 電子發(fā)燒友App
電子發(fā)燒友App


微處理器工作原理
1. 引言 2. 微處理器的結(jié)構(gòu) 3. 微處理器指令 4. 微處理器的性能和發(fā)展趨勢您在瀏覽本頁面時使用的計算機便通過微處理器來完成其工作。微處理器是所有標(biāo)準(zhǔn)計算機的心臟,無論該計算機是桌面計算機、服務(wù)器還是筆記本電腦。您正在使用的微處理器可能是奔騰、K6、PowerPC、Sparc或者其他任何品牌和類型的微處理器,但是它們的作用大體相同,工作方式也基本類似。
如果您曾經(jīng)疑惑計算機中的微處理器是干什么用的,或者對各種類型的微處理器之間的差異感到迷惑,請繼續(xù)閱讀下面的內(nèi)容。在本文中,您將了解到簡簡單單的數(shù)字邏輯電路技術(shù)如何讓計算機完成諸如玩游戲或是對文檔進(jìn)行拼寫檢查的工作。
|
Intel4004芯片 |
|
Intel8080 |
微處理器的發(fā)展過程:Intel
下表可幫助您了解 Intel 在不同時間推出的不同處理器之間的差異。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
8 位總線 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
64位總線 |
|
|
|
|
|
|
|
64位總線 |
|
|
|
|
|
|
|
64位總線 |
|
|
|
|
|
|
|
64位總線 |
|
|
|
|
|
|
|
64 位總線 |
|
與此表有關(guān)的信息:
- 日期是該款處理器首次推出的年份。許多處理器會在首次發(fā)布之后在多年中不斷推出具有更高時鐘頻率的型號。
- 晶體管數(shù)量是指芯片上晶體管的數(shù)量。可以看到,芯片上包含的晶體管數(shù)量在逐年穩(wěn)步上升。
- 微米是指芯片上最細(xì)的電路的寬度(單位為微米)。可以用人的頭發(fā)做個比較,頭發(fā)的寬度為100微米。隨著芯片外形尺寸不斷縮小,晶體管數(shù)量卻在不斷增加。
- 時鐘頻率是指芯片的最大時鐘速度。我們將在下一節(jié)中詳細(xì)介紹時鐘頻率。
- 數(shù)據(jù)寬度是指 ALU的寬度。8位的ALU可以對兩個8位(8比特)數(shù)字進(jìn)行加減乘除運算,而32位的ALU可以計算32位的數(shù)字。8位ALU如果要對兩個 32位數(shù)字進(jìn)行加法操作,必須執(zhí)行四條相加指令,而32位ALU則只需要執(zhí)行一條指令。很多情況下,外部數(shù)據(jù)總線的寬度與ALU相同,但也有不同的情況。8088的ALU為16位,而總線為8位,而現(xiàn)代的奔騰處理器的數(shù)據(jù)總線寬度為64位,ALU為32位。
- MIPS代表“每秒百萬條指令”,是衡量CPU性能的粗略標(biāo)準(zhǔn)。對于現(xiàn)代 CPU的許多工作,MIPS指標(biāo)在很大程度上已經(jīng)失去了意義,但是您可以將它作為一個大致的量度,根據(jù)本欄中的數(shù)據(jù)來了解CPU的性能強弱。
|
|
