 電子發燒友App
電子發燒友App


1.研究背景
隨著配電網信息化建設的推進,配電網在日常運行中產生了大量的配用電數據,但一直以來這些數據并未得到充分的挖掘和有效的利用。如今電改政策試點、售電側放開對電力客戶服務提出了更高的要求,電力行業市場化進程的深入也對電力負荷預測提出了更高的要求。目前,國內外專家和學者已經在大數據負荷預測領域展開了研究工作,也取得了一些成果。
江蘇居住區配電一體化系統的全面建成、用電信息采集系統(下稱“用采系統”)的全面覆蓋,積累了自2009年以來全省47萬配變、26萬專變、3700萬用戶的負荷和電量數據,營銷系統保存著自2009年以來全省26萬大用戶的業擴報裝、增容、減容數據,江蘇省電力公司氣象信息系統積累了自2006年以來全省13地市71個氣象站的10min/點溫度、濕度、雨量、風速等氣象數據,上述數據總量已累計達到180TB,且仍然在以每日30GB的速度快速增長。如何充分利用這些數據資源,挖掘負荷、電量、業擴、氣象、經濟等因素的關系,建立更加精準的負荷和電量影響模型,提高短期負荷預測的精確度,是本文的重點研究內容。
本文分析了大數據負荷預測方法的優勢,介紹了配用電大數據的清洗方法,構建了多維負荷和電量模型,實現了基于配用電大數據的短期負荷預測方法,并且結合實際計算結果,驗證了方法的準確性。
2.大數據負荷預測方法的優勢
傳統負荷預測方法大致可以分為統計算法和智能算法,統計算法包括時間序列模型、決策樹、回歸算法、隨機森林等,智能算法包括人工神經網絡、支持向量機、貝葉斯理論等基本算法及其改進算法,但上述方法由于建模時選取的樣本較小,歷史數據的選取直接影響負荷預測的效果。大數據負荷預測方法存在以下3點優勢:
(1)考慮的影響因素更全。影響負荷走勢的因素眾多,主要包括兩大類型:用戶用電行為中體現的隨機性,以及外部氣象因素和節假日的影響。
(2)數據的時間跨度更長。大數據負荷預測方法選取了時間跨度更長的歷史數據,用于發現負荷數據隨月、季、年周期發生的變化規律。
(3)數據的空間粒度更細。大數據負荷預測方法所采用的負荷數據粒度可以細化到地區、行業、變壓器、線路、臺區、用戶等各個級別。
3.數據源建設
江蘇電力大數據平臺以營配集成、用電信息采集、省地縣一體化電量系統為基礎,結合外部氣象和經濟數據,建成了江蘇配用電大數據中心,為江蘇配用電大數據分析工作提供了豐富的數據資源。
3.1配用電大數據的來源與分類
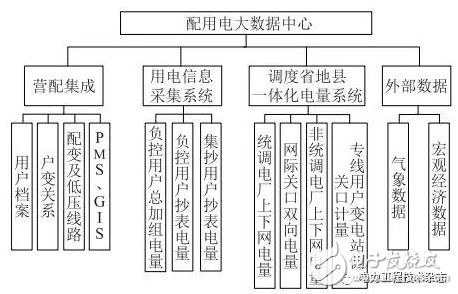
配用電大數據中心的數據體系架構如圖1所示。數據主要來源于營配集成、用電信息采集系統、調度省地縣一體化電量系統,以及外部的氣象數據和宏觀經濟數據。
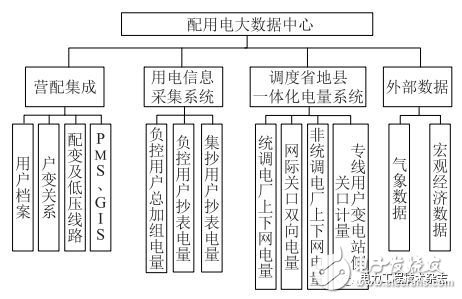
圖1 配用電大數據中心的數據體系架構
3.2配用電大數據的預處理
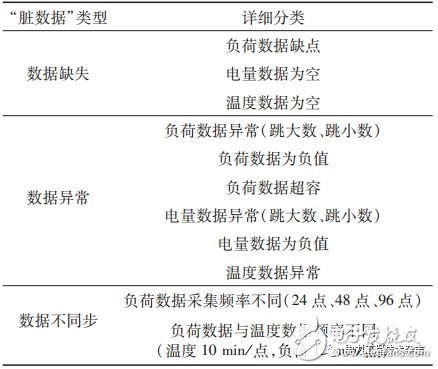
從大數據平臺目前集成的所有數據類型來看,“臟數據”主要有3種大類型,11個小類,如表1所示。
表1 “臟數據”類型
3.2.1數據缺失/異常的清洗方法
數據缺失/異常的清洗主要采用了替代法和插值法。
(1)插值法。負荷數據缺點(異常)較少時,可以基于當日負荷曲線,采用插值法(如拉格朗日插值、三次樣條插值等)實現負荷曲線的補全。
