 基于內容的推薦算法算是最早應用于工程實踐的推薦算法,有大量的應用案例
基于內容的推薦算法算是最早應用于工程實踐的推薦算法,有大量的應用案例
這篇文章我們主要關注的是基于內容的推薦算法,它也是非常通用的一類推薦算法,在工業界有大量的應用案例。
本文會從什么是基于內容的推薦算法、算法基本原理、應用場景、基于內容的推薦算法的優缺點、算法落地需要關注的點等5個方面來講解。
希望讀者讀完可以掌握常用的基于內容的推薦算法的實現原理,并且可以基于本文的思路快速將基于內容的推薦算法落地到真實業務場景中。
01什么是基于內容的推薦算法
首先我們給基于內容的推薦算法下一個定義,讓讀者有初步的印象,后面更容易理解我們講的基于內容的推薦算法。
所謂基于內容的推薦算法(Content-Based Recommendations)是基于標的物相關信息、用戶相關信息及用戶對標的物的操作行為來構建推薦算法模型,為用戶提供推薦服務。這里的標的物相關信息可以是對標的物文字描述的metadata信息、標簽、用戶評論、人工標注的信息等。用戶相關信息是指人口統計學信息(如年齡、性別、偏好、地域、收入等等)。用戶對標的物的操作行為可以是評論、收藏、點贊、觀看、瀏覽、點擊、加購物車、購買等。基于內容的推薦算法一般只依賴于用戶自身的行為為用戶提供推薦,不涉及到其他用戶的行為。
廣義的標的物相關信息不限于文本信息,圖片、語音、視頻等都可以作為內容推薦的信息來源,只不過這類信息處理成本較大,不光是算法難度大、處理的時間及存儲成本也相對更高。
基于內容的推薦算法算是最早應用于工程實踐的推薦算法,有大量的應用案例,如今日頭條的推薦有很大比例是基于內容的推薦算法。
02基于內容的推薦算法實現原理
基于內容的推薦算法的基本原理是根據用戶的歷史行為,獲得用戶的興趣偏好,為用戶推薦跟他的興趣偏好相似的標的物,讀者可以直觀上從下圖理解基于內容的推薦算法。
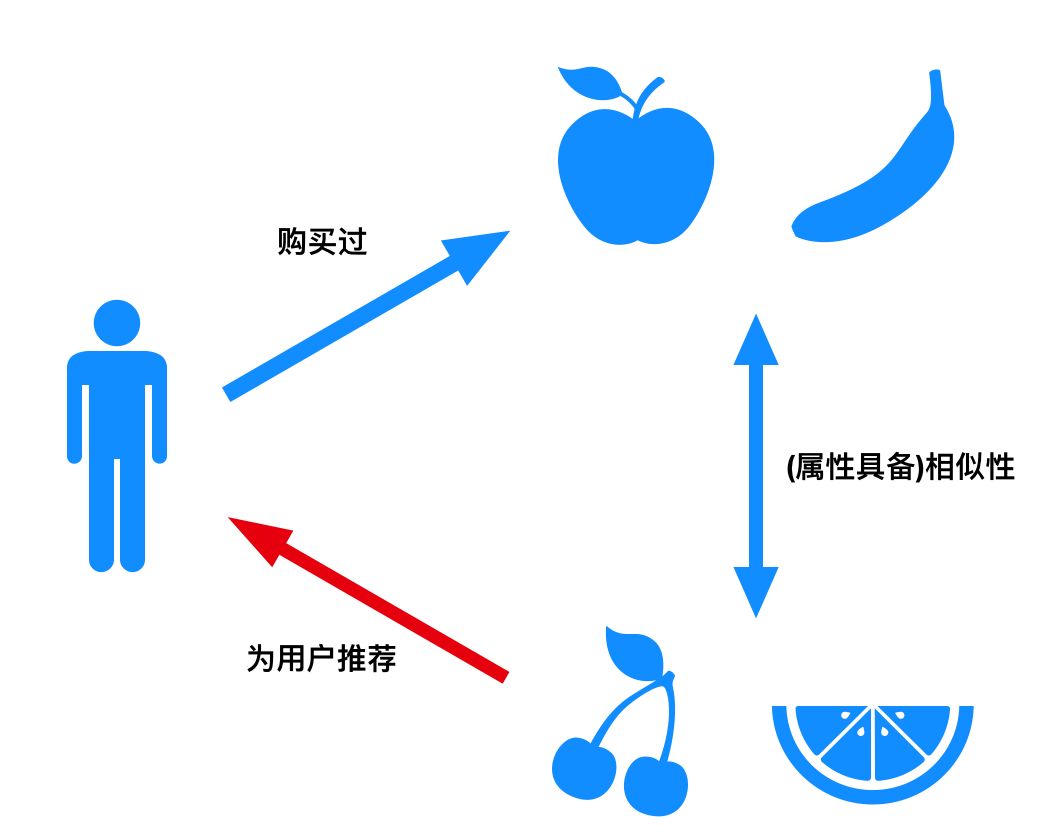
圖1:基于內容的推薦算法示意圖
從上圖也可以看出,要做基于內容的個性化推薦,一般需要三個步驟,它們分別是:基于用戶信息及用戶操作行為構建用戶特征表示、基于標的物信息構建標的物特征表示、基于用戶及標的物特征表示為用戶推薦標的物,具體參考圖2:
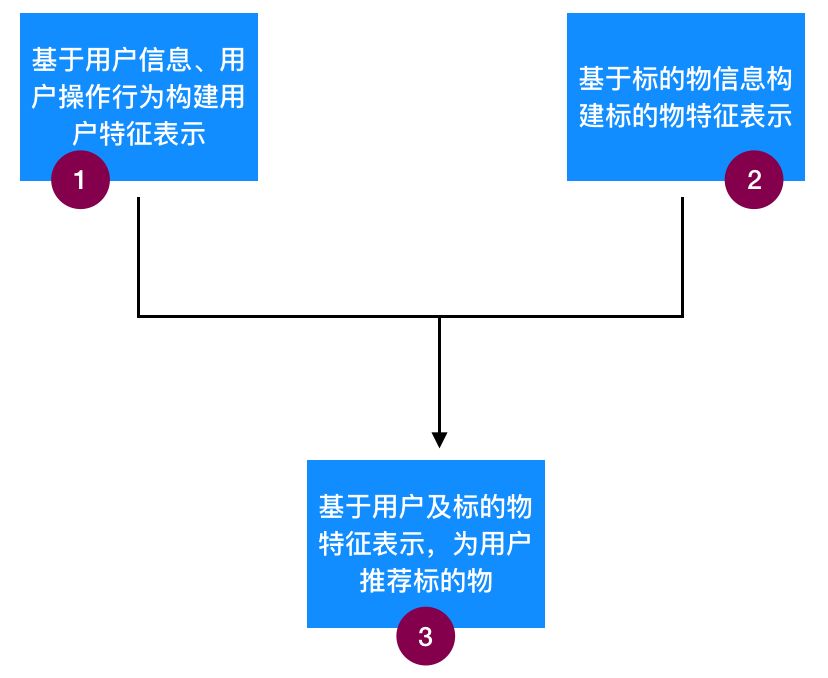
圖2:基于內容的個性化推薦的三個核心步驟
本節我們先簡單介紹一下怎么基于上圖的步驟1、步驟2為用戶做推薦(即步驟3中給用戶做推薦的核心思想),然后分別對這三個步驟加以說明,介紹每個步驟都有哪些方法和策略可供選擇。
▌1.基于用戶和標的物特征為用戶推薦的核心思想
有了用戶特征和標的物特征,我們怎么給用戶做推薦呢?我認為主要的推薦思路有如下三個:
(1)基于用戶歷史行為記錄做推薦
我們需要事先計算標的物之間的相似性,然后將用戶歷史記錄中的標的物的相似標的物推薦給用戶。
不管標的物包含哪類信息,一般的思路是將標的物特征轉化為向量化表示,有了向量化表示,我們就可以通過cosine余弦相似度計算兩個標的物之間的相似度了。
(2)用戶和標的物特征都用顯式的標簽表示,利用該表示做推薦
標的物用標簽來表示,那么反過來,每個標簽就可以關聯一組標的物,那么根據用戶的標簽表示,用戶的興趣標簽就可以關聯到一組標的物,這組通過標簽關聯到的標的物,就可以作為給用戶的推薦候選集。這類方法就是所謂的倒排索引法,是搜索業務通用的解決方案。
(3)用戶和標的物嵌入到同一個向量空間,基于向量相似做推薦
當用戶和標的物嵌入到同一個向量空間中后,我們就可以計算用戶和標的物之間的相似度,然后按照標的物跟用戶的相似度,為用戶推薦相似度高的標的物。還可以基于用戶向量表示計算用戶相似度,將相似用戶喜歡的標的物推薦給該用戶,這時標的物嵌入是不必要的。
講清楚了基于內容的推薦的核心思想,那么下面我們分別講解怎么表示用戶特征、怎么表示標的物特征以及怎么為用戶做推薦。
