") 深度強化學習給推薦系統(tǒng)以及CTR預估工業(yè)界帶來的最新進展
深度強化學習給推薦系統(tǒng)以及CTR預估工業(yè)界帶來的最新進展
導讀:本文將介紹在深度學習的強力驅動下,給推薦系統(tǒng)工業(yè)界所帶來的最前沿的變化。本文主要根據(jù)幾大頂會2019的最新論文,總結一下深度強化學習給推薦系統(tǒng)以及CTR預估工業(yè)界帶來的最新進展。
凡是Google出品,必屬精品。遙想當年(其實也就近在2016),YoutubeDNN[1]以及WDL[2]的橫空出世引領了推薦系統(tǒng)以及CTR預估工業(yè)界潮流至今,掀起了召回層與排序層算法大規(guī)模優(yōu)雅而高效地升級深度學習模型的浪潮。發(fā)展至今其實已經(jīng)形成了工業(yè)界推薦系統(tǒng)與廣告CTR預估的龐大家族群,具體可以參見下文中的家族圖譜。
https://zhuanlan.zhihu.com/p/69050253
當然,本文的重點不是回首往事。好漢不提當年勇,而是立足當下看看接下來推薦系統(tǒng)和CTR預估工業(yè)界的路在何方。起因就在于Google先后在WSDM 2019和IJCAI 2019發(fā)表了極具工業(yè)界風格應用強化學習的論文,而且聲稱已經(jīng)在Youtube推薦排序層的線上實驗中相對線上已有的深度學習模型獲得了顯著的收益。因此,本文就總結一下幾大頂會2019上強化學習應用于推薦系統(tǒng)和CTR預估工業(yè)界的最新進展,也歡迎各位有經(jīng)驗的同行多多交流共同進步。
眾所周知,強化學習雖然在圍棋、游戲等領域大放異彩,但是在推薦系統(tǒng)以及CTR預估上的應用一直有很多難點尚未解決。一方面是因為強化學習與推薦系統(tǒng)結合的探索剛剛開始,目前的方案尚未像傳統(tǒng)機器學習升級深度學習那樣效果顯著,升級強化學習在效果上相對已有的深度學習模型暫時還無法做到有質(zhì)的飛躍;另外一方面,就是離線模型訓練與線上實驗在線學習環(huán)境搭建較為復雜。這就造成了目前在工業(yè)界應用強化學習模型性價比并不高。而且尷尬的是,很多論文在升級RL比較效果的時候使用的Baseline都是傳統(tǒng)機器學習算法而不是最新的深度學習模型,其實從某種程度上來說是很難讓人信服的。
所以,Google這兩篇強化學習應用于YouTube推薦論文的出現(xiàn)給大家?guī)砹吮容^振奮人心的希望。首先,論文中宣稱效果對比使用的Baseline就是YouTube推薦線上最新的深度學習模型;其次,兩篇論文從不同的指標維度都帶來了比較明顯的效果增長。而且其中一篇論文的作者Minmin Chen大神在Industry Day上也提到線上實驗效果顯示這個是YouTube單個項目近兩年來最大的reward增長。這雖然不代表著強化學習與推薦系統(tǒng)的結合方案已經(jīng)很成熟了,至少給大家?guī)砹艘恍┰诠I(yè)界積極嘗試的動力。
Top-K Off-Policy Correction for a REINFORCE Recommender System,WSDM 2019
本文的主要亮點是提出了一種Top-K的Off-Policy修正方案將RL中Policy-Gradient類算法得以應用在動作空間數(shù)以百萬計的Youtube在線推薦系統(tǒng)中。
