 FRVT賽程全紀錄:格靈深瞳全球排名前五
FRVT賽程全紀錄:格靈深瞳全球排名前五
最近兩個月,格靈深瞳首席科學家&算法部負責人張德兵與算法團隊參加了全球人臉識別算法測試(FRVT、Face Recognition Vendor Test)。雖然是第一次參加此比賽,格靈深瞳還是取得了不錯的成績,排名世界前五,在國內領先,且具體的成績接近世界最好水平(見表一)。
賽后,張德兵回憶了競賽的準備過程并記錄下來,希望激勵團隊在不久的將來能夠更上一層樓,以下為參賽記錄:

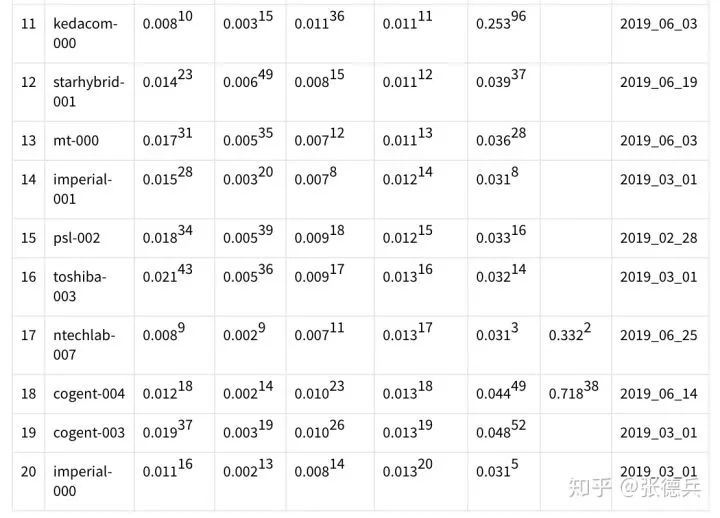
表一:FRVT 1:1 最新排名的前20名(基于第四列的跨14歲嫌疑人識別結果排序)
先介紹一下 FRVT。FRVT 由美國國家標準與技術研究院主辦,號稱是當今全球規模最大、標準最嚴、競爭最激烈、最權威的人臉識別算法競賽,到目前為止,全球已經有近百家公司和研究機構參與了此項測試,包括VisionLabs(俄羅斯)、Ever AI(美國)、Vocord(俄羅斯)、 依圖、商湯、曠視、海康、大華、騰訊等等。關于這個比賽,網上也能找到很多介紹,我大概總結一下我覺得比較重要的幾個點:
獨特的測試模式。在FRVT評測中,測試集是完全不公開的,只有簡略的幾段話描述。這意味著FRVT用的不是傳統那種通過在本地跑一遍測試集,然后提交結果的評測方式(在傳統評測中,大家往往不太考慮模型的計算效率,為了獲得更好的成績,經常會通過大幅提升模型容量的方法來提高效果,而且往往還會采用更加耗時的多模型甚至多尺度預測的融合策略。
所以,很多比賽中排名靠前的算法,它們的實用價值有可能并不高)。但在FRVT的測試中,官方要求每個廠商或者研究機構都要提供完整的預測代碼,并且由主辦方在同一個平臺上來運行所有提交,得到最終各個測試集上的結果。而且,該測試對于算法的運行時間也有著很嚴格的限制,所有提交都只能使用不超過CPU單線程1秒的計算資源來處理一張圖片從人臉檢測、人臉對齊到人臉特征提取和識別的所有功能。這些特點使得FRVT非常客觀且直接面向實際應用。
最嚴格的提交頻率限制。為了避免測試廠商通過反復提交來過擬合測試集,2019年6月以前的規定是,每個廠商每次只能提交一個算法版本,且兩次提交之間相隔至少要3個月,其中第一次提交的時候為了避免大家成績太差,官方允許同時提交兩個算法版本。但在2019年6月以后,規則變得更加嚴格了一些,每個廠商的兩次提交間隔變成了4個月,而且不管是不是第一次提交,每次都只能提交一個算法版本。這也就是說我們只有一次提交機會,風險還是挺大的。
豐富多樣的測試場景。FRVT主要覆蓋了四種類型的測試場景照片,分別是簽證照片(Visa),嫌疑人照片(Mugshot),自然場景照片(Wild)和兒童照片(Child),下面簡單介紹一下:
簽證照片(如圖一(a))。簽證照片是非常清晰、正面、無遮擋的一種受控測試場景,成像質量很高,且覆蓋了多達上百個國家的人臉數據。
嫌疑人照片(如圖1(b))。嫌疑人照片也是比較高清的,跟簽證照片相比,嫌疑人兩張照片間的年齡跨度一般會更大,有很多都超過了十年的年齡間隔。這個測試又分為兩個場景,一個是混合的測試,一個是基于專門挑出來年齡跨度達14年以上的照片進行的更有挑戰的評測。