▌2.構建用戶特征表示
用戶的特征表示可以基于用戶對標的物的操作行為(如點擊、購買、收藏、播放等)構建用戶對標的物的偏好畫像,也可以基于用戶自身的人口統計學特征來表達。有了用戶特征表示,我們就可以基于用戶特征為用戶推薦與他特征匹配的標的物。構建用戶特征的方法主要有如下5種:
(1)用戶行為記錄作為顯示特征
記錄用戶過去一段時間對標的物的偏好。拿視頻行業來說,如果用戶過去一段時間看了A、B、C三個視頻,同時可以根據每個視頻用戶觀看時長占視頻總時長的比例給用戶的行為打分,這時用戶的興趣偏好就可以記錄為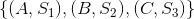 ,其中S1、S2、S3分別是用戶對視頻A、B、C的評分。
,其中S1、S2、S3分別是用戶對視頻A、B、C的評分。
該方案直接將用戶歷史操作過的標的物作為用戶的特征表示,在推薦時可以將與用戶操作過的標的物相似的標的物推薦給用戶。
(2)顯式的標簽特征
如果標的物是有標簽來描述的,那么這些標簽可以用來表征標的物。用戶的興趣畫像也可以基于用戶對標的物的行為來打上對應的標簽。拿視頻推薦來舉例,如果用戶過去看了科幻和恐怖兩類電影,那么恐怖、科幻就是用戶的偏好標簽了。
每個標的物的標簽可以是包含權重的,而用戶對標的物的操作行為也是有權重的,從而用戶的興趣標簽是有權重的。
在具體推薦時,可以將用戶的興趣標簽關聯到的標的物(具備該標簽的標的物)推薦給用戶。
(3)向量式的興趣特征
可以基于標的物的信息將標的物嵌入到向量空間中,利用向量來表示標的物,我們會在后面講解嵌入的算法實現方案。有了標的物的向量化表示,用戶的興趣向量就可以用他操作過的標的物的向量的平均向量來表示了。
這里表示用戶興趣向量有很多種策略,可以基于用戶對操作過的標的物的評分以及時間加權來獲取用戶的加權偏好向量,而不是直接取平均。另外,我們也可以根據用戶操作過的標的物之間的相似度,為用戶構建多個興趣向量(比如對標的物聚類,用戶在某一類上操作過的標的物的向量均值作為用戶在這個類別上的興趣向量),從而更好地表達用戶多方位的興趣偏好。
有了用戶的興趣向量及標的物的興趣向量,可以基于向量相似性計算用戶對標的物的偏好度,再基于偏好度大小來為用戶推薦標的物。
(4)通過交互方式獲取用戶興趣標簽
很多APP在用戶第一次注冊時讓用戶選擇自己的興趣標簽,一旦用戶勾選了自己的興趣標簽,那么這些興趣標簽就是系統為用戶提供推薦的原材料。具體推薦策略與上面的(3)一樣。
(5)用戶的人口統計學特征
用戶在登陸、注冊時提供的關于自身相關的信息、通過運營活動用戶填寫的信息、通過用戶行為利用算法推斷得出的結論,如年齡、性別、地域、收入、愛好、居住地、工作地點等是非常重要的信息。基于這些關于用戶維度的信息,我們可以將用戶特征用向量化表示出來,向量的維度就是可獲取的用戶特征數。
有了用戶特征向量就可以計算用戶相似度,將相似用戶喜歡的標的物推薦給該用戶。
▌3.構建標的物特征表示
標的物的特征,一般可以利用顯式的標簽來表示,也可以利用隱式的向量(當然one-hot編碼也是向量表示,但是不是隱式的)來刻畫,向量的每個維度就是一個隱式的特征項。前面提到某些推薦算法需要計算標的物之間的相似度,下面我們在講標的物的各種特征表示時,也簡單介紹一下標的物之間的相似度計算方法。順便說一下,標的物關聯標的物的推薦范式也需要知道標的物之間的相似度。下面我們從4個方面來詳細講解怎么構建標的物的特征表示。
(1)標的物包含標簽信息
最簡單的方式是將將標簽按照某種序排列,每個標簽看成一個維度,那么每個標的物就可以表示成一個N維的向量了(N是標簽的個數),如果標的物包含某個標簽,向量在相應標簽的分量上的值為1,否則為0,即所謂的one-hot編碼。有可能N非常大(如視頻行業,N可能是幾萬、甚至幾十萬上百萬),這時向量是稀疏向量(一般標的物只有少量的幾個或者幾十個標簽),我們可以采用稀疏向量的表示來優化向量存儲和計算,提升效率。有了標的物基于標簽的向量化表示,很容易基于cosine余弦計算相似度了。
