type -> Hardware Accelerator -> GPU
設(shè)置IPython內(nèi)核并初始化
加載依賴庫

初始化

其中,bs 代表batch size,意為每次送入模型的訓(xùn)練圖像的數(shù)量。每次batch迭代后都會更新模型參數(shù)。
比如我們有640個圖像,那么bs=64;參數(shù)將在1 epoch的過程中更新10次。
如果你運(yùn)行教程過程中提示內(nèi)存不足,可以使用較小的bs,按照2的倍數(shù)增減即可。
使用特定值初始化上面的偽隨機(jī)數(shù)生成器可使系統(tǒng)穩(wěn)定,從而產(chǎn)生可重現(xiàn)的結(jié)果。
數(shù)據(jù)提取
數(shù)據(jù)集來自O(shè)xford-IIIT Pet Dataset,可以使用fastai數(shù)據(jù)集對模塊進(jìn)行檢索。

URLs.PETS 是數(shù)據(jù)集的url。這里提供了12個品種的貓和25個品種的狗。untar_data 解壓并下載數(shù)據(jù)文件到 path。
PosixPath('/home/jupyter/.fastai/data/oxford-iiit-pet/images/scottish_terrier_119.jpg')
每個圖像的標(biāo)簽都包含在圖像文件名中,需要使用正則表達(dá)式提取。模式如下:

創(chuàng)建訓(xùn)練并驗(yàn)證數(shù)據(jù)集:

ImageDataBunch 根據(jù)路徑 path_img 中的圖像創(chuàng)建訓(xùn)練數(shù)據(jù)集 train_ds 和驗(yàn)證數(shù)據(jù)集 valid_ds。
from_name_re 使用在編譯表達(dá)式模式 pat 后獲得的正則表達(dá)式從文件名 fnames 列表中獲取標(biāo)簽。
df_tfms 是即時(shí)應(yīng)用于圖像的轉(zhuǎn)換。在這里,圖像將調(diào)整為 224x224,居中,裁剪和縮放。
這種轉(zhuǎn)換是數(shù)據(jù)增強(qiáng)的實(shí)例,不會更改圖像內(nèi)部的內(nèi)容,但會更改其像素值以獲得更好的模型概括。
normalize 使用ImageNet圖像的標(biāo)準(zhǔn)偏差和平均值對數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)化。
數(shù)據(jù)可視化
訓(xùn)練數(shù)據(jù)樣本表示為
(Image (3, 224, 224), Category scottish_terrier)
Image里是RGB數(shù)值,Category 是圖像標(biāo)簽。對應(yīng)的圖像如下:
len(data.train_ds)和len(data.valid_ds)分別輸出訓(xùn)練樣本5912和驗(yàn)證樣本數(shù)量1478。
data.c和data.classes分別輸出類及其標(biāo)簽的數(shù)量。下面的標(biāo)簽共有37個類別:
['Abyssinian', 'Bengal', 'Birman', 'Bombay', 'British_Shorthair', 'Egyptian_Mau', 'Maine_Coon', 'Persian', 'Ragdoll', 'Russian_Blue', 'Siamese', 'Sphynx', 'american_bulldog', 'american_pit_bull_terrier', 'basset_hound', 'beagle','boxer', 'chihuahua', 'english_cocker_spaniel', 'english_setter', 'german_shorthaired', 'great_pyrenees', 'havanese', 'japanese_chin', 'keeshond', 'leonberger', 'miniature_pinscher', 'newfoundland', 'pomeranian', 'pug', 'saint_bernard', 'samoyed', 'scottish_terrier', 'shiba_inu', 'staffordshire_bull_terrier', 'wheaten_terrier', 'yorkshire_terrier']

show_batch 顯示一些batch里的圖片。
模型訓(xùn)練

cnn_learner 使用來自給定架構(gòu)的預(yù)訓(xùn)練模型構(gòu)建CNN學(xué)習(xí)器、來自預(yù)訓(xùn)練模型的學(xué)習(xí)參數(shù)用于初始化模型,允許更快的收斂和高精度。我們使用的CNN架構(gòu)是ResNet34。下圖是一個典型的CNN架構(gòu)。