從本表中可以看到,總體來說,時鐘頻率和MIPS之間存在一定關(guān)系。最大時鐘頻率與制造工藝和芯片內(nèi)的延遲密切相關(guān)。此外,在晶體管數(shù)量和MIPS之間也存在一定聯(lián)系。例如,8088的時鐘頻率為5MHz,但是只能以0.33MIPS的速度執(zhí)行指令(大約每15個周期執(zhí)行1條指令)。現(xiàn)代的處理器經(jīng)常可以在每個時鐘周期內(nèi)執(zhí)行兩條指令。這種能力改進(jìn)與晶體管的數(shù)量有直接關(guān)系,我們將在下一節(jié)中對此加以討論。
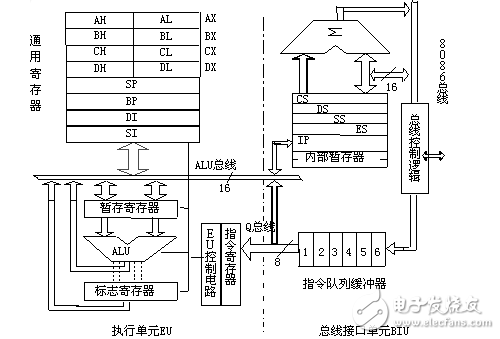
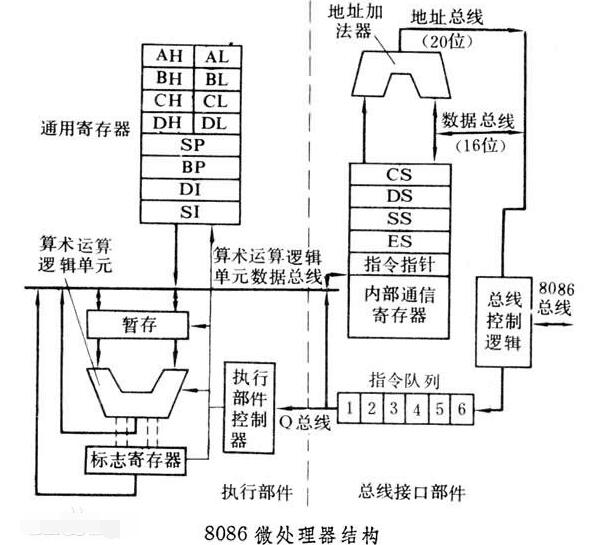
微處理器的結(jié)構(gòu)
為了理解微處理器的工作原理,首先看看它的內(nèi)部結(jié)構(gòu)和了解其工作邏輯會很有幫助。在這個過程中,您還可以了解到匯編語言——微處理器的固有語言——以及工程師們?yōu)榱颂岣咛幚砥魉俣人龅拇罅抗ぷ鳌?
微處理器執(zhí)行一組機器指令,這組指令可向處理器告知應(yīng)執(zhí)行哪些操作。微處理器就會根據(jù)指令執(zhí)行三種基本工作:
- 通過使用ALU(算術(shù)/邏輯單元),微處理器可以執(zhí)行數(shù)學(xué)計算。例如:加法、減法、乘法和除法。現(xiàn)代的微處理器包含完整的浮點處理器,它可以對很大的浮點數(shù)執(zhí)行非常復(fù)雜的浮點運算。
- 微處理器可以將數(shù)據(jù)從一個內(nèi)存位置移動到另一個位置。
- 微處理器可以做出決定,并根據(jù)這些決定跳轉(zhuǎn)到一組新指令。
微處理器能夠執(zhí)行許多非常復(fù)雜的工作,但是所有工作都屬于這三種基本操作的范疇。下圖顯示了一個能夠執(zhí)行上述三種操作的非常簡單的微處理器:
|
|
這是一個進(jìn)行了最大程度簡化的微處理器。此微處理器具有:
- 一條地址總線(總線寬度可以8位、16位或32位),用于向內(nèi)存發(fā)送一個地址
- 一條數(shù)據(jù)總線(總線寬度可以是8位、16位或32位),能夠?qū)?shù)據(jù)發(fā)送到內(nèi)存或從內(nèi)存取得數(shù)據(jù)
- 一條RD(讀)和WR(寫)線路,告訴內(nèi)存它是希望寫入某個地址位置還是獲得某個地址位置的內(nèi)容
- 一條時鐘線路,將時鐘脈沖序列發(fā)送到處理器
- 復(fù)位線路,用于將程序計數(shù)器重置為零(或者其他內(nèi)容)并重新開始執(zhí)行
在本例中,我們假定地址和數(shù)據(jù)總線的寬度都是8位的。
以下是這個簡單的微處理器的各個組成部分:
- 寄存器A、B和C就是一些用觸發(fā)器制造的鎖存器。(有關(guān)詳細(xì)信息,請參見布爾邏輯的應(yīng)用一文的“邊緣觸發(fā)鎖存器”部分。)
- 地址鎖存器與寄存器A、B和C極其類似。
- 程序計數(shù)器也是一個鎖存器,但是它有一種額外的能力,也就是能夠在執(zhí)行每條語句后將計數(shù)器加一,并在被告知應(yīng)進(jìn)行重置時將計數(shù)器重置為零。
- ALU可以像一個8位加法器一樣簡單(有關(guān)詳細(xì)信息,請參見布爾邏輯的應(yīng)用一文中有關(guān)加法器的部分),也可以較為復(fù)雜,能夠?qū)?位的值進(jìn)行加法、減法、乘法和除法運算。我們假定是后面一種加法器。