實際上標簽不是這么簡單的,有很多業務標簽是分級的,比如電商(如淘寶),有多級的標簽(見下面圖3),標簽的層級關系形成一顆樹狀結構,這時該怎么向量化呢?最簡單的方案是只考慮葉子節點的標簽(也是最低層級的標簽),基于葉子節點標簽構建向量表示。更復雜的方法,可以基于層級結構構建標簽表示及計算標的物相似度。
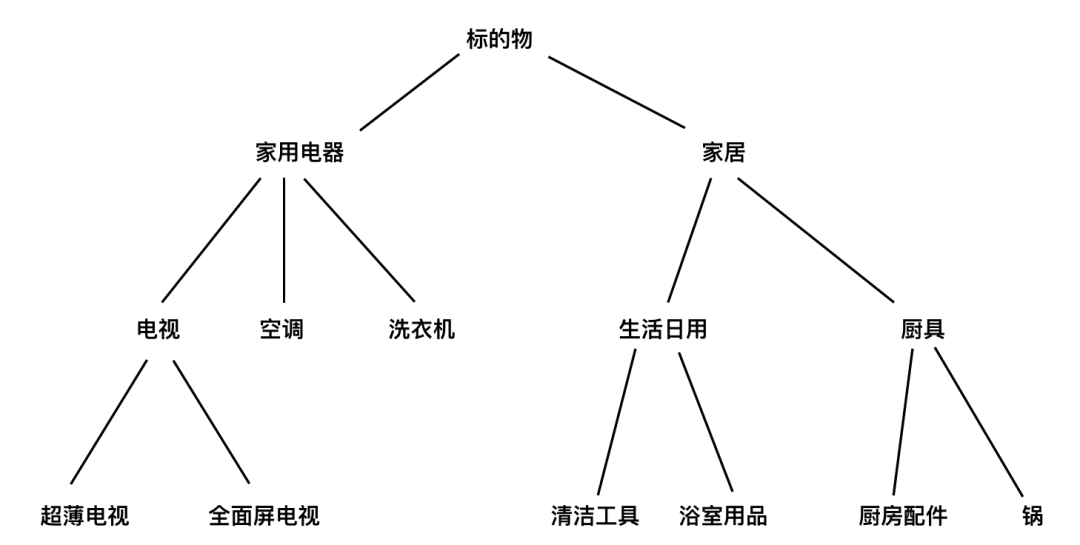
圖3:標簽的層級表示關系
標簽可以是通過算法獲取的,比如通過NLP技術從文本信息中提取關鍵詞作為標簽。對于圖片/視頻,它們的描述信息(標題等)可以提取標簽,另外可以通過目標檢測的方法從圖片/視頻中提取相關對象構建標簽。
標簽可以是用戶打的,很多產品在用戶與標的物交互時可以為標的物打標簽,這些標簽就是標的物的一種刻畫。標簽也可是人工標注的,像Netflix在做推薦時,請了上萬個專家對視頻從上千個維度來打標簽,讓標簽具備非常高的質量。基于這么精細優質的標簽做推薦,效果一定不錯。很多行業的標的物來源于第三方提供商,他們在入駐平臺時會被要求按照某些規范填寫相關標簽信息(比如典型的如電商)。
(2)標的物具備結構化的信息
有些行業標的物是具備結構化信息的,如視頻行業,一般會有媒資庫,媒資庫中針對每個節目會有標題、演職員、導演、標簽、評分、地域等維度數據,這類數據一般存在關系型數據庫中。這類數據,我們可以將一個字段(也是一個特征)作為向量的一個維度,這時向量化表示每個維度的值不一定是數值,但是形式還是向量化的形式,即所謂的向量空間模型(Vector Space Model,簡稱VSM)。這時我們可以通過如下的方式計算兩個標的物之間的相似度。
假設兩個標的物的向量表示分別為:
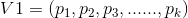
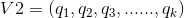
這時這兩個標的物的相似性可以表示為:
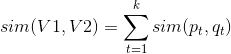
其中代表的是向量的兩個分量之間的相似度。可以采用Jacard相似度等各種方法計算兩個分量之間的相似度。上面公式中還可以針對不同的分量采用不同的權重策略,見下面公式,其中是第t個分量(特征)的權重,具體權重的數值可以根據對業務的理解來人工設置,或者利用機器學習算法來訓練學習得到。
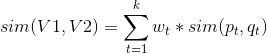
(3)包含文本信息的標的物的特征表示
像今日頭條和手機百度APP這類新聞資訊或者搜索類APP,標的物就是一篇篇的文章(其中會包含圖片或者視頻),文本信息是最重要的信息形式,構建標的物之間的相似性有很多種方法。下面對常用的方法做一些講解說明。
a. 利用TF-IDF將文本信息轉化為特征向量
TF-IDF通過將所有文檔(即標的物)分詞,獲得所有不同詞的集合(假設有M個詞),那么就可以為每個文檔構建一個M維(每個詞就是一個維度)的向量,而該向量中某個詞所在維度的值可以通過統計每個詞在文檔中的重要性來衡量,這個重要性的度量就是TF-IDF。下面我們來詳細說明TF-IDF是怎么計算的。
TF即某個詞在某篇文檔中出現的頻次,用于衡量這個詞在文檔中的重要性,出現次數越多的詞重要性越大,當然我們會提前將“的”、“地”、“啊”等停用詞去掉,這些詞對構建向量是沒有任何實際價值的,甚至是有害的。TF具體計算公式如下,tk是第k個詞,dj是第j個文檔,下式中分子是tk在中出現的次數,分母是dj中詞的總個數。
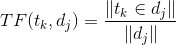
