 電子發(fā)燒友App
電子發(fā)燒友App


機(jī)器學(xué)習(xí)十大算法之一:EM算法。能評(píng)得上十大之一,讓人聽(tīng)起來(lái)覺(jué)得挺NB的。什么是NB啊,我們一般說(shuō)某個(gè)人很NB,是因?yàn)樗芙鉀Q一些別人解決不了的問(wèn)題。神為什么是神,因?yàn)樯衲茏龊芏嗳俗霾涣说氖隆D敲碋M算法能解決什么問(wèn)題呢?或者說(shuō)EM算法是因?yàn)槭裁炊鴣?lái)到這個(gè)世界上,還吸引了那么多世人的目光。
我希望自己能通俗地把它理解或者說(shuō)明白,但是,EM這個(gè)問(wèn)題感覺(jué)真的不太好用通俗的語(yǔ)言去說(shuō)明白,因?yàn)樗芎?jiǎn)單,又很復(fù)雜。簡(jiǎn)單在于它的思想,簡(jiǎn)單在于其僅包含了兩個(gè)步驟就能完成強(qiáng)大的功能,復(fù)雜在于它的數(shù)學(xué)推理涉及到比較繁雜的概率公式等。如果只講簡(jiǎn)單的,就丟失了EM算法的精髓,如果只講數(shù)學(xué)推理,又過(guò)于枯燥和生澀,但另一方面,想把兩者結(jié)合起來(lái)也不是件容易的事。所以,我也沒(méi)法期待我能把它講得怎樣。希望各位不吝指導(dǎo)。
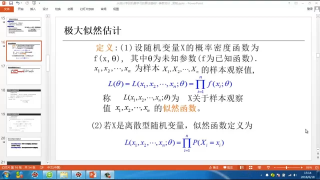
EM算法 :
相信大家對(duì)似然函數(shù)已經(jīng)手到擒來(lái)了。那么我們就來(lái)看看高深的。
一個(gè)概率模型有時(shí)候既含有觀察變量,有含有隱變量。如果只有觀察變量那么我們可以用最大似然法(或者貝葉斯)估計(jì)未知參數(shù),但是如果還含有隱變量就不能如此簡(jiǎn)單解決了。這時(shí)候就需要EM算法。
大家可能對(duì)這種問(wèn)題不是很明白,也不太明白隱變量是什么意思。我舉個(gè)例子(引用統(tǒng)計(jì)學(xué)習(xí)方法的例子):
有3枚硬幣分別記為A,B,C,并且出現(xiàn)正面概率分別