(2)替代法。負荷數據缺點(異常)較多,無法采用插值法時,可以用相似日(工作日選取上一周工作日,周末選取上一周周末)同一時段負荷數據替代;電量數據缺點(異常)較多時,可以用相似日(工作日選取上一月工作日,周末選取上一月周末)的電量數據替代。
3.2.2數據不同步的清洗方法
數據不同步的情況下,通常采用平均值法、強制同步法進行數據清洗。
(1)平均值法。由于極少部分終端采集頻率為48點/日,因此需要將48點負荷數據擴展為96點負荷數據,可以采用平均值法進行數據擴展。
(2)強制同步法。溫度數據為10min/點,而負荷數據15min/點,強制將00:10的溫度數據與00:15的負荷數據匹配,00:30的溫度數據與00:30的負荷數據匹配,00:40的溫度數據與00:45的負荷數據集匹配,以此類推。
4.多維用電影響因素模型的構建
4.1模型構建的總體思路
由于經濟數據發布頻率太低,而且經濟環境在一段時間內相對于氣象因素而言比較穩定,因此本文只考慮氣象因素和節假日建立用電影響因素模型。用電影響因素模型的總體構建思路如圖2所示。
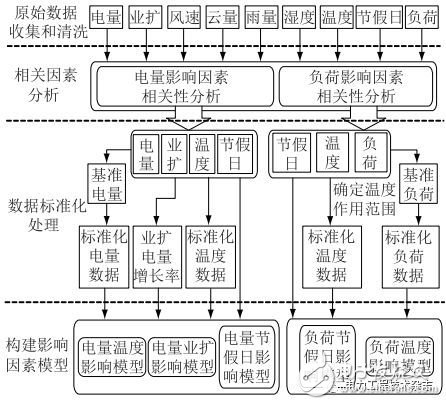
圖2 用電影響因素模型構建思路
模型構建思路主要包括以下4個步驟:
(1)原始數據收集和清洗;
(2)相關因素分析;
(3)數據標準化處理;
(4)用電影響模型構建。
4.2相關因素分析
用電量受氣象因素、節假日、經濟形勢等眾多因素的影響,由于經濟數據發布頻率太低,而且經濟環境在一段時間內相對于氣象因素而言比較穩定,因此這里只考慮氣象因素和節假日與用電量的相關性。
目前氣象信息考慮溫度、濕度、雨量、云量、氣壓、風速六項指標,采用式(1)的相關性計算方法分別對各影響因素進行分析:
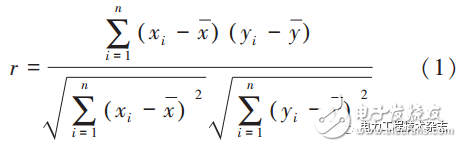
式中:xi為用戶第i天的日用電量數據;x為用戶n天的日用電量平均值;yi為第i天的影響因素數據(例如溫度、濕度等);y為n天的影響因素數據平均值。
4.3數據標準化處理
在構建用電影響因素模型之前,需要通過計算選取合適的基準電量(負荷),實現電量(負荷)數據的標幺化,便于后期直觀地分析各影響因素對電量(負荷)的影響率。數據標準化處理主要包括以下幾個步驟:
(1)按度劃分溫度區間,將各溫度區間對應的電量(負荷)數據歸并,得到各溫度區間內的平均電量(負荷)。
(2)繪制電量(負荷)-溫度曲線,并采用七點平滑算法平滑曲線。
(3)按點計算(2)中曲線斜率,選擇曲線中較為平緩的溫度區間,計算該溫度區間內的平均電量(負荷),作為基準電量(負荷)。
(4)采用(3)中的基準電量(負荷),標準化所有電量(負荷)數據。
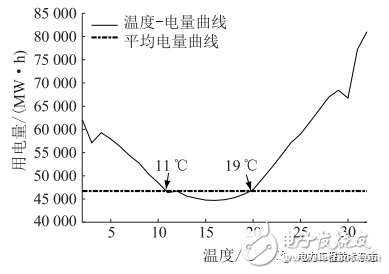
圖3 南京商業電量-溫度曲線
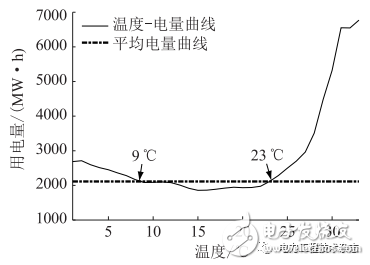
圖4 蘇州居民電量-溫度曲線
4.4行業用電影響模型
由3.1可知,用電影響模型包括電量溫度影響模型、電量業擴影響模型、電量節假日影響模型、負荷溫度影響模型和負荷節假日影響模型,限于篇幅,這里主要介紹行業負荷溫度影響模型和行業電量節假日影響模型的構建方法。
4.4.1行業負荷溫度影響模型
(1)首先根據3.3的計算方法得到待計算行業的基準負荷(基準負荷為全年工作日96點負荷平均值Pi,其中i取值為1~96。
(2)逐日逐點計算負荷影響率:
