") Python告訴你充氣娃娃什么感覺?
Python告訴你充氣娃娃什么感覺?
【導(dǎo)語】:之前為大家介紹了 requests 庫的基本信息以及使用方法,收到了很多同學(xué)的反饋,期待作者新作,今天不負(fù)所望,作者就帶大家來玩一把刺激的。
一、需求背景
在實(shí)際開發(fā)過程中,在我們動(dòng)手開發(fā)之前,都是由產(chǎn)品經(jīng)理為我們(測(cè)試、前端、后端、項(xiàng)目經(jīng)理等)先講解一下需求,我們了解了需求之后,才開始一起來討論技術(shù)方案。

我們自己實(shí)現(xiàn)一些小功能時(shí)同樣需要討論需求,也就是告訴別人我們?yōu)槭裁匆鲞@個(gè)東西?或者我們想利用這款產(chǎn)品解決什么問題。
我們常常看到一些有關(guān)充氣娃娃的表情包和圖片或新聞,但是這種東西很少會(huì)像一些小視頻一些相互交流,大家可能都是偷摸玩耍。所以豬哥相信其實(shí)大部分同學(xué)并沒有親身體驗(yàn)過充氣娃娃到底是什么感覺(包括豬哥),所以豬哥很好奇究竟是什么一種體驗(yàn)?真的如傳言中那樣爽嗎?
二、功能描述
基于很多人沒有體驗(yàn)過充氣娃娃是什么感覺,但是又很好奇,所以希望通過爬蟲+數(shù)據(jù)分析的方式直觀而真實(shí)的告訴大家(下圖為成品圖)。
三、技術(shù)方案
為了實(shí)現(xiàn)上面的需求以及功能,我們來討論下具體的技術(shù)實(shí)現(xiàn)方案:
分析某東評(píng)論數(shù)據(jù)請(qǐng)求
使用requests庫抓取某東的充氣娃娃評(píng)論
使用詞云做數(shù)據(jù)展示
四、技術(shù)實(shí)現(xiàn)
上篇文章中就給大家說過,今天我們以某東商品編號(hào)為:1263013576 的商品為對(duì)象,進(jìn)行數(shù)據(jù)分析,我們來看看詳細(xì)的技術(shù)實(shí)現(xiàn)步驟吧!
本教程只為學(xué)習(xí)交流,不得用于商用獲利,后果自負(fù)!如有侵權(quán)或者對(duì)任何公司或個(gè)人造成不利影響,請(qǐng)告知?jiǎng)h除