ResNet34后面的數(shù)字可以隨意更改,比如改成ResNet50。數(shù)字越大,GPU內(nèi)存消耗越高。
讓我們繼續(xù),現(xiàn)在可以在數(shù)據(jù)集上訓(xùn)練模型了!
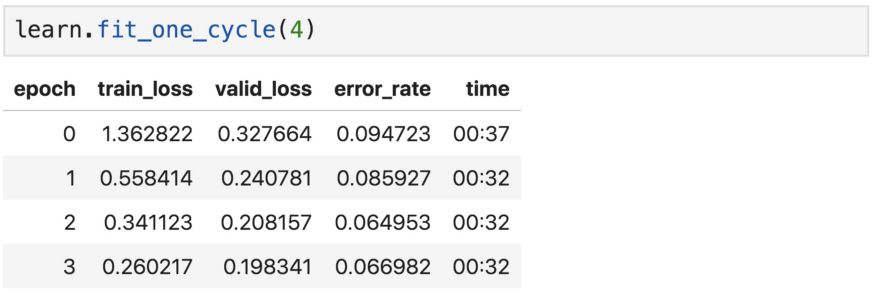
fit_one_cycle會按預(yù)設(shè)epoch數(shù)訓(xùn)練模型,比如4個epoch。
epoch數(shù)表示模型查看整個圖像集的次數(shù)。但是,在每個epoch中,隨著數(shù)據(jù)的增加,同一張圖像都會與上個epoch略有不同。
通常,度量誤差將隨著epoch的增加而下降。只要驗(yàn)證集的精度不斷提高,增加epoch數(shù)量就是個好辦法。然而,epoch過多可能導(dǎo)致模型學(xué)習(xí)了特定的圖像,而不是一般的類,要避免這種情況出現(xiàn)。
剛才提到的訓(xùn)練就是我們所說的“特征提取”,所以只對模型的頭部(最底下的幾層)的參數(shù)進(jìn)行了更新。接下來將嘗試對全部層的參數(shù)進(jìn)行微調(diào)。
恭喜!模型已成功訓(xùn)練,可以識別貓和狗了。識別準(zhǔn)確率大約是93.5%。
還能進(jìn)步嗎?這要等到微調(diào)之后了。
我們保存當(dāng)前的模型參數(shù),以便重新加載時(shí)使用。

對預(yù)測結(jié)果的解釋
現(xiàn)在我們看看如何正確解釋當(dāng)前的模型結(jié)果。

ClassificationInterpretation提供錯誤分類圖像的可視化實(shí)現(xiàn)。

plot_top_losses顯示最高損失的圖像及其:預(yù)測標(biāo)簽/實(shí)際標(biāo)簽/損失/實(shí)際圖像類別的概率
高損失意味著對錯誤答案出現(xiàn)的高信度。繪制最高損失是可視化和解釋分類結(jié)果的好方法。
具有最高損失的錯誤分類圖像
分類混淆矩陣

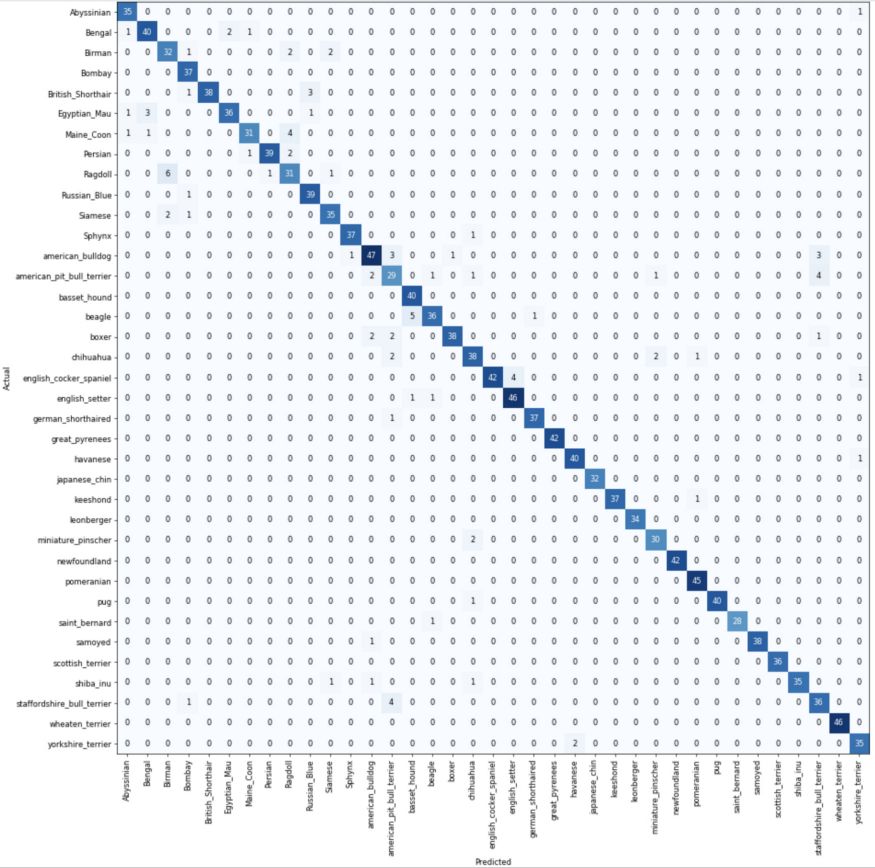
在混淆矩陣中,對角線元素表示預(yù)測標(biāo)簽與真實(shí)標(biāo)簽相同的圖像的數(shù)量,而非對角線元素是由分類器錯誤標(biāo)記的元素。

