 哈工大訊飛聯合實驗室發布基于全詞覆蓋的中文BERT預訓練模型
哈工大訊飛聯合實驗室發布基于全詞覆蓋的中文BERT預訓練模型
為了進一步促進中文自然語言處理的研究發展,哈工大訊飛聯合實驗室發布基于全詞覆蓋(Whole Word Masking)的中文BERT預訓練模型。我們在多個中文數據集上得到了較好的結果,覆蓋了句子級到篇章級任務。同時,我們對現有的中文預訓練模型進行了對比,并且給出了若干使用建議。我們歡迎大家下載試用。
下載地址:https://github.com/ymcui/Chinese-BERT-wwm
技術報告:https://arxiv.org/abs/1906.08101

摘要
基于Transformers的雙向編碼表示(BERT)在多個自然語言處理任務中取得了廣泛的性能提升。近期,谷歌發布了基于全詞覆蓋(Whold Word Masking)的BERT預訓練模型,并且在SQuAD數據中取得了更好的結果。應用該技術后,在預訓練階段,同屬同一個詞的WordPiece會被全部覆蓋掉,而不是孤立的覆蓋其中的某些WordPiece,進一步提升了Masked Language Model (MLM)的難度。在本文中我們將WWM技術應用在了中文BERT中。我們采用中文維基百科數據進行了預訓練。該模型在多個自然語言處理任務中得到了測試和驗證,囊括了句子級到篇章級任務,包括:情感分類,命名實體識別,句對分類,篇章分類,機器閱讀理解。實驗結果表明,基于全詞覆蓋的中文BERT能夠帶來進一步性能提升。同時我們對現有的中文預訓練模型BERT,ERNIE和本文的BERT-wwm進行了對比,并給出了若干使用建議。預訓練模型將發布在:https://github.com/ymcui/Chinese-BERT-wwm
簡介
Whole Word Masking (wwm),暫翻譯為全詞Mask,是谷歌在2019年5月31日發布的一項BERT的升級版本,主要更改了原預訓練階段的訓練樣本生成策略。簡單來說,原有基于WordPiece的分詞方式會把一個完整的詞切分成若干個詞綴,在生成訓練樣本時,這些被分開的詞綴會隨機被[MASK]替換。在全詞Mask中,如果一個完整的詞的部分WordPiece被[MASK]替換,則同屬該詞的其他部分也會被[MASK]替換,即全詞Mask。
同理,由于谷歌官方發布的BERT-base(Chinese)中,中文是以字為粒度進行切分,沒有考慮到傳統NLP中的中文分詞(CWS)。我們將全詞Mask的方法應用在了中文中,即對組成同一個詞的漢字全部進行[MASK]。該模型使用了中文維基百科(包括簡體和繁體)進行訓練,并且使用了哈工大語言技術平臺LTP(http://ltp.ai)作為分詞工具。
下述文本展示了全詞Mask的生成樣例。