IDF代表的是某個詞在所有文檔中的“區分度”,如果某個詞只在少量幾個文檔中出現,那么它包含的價值就是巨大的(所謂物以稀為貴),如果某個詞在很多文檔中出現,那么它就不能很好地衡量(區分出)這個文檔。下面是IDF的計算公式,其中N是所有文檔的個數,是包含詞的文檔個數,這個公式剛好跟前面的描述是一致的:稀有的詞區分度大。
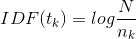
有了上面對TF和IDF的定義,實際的TF-IDF就是上面兩個量的乘積:
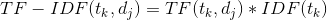
有了基于TF-IDF計算的標的物的向量表示,我們就很容易計算兩個標的物之間的相似度了(cosine余弦相似度)。
b. 利用LDA算法構建文章(標的物)的主題
LDA算法是一類文檔主題生成模型,包含詞、主題、文檔三層結構,是一個三層的貝葉斯概率模型。對于語料庫中的每篇文檔,LDA定義了如下生成過程(generativeprocess):
[1]對每一篇文檔,從主題分布中抽取一個主題;
[2]從上述被抽到的主題所對應的單詞分布中抽取一個單詞;
[3]重復上述過程直至遍歷文檔中的每一個單詞。
我們通過對所有文檔進行LDA訓練,就可以構建每篇文檔的主題分布,從而構建一個基于主題的向量(每個主題就是向量的一個分量,而值就是該主題的概率值),這樣我們就可以利用該向量來計算兩篇文檔的相似度了。主題模型可以理解為一個降維過程,將文檔的詞向量表示降維成主題的向量表示(主題的個數是遠遠小于詞的個數的,所以是降維)。想詳細了解LDA的讀者可以看參考文獻1、2。
c. 利用doc2vec算法構建文本相似度
doc2vec或者叫做 paragraph2vec, sentence embeddings,是一種非監督式算法,可以獲得 句子、段落、文章的稠密向量表達,它是 word2vec 的拓展,2014年被Google的兩位大牛提出,并大量用于文本分類和情感分析中。通過doc2vec學出句子、段落、文章的向量表示,可以通過計算向量之間距離來表達句子、段落、文章之間的相似性。
這里我們簡單描述一下doc2vec的核心思想。doc2vec受word2vec啟發,由它推廣而來,我們先來簡單解釋一下word2vec的思路。
word2vec通過學習一個唯一的向量表示每個詞,每個詞向量作為矩陣W中的一列(W是所有詞的詞向量構成的矩陣),矩陣列可以通過詞匯表為每個詞做索引,排在索引第一位的放到矩陣W的第一列,如此類推。將學習問題轉化為通過上下文詞序列中前幾個詞來預測下一個詞。具體的模型框架如下圖:
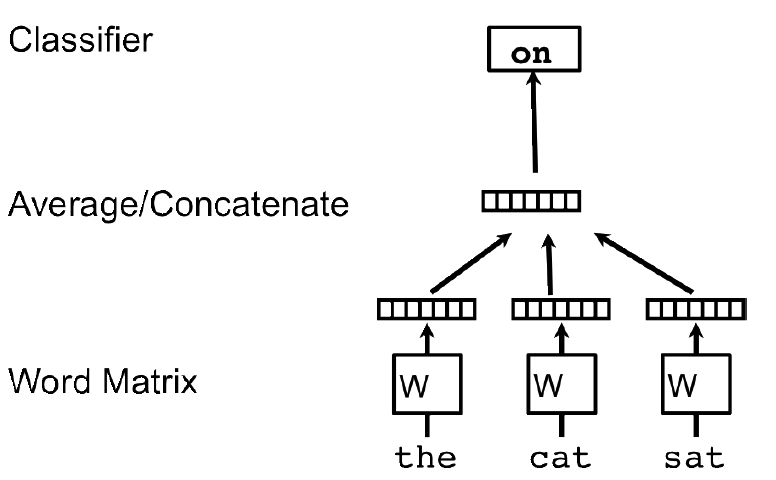
圖4:word2vec算法框架,圖片來源于參考文獻5
簡單來說,給定一個待訓練的詞序列,詞向量模型通過極大化平均對數概率
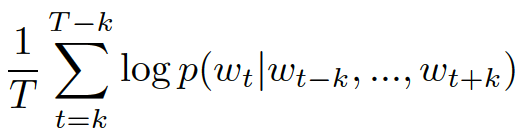
將預測任務通過softmax變換看成一個多分類問題
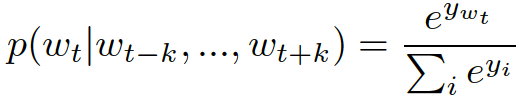
上式中是詞i的歸一化的對數概率,具體用下式來計算,其中U、b是參數,h是通過詞向量的拼接或者平均來構建的
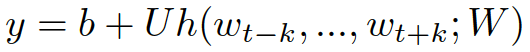
word2vec算法隨機初始化詞向量,通過隨機梯度下降法來訓練神經網絡模型,最終得到每個詞的向量表示。
doc2vec類似地,每個段落/文檔表示為向量,作為矩陣D的一列,每個詞也表示為一個向量,作為矩陣W中的一列。將學習問題轉化為通過上下文詞序列中前幾個詞和段落/文檔來預測下一個詞。將段落/文檔和詞向量通過拼接或者平均來預測句子的下一個詞(下圖是通過“the”、“cat”、“sat”及段落id來預測下一個詞“on”)。在訓練的時候我們固定上下文的長度,用滑動窗口的方法產生訓練集。段落向量/句向量在上下文中共享。