most_confused只突出顯示預(yù)測分類和實(shí)際類別中最混亂的組合,換句話說,就是分類最常出錯的那些組合。從圖中可以看到,模型經(jīng)常將斯塔福郡斗牛犬錯誤分類為美國斗牛犬,它們實(shí)際上看起來非常像。
[('Siamese', 'Birman', 6), ('american_pit_bull_terrier', 'staffordshire_bull_terrier', 5), ('staffordshire_bull_terrier', 'american_pit_bull_terrier', 5), ('Maine_Coon', 'Ragdoll', 4), ('beagle', 'basset_hound', 4), ('chihuahua', 'miniature_pinscher', 3), ('staffordshire_bull_terrier', 'american_bulldog', 3), ('Birman', 'Ragdoll', 2), ('British_Shorthair', 'Russian_Blue', 2), ('Egyptian_Mau', 'Abyssinian', 2), ('Ragdoll', 'Birman', 2), ('american_bulldog', 'staffordshire_bull_terrier', 2), ('boxer', 'american_pit_bull_terrier', 2), ('chihuahua', 'shiba_inu', 2), ('miniature_pinscher', 'american_pit_bull_terrier', 2), ('yorkshire_terrier', 'havanese', 2)]
對網(wǎng)絡(luò)層的凍結(jié)和解凍
在默認(rèn)情況下,在fastai中,使用預(yù)訓(xùn)練的模型對較早期的層進(jìn)行凍結(jié),使網(wǎng)絡(luò)只能更改最后一層的參數(shù),如上所述。凍結(jié)第一層,僅訓(xùn)練較深的網(wǎng)絡(luò)層可以顯著降低計(jì)算量。
我們總是可以調(diào)用unfreeze函數(shù)來訓(xùn)練所有網(wǎng)絡(luò)層,然后再使用fit或fit_one_cycle。這就是所謂的“微調(diào)”,這是在調(diào)整整個網(wǎng)絡(luò)的參數(shù)。
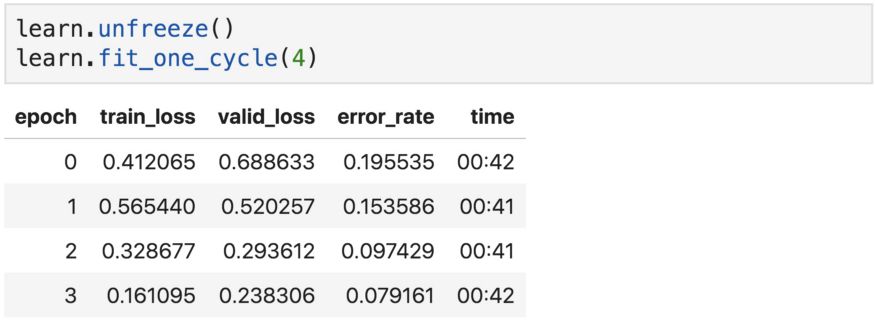
現(xiàn)在的準(zhǔn)確度比以前略差。這是為什么?
這是因?yàn)槲覀円韵嗤乃俣雀铝怂袑拥膮?shù),這不是我們想要的,因?yàn)榈谝粚硬恍枰褡詈笠粚幽菢有枰鎏嘧儎印?刂茩?quán)重更新量的超參數(shù)稱為“學(xué)習(xí)率”,也叫步長。它可以根據(jù)損失的梯度調(diào)整權(quán)重,目的是減少損失。例如,在最常見的梯度下降優(yōu)化器中,權(quán)重和學(xué)習(xí)率之間的關(guān)系如下:
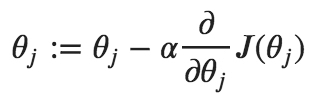
順便說一下,梯度只是一個向量,它是導(dǎo)數(shù)在多變量領(lǐng)域的推廣。
因此,對模型進(jìn)行微調(diào)的更好方法是對較低層和較高層使用不同的學(xué)習(xí)率,通常稱為差異或判別學(xué)習(xí)率。
本教程中可以互換使用參數(shù)和權(quán)重。更準(zhǔn)確地說,參數(shù)是權(quán)重和偏差。但請注意,超參數(shù)和參數(shù)不一樣,超參數(shù)無法在訓(xùn)練中進(jìn)行估計(jì)。
對預(yù)測模型的微調(diào)
為了找到最適合微調(diào)模型的學(xué)習(xí)率,我們使用學(xué)習(xí)速率查找器,可以逐漸增大學(xué)習(xí)速率,并且在每個batch之后記錄相應(yīng)的損失。在fastai庫通過lr_find來實(shí)現(xiàn)。
首先加載之前保存的模型,并運(yùn)行l(wèi)r_find

