 電子發燒友App
電子發燒友App


什么是OCR
OCR的英文全稱:
OCR是英文Optical Character Recognition的縮寫,意思是光學字符識別,也可簡單地稱為文字識別,是文字自動輸入的一種方法。它通過掃描和攝像等光學輸入方式獲取紙張上的文字圖像信息,利用各種模式識別算法分析文字形態特征,判斷出漢字的標準編碼,并按通用格式存儲在文本文件中,所以,OCR是一種非常快捷、省力的文字輸入方式,也是在文字量比較大的今天,很受人們歡迎的一種輸入方式。
OCR的發展簡況
OCR的概念是在1929年由德國科學家Tausheck最先提出來的,后來美國科學家Handel也提出了利用技術對文字進行識別的想法。而最早對印刷體漢字識別進行研究的是IBM公司的Casey和Nagy,1966年他們發表了第一篇關于漢字識別的文章,采用了模板匹配法識別了1000個印刷體漢字。
20世紀70年代初,日本的學者開始研究漢字識別,并做了大量的工作。我國研究漢字識別的起步比較晚,20世紀70年代末才開始進行OCR的研究工作。早期的OCR軟件,由于識別率及產品化等多方面的因素,未能達到實際要求。同時,由于硬件設備成本高,運行速度慢,也沒有達到實用的程度。只有個別部門,如信息部門、新聞出版單位等使用OCR軟件。1986年以后我國的OCR研究有了很大進展,在漢字建模和識別方法上都有所創新,在系統研制和開發應用中都取得了豐碩的成果,不少單位相繼推出了中文OCR產品。進入20世紀90年代以后,隨著平臺式掃描儀的廣泛應用,以及我國信息自動化和辦公自動化的普及,大大推動了OCR技術的進一步發展,使OCR的識別正確率、識別速度滿足了廣大用戶的要求。
目前,比較流行的OCR軟件很多,英文OCR主要有OmniPage,中文OCR主要有清華紫光OCR、清華文通OCR、漢王OCR、中晶尚書OCR、丹青OCR、蒙恬OCR等。盡管漢字字量大、字形復雜,但OCR技術已經走向成熟。許多OCR軟件不僅能識別黑白印刷體漢字,還能識別灰度和彩色印刷體漢字,識別速度很快,識別正確率達到了99%以上;可識別宋體、黑體、楷體等多種字體的簡、繁體;可對多種字體、不同字號的混排進行識別;有些OCR軟件還能識別圖像、表格。與此同時,對于手寫體漢字識別的研究也取得了很大進展,正確識別率已達到了70%以上。
OCR軟件的應用
在掃描儀市場上,許多類型的辦公和家用掃描儀均配有OCR軟件,如紫光的掃描儀配備了紫光O
CR,中晶的掃描儀配備了尚書OCR,Mustek的掃描儀配備了丹青OCR等。掃描儀與OCR軟件共同承擔著從文稿的輸入到文字識別的全過程。
文稿掃描在辦公領域中經常用到,即將報紙、雜志等媒體上刊載的有關文稿通過掃描儀進行掃描,隨后進行OCR識別,或存儲成圖像文件,留待以后進行OCR識別,將圖像文件轉換成文本文件或Word文件進行存儲。
此外,數字化信息的存儲、傳輸、不僅成本低、效率高,而且能夠適應排版,網絡傳輸等不斷發展的需要。目前我國有很多歷史遺留下來的大量圖書、報刊、雜志等紙質珍品,急需將其轉換成電子信息。如電子圖書館的建立,就需要將圖書逐頁掃描,加上OCR軟件的識別,更替代了人工鍵入文字的工作,大大縮短了錄入時間,減輕了勞動強度,節省了人力且降低了費用,提高了錄入正確率、工作效率和現代辦公自動化程度。
目前OCR軟件與掃描儀的搭配已應用到信息化時代的多個領域,如數字化圖書館,各種報表的識別,以及銀行、稅務系統票據的識別等。隨著網絡化、信息化的發展與普及,其應用范圍將越來越廣泛。
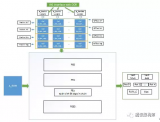
OCR系統的組成
漢字識別軟件OCR的功能是將各種錄入漢字、印刷體或手寫體中每個漢字的圖形或圖像通過計算機辨認出來,并標出漢字類別代碼。因此,漢字識別歸根結底是一個圖像識別問題。由于漢字信息量很大,具有不同的字形、字體,而且結構復雜,因此漢字識別的過程極其復雜。