1.分析并獲取評(píng)論接口的URL
第一步:打開某東的商品頁,搜索你想研究的商品。
第二步:我們?cè)陧撁嬷惺髽?biāo)右鍵選擇檢查(或F12)調(diào)出瀏覽器的調(diào)試窗口。
第三步:調(diào)出瀏覽器后點(diǎn)擊評(píng)論按鈕使其加載數(shù)據(jù),然后我們點(diǎn)擊network查看數(shù)據(jù)。
第四步:查找加載評(píng)論數(shù)據(jù)的請(qǐng)求url,我們可以使用某條評(píng)論中的一段話,然后在調(diào)試窗口中搜索。
經(jīng)過上面4步分析,我們就拿到了京東評(píng)論數(shù)據(jù)的接口:
https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4654&productId=1263013576&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
productPageComments:看這個(gè)名字就知道是產(chǎn)品頁評(píng)論
2.爬取評(píng)論數(shù)據(jù)
拿到評(píng)論數(shù)據(jù)接口url之后,我們就可以開始寫代碼抓取數(shù)據(jù)了。一般我們會(huì)先嘗試抓取一條數(shù)據(jù),成功之后,我們?cè)偃シ治鋈绾螌?shí)現(xiàn)大量抓取。
上一篇我們已經(jīng)講解了如何使用requests庫發(fā)起http/s請(qǐng)求,我們來看看代碼:
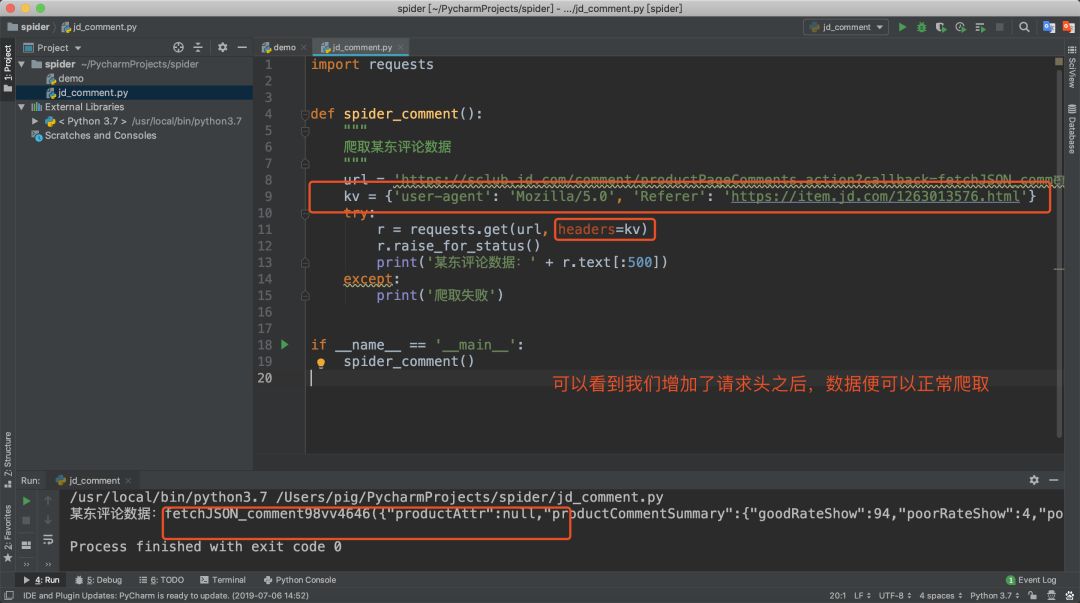
但是在打印的結(jié)果中數(shù)據(jù)卻是空?為何瀏覽器請(qǐng)求成功,而我們的代碼卻請(qǐng)求不到數(shù)據(jù)呢?難道我們遇到了反爬?這種情況下如何解決?
大家在遇到這種情況時(shí),回到瀏覽器的調(diào)試窗口,查看下瀏覽器發(fā)起的請(qǐng)求頭,因?yàn)榭赡転g覽器請(qǐng)求時(shí)攜帶了什么請(qǐng)求頭參數(shù)而我們代碼中沒有。