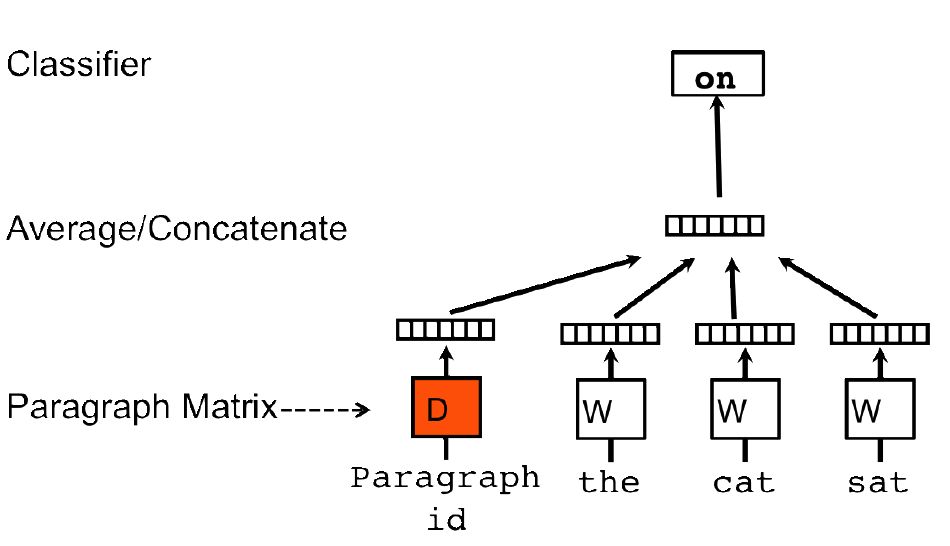
圖5:doc2vec模型結構,圖片來源于參考文獻5
對算法原理感興趣的讀者可以看看參考文獻3、4、5。工程實現上有很多開源框架有word2vec或者doc2vec的實現,比如gensim中就有很好的實現,作者公司就用gensim來做word2vec嵌入用于相似視頻的推薦業務中,效果非常不錯,讀者可以參考https://radimrehurek.com/gensim/models/doc2vec.html。
(4)圖片、音頻、或者視頻信息
如果標的物包含的是圖片、音頻或者視頻信息,處理起來會更加復雜。一種方法是利用它們的文本信息(標題、評論、描述信息、利用圖像技術提取的字幕等文本信息等等,對于音頻,可以通過語音識別轉化為文本)采用上面(3)的技術方案獲得向量化表示。對于圖像或者視頻,也可以利用openCV中的PSNR和SSIM算法來表示視頻特征,也可以計算視頻之間的相似度。另外一種可行的方法是采用圖像、音頻處理技術直接從圖像、視頻、音頻中提取特征進行向量化表示,從而容易計算出相似度。總之,圖片、圖像、音頻都可以轉化為NLP問題或者圖像處理問題(見下面圖6),通過圖像處理和NLP獲得對應的特征表示,從而最終計算出相似度,這里不詳細講解。
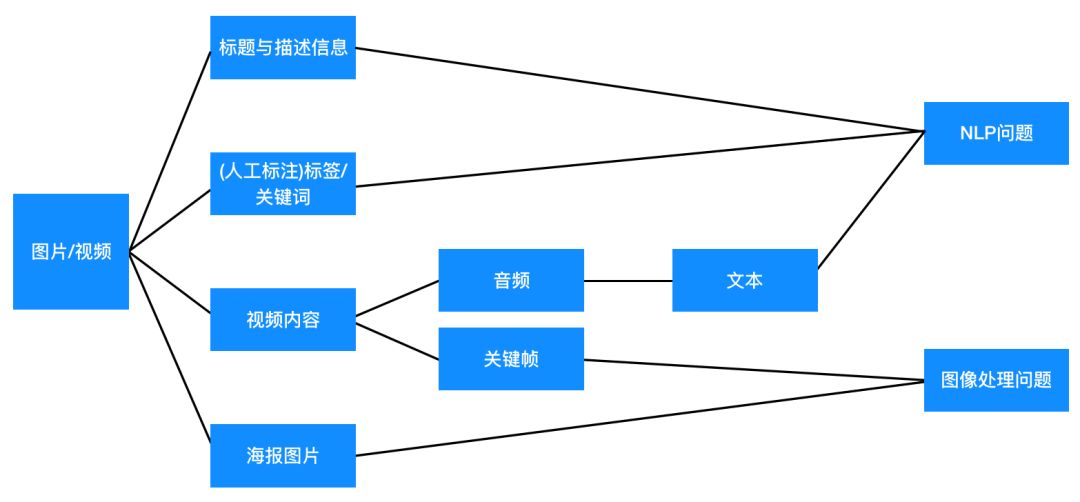
圖6:視頻/圖片問題都可以轉化為
NLP或圖像處理問題
▌4.為用戶做個性化推薦
有了上面用戶和標的物的特征表示,剩下就是基于此為用戶做個性化推薦了,一般有5種方法和策略,下面我們來一一講解。這里的推薦就是完全個性化范式的推薦,為每個用戶生成不一樣的推薦結果。
(1)采用跟基于物品的協同過濾類似的方式推薦
該方法采用基于用戶行為記錄的顯式特征表示用戶特征,通過將用戶操作過的標的物最相似的標的物推薦給用戶,算法原理跟基于物品的協同過濾類似,計算公式甚至是一樣的,但是這里計算標的物相似度是基于標的物的自身信息來計算的,而基于物品的協同過濾是基于用戶對標的物的行為矩陣來計算的。
用戶u對標的物s的喜好度sim(u,s)可以采用如下公式計算,其中U是所有用戶操作過的標的物的列表,是用戶u對標的物的喜好度,是標的物與s的相似度。
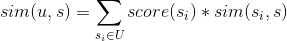
有了用戶對每個標的物的相似度,基于相似度降序排列,就可以取topN推薦給用戶了。
除了采用上面的公式外,我們在推薦時也可以稍作變化,采用最近鄰方法(K-NearestNeighbor, KNN)。對于用戶操作/喜歡過的每個標的物,通過kNN找到最相似的k個標的物。
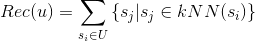
其中是給用戶u的推薦,是標的物最近鄰(最相似)的k個標的物。
(2)采用跟基于用戶協同過濾類似的方法計算推薦
如果我們獲得了用戶的人口統計學向量表示或者基于用戶歷史操作行為獲得了用戶的向量化表示,那么我們可以采用跟基于用戶的協同過濾方法相似的方法來為用戶提供個性化推薦,具體思路如下:
我們可以將與該用戶最相似的用戶喜歡的標的物推薦給該用戶,算法原理跟基于用戶的協同過濾類似,計算公式甚至是一樣的。但是這里計算用戶相似度是基于用戶的人口統計學特征向量表示來計算的(計算用戶向量cosine余弦相似度)或者是基于用戶歷史行為嵌入獲得的特征向量來計算的,而基于用戶的協同過濾是基于用戶對標的物的行為矩陣來計算用戶之間的相似度。
用戶u對標的物s的喜好度sim(u,s)可以采用如下公式計算,其中U是與該用戶最相似的用戶集合,是用戶對標的物s的喜好度,是用戶與用戶u的相似度。
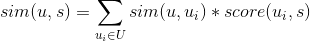
有了用戶對每個標的物的相似度,基于相似度降序排列,就可以取topN推薦給用戶了。