眾所周知[1],Youtube推薦系統(tǒng)架構主要分為兩層:召回和排序。本文中的算法應用在召回側。建模思路與RNN召回類似,給定用戶的行為歷史,預測用戶下一次的點擊item。受限于On-Policy方法對系統(tǒng)訓練架構要求復雜,所以本文中轉而采用Off-Policy的訓練策略。也就是說并不是根據(jù)用戶的交互進行實時的策略更新,而是根據(jù)收集到日志中用戶反饋進行模型訓練。
這種Off-Policy的訓練方式會給Policy-Gradient類的模型訓練帶來一定的問題,一方面策略梯度是由不同的policy計算出來的;另一方面同一個用戶的行為歷史也收集了其他召回策略的數(shù)據(jù)。所以文中提出了一種基于importance weighting的Off-Policy修正方案,針對策略梯度的計算進行了一階的近似推導。
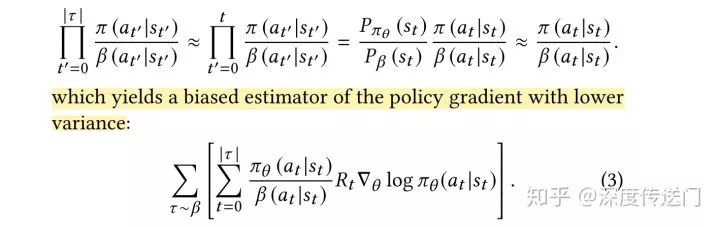
因為是基于用戶的交互歷史預測下一個用戶點擊的item,所以文中也采用RNN針對用戶State的轉換進行建模。文中提到實驗了包括LSTM、GRU等RNN單元,發(fā)現(xiàn)Chaos Free的RNN單元因為穩(wěn)定高效而使用起來效果最好。
在上述的策略修正公式(3)中最難獲取到的是用戶的行為策略,理想情況下是收集日志的時候同時把用戶相應的用戶策略也就是點擊概率給收集下來,但由于策略不同等客觀原因文中針對用戶的行為策略使用另外一組θ'參數(shù)進行預估,而且防止它的梯度回傳影響主RNN網(wǎng)絡的訓練。

另外,由于在推薦系統(tǒng)中,用戶可以同時看到k個展示給用戶的候選item,用戶可能同時與一次展示出來的多個item進行交互。因此需要擴展策略根據(jù)用戶的行為歷史預測下一次用戶可能點擊的top-K個item。
假設同時展示K個不重復item的reward獎勵等于每個item的reward的之和,根據(jù)公式推導我們可以得到Top-K的Off-Policy修正的策略梯度如下,與上面Top 1的修正公式相比主要是多了一個包含K的系數(shù)。也就是說,隨著K的增長,策略梯度會比原來的公式更快地降到0。

從實驗結果的角度,文中進行了一系列的實驗進行效果比較和驗證,其中Top-K的Off-Policy修正方案帶來了線上0.85%的播放時長提升。而且前文也提到過,Minmin Chen大神在Industry Day上也提到線上實驗效果顯示這個是YouTube單個項目近兩年來最大的reward增長。
另外,在最新一期的Google AI Blog[3]上,宣布提出了一種基于強化學習Off-Policy的分類方法,可以預測出哪種機器學習模型會產(chǎn)生最好結果。感興趣的可以繼續(xù)延伸閱讀一下。
Reinforcement Learning for Slate-based Recommender Systems: A Tractable Decomposition and Practical Methodology,IJCAI 2019
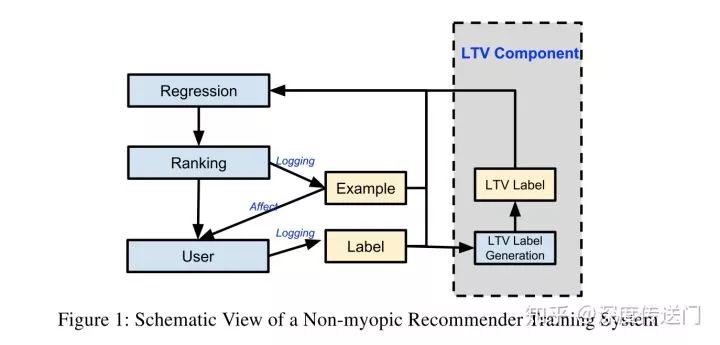
這篇文章相比于第一篇文章時間要晚一點,提出的方法也不盡相同,不過類似的是都宣稱在Youtube線上推薦系統(tǒng)上取得了不錯的效果。主要貢獻是提出了一種名為SLATEQ的Q-Learning算法,優(yōu)化推薦系統(tǒng)里面同時展示給用戶多個item情況的長期收益LTV(Long-term Value)。