基線測試結果
我們選擇了若干中文自然語言處理數據集來測試和驗證預訓練模型的效果。同時,我們也對近期發布的谷歌BERT,百度ERNIE進行了基準測試。為了進一步測試這些模型的適應性,我們特別加入了篇章級自然語言處理任務,來驗證它們在長文本上的建模效果。
以下是我們選用的基準測試數據集。
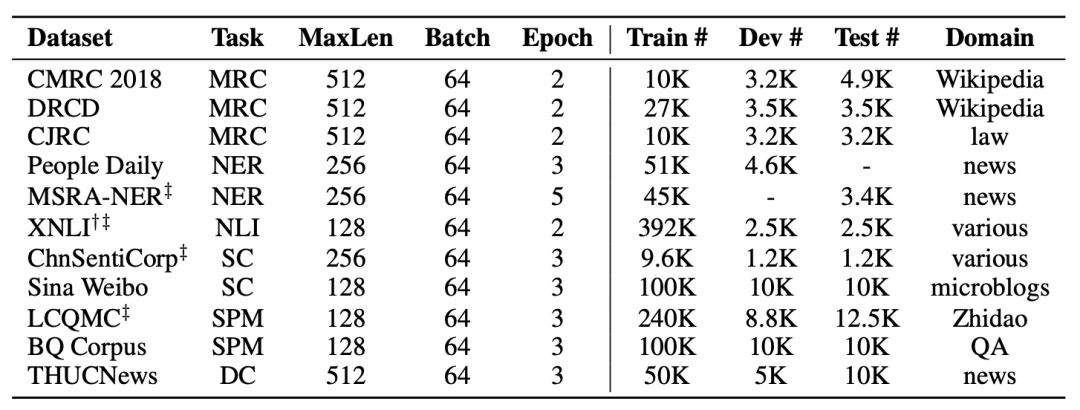
我們列舉其中部分實驗結果,完整結果請查看我們的技術報告。為了確保結果的穩定性,每組實驗均獨立運行10次,匯報性能最大值和平均值(括號內顯示)。
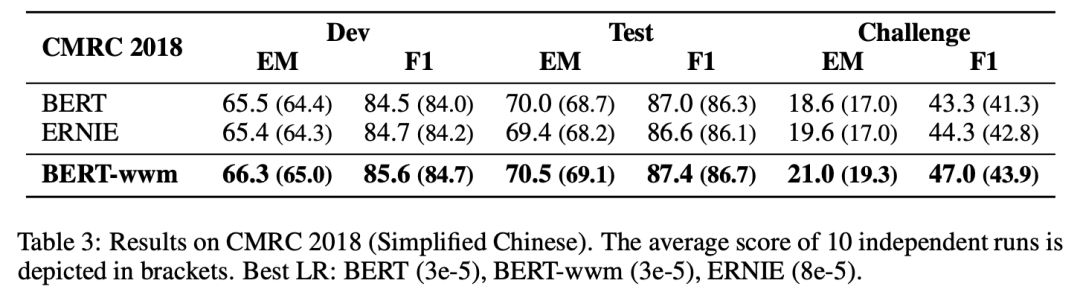
▌中文簡體閱讀理解:CMRC 2018
CMRC 2018是哈工大訊飛聯合實驗室發布的中文機器閱讀理解數據。根據給定問題,系統需要從篇章中抽取出片段作為答案,形式與SQuAD相同。
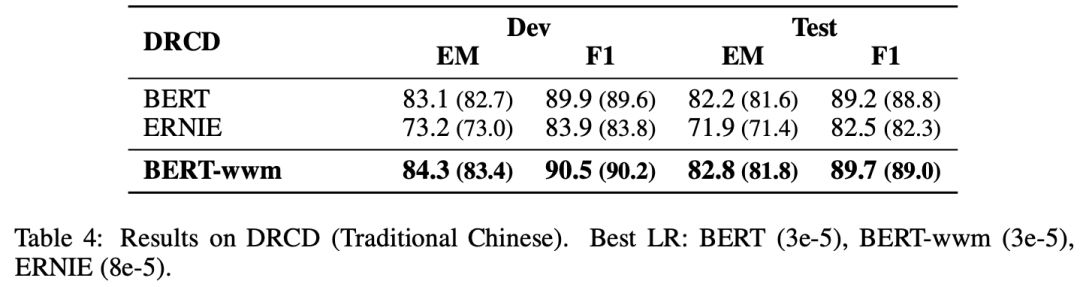
▌中文繁體閱讀理解:DRCD
DRCD數據集由中國***臺達研究院發布,其形式與SQuAD相同,是基于繁體中文的抽取式閱讀理解數據集。
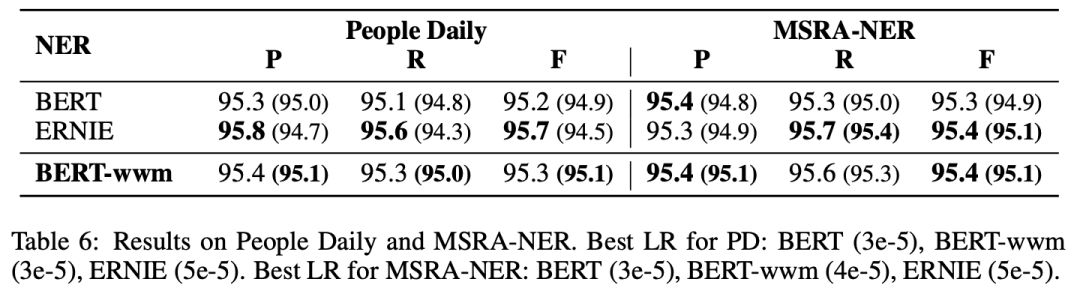
▌中文命名實體識別:人民日報,MSRA-NER
中文命名實體識別(NER)任務中,我們采用了經典的人民日報數據以及微軟亞洲研究院發布的NER數據。
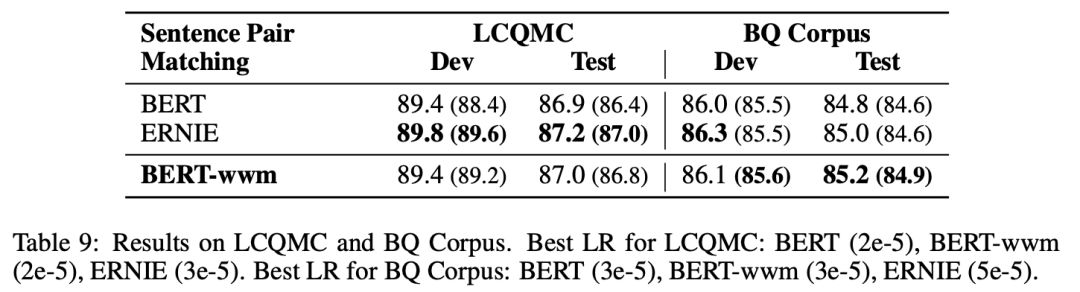
▌句對分類:LCQMC,BQ Corpus
LCQMC以及BQ Corpus是由哈爾濱工業大學(深圳)發布的句對分類數據集。
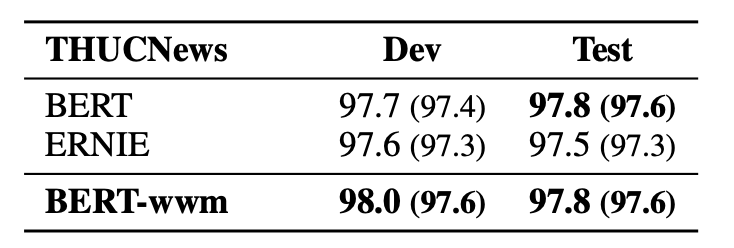
▌篇章級文本分類:THUCNews
由清華大學自然語言處理實驗室發布的新聞數據集,需要將新聞分成10個類別中的一個。
使用建議
基于以上實驗結果,我們給出以下使用建議(部分),完整內容請查看我們的技術報告。
初始學習率是非常重要的一個參數(不論是BERT還是其他模型),需要根據目標任務進行調整。
ERNIE的最佳學習率和BERT/BERT-wwm相差較大,所以使用ERNIE時請務必調整學習率(基于以上實驗結果,ERNIE需要的初始學習率較高)。
由于BERT/BERT-wwm使用了維基百科數據進行訓練,故它們對正式文本建模較好;而ERNIE使用了額外的百度百科、貼吧、知道等網絡數據,它對非正式文本(例如微博等)建模有優勢。