recorder.plot可用于繪制損失與學(xué)習(xí)率的關(guān)系圖。當(dāng)損失開始發(fā)散時(shí),停止運(yùn)行。
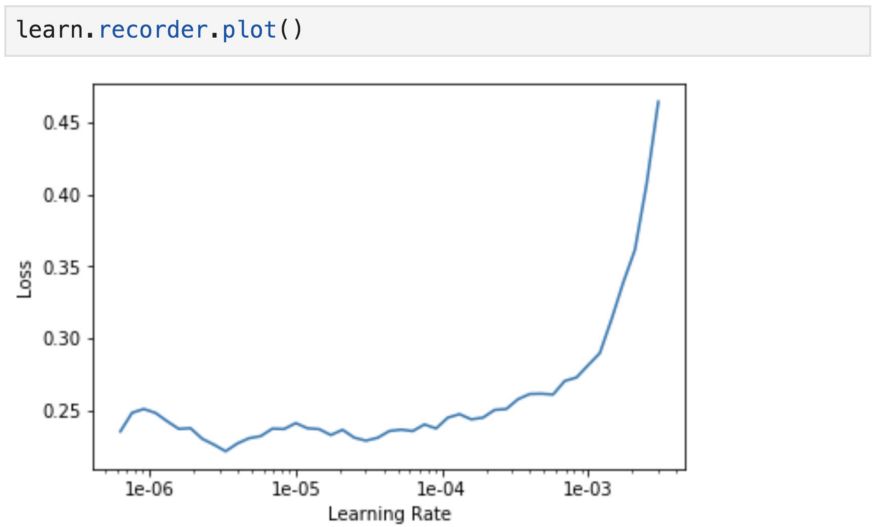
從得到的圖中,我們一致認(rèn)為適當(dāng)?shù)膶W(xué)習(xí)率約為1e-4或更小,超過這個范圍,損失就開始增大并失去控制。我們將最后一層的學(xué)習(xí)速率設(shè)為1e-4,更早期的層設(shè)為1e-6。同樣,這是因?yàn)樵缙诘膶右呀?jīng)訓(xùn)練得很好了,用來捕獲通用特征,不需要那么頻繁的更新。
我們之前的實(shí)驗(yàn)中使用的學(xué)習(xí)率為0.003,這是該庫的默認(rèn)設(shè)置。
在我們使用這些判別性學(xué)習(xí)率訓(xùn)練我們的模型之前,讓我們揭開fit_one_cycle和fitmethods之間的差異,因?yàn)閮烧叨际怯?xùn)練模型的合理選擇。這個討論對于理解訓(xùn)練過程非常有價(jià)值,但可以直接跳到結(jié)果。
fit_one_cycle vs fit:
簡而言之,二者之間不同之處在于fit_one_cycle實(shí)現(xiàn)了Leslie Smith 循環(huán)策略,而沒有使用固定或逐步降低的學(xué)習(xí)率來更新網(wǎng)絡(luò)的參數(shù),而是在兩個合理的較低和較高學(xué)習(xí)速率范圍之間振蕩。
訓(xùn)練中的學(xué)習(xí)率超參數(shù)
在微調(diào)深度神經(jīng)網(wǎng)絡(luò)時(shí),良好的學(xué)習(xí)率超參數(shù)是至關(guān)重要的。使用較高的學(xué)習(xí)率可以讓網(wǎng)絡(luò)更快地學(xué)習(xí),但是學(xué)習(xí)率太高可能使模型無法收斂。另一方面,學(xué)習(xí)率太小會使訓(xùn)練速度過于緩慢。
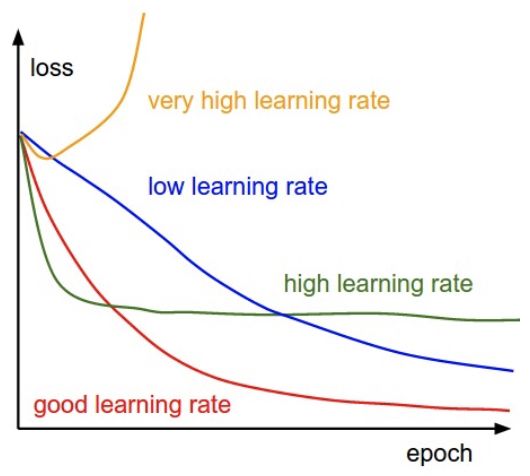
不同水平的學(xué)習(xí)率對模型收斂性的影響
在本文的實(shí)例中,我們通過查看不同學(xué)習(xí)率下記錄的損失,估算出合適的學(xué)習(xí)率。在更新網(wǎng)絡(luò)參數(shù)時(shí),可以將此學(xué)習(xí)率作為固定學(xué)習(xí)率。換句話說,就是對所有訓(xùn)練迭代使用相同的學(xué)習(xí)率,可以使用learn.fit來實(shí)現(xiàn)。一種更好的方法是,隨著訓(xùn)練的進(jìn)行逐步改變學(xué)習(xí)率。有兩種方法可以實(shí)現(xiàn),即學(xué)習(xí)率規(guī)劃(設(shè)定基于時(shí)間的衰減,逐步衰減,指數(shù)衰減等),以及自適應(yīng)學(xué)習(xí)速率法(Adagrad,RMSprop,Adam等)。
簡單的1cycle策略
1cycle策略是一種學(xué)習(xí)率調(diào)度器,讓學(xué)習(xí)率在合理的最小和最大邊界之間振蕩。制定這兩個邊界有什么價(jià)值呢?上限是我們從學(xué)習(xí)速率查找器獲得的,而最小界限可以小到上限的十分之一。這種方法的優(yōu)點(diǎn)是可以克服局部最小值和鞍點(diǎn),這些點(diǎn)是平坦表面上的點(diǎn),通常梯度很小。事實(shí)證明,1cycle策略比其他調(diào)度或自適應(yīng)學(xué)習(xí)方法更快、更準(zhǔn)確。Fastai在fit_one_cycle中實(shí)現(xiàn)了cycle策略,在內(nèi)部調(diào)用固定學(xué)習(xí)率方法和OneCycleScheduler回調(diào)。