與前面一樣我們也可以采用最近鄰方法(K-NearestNeighbor, KNN)。通過kNN找到最相似的k個用戶,將這些用戶操作/喜歡過的每個標的物推薦給用戶。
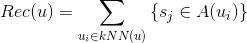
其中是給用戶u的推薦,是用戶相似的k個用戶。是用戶操作/喜歡過的標的物的集合。
(3)基于標的物聚類的推薦
有了標的物的向量表示,我們可以用kmeans等聚類算法將標的物聚類,有了標的物的聚類,推薦就好辦了。從用戶歷史行為中的標的物所在的類別挑選用戶沒有操作行為的標的物推薦給用戶,這種推薦方式是非常直觀自然的。電視貓的個性化推薦就采用了類似的思路。具體計算公式如下,其中是給用戶u的推薦,H是用戶的歷史操作行為集合,Cluster(s)是標的物s所在的聚類。
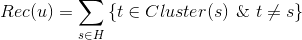
(4)基于向量相似的推薦
不管是前面提到的用戶的顯示的興趣特征(利用標簽來衡量用戶興趣)或者是向量式的興趣特征(將用戶的興趣投影到向量空間),我們都可以獲得用戶興趣的向量表示。
如果我們獲得了用戶的向量表示和標的物的向量表示,那么我們就可以通過向量的cosine余弦相似度計算用戶與標的物之間的相似度。一樣地,有了用戶對每個標的物的相似度,基于相似度降序排列,就可以取topN推薦給用戶了。
基于向量的相似的推薦,需要計算用戶向量與每個標的物向量的相似性。如果標的物數量較多,整個計算過程還是相當耗時的。同樣地,計算標的物最相似的K個標的物,也會涉及到與每個其他的標的物計算相似度,也是非常耗時的。整個計算過程的時間復雜度是,其中N是標的物的總個數。
上述復雜的計算過程可以利用Spark等分布式計算平臺來加速計算。對于T+1級(每天更新一次推薦結果)的推薦服務,利用Spark事先計算好,將推薦結果存儲起來供前端業務調用是可以的。
另外一種可行的策略是利用高效的向量檢索庫,在極短時間(一般幾毫秒或者幾十毫秒)內為用戶索引出topN最相似的標的物。目前FaceBook開源的FAISS庫(https://github.com/facebookresearch/faiss)就是一個高效的向量搜索與聚類庫,可以在毫秒級響應查詢及聚類需求,因此可以用于個性化的實時推薦。目前國內有很多公司將該庫用到了推薦業務上。
FAISS庫適合稠密向量的檢索和聚類,所以對于利用LDA、Doc2vector算法構建向量表示的方案是實用的,因為這些方法構建的是稠密向量。而對于TF-IDF及基于標簽構建的向量化表示,就不適用了,這兩類方法構建的都是稀疏的高維向量。
(5)基于標簽的反向倒排索引做推薦
該方法在《推薦系統產品與算法概述》這篇文章中也簡單做了介紹,這里再簡單說一下,并且給出具體的計算公式。基于標的物的標簽和用戶的歷史興趣,我們可以構建出用戶基于標簽興趣的畫像及標簽與標的物的倒排索引查詢表(熟悉搜索的同學應該不難理解)。基于該反向索引表及用戶的興趣畫像,我們就可以為用戶做個性化推薦了。該類算法其實就是基于標簽的召回算法。
具體推薦過程是這樣的(見下面圖7):從用戶畫像中獲取用戶的興趣標簽,基于用戶的興趣標簽從倒排索引表中獲取該標簽對應的標的物,這樣就可以從用戶關聯到標的物了。其中用戶的每個興趣標簽及標簽關聯到的標的物都是有權重的。
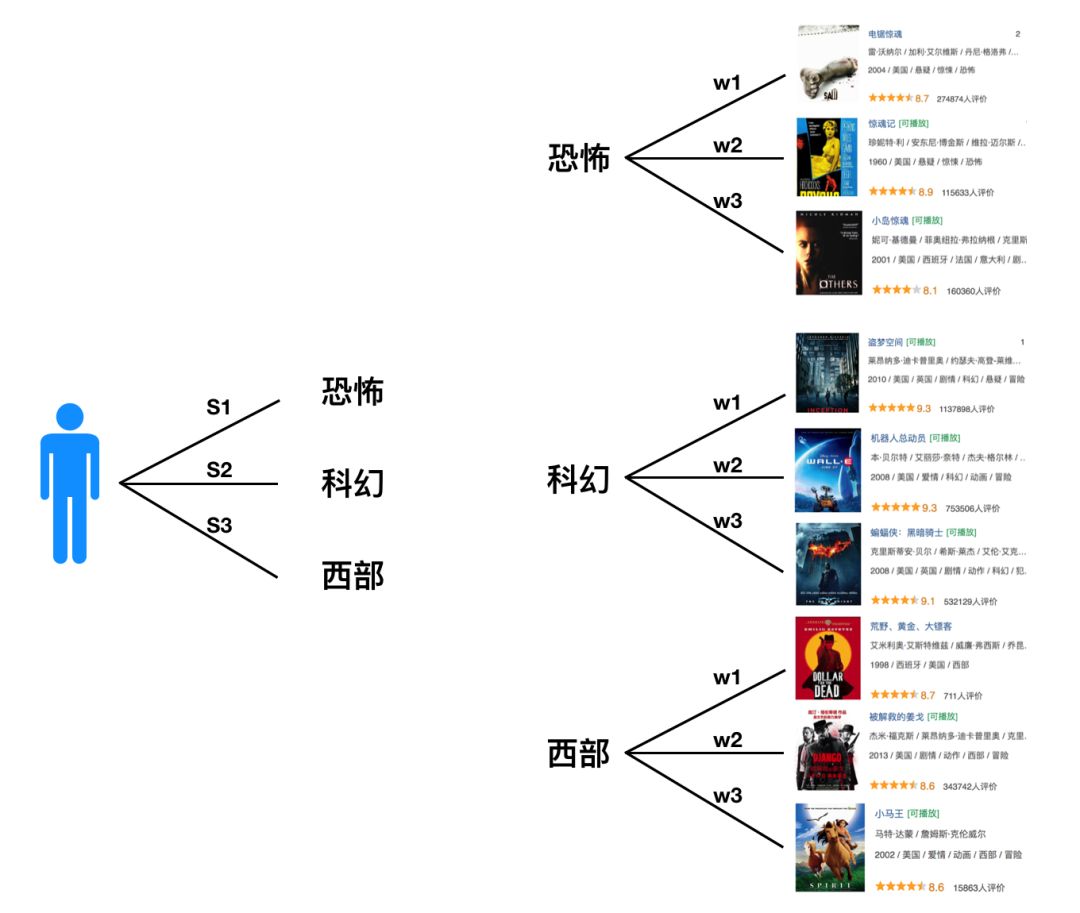
圖7:基于倒排索引的電影推薦
假設用戶的興趣標簽及對應的標簽權重如下,其中是標簽,是用戶對標簽的偏好權重。
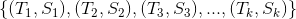
假設標簽關聯的標的物分別為
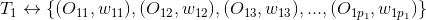
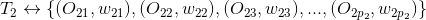
......