- 測試寄存器是一種特殊的鎖存器,可以存放在ALU中執(zhí)行的比較運算的結(jié)果。ALU通常可以比較兩個數(shù)字,并確定它們是否相等以及其中一個數(shù)字是否大于另一個數(shù)字等。測試寄存器通常還可以保存加法器上一次計算產(chǎn)生的進(jìn)位。它將這些值存放在觸發(fā)器中,隨后指令解碼器可以使用這些值做出決定。
- 圖中有六個標(biāo)記有“3-State”(三態(tài))的方框。它們是三態(tài)緩沖區(qū)。三態(tài)緩沖區(qū)可以輸出1、0或者徹底斷開其輸出(可以將其想像為一個將輸出線從電路中徹底斷開的開關(guān))。三態(tài)緩沖區(qū)能夠?qū)⒍喾N輸出連接到電路中,但是線路上的某一個輸出實際上代表的是1或0。
- 指令寄存器和指令解碼器負(fù)責(zé)控制所有其他組件。
|
|
- 通知A寄存器鎖存當(dāng)前在數(shù)據(jù)總線上傳遞的值
- 通知B寄存器鎖存當(dāng)前在數(shù)據(jù)總線上傳遞的值
- 通知C寄存器鎖存當(dāng)前由ALU輸出的值
- 通知程序計數(shù)器寄存器鎖存當(dāng)前在數(shù)據(jù)總線上傳遞的值
- 通知地址寄存器鎖存當(dāng)前在數(shù)據(jù)總線上傳遞的值
- 通知指令寄存器鎖存當(dāng)前在數(shù)據(jù)總線上傳遞的值
- 通知程序計數(shù)器進(jìn)行遞增
- 通知程序計數(shù)器重置為零
- 激活所有六個三態(tài)緩沖區(qū)(六條單獨的線路)
- 通知ALU要執(zhí)行的操作
- 通知測試寄存器鎖存ALU的測試位
- 激活RD線路
- 激活WR線路
來自測試寄存器和時鐘線路(以及指令寄存器)的數(shù)據(jù)位會進(jìn)入到指令解碼器中。
上一節(jié)中我們討論了地址和數(shù)據(jù)總線,以及RD和WR線路。這些總線和線路連接到RAM或ROM——通常是同時連接到二者。在我們作為例子的微處理器中,有一個寬度為8位的地址總線和一個寬度為8位的數(shù)據(jù)總線。也就是說,該微處理器可以尋址(28) 256個字節(jié)的內(nèi)存空間,并且可以向內(nèi)存讀取或?qū)懭?位的數(shù)據(jù)。我們假定這個簡單的微處理器有128字節(jié)的ROM,其地址從0開始,此外還有128字節(jié)的RAM,其地址從128開始。
|
ROM芯片 |
ROM代表只讀內(nèi)存。ROM芯片使用永久性的預(yù)設(shè)字節(jié)進(jìn)行了編程。地址總線通知ROM芯片應(yīng)取出哪些字節(jié)并將它們放在數(shù)據(jù)總線上。當(dāng)RD線的狀態(tài)更改后,ROM芯片會將選擇的字節(jié)放在數(shù)據(jù)總線上。
|
RAM芯片 |
順便說一下,幾乎所有計算機都包含一定數(shù)量的 ROM(可以制造出不包括任何RAM的簡單計算機——許多微控制器便做到了這一點,方法是將少量的RAM字節(jié)放在處理器芯片自身中——但是,通常不可能制造出不包含任何ROM的計算機)。在PC中,ROM稱作BIOS(基本輸入輸出系統(tǒng))。在微處理器啟動時,它開始執(zhí)行在BIOS中找到的指令。BIOS指令會執(zhí)行對計算機中的硬件進(jìn)行測試這樣的工作,然后訪問硬盤以讀取啟動扇區(qū)(有關(guān)詳細(xì)信息,請參見硬盤工作原理)。該啟動扇區(qū)是另一個小型程序,在將其從磁盤中讀出后,BIOS將它存儲在RAM中。然后,微處理器開始從 RAM中執(zhí)行啟動扇區(qū)的指令。啟動扇區(qū)程序會通知微處理器將其余指令從硬盤讀入RAM,微處理器隨后又會執(zhí)行這些指令,以此類推。這就是微處理器加載和執(zhí)行整個操作系統(tǒng)的過程。