這里首先講一下這篇文章與第一篇文章的不同,首先,第一篇文章假設了在推薦系統(tǒng)中同時展示K個不重復item(本文中稱為Slate)的獎勵reward等于每個item的reward的之和,這個在本文中認為實際上是不合理的,因此建模了Slate的LTV和單個item的LTV之間的關系;其次,本文顯式的建模與評估了整個系統(tǒng)LTV的收益。
從系統(tǒng)架構的角度,本文擴展了Youtube現(xiàn)有的只注重即時收益的ranker,也就是針對CTR等指標以及長期收益LTV進行多目標前向深度網(wǎng)絡學習。值得注意的是,為了保證線上實驗的公正性,這里除了多目標外,其他與Youtube線上的特征以及網(wǎng)絡參數(shù)都完全一樣。
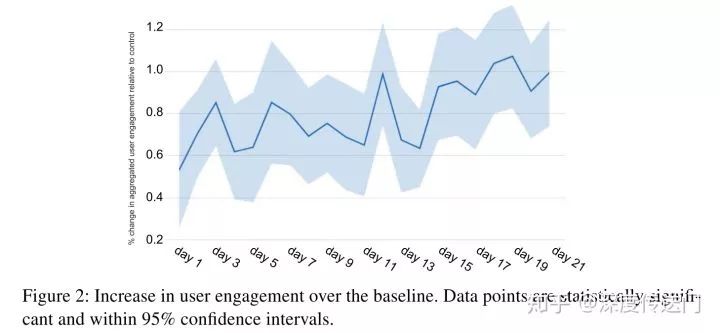
最后實驗部分,本文中評估的是User engagement,可以從下圖中看到效果提升是明顯且穩(wěn)定的。
其他業(yè)界進展
除了Google的上述兩篇論文外,工業(yè)界其他公司也在積極嘗試強化學習在推薦系統(tǒng)中的實戰(zhàn),下面主要簡要列出來一些到目前為止的進展:
Generative Adversarial User Model for Reinforcement Learning Based Recommendation System,ICML 2019
在螞蟻金服被 ICML 2019 接收的這篇論文中,作者們提出用生成對抗用戶模型作為強化學習的模擬環(huán)境,先在此模擬環(huán)境中進行線下訓練,再根據(jù)線上用戶反饋進行即時策略更新,以此大大減少線上訓練樣本需求。此外,作者提出以集合(set)為單位而非單個物品(item)為單位進行推薦,并利用 Cascading-DQN 的神經(jīng)網(wǎng)絡結構解決組合推薦策略搜索空間過大的問題[1]。
Virtual-Taobao: Virtualizing real-world online retail environment for reinforcement learning,AAAI 2019
阿里 at AAAI 2019,“虛擬淘寶”模擬器,利用RL與GAN規(guī)劃最佳商品搜索顯示策略,在真實環(huán)境中讓淘寶的收入提高2%。美中不足的是baseline仍然是傳統(tǒng)監(jiān)督學習而不是深度學習方案。
Large-scale Interactive Recommendation with Tree-structured Policy Gradient,AAAI 2019
-
算法
+關注
關注
23文章
4624瀏覽量
93110 -
強化學習
+關注
關注
4文章
268瀏覽量
11273
原文標題:強化學習大規(guī)模應用還遠嗎?Youtube推薦已強勢上線
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
相關推薦
風光互補技術及應用新進展
風光互補技術原理及最新進展
DIY懷表設計正式啟動,請關注最新進展。
車聯(lián)網(wǎng)技術的最新進展
深度強化學習實戰(zhàn)
VisionFive 2 AOSP最新進展即將發(fā)布!
工業(yè)機器人市場的最新進展淺析
不同神經(jīng)網(wǎng)絡量子態(tài)的最新進展以及面臨的挑戰(zhàn)
關于深度學習的最新進展
ASML***的最新進展






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論