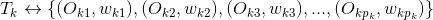
其中、分別是標的物及對應的權重,那么
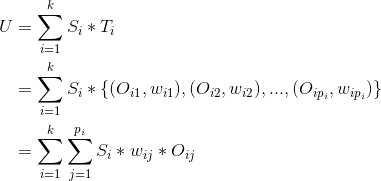
上式中U是用戶對標的物的偏好集合,我們這里將標的物看成向量空間的基,所以有上面的公式。不同的標簽可以關聯到相同的標的物(因為不同的標的物可以有相同的標簽),上式中最后一個等號右邊需要合并同類項,將相同基前面的系數相加。合并同類項后,標的物(基)前面的數值就是用戶對該標的物的偏好程度了,我們對這些偏好程度降序排列,就可以為用戶做topN推薦了。
到此我們介紹完了基于內容的推薦算法的核心原理,那么這些算法是怎么應用到真實的產品中的呢?有哪些可行的推薦產品形態?這就是下節的主要內容。
03基于內容的推薦算法應用場景
基于內容的推薦是最古老的一類推薦算法,在整個推薦系統發展史上具有舉足輕重的地位。雖然它的效果可能沒有協同過濾及新一代推薦算法好,但是它們還是非常有應用價值的,甚至是必不可少的。基于內容的推薦算法主要用在如下幾類場景。
▌1.完全個性化推薦
就是基于內容特征來為每個用戶生成不同的推薦結果,我們常說的推薦系統就是指這類推薦形態。上面一節第四部分已經完整地講解了怎么為用戶做個性化推薦,這里不再贅述。
▌2.標的物關聯標的物推薦
標的物關聯標的物的推薦也是工業界最常用的推薦形態,大量用于真實產品中。
上一節第三部分講了很多怎么構建標的物之間相似度的方法,其實這些方法可以直接用來做標的物關聯標的物的推薦,只要我們將與某個標的物最相似的topN的標的物作為關聯推薦即可。
▌3.配合其他推薦算法
由于基于內容的推薦算法在精準度上不如協同過濾等算法,但是可以更好的適應冷啟動,所以在實際業務中基于內容的推薦算法會配合其他算法一起服務于用戶,最常用的方法是采用級聯的方式,先給用戶協同過濾的推薦結果,如果該用戶行為少沒有協同過濾推薦結果,就為該用戶推薦基于內容的推薦算法產生的推薦結果。
▌4.主題推薦
如果我們有標的物的標簽信息,并且基于標簽系統構建了一套推薦算法,那么我們就可以將用戶喜歡的標簽采用主題的方式推薦給用戶,每個主題就是用戶的一個興趣標簽。通過一些列主題的羅列展示,讓用戶從中篩選自己感興趣的內容(見下面圖8)。Netflix的首頁大量采用基于主題的推薦模式。主題推薦的好處是可以將用戶所有的興趣點按照興趣偏好大小先后展示出來,可解釋性強,并且讓用戶有更多維度的自由選擇空間。
當然,在真實產品中可以采用比下面圖8這種簡單標簽直接展示更好的方式。具體來說,我們可以為每個標簽通過人工編輯生成一句更有表達空間的話(如武俠標簽,可以采用“江湖風云再起,各大門派齊聚論劍”這樣更有深度的表述),具體前端展示時映射到人工填充的話而不是直接展示原來的標簽。
圖8:電視貓主題推薦(紅色圈圈中就是基于標簽的用戶興趣)
▌5.給用戶推薦標簽
另外一種可行的推薦策略是不直接給用戶推薦標的物,而是給用戶推薦標簽,用戶通過關注推薦的標簽,自動獲取具備該標簽的標的物。除了可以通過推薦的標簽關聯到標的物獲得直接推薦標的物類似的效果外,間接地通過用戶對推薦的標簽的選擇、關注進一步獲得了用戶的興趣偏好,這是一種可行的推薦產品實現方案。
04基于內容的推薦算法的優勢與缺點
基于內容的推薦算法算是一類比較直觀易懂的算法,目前在工業級推薦系統中有大量的使用場景,在本節我們對基于內容的推薦算法的優缺點加以說明,方便讀者在實踐中選擇取舍,構建適合業務場景的內容推薦系統。
▌1.優點
基于上面的介紹,基于內容的推薦算法是非常直觀的,具體來說,它有如下6個優點。
(1)可以很好的識別用戶的口味
該算法完全基于用戶的歷史興趣來為用戶推薦,推薦的標的物也是跟用戶歷史興趣相似的,所以推薦的內容一定是符合用戶的口味的。
(2)非常直觀易懂,可解釋性強
基于內容的推薦算法基于用戶的興趣為用戶推薦跟他興趣相似的標的物,原理簡單,容易理解。同時,由于是基于用戶歷史興趣推薦跟興趣相似的標的物,用戶也非常容易接受和認可。
(3)可以更加容易的解決冷啟動
只要用戶有一個操作行為,就可以基于內容為用戶做推薦,不依賴其他用戶行為。同時對于新入庫的標的物,只要它具備metadata信息等標的物相關信息,就可以利用基于內容的推薦算法將它分發出去。因此,對于強依賴于UGC內容的產品(如抖音、快手等),基于內容的推薦可以更好地對標的物提供方進行流量扶持。
(4)算法實現相對簡單
基于內容的推薦可以基于標簽維度做推薦,也可以將標的物嵌入向量空間中,利用相似度做推薦,不管哪種方式,算法實現較簡單,有現成的開源的算法庫供開發者使用,非常容易落地到真實的業務場景中。
(5)對于小眾領域也能有比較好的推薦效果
對于冷門小眾的標的物,用戶行為少,協同過濾等方法很難將這類內容分發出去,而基于內容的算法受到這種情況的影響相對較小。
(6)非常適合標的物快速增長的有時效性要求的產品
對于標的物增長很快的產品,如今日頭條等新聞資訊類APP,基本每天都有幾十萬甚至更多的標的物入庫,另外標的物時效性也很強。新標的物一般用戶行為少,協同過濾等算法很難將這些大量實時產生的新標的物推薦出去,這時就可以采用基于內容的推薦算法更好地分發這些內容。
▌2.缺點
雖然基于內容的推薦實現相對容易,解釋性強,但是基于內容的推薦算法存在一些不足,導致它的效果及應用范圍受到一定限制。主要的問題有如下4個:
(1)推薦范圍狹窄,新穎性不強
由于該類算法只依賴于單個用戶的行為為用戶做推薦,推薦的結果會聚集在用戶過去感興趣的標的物類別上,如果用戶不主動關注其他類型的標的物,很難為用戶推薦多樣性的結果,也無法挖掘用戶深層次的潛在興趣。特別是對于新用戶,只有少量的行為,為用戶推薦的標的物較單一。
(2)需要知道相關的內容信息且處理起來較難
內容信息主要是文本、視頻、音頻,處理起來費力,相對難度較大,依賴領域知識。同時這些信息更容易有更大概率含有噪音,增加了處理難度。另外,對內容理解的全面性、完整性及準確性會影響推薦的效果。
(3)較難將長尾標的物分發出去
基于內容的推薦需要用戶對標的物有操作行為,長尾標的物一般操作行為非常少,只有很少用戶操作,甚至沒有用戶操作。由于基于內容的推薦只利用單個用戶行為做推薦,所以更難將它分發給更多的用戶。
(4)推薦精準度不太高
基于工業界的實踐經驗,相比協同過濾算法,基于內容的推薦算法精準度要差一些。
05算法落地需要關注的重要問題
基于內容的推薦算法雖然容易理解,實現起來相對簡單,但在落地到真實業務場景中,有很多問題需要思考解決。下面這些問題是在落地基于內容推薦算法時必須思考的,這里將他們列舉出來,并提供一些簡單的建議,希望可以幫到讀者。
▌1.內容來源的獲取