由于掃描儀的普及與廣泛應用,OCR軟件只需提供與掃描儀的接口,利用掃描儀驅動軟件即可。因此,OCR軟件主要是由圖像處理模塊、版面劃分模塊、文字識別模塊和文字編輯模塊等4部分組成。
1、圖像處理模塊
圖像處理模塊主要具有文稿掃描、圖像縮放、圖像旋轉等功能。通過掃描儀輸入后,文稿形成圖像文件,圖像處理模塊可對圖像進行放大,去除污點和劃痕,如果圖像放置不正,可以手工或自動旋轉圖像,目的是為文字識別創造更好的條件,使識別率更高。
2、版面劃分模塊
版面劃分模塊主要包括版面劃分、更改劃分,即對版面的理解、字切分、歸一化等,可選擇自動或手動兩種版面劃分方式。目的是告訴OCR軟件將同一版面的文章、表格等分開,以便于分別處理,并按照怎樣的順序進行識別。
3、文字識別模塊
文字識別模塊是OCR軟件的核心部分,文字識別模塊主要對輸入的漢字進行"閱讀",但不能一目多行,必須逐行切割,對于漢字通常也是一個字一個字地辨認,即單字識別,再進行歸一化。文字識別模塊通過對不同樣本漢字的特征進行提取,完成識別,自動查找可疑字,具有前后聯想等功能。
4、文字編輯模塊
文字編輯模塊主要對OCR識別后的文字進行修改、編輯,如系統識別認為有誤,則文字會以醒目的紅色或藍色顯示,并提供相似的文字供選擇,選擇編輯器供輸出等。
OCR軟件的使用方法
OCR軟件的種類雖然很多,但其使用方法大同小異。首先要對文稿進行掃描,然后進行OCR識別。OCR軟件的使用方法如下:
1、文稿掃描
為了利用OCR軟件進行文字識別,可直接在OCR軟件中掃描文稿。運行OCR軟件后,會出現OCR軟件界面。
將要掃描的文稿放在掃描儀的玻璃面上,使要掃描的一面朝向掃描儀的玻璃面并讓文稿的上端朝下,與標尺邊緣對齊,再將掃描儀蓋上,即可準備掃描。點擊視窗中的"掃描"鍵,即可進入掃描驅動軟件進行掃描,有關掃描方法這里不再贅述。但應注意的是:分辨力可設置在200~400dpi,對于文本文檔,調整亮度適中很關鍵。掃描后的文檔圖像出現在OCR軟件視窗中。
2、OCR識別
為了便于操作,可從菜單中選擇選項,各種圖標出現在視窗的左邊。
為了更好使用,首先從上到下介紹畫面左邊的圖標:
"放大"工具:用于放大圖像;"縮小"工具:用于縮小圖像;"設定識別區域"工具:用于設定識別區域;"設定識別順序"工具:用于設定識別順序;"刪除識別區域"工具:用于刪除識別區域;"擦除圖像雜點"工具:用于擦除圖像中的雜點;"擦拭圖像塊"工具:用于擦除圖像中的某一區域;"旋轉圖像"工具:用于將圖像旋轉90°、180°或270°;"傾斜校正"工具:用于手動圖像傾斜校正。
OCR識別的一般步驟:
(1)文稿掃描后,剛開始出現在視窗中的要識別的文字畫面很小,首先選擇"放大"工具,對畫面進行適當放大,以使畫面看得更清楚。必要時還可以選擇"縮小"工具,將畫面適當縮小。
(2)如果畫面需要旋轉90°,180°或270°,可使用"旋轉圖像"工具旋轉圖像。如果文字畫面傾斜,可選擇"傾斜校正"工具,將畫面調正。
(3)識別時選擇"設定識別區域"工具,在文字畫面上框出要識別的區域,這時也可根據畫面情況框出多個區域。如果所框區域有誤,則可使用"刪除識別區域"工具,刪除所選識別區域。
(4)為了提高識別率,如果所選識別區有雜點或有不能識別的圖像,則可選擇"擦除圖像雜點"工具,將雜點一點一點地擦除。如果需要成片地擦除,則可選擇"擦拭圖像塊"工具。
(5)點擊"識別"圖標,則OCR顯示正在進行文字切分,然后轉入"正在識別"畫面,將識別的文字逐步顯示出來,"文稿校對"窗口。
許多OCR軟件都具有文字修改功能,被識別出可能有錯誤的文字,用比較鮮明的顏色顯示出來,并且可以進行修改。
(6)將識別后的文件存儲成文本(TXT)文件或Word的RTF文件。















 工商網監
工商網監
評論