果然,我們?cè)跒g覽器頭中看到了有兩個(gè)請(qǐng)求頭 Referer 和 User-Agent,那我們先把他們加到代碼的請(qǐng)求頭中,再試試!
3.數(shù)據(jù)提取
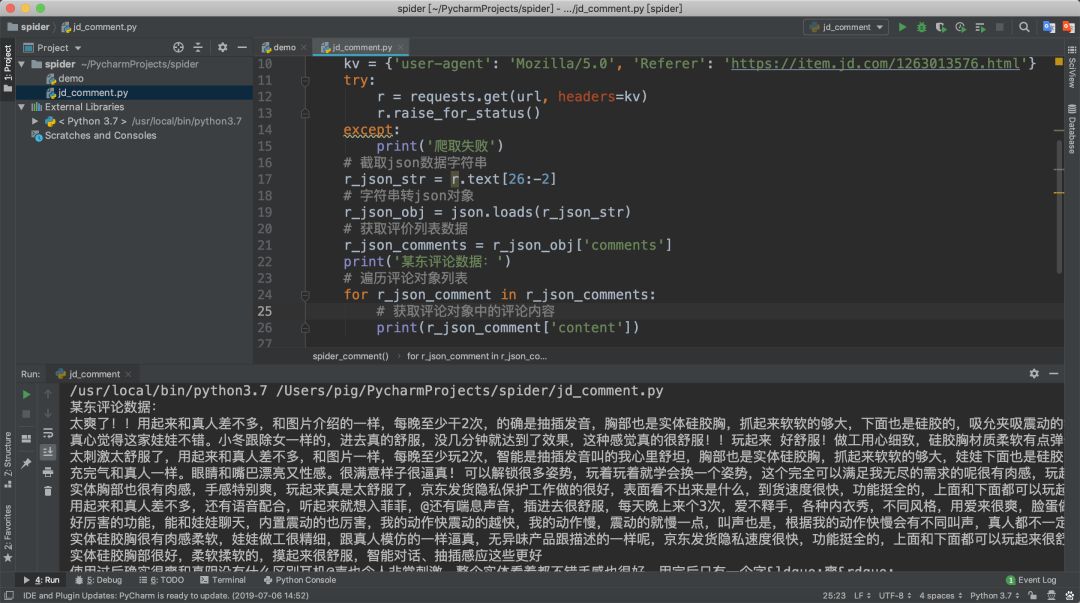
我們對(duì)爬取的數(shù)據(jù)分析發(fā)現(xiàn),此數(shù)據(jù)為jsonp跨域請(qǐng)求返回的json結(jié)果,所以我們只要把前面的fetchJSON_comment98vv4646(和最后的)去掉就拿到j(luò)son數(shù)據(jù)了。

將json數(shù)據(jù)復(fù)制到j(luò)son格式化工具中或者在Chrome瀏覽器調(diào)試窗口點(diǎn)擊Preview也可以看到,json數(shù)據(jù)中有一個(gè)key為comments的值便是我們想要的評(píng)論數(shù)據(jù)。
我們?cè)賹?duì)comments值進(jìn)行分析發(fā)現(xiàn)是一個(gè)有多條數(shù)據(jù)的列表,而列表里的每一項(xiàng)就是每個(gè)評(píng)論對(duì)象,包含了評(píng)論的內(nèi)容,時(shí)間,id,評(píng)價(jià)來源等等信息,而其中的content字段便是我們?cè)陧撁婵吹降挠脩粼u(píng)價(jià)內(nèi)容。
那我們來用代碼將每個(gè)評(píng)價(jià)對(duì)象的content字段提取并打印出來。
4.數(shù)據(jù)保存
數(shù)據(jù)提取后我們需要將他們保存起來,一般保存數(shù)據(jù)的格式主要有:文件、數(shù)據(jù)庫、內(nèi)存這三大類。今天我們就將數(shù)據(jù)保存為txt文件格式,因?yàn)椴僮魑募鄬?duì)簡單同時(shí)也能滿足我們的后續(xù)數(shù)據(jù)分析的需求。
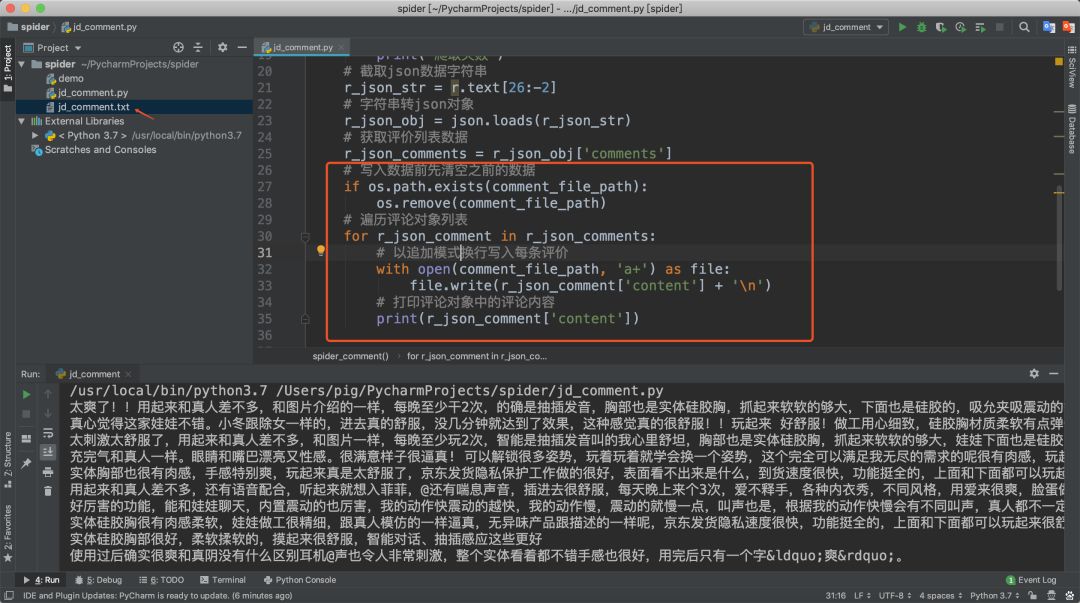
然后我們查看一下生成的文件內(nèi)容是否正確。

5.批量爬取
再完成一頁數(shù)據(jù)爬取、提取、保存之后,我們來研究一下如何批量抓取?