對于基于內容的推薦來說,有完整的、高質量的內容信息是可以構建精準的推薦算法的基礎,那我們有哪些方法可以獲取內容來源呢?下面這些策略是主要獲取內容(包括標的物內容和用戶相關內容)來源的手段。
(1)標的物“自身攜帶”的信息
標的物在上架時,第三方會準備相關的內容信息,如天貓上的商品在上架時會補充很多必要的信息。對于視頻來說,各類metadata信息也是視頻入庫時需要填充的信息。我們要做的是增加對新標的物入庫的監控和審核,及時發現信息不全的情況并做適當處理。
(2)通過爬蟲獲取標的物相關信息
通過爬蟲爬取的信息可以作為標的物信息的補充,特別是補充上面(1)不全的信息。有了更完整的信息就可以獲得更好的特征表示。
(3)通過人工標注數據
往往人工標注的數據價值密度高,通過人工精準的標注可以大大提升算法推薦的精準度。但是人工標注成本太大。
(4)通過運營活動或者產品交互讓用戶填的內容
通過抽獎活動讓用戶填寫家庭組成、興趣偏好等,在用戶開始注冊時讓用戶填寫興趣偏好特征,這些都是獲取內容的手段。
(5)通過收集用戶行為直接獲得或者預測推斷出的內容
通過請求用戶GPS位置知道用戶的活動軌跡,用戶購物時填寫收貨地址,用戶綁定的身份證和銀行卡等,通過用戶操作行為預測出用戶的興趣偏好,這些方法都可以獲得部分用戶數據。
(6)通過與第三方合作或者產品矩陣之間補充信息
目前中國有大數據交易市場,通過正規的數據交易或者跟其他公司合作,在不侵犯用戶隱私的情況下,通過交換數據可以有效填補自己產品上缺失的數據。
如果公司有多個產品,新產品可以借助老產品的巨大用戶基數,將新產品的用戶與老產品用戶關聯起來(id-maping或者賬號打通),這樣老產品上豐富的用戶行為信息可以賦能給新產品。
▌2.怎么利用負反饋
用戶對標的物的操作行為不一定代表正向反饋,有可能是負向的。比如點開一個視頻,看了不到幾秒就退出來了,明顯表明用戶不喜歡。有很多產品會在用戶交互中直接提供負向反饋能力,這樣可以收集到更多負向反饋。下面是今日頭條和百度APP推薦的文章,右下角有一個小叉叉(見下面圖9中紅色圈圈),點擊后展示上面的白色交互區域,讀者可以勾選幾類不同的負向反饋機制。
圖9:負向反饋的交互形式:利用用戶負向反饋來優化產品體驗
負向反饋代表用戶強烈的不滿,因此如果推薦算法可以很好的利用這些負向反饋就能夠大大提升推薦系統的精準度和滿意度。基于內容的推薦算法整合負向反饋的方式有如下幾種:
(1) 將負向反饋整合到算法模型中
在構建算法模型中整合負向反饋,跟正向反饋一起學習,從而更自然地整合負向反饋信息。
(2) 采用事后過濾的方式
先給用戶生成推薦列表,再從該推薦列表中過濾掉與負向反饋關聯的或者相似的標的物。
(3) 采用事前處理的方式
從待推薦的候選集中先將與負向反饋相關聯或者相似的標的物剔除掉,然后再進行相關算法的推薦。
▌3.興趣隨時間變化
用戶的興趣不是一成不變的,一般用戶的興趣是隨著時間變化的,那怎么在算法中整合用戶的興趣變化呢?可行的策略是對用戶的興趣根據時間衰減,最近的行為給予最大的權重。還可以分別給用戶建立短期興趣特征和長期興趣特征,在推薦時既考慮短期興趣又考慮長期興趣,最終推薦列表中整合兩部分的推薦結果。
對于新聞資訊等這類時效性強的產品,能夠整合用戶的實時興趣變化可以大大提升用戶體驗,這也是現在信息流類推薦產品大行其道的原因。
▌4.數據清洗
基于內容的推薦算法依賴于標的物相關的描述信息,這些信息更多的是以文本的形式存在,這就涉及到自然語言處理了,文本中可能會存在很多歧義、符號、臟數據,我們需要事先對數據進行很好的處理,才能讓后續的推薦算法產生好的效果。
▌5.加速計算與節省資源
在實際推薦算法落地時,我們會事先為每個標的物計算N(=50)個最相似的標的物,事先將計算好的標的物存起來,減少時間和空間成本,方便后續更好地做推薦。同時也可以利用各種分布式計算平臺和快速查詢平臺(如Spark、FAISS庫等)加速計算過程。另外,算法開發過程中盡量做到模塊化,對業務做抽象封裝,這可以大大提升開發效率,并且可能會節省很多資源。
▌6.怎么解決基于內容的推薦越推越窄的問題
前面提到基于內容的推薦存在越推越窄的缺點,那怎么避免或者減弱這種影響呢?當然用協同過濾等其他算法是一個有效的方法。另外,我們可以給用戶做興趣探索,為用戶推薦興趣之外的特征關聯的標的物,通過用戶的反饋來拓展用戶興趣空間,這類方法就是強化學習中的EE方法。如果我們構造了標的物的知識圖譜系統,我們就可以通過圖譜拓展標的物更遠的聯系,通過長線的相關性來做推薦,同樣可以有效解決越推越窄的問題。
▌7.工程落地技術選型
本篇文章主要講的是基于內容的推薦系統的算法實現原理,具體工程實踐時,需要考慮到數據處理、模型訓練、分布式計算等技術,當前很多開源方案可以使用,常用的如Spark mllib,scikit-learn,Tensorflow,pytorch,gensim等,這些工具都封裝了很多數據處理、特征提取、機器學習算法,我們可以基于第二節的算法思路來落地實現。
▌8.業務的安全性
除了技術外,在推薦產品落地中還需要考慮推薦的標的物的安全性,避免推薦反動、色情、標題黨、低俗內容,這些就需要基于NLP或者CV技術對文本或者視頻進行分析過濾。如果是UGC平臺型的產品,還需要考慮怎么激勵優質內容創作者,讓好的內容得到更多的分發機會,同時對產生劣質內容的創作者采取一定的懲罰措施,比如限制發文頻率、禁止一段時間的發文權限等。
寫在最后
本文作者基于自己的實踐經驗總結了常用的基于內容的推薦算法及落地場景,并對基于內容的推薦算法的優缺點及實踐過程中需要關注的問題進行了分析討論。基于內容的推薦算法一般用于推薦召回階段,通過內容特征來為用戶選擇可能喜歡的內容。
-
計算
+關注
關注
2文章
450瀏覽量
38806 -
推薦算法
+關注
關注
0文章
47瀏覽量
10003 -
nlp
+關注
關注
1文章
488瀏覽量
22038
原文標題:一文全面了解基于內容的推薦算法
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
【大語言模型:原理與工程實踐】探索《大語言模型原理與工程實踐》2.0
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+一本介紹基礎硬件算法模塊實現的好書
【「從算法到電路—數字芯片算法的電路實現」閱讀體驗】+內容簡介
應用于聲音振動的高級信號處理算法-超越FFT pdf
算法工程師(通信 視頻 音頻 圖像)-廣東
應用于G3-PLC的幀同步算法的設計與實現

基于內容的推薦算法概覽

人工魚群算法應用于飼料配方優化





 工商網監
工商網監
評論