微處理器指令
雖然前面例子中的微處理器非常簡單,但是它仍然可以執(zhí)行相當(dāng)多的指令。指令集通過位模式的方式實現(xiàn),每一個位模式在加載到指令寄存器中后都有不同的含義。由于人們不能很好記住這些位模式,所以定義了一些簡短的單詞來表示不同的位模式。這些單詞的集合稱作處理器的匯編語言。匯編程序可以將這些單詞輕松翻譯成它們的位模式,然后會將匯編程序的輸出放在內(nèi)存中供處理器執(zhí)行。
以下是設(shè)計人員可以為例子中的微處理器建立的一組匯編語言指令:
- LOADA mem——將某個內(nèi)存地址的數(shù)據(jù)加載到寄存器A中
- LOADB mem——將某個內(nèi)存地址的數(shù)據(jù)加載到寄存器B中
- CONB con——將一個常量值加載到寄存器B中
- SAVEB mem——將寄存器B的內(nèi)容保存到某個內(nèi)存地址
- SAVEC mem——將寄存器C的內(nèi)容保存到某個內(nèi)存地址
- ADD——將A和B相加并將結(jié)果保存在C中
- SUB——將A和B相減并將結(jié)果保存在C中
- MUL——將A和B相乘并將結(jié)果保存在C中
- DIV——將A和B相除并將結(jié)果保存在C中
- COM——將A和B進(jìn)行比較并將結(jié)果保存在測試寄存器中
- JUMP addr——跳轉(zhuǎn)到某個地址
- JEQ addr——如果相等則跳轉(zhuǎn)到某個地址
- JNEQ addr——如果不相等則跳轉(zhuǎn)到某個地址
- JG addr——如果大于則跳轉(zhuǎn)到某個地址
- JGE addr——如果大于或等于則跳轉(zhuǎn)到某個地址
- JL addr——如果小于則跳轉(zhuǎn)到某個地址
- JLE addr——如果小于或等于則跳轉(zhuǎn)到某個地址
- STOP——停止執(zhí)行
如果你讀過C語言入門教程一文,那么會知道下面這段簡單的C代碼可計算5的階乘(5的階乘=5!=5X4X3X2X1=120):
a=1;
f=1;
while (a<=5)
{
f=f*a;
a=a+1;
}
在程序執(zhí)行末尾,變量f中包含了5的階乘。
匯編語言
C編譯器可將這段C代碼編譯為匯編語言。假定此處理器中RAM的地址從128開始,而ROM(包含匯編語言程序)的地址從0開始,那么對于我們這個簡單的微處理器來說,該匯編語言看起來如下所示:
// 假定a位于地址128處
// 假定F位于地址129處
0 CONB 1 // a=1;
1 SAVEB 128
2 CONB 1 // f=1;
3 SAVEB 129
4 LOADA 128 // 如果a>5,則跳轉(zhuǎn)到17
5 CONB 5
6 COM
7 JG 17
8 LOADA 129 // f=f*a;
9 LOADB 128
10 MUL
11 SAVEC 129
12 LOADA 128 // a=a+1;
13 CONB 1
14 ADD
15 SAVEC 128