做過web的同學(xué)可能知道,有一項(xiàng)功能是我們必須要做的,那便是分頁。何為分頁?為何要做分頁?
我們?cè)跒g覽很多網(wǎng)頁的時(shí)候常常看到“下一頁”這樣的字眼,其實(shí)這就是使用了分頁技術(shù),因?yàn)橄蛴脩粽故緮?shù)據(jù)時(shí)不可能把所有的數(shù)據(jù)一次性展示,所以采用分頁技術(shù),一頁一頁的展示出來。
讓我們?cè)倩氐阶铋_始的加載評(píng)論數(shù)據(jù)的url:
https://sclub.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98vv4654&productId=1263013576&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1
我們可以看到鏈接里面有兩個(gè)參數(shù)page=0&pageSize=10,page表示當(dāng)前的頁數(shù),pageSize表示每頁多少條,那這兩個(gè)數(shù)據(jù)直接去數(shù)據(jù)庫limit數(shù)據(jù)。
老司機(jī)一眼便可以看出這就是分頁的參數(shù),但是有同學(xué)會(huì)說:如果我是老司機(jī)還干嘛看你的文章?所以我教大家如何來找到這個(gè)分頁參數(shù)。
回到某東的商品頁,我們將評(píng)價(jià)頁面拉到最底下,發(fā)現(xiàn)有分頁的按鈕,然后我們?cè)谡{(diào)試窗口清空之前的請(qǐng)求記錄。
清空之前的請(qǐng)求記錄之后,我們點(diǎn)擊上圖紅框分頁按鈕的數(shù)字2,代表這第二頁,然后復(fù)制第一條評(píng)價(jià)去調(diào)試窗口搜索,最后找到請(qǐng)求鏈接。
然后我們點(diǎn)擊Headers查看第二頁請(qǐng)求數(shù)據(jù)的url
然后我們比較第一頁評(píng)價(jià)與第二頁評(píng)價(jià)的url有何區(qū)別。