自然場景照片(如圖1(c))。自然場景的照片是在非限制場景下采集的,各種光照,角度,遮擋,模糊,低分辨率的情況都可能會出現,是難度非常大的一種場景,某種意義上也更接近安防場景的實際應用。
兒童照片。兒童照片也是在非限制場景下采集的,因為年齡分布跟大家的訓練集可能差別比較大,所以也是非常難的一個任務。很多廠商提供的算法,完全無法支持這個場景,以至于得分都沒有顯示(成績差于某個數值就不會顯示了)。
圖一,簽證照片,嫌疑人照片和自然場景的拍攝照片
FRVT對以上每種場景都會進行單獨的評測,然后給出一個最終的排名表。在早期的排名表中,是以簽證照片識別結果的優劣對大家進行排名的,最近幾次的評測則改成了以跨年齡嫌疑人照片的識別結果優劣進行排名。我個人認為,所有這些場景都是挺重要的,在實際應用中都會用到,都不能有短板。且隨著人臉識別技術的不斷提升,非配合式的自然場景識別肯定是未來需求的大趨勢,只有真正做好非配合且無場景限制下的識別才能支持解鎖更多的、更廣泛的、更大規模的各行各業應用。
比賽前:
一直以來,我們對于刷LFW或者MegaFace之類數據集的就沒有太大的興趣,因為大家都知道,這里面的各種排名其實也都有不公平或者不合理的地方。FRVT則非常專業(看看它上百頁的測試報告也能感覺到這一點)。但是對于FRVT競賽,我個人一直下意識的認為Visa簽證照片涉及到了上百個國家的人臉照片,如果沒有類似的數據做訓練,結果應該很難能做到非常好。而收集相關數據又挑戰巨大。
首先想收集覆蓋這么多國家的人臉數據已經是非常困難了;其次, 就算收集到一些數據,跟簽證的場景也會差別很大;且經過一些嘗試后發現,在現階段,想大量采集簽證場景的真實數據幾乎是不可能的。-------另外,當看到以往成績較好的一些廠商的結果后,在團隊自己內部制作的中國人測試集上對比估算了一下,也發現我們在低誤識率下的召回率還是明顯要差一些,所以就一直沒有嘗試。
直到4月份的某一天,當我看到ArcFace在NIST上表現是超出預期的好(github.com/deepinsight/),我才突然意識到,FRVT對于我們的難度很可能被高估了。有了ArcFace這個baseline,感覺就踏實了很多。我個人猜測排名靠前的廠商也不一定真有多少能覆蓋到眾多國家的簽證數據,大家可能更多的還是在用一些開源數據和自己的業務數據來訓練的。
同時我們也注意到了大部分廠商其實還并不能在每個任務上都得到很好的結果,有明顯的domain差異帶來的識別率下降,所以也能多少猜出來一些可能用了什么樣的數據之類的信息。
比賽中:
既然如此,那必須要試一下了。
首先仿照ArcFace在開源數據上做一些baseline的模型出來作為參照。這里要強調一下,豐富的測試集對于衡量模型效果是非常必要的。在平時的產品研發中,我們已經積累了大量的多場景測試集,可以測試到非常低的誤識別率(我們也發布過一個人臉測試平臺,支持接近萬億分之一低誤識率且非常高效率的在線模型評測,trillionpairs.deepglint.com,該測試平臺也支持了ICCV 2019 的人臉識別 workshop 競賽 insightface-challenge.com)
接下來就是把長期以來產品研發中積累下來的模型結構設計經驗,分布式模型訓練經驗,數據集融合經驗和CPU平臺上的高效inference經驗快速移植到官方指定的測試環境下。