16 JUMP 4 // 進(jìn)行循環(huán),返回到比較部分
17 STOP
ROM
那么,現(xiàn)在的問題是:所有這些指令在ROM中是什么樣的?所有這些匯編語言指令必須以二進(jìn)制數(shù)字的形式表示。為了簡單起見,我們假定每條匯編語言指令具有一個唯一的編號,如下所示:
- LOADA-1
- LOADB-2
- CONB-3
- SAVEB-4
- SAVEC mem-5
- ADD -6
- SUB -7
- MUL -8
- DIV -9
- COM -10
- JUMP addr -11
- JEQ addr -12
- JNEQ addr -13
- JG addr -14
- JGE addr -15
- JL addr -16
- JLE addr -17
- STOP -18
這些數(shù)字稱作opcode(優(yōu)化代碼)。在ROM中,我們的小程序看起來如下所示:
// 假定a位于地址128處
// 假定F位于地址129處
地址 opcode/值
0 3 // CONB 1
1 1
2 4 // SAVEB 128
3 128
4 3 // CONB 1
5 1
6 4 // SAVEB 129
7 129
8 1 // LOADA 128
9 128
10 3 // CONB 5
11 5
12 10 // COM
13 14 // JG 17
14 31
15 1 // LOADA 129
16 129
17 2 // LOADB 128
18 128
19 8 // MUL
20 5 // SAVEC 129
21 129
22 1 // LOADA 128
23 128
24 3 // CONB 1
25 1
26 6 // ADD
27 5 // SAVEC 128
28 128
29 11 // JUMP 4
30 8
31 18 // STOP
您可以看到,七行C代碼變成了18行匯編語言,并且變成了ROM中的32個字節(jié)。
解碼
指令解碼器需要將每個opcode轉(zhuǎn)變?yōu)橐唤M能夠驅(qū)動微處理器內(nèi)部各個部件的信號。讓我們以ADD指令為例,看看解碼器都執(zhí)行了哪些工作:
- 在第一個時鐘周期,我們需要實際載入該指令。因此,指令解碼器需要:
- 激活程序計數(shù)器的三態(tài)緩沖區(qū)
- 激活RD線路
- 激活data-in(讀入數(shù)據(jù))三態(tài)緩沖區(qū)
- 將指令鎖存在指令寄存器中
- 在第二個時鐘周期中,對ADD指令進(jìn)行解碼。需要做的工作很少:
- 將ALU的操作設(shè)置為加法
- 將ALU的輸出鎖存到C寄存器中
- 在第三個時鐘周期中,程序計數(shù)器會進(jìn)行遞增(理論上這個過程與第二個時鐘周期是重疊進(jìn)行的)。
所有指令都會像這樣分解成一組有序操作,按照正確的順序操作微處理器的各個組件。有些指令(例如這條ADD指令)需要2或3個時鐘周期即可完成。而其他指令則可能需要5或6個時鐘周期才能完成。
微處理器的性能和發(fā)展趨勢
可用晶體管的數(shù)量對處理器性能有巨大影響。如上所述,在8088這樣的處理器中,通常要花費15個時鐘周期才能執(zhí)行一條指令。由于乘法器的設(shè)計方式,在 8088上進(jìn)行16位的乘法運算大約需要80個時鐘周期。而晶體管越多,就越有可能在一個周期中執(zhí)行更多的乘法運算。