1cycle的一個周期長度
下圖顯示了超收斂方法如何在Cifar-10的迭代次數(shù)更少的情況下達(dá)到比典型(分段常數(shù))訓(xùn)練方式更高的精度,兩者都使用56層殘余網(wǎng)絡(luò)架構(gòu)。
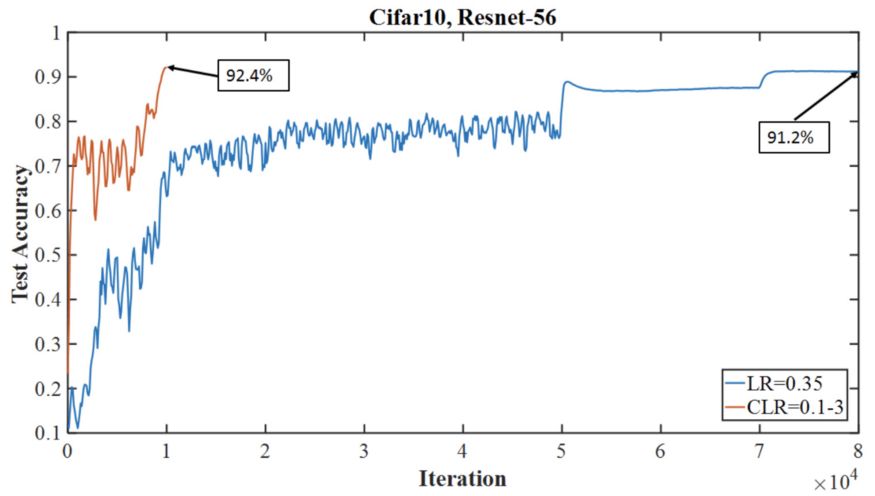
超收斂精度測試與Cifar-10上具有相同架構(gòu)模型的典型訓(xùn)練機(jī)制
揭曉真相的時(shí)刻到了
在選擇了網(wǎng)絡(luò)層的判別學(xué)習(xí)率之后,就可以解凍模型,并進(jìn)行相應(yīng)的訓(xùn)練了。