這里也就驗(yàn)證了豬哥的猜想:page表示當(dāng)前的頁數(shù),pageSize表示每頁多少條。而且我們還能得出另一個(gè)結(jié)論:第一個(gè)page=0,第二頁page=1 然后依次往后。有同學(xué)會(huì)問:為什么第一頁不是1,而是0,因?yàn)樵跀?shù)據(jù)庫中一般的都是從0開始計(jì)數(shù),編程行業(yè)很多數(shù)組列表都是從0開始計(jì)數(shù)。
好了,知道分頁規(guī)律之后,我們只要在每次請(qǐng)求時(shí)將page參數(shù)遞增不就可以批量抓取了嗎?我們來寫代碼吧!
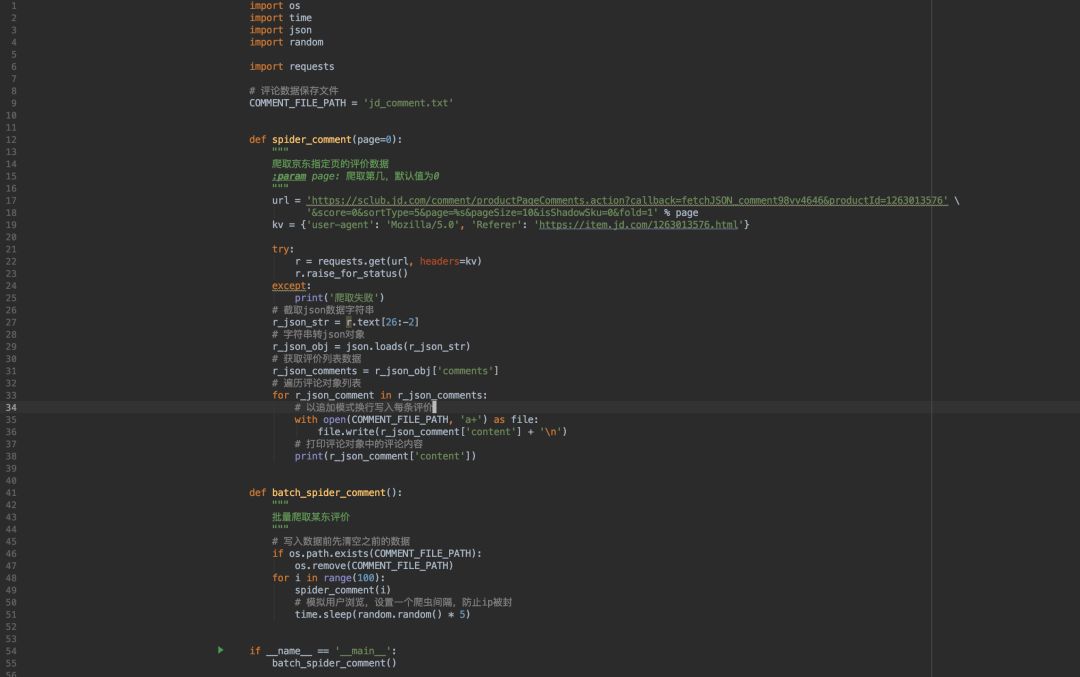
簡單講解一下做的改動(dòng):
對(duì)spider_comment方法增加入?yún)?shù),然后在url中增加占位符,這樣就可以動(dòng)態(tài)修改url,爬取指定的頁數(shù)。
增加一個(gè)batch_spider_comment方法,循環(huán)調(diào)用spider_comment方法,暫定爬取100頁。
在batch_spider_comment方法的for循環(huán)中設(shè)置了一個(gè)隨機(jī)的休眠時(shí)間,意在模擬用戶瀏覽,防止因?yàn)榕廊√l繁被封ip。
爬取完成之后檢查成果。
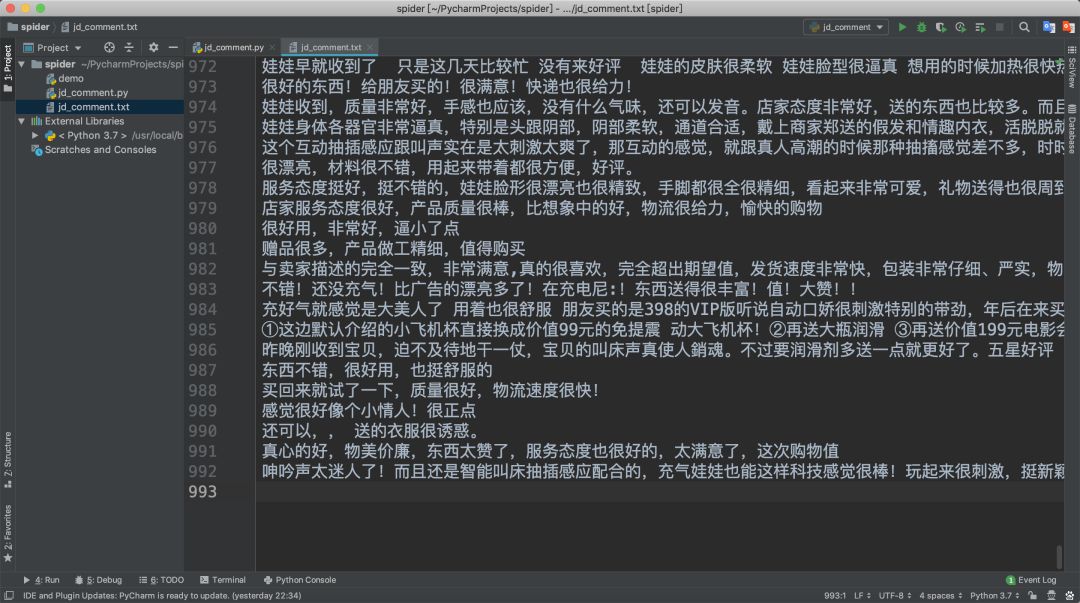
6.數(shù)據(jù)清洗
數(shù)據(jù)成功保存之后我們需要對(duì)數(shù)據(jù)進(jìn)行分詞清洗,對(duì)于分詞我們使用著名的分詞庫jieba。
首先是安裝jieba庫:
pip3 install jieba
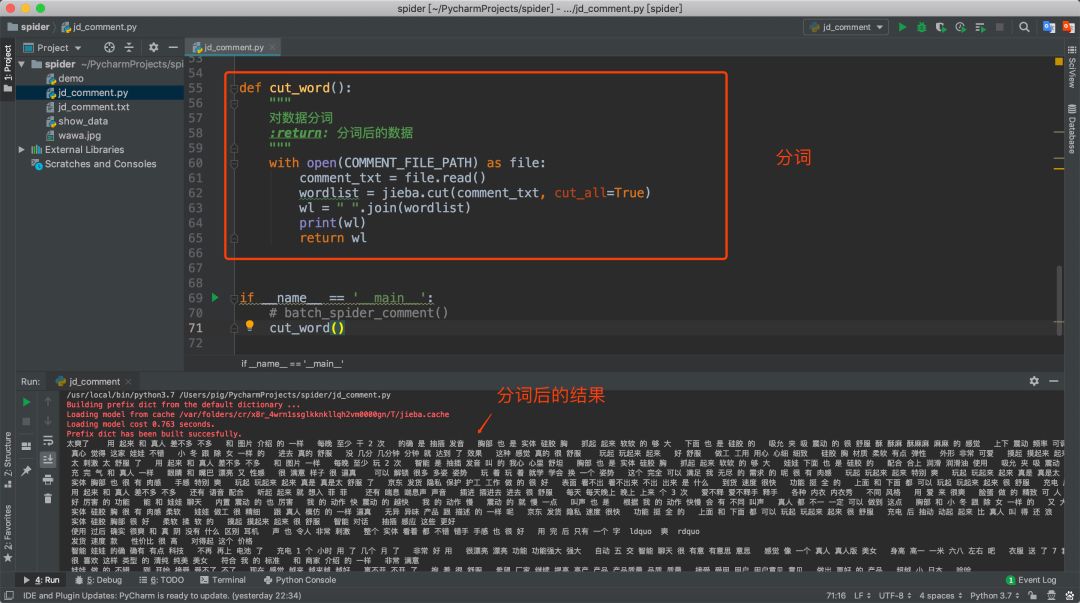
當(dāng)然這里你還可以對(duì)一些介詞等無效詞進(jìn)行剔除,這樣可以避免無效數(shù)據(jù)。
7.生成詞云
生成詞云我們需要用到numpy、matplotlib、wordcloud、Pillow這幾個(gè)庫,大家先自行下載。matplotlib庫用于圖像處理,wordcloud庫用于生成詞云。

注意:font_path是選擇字體的路徑,如果不設(shè)置默認(rèn)字體可能不支持中文,豬哥選擇的是Mac系統(tǒng)自帶的宋體字!