關于模型結構設計和壓縮,在產品的持續研發和迭代中,我們已經積累了比較多的經驗,可以很快的設計一批各種各樣的CPU友好的模型結構。
關于分布式模型訓練,可以參考我們之前的一個分布式人臉識別算法介紹(zhuanlan.zhihu.com/p/35),可以獲得幾乎線性的加速。
關于數據集融合,在很多場景我們可能都會發現,直接融合兩個不同源的數據可能會有一些問題。我們也曾經思考了很久,最終找到了一種可以有效利率各個數據源的融合策略,使得在多個不同的產品場景中都能表現得很好。所以要做的就是把手頭上所有的跟NIST比賽數據類型有關的數據都巧妙的融合起來,但是由于時間有限,全量數據做實驗是不現實的,這次比賽還是只能用一部分。
關于高效的CPU inference。這里有個小插曲。我們曾經做過一個業余項目,基于強化學習的五子棋AI訓練。我們仿照AlphaZero的思路,并且做了針對性的改進,使得基于幾十張卡就可訓練到強職業的水平,最后這個項目也參加了2019年的五子棋AI世界錦標賽(Gomocup 2019),并且拿了平衡開局的無禁手世界第四名(StarDust),是所有基于深度學習算法中最好的(gomocup.org/results/gom)。為什么只有第四呢?深度學習算法潛力巨大,如果有充分的訓練資源,再加上GPU支持的走棋策略當然可以完勝傳統算法,但是這個比賽為了公平性的考慮,也有一個限制就是必須要提供CPU單線程下的可執行程序,所以在這么有限的計算資源條件下(而且評測的19x19路的大棋盤),我們覺得能到第四名已經還不錯了。雖然沒有顛覆所有傳統算法,但這次的業余項目,也使得我們對CPU單線程下的inference優化有了比較好的積累。
在這個過程中,我們根據以往的經驗,在這個特定比賽任務上,不斷的試驗各種模型優化策略、數據集融合策略,也包括調整和嘗試各種模型結構、超參數、迭代次數、損失函數等等。因為要試驗驗證的細節非常多,我們先以很高優先級,走通了基于fp16的訓練方式,使得訓練速度提升了幾乎一倍。
這段時間在印象里是過得飛快,但大家都非常興奮,因為高效率的試驗使得我們幾乎每隔幾天就能看到新的提高。但時間總是很有限,在我們迭代了幾十個模型后,就已經六月初,臨近比賽結束了。雖然感覺還有很多的想法沒有試驗完,但是也沒辦法,差不多就打算選個最好的模型提交了。當時根據我們的自測,結果還湊合,按照ArcFace之前成績的估算,應該大概率能進入前五名(按FRVT 4月份的成績)。
之后恰好是CVPR 2019的會議時間(6.15-6.21),FRVT相關的一切基本準備就緒后(只差最后的確認提交),我就帶著幾個瞳學去了Long Beach,去了解最新的學術動態去了。沒想到還沒等到開會,就收到了小伙伴新的消息,在半精度模型訓練的過程中,發現了一處隱藏的bug,在復雜Loss和數據源的情況下會造成模型訓練的不穩定。于是,中美兩地開始不分白天黑夜的緊急修改(倒也省得倒時差了),一陣忙活之后,又看到了非常顯著的提升,那種感覺是非常不錯的。
之后就按照官方要求進行了最終的郵件提交,之后就一直沒有什么信息了,直到7.3號,比賽結果出來,看到三項的結果都超過了依圖。如果按照4月份的排名,這個成績基本上能跟當時的VisionLabs并列第一。不過因為VisionLabs也有了小幅提升,然后又冒出來一個成績還挺不錯的Ever AI,所以我們在7.3號最新的榜單里是世界第三名(按公司來看) 或者世界第四名(按模型提交數來看)。只看國內的話,是順利的暫列第一了(大部分任務都超過了友商,當然在簽證照片上還遜色依圖,在兒童照片上比曠世差一點)。