在長文本建模任務上,例如閱讀理解、文檔分類,BERT和BERT-wwm的效果較好。
如果目標任務的數據和預訓練模型的領域相差較大,請在自己的數據集上進一步做預訓練。
如果要處理繁體中文數據,請使用BERT或者BERT-wwm。因為我們發現ERNIE的詞表中幾乎沒有繁體中文。
聲明
雖然我們極力的爭取得到穩定的實驗結果,但實驗中難免存在多種不穩定因素(隨機種子,計算資源,超參),故以上實驗結果僅供學術研究參考。由于ERNIE的原始發布平臺是PaddlePaddle(https://github.com/PaddlePaddle/LARK/tree/develop/ERNIE),我們無法保證在本報告中的效果能反映其真實性能(雖然我們在若干數據集中復現了效果)。同時,上述使用建議僅供參考,不能作為任何結論性依據。
該項目不是谷歌官方發布的中文Whole Word Masking預訓練模型。
總結
我們發布了基于全詞覆蓋的中文BERT預訓練模型,并在多個自然語言處理數據集上對比了BERT、ERNIE以及BERT-wwm的效果。實驗結果表明,在大多數情況下,采用了全詞覆蓋的預訓練模型(ERNIE,BERT-wwm)能夠得到更優的效果。由于這些模型在不同任務上的表現不一致,我們也給出了若干使用建議,并且希望能夠進一步促進中文信息處理的研究與發展。
-
數據集
+關注
關注
4文章
1208瀏覽量
24703 -
自然語言處理
+關注
關注
1文章
618瀏覽量
13561
原文標題:刷新中文閱讀理解水平,哈工大訊飛聯合發布基于全詞覆蓋中文BERT預訓練模型
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
小米與聚飛光電成立聯合實驗室
科大訊飛發布訊飛星火4.0 Turbo大模型及星火多語言大模型
華工科技聯合哈工大實現國內首臺激光智能除草機器人落地
榮耀與智譜攜手共建AI大模型聯合實驗室
MediaTek與小米集團聯合實驗室正式揭幕
中山聯合光電:精密光學實驗室簽約落地長春理工大學中山研究院

【大語言模型:原理與工程實踐】大語言模型的預訓練
西井科技和香港理工大學簽署合作協議,將共建聯合創新實驗室

AI+教育 深圳市中小學聯合實驗室正式啟用







 工商網監
工商網監
評論