晶體管數(shù)量的增多還使我們能夠使用一種稱為流水線的技術(shù)。在流水線式的體系結(jié)構(gòu)中,指令的執(zhí)行過程是相互重疊的。所以,雖然需要花費5個時鐘周期來執(zhí)行每條指令,但是可以同時執(zhí)行5條指令的各個階段。這樣,表面看起來在每個時鐘周期內(nèi)即可執(zhí)行完一條指令。
許多現(xiàn)代的處理器具有多個指令解碼器,每一個都有自己的流水線。這樣便存在多個指令流,也就是說每個時鐘周期可以完成多條指令。但是這種技術(shù)實現(xiàn)起來非常復(fù)雜,因此需要使用大量的晶體管。
發(fā)展趨勢
處理器設(shè)計的發(fā)展趨勢主要是:完全32位的ALU(內(nèi)置快速浮點處理器)和多指令流的流水線式執(zhí)行方式。處理器設(shè)計的最新進(jìn)展是64位ALU,預(yù)計在下一個十年中家用PC就會用上這種處理器。此外,還存在為處理器添加可高效執(zhí)行某些操作的特殊指令(例如MMX指令)的趨勢,以及在處理器芯片中增加硬件虛擬內(nèi)存支持和L1緩存的趨勢。所有這些趨勢都進(jìn)一步增加了晶體管的數(shù)量,導(dǎo)致現(xiàn)在的處理器包含數(shù)千萬個晶體管。而這些處理器每秒大約可以執(zhí)行十億條指令!
64位處理器
64位處理器在1992年就已經(jīng)開發(fā)成功,預(yù)計它們在21世紀(jì)將逐步成為主流產(chǎn)品。I英特爾和AMD都開發(fā)出了64位芯片,Mac G5也是一款64位處理器產(chǎn)品。64位處理器具有64位ALU、64位寄存器、64位總線等等。
|
|
人們需要64位處理器的原因之一是它們具有更大的地址空間。32位芯片通常只能訪問最大2GB或4GB的RAM空間。這聽起來似乎是一個很大的空間,是因為當(dāng)前的大多數(shù)家用計算機只配備了256MB到512MB的RAM。但是,對于服務(wù)器和運行大型數(shù)據(jù)庫的計算機來說,4GB的內(nèi)存空間限制是一個嚴(yán)重問題。而且,即使是家用計算機,如果按照當(dāng)前趨勢繼續(xù)發(fā)展,也很快會遇到2GB或4GB限制這個問題。64位芯片則不存在上述限制,因為在可以預(yù)見的未來,64位RAM地址空間都可以說是一個無限大的地址空間——2^64字節(jié)的RAM大概相當(dāng)于十億吉字節(jié)的 RAM。
憑借64位地址總線以及主板上寬闊的高速數(shù)據(jù)總線,64位計算機還可以為硬盤驅(qū)動器和顯卡這樣的設(shè)備提供更快的I/O(輸入/輸出)速度。這些特點可極大地提升系統(tǒng)的性能。
服務(wù)器肯定會受益于64位技術(shù),但是它對于普通用戶有何意義呢?除了解除RAM限制之外,目前我們還不是很清楚64位芯片能夠為普通用戶提供那些切實的好處。但是它們可以更快地處理數(shù)據(jù)(能夠計算很復(fù)雜的實數(shù))。進(jìn)行視頻編輯和處理超大圖像的人會受益于這種強大的計算能力。高端游戲也會從中受益,但是需要對它們進(jìn)行重新編碼以利用64位技術(shù)。而閱讀電子郵件、瀏覽網(wǎng)絡(luò)和編輯Word文檔的人實際則不需要使用這種處理器。

















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論