Slice函數(shù)將網(wǎng)絡(luò)的最后一層學(xué)習(xí)率設(shè)為1e-4,將第一層學(xué)習(xí)率設(shè)為1e-6。中間各層在此范圍內(nèi)以相等的增量設(shè)定學(xué)習(xí)率。
結(jié)果,預(yù)測準(zhǔn)確度有所提升,但提升的并不多,我們想知道,這時(shí)是否需要對模型進(jìn)行微調(diào)?
在微調(diào)任何模型之前始終要考慮的兩個關(guān)鍵因素就是數(shù)據(jù)集的大小及其與預(yù)訓(xùn)練模型的數(shù)據(jù)集的相似性。在我們的例子中,我們使用“寵物”數(shù)據(jù)集類似于ImageNet中的圖像,數(shù)據(jù)集相對較小,所以我們從一開始就實(shí)現(xiàn)了高分類精度,而沒有對整個網(wǎng)絡(luò)進(jìn)行微調(diào)。
盡管如此,我們?nèi)匀荒軌驅(qū)冉Y(jié)果進(jìn)行改進(jìn),并從中學(xué)到很多東西。
下圖說明了使用和微調(diào)預(yù)訓(xùn)練模型的三種合理方法。在本教程中,我們嘗試了第一個和第三個策略。第二個策略在數(shù)據(jù)集較小,但與預(yù)訓(xùn)練模型的數(shù)據(jù)集不同,或者數(shù)據(jù)集較大,但與預(yù)訓(xùn)練模型的數(shù)據(jù)集相似的情況下也很常見。

在預(yù)訓(xùn)練模型上微調(diào)策略
恭喜,我們已經(jīng)成功地使用最先進(jìn)的CNN覆蓋了圖像分類任務(wù),網(wǎng)絡(luò)的基礎(chǔ)結(jié)構(gòu)和訓(xùn)練過程都打下了堅(jiān)實(shí)的基礎(chǔ)。
至此,你已經(jīng)可以自己的數(shù)據(jù)集上構(gòu)建圖像識別器了。如果你覺得還沒有準(zhǔn)備好,可以從Google Image抓取一部分圖片組成自己的數(shù)據(jù)集。
開始體驗(yàn)吧!
-
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1208瀏覽量
24749 -
cnn
+關(guān)注
關(guān)注
3文章
353瀏覽量
22266 -
pytorch
+關(guān)注
關(guān)注
2文章
808瀏覽量
13283
原文標(biāo)題:從零開始,半小時(shí)學(xué)會PyTorch快速圖片分類
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
PMP10215工作半小時(shí)溫度就高達(dá)127.3度,這樣怎么做實(shí)際應(yīng)用呢?
半小時(shí)的不眠不休,終于搞定~~~
如何快速學(xué)會AD?
寫個單片機(jī)小程序。按鍵每按一次,時(shí)間增加半小時(shí) c51
labview2014中在一個while循環(huán)里調(diào)用dll運(yùn)行半小時(shí)后就崩潰了該怎么解決?
半小時(shí)開發(fā)基于 STM32 的室內(nèi)智能環(huán)境監(jiān)測儀
6小時(shí)學(xué)會labview
PyTorch官網(wǎng)教程PyTorch深度學(xué)習(xí):60分鐘快速入門中文翻譯版
textCNN論文與原理——短文本分類

PyTorch教程4.2之圖像分類數(shù)據(jù)集

PyTorch教程4.3之基本分類模型
PyTorch教程4.6之分類中的泛化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論