最終結(jié)果:
我們來看看全代碼。
五、總結(jié)
因考慮新手的友好性,文章篇幅較長,詳細(xì)的介紹了從需求到技術(shù)分析、爬取數(shù)據(jù)、清洗數(shù)據(jù)、最后的分析數(shù)據(jù)。我們來總結(jié)一下本篇文章學(xué)到的東西吧:
如何分析并找出加載數(shù)據(jù)的url
如何使用requests庫的headers解決Referer和User-Agent反扒技術(shù)
如何找出分頁參數(shù)實(shí)現(xiàn)批量爬取
設(shè)置一個(gè)爬蟲間隔時(shí)間防止被封ip
數(shù)據(jù)的提取與保存到文件
使用jieba庫對(duì)數(shù)據(jù)分詞清洗
使用wordcloud生成指定形狀的詞云
這是一套完整的數(shù)據(jù)分析案例,希望大家能自己動(dòng)手嘗試,去探索更多有趣的案例。
-
數(shù)據(jù)分析
+關(guān)注
關(guān)注
2文章
1464瀏覽量
34355 -
python
+關(guān)注
關(guān)注
56文章
4813瀏覽量
85314 -
爬蟲
+關(guān)注
關(guān)注
0文章
82瀏覽量
7131
原文標(biāo)題:充氣娃娃什么感覺?Python告訴你
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
【labview我來告訴你】對(duì)像高亮顯示”實(shí)現(xiàn)酷閃耀功能
共享掃碼娃娃機(jī)方案內(nèi)容
DIY娃娃機(jī)相關(guān)資料推薦
制作櫻花娃娃的教程分享
聲控音樂娃娃電路圖
用紙板制作抓娃娃機(jī)
如何使用電子技術(shù)設(shè)計(jì)一個(gè)會(huì)說話的布娃娃
Arduino娃娃屋迷你電視開源設(shè)計(jì)

充氣泵方案中的芯片選擇與應(yīng)用案例
充氣泵方案的原理和結(jié)構(gòu)是什么?
充氣柜和普通開關(guān)柜相比有什么優(yōu)點(diǎn)和缺點(diǎn)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論