式中:d表示工作日編號,R(d,i)為第d個工作日第i個點的負荷影響率。
(3)將溫度劃分為>40、<-4、-4~40這45個檔位,將所有工作日的96點負荷影響率歸類到對應的溫度檔位,形成45×96的溫度—負荷影響率序列S(d,i,t),其中下標t為溫度標簽。
(4)逐一對S(d,i,t)中的數據集合求平均值,得到溫度綜合影響率C(i,t),若S(d,i,t)中某一格數據樣本太少,則溫度范圍上下擴展1 ℃ ,重新計算溫度綜合影響率,若果數據樣本依然過少,則將該點的溫度綜合影響率交給后續的模型擬合算法完成。
(5)形成負荷-溫度綜合影響率矩陣C(i,t)后,通過插值法修補殘缺數據點,通過平滑算法平抑模型中的異常數據點,最終得到負荷溫度影響模型。
(6)由于負荷數據更新較快,且過于久遠的歷史數據不具備參考價值,因此負荷溫度影響模型每月根據新增數據更新。
4.4.2行業電量節假日影響模型
以年為計算周期,計算每年所有節假日期間,行業日電量相對于節假日前正常電量的影響率,其計算流程如下:
(1)根據實時節假日放假時間及調休安排,配置節假日信息表,為了顯示節假對電量的連續影響趨勢,應在實際節假日的基礎上前后多配置1d,對于春節這個特殊節假日,前后多配置一周。
(2)找節假日前最近5個工作日,計算這5個工作日的平均用電量,將該電量作為基準電量。
(3)根據下式計算節假日期間每天的電量影響率:
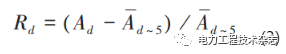
其中:Rd為節假日第d天的行業電量影響率;Ad為節假日第d天的行業用電量;Ad~5為節假日前的5個工作日的行業平均用電量。
5.短期負荷預測的實現與應用
由于江蘇全省用戶數量高達4000萬,若全省網供負荷預測分解過細(到用戶)工作量太大,且用戶負荷隨機性較強,預測精確度反而較低。實踐表明,將全省網供負荷分解到行業級即可得到令人滿意的精確度,且計算量也在合理的范圍內。圖5為基于配用電大數據的短期網供負荷預測方法。
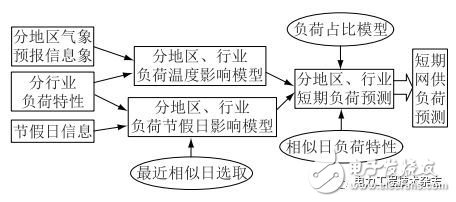
圖5 基于配用電大數據的短期網供負荷預測方法示意圖
在傳統方法中,誤差逆向傳播神經網絡(back propagation,BP)算法應用廣泛、適應性強,以BP算法為傳統方法的代表,與本文提出的大數據方法進行比較。圖6為BP算法和大數據方法的全省網供負荷預測誤差率。
(1)最近相似日選取;
(2)相似日氣象因素剔除;
(3)預測日氣象因素加成;
(4)節假日因素考慮;
(5)構建負荷占比模型;
(6)實現網供負荷預測。
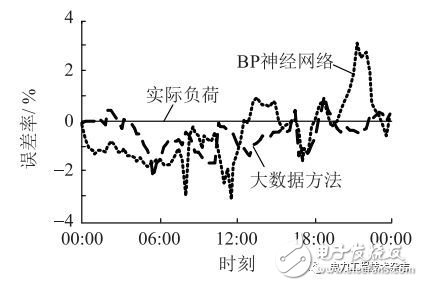
圖6 短期網供負荷預測結果
6.結語
本文基于配用電大數據開展了大量的研究工作,主要進行了:
(1)配用電大數據的清洗。基于配用電大數據的特點以及實際業務的需要,分析了配用電大數據中“臟數據”的來源和類型,針對性地提出了數據清洗方法。
(2)基于配用電大數據,構建了行業負荷溫度影響模型和行業電量節假日影響模型,為后期開展短期負荷預測打下基礎。
(3)提出了基于大數據的短期負荷預測方法。基于多維用電影響因素模型,開展了分地區、行業的短期網供負荷預測,計算結果表明基于配用電大數據的網供負荷預測有著較高的準確性,可以為電網運行和規劃提供數據支撐。












 工商網監
工商網監
評論