我覺得我們有一個比較大的優勢是在所有任務上表現都相對比較一致,不像大部分友商的提交,會在某些場景表現得比較差,似乎是出現了一些domain的偏向性,這在實際應用中,有可能會遇到一些問題。仔細看一下結果我們會發現,在這方面Ever AI其實做得更加優秀,非常值得我們學習。
最后再做一個總結吧,簡單分三個方面:
一:感謝
感謝ArcFace的Baseline, 以及在我們比賽中提供的一些支持。
感謝靠譜的團隊成員,人數不多,在產品壓力下,還敢做挑戰世界的事情,而且還能做得不錯。
感謝友商,給我們提供了階段性的追趕目標。
二:不足
訓練數據仍沒有充分使用起來
在新型網絡結構的探索、模型結構搜索(NAS)和模型inference優化(如定點化, 模型壓縮等)等方面還有一定的空間
在人臉識別的問題建模、損失函數的進一步優化、泛化性能的保證、優化策略的影響等方面仍然缺乏足夠的清晰理解
三:未來
人臉識別在真實場景的應用效果,其實遠不是一個比賽能夠完全衡量的。人臉識別發展到現在,也包括基于人臉識別而衍生出來的行人ReID等以圖搜圖技術,其實離真正解決工業界大規模的應用都還有不小的距離,萬路、十萬路、乃至百萬路的剛需,仍在前面等著我們去不斷優化和探索。
當然,因為涉及到公司內部的很多研發細節,這里無法更加詳細的介紹具體技術,但我們非常期待對相關技術有濃厚興趣、有獨特想法、有很強執行力的朋友加入我們,你將有機會了解到所有的技術細節,并與我們一起進一步推進相關研究,做更多有意義的事情。另外,本文的很多內容都是我個人的一些理解和分析,應邀匆忙整理了一下,有些疏漏或者錯誤也是難免的,如有發現,歡迎指出。
格靈深瞳算法團隊:格靈深瞳核心團隊,負責公司所有產品線的各類不同算法的支持(安防、零售、智能相機、機器人等等,檢測、跟蹤、識別、檢索、商品推薦、數據挖掘、定位和導航等)。同時關注前沿算法研發和踏實的產品落地,擁有大規模的業務數據積累。
-
算法
+關注
關注
23文章
4625瀏覽量
93124 -
開源
+關注
關注
3文章
3385瀏覽量
42611 -
數據集
+關注
關注
4文章
1208瀏覽量
24759
原文標題:FRVT賽程全紀錄:格靈深瞳全球排名前五
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
AI與體育結合,中國教育電視臺深度報道格靈深瞳AI訓考系統
格靈深瞳入選2024年度智能體育典型案例
格靈深瞳近期接連斬獲8項大獎
格靈深瞳亮相中國鐵路蘭州局科技創新大會
格靈深瞳擬控股國科億道
格靈深瞳同時入選科創AI和科創200兩大指數
雷軍稱小米汽車目標全球前五
格靈深瞳亮相2024 ChinaJoy AIGC大會
格靈深瞳金融和軌交行業大模型入選「2024人工智能大模型場景應用典型案例」

格靈深瞳推動人工智能產業健康長久發展
格靈深瞳斬獲首屆花樣滑冰動作識別競賽奪冠

格靈深瞳入選「2024年最值得關注的AIGC企業」

格靈深瞳受邀參加華為中國合作伙伴大會,榮獲“昇騰突出貢獻獎”
AI PC元年,全球前五大PC廠商如何領跑?






 工商網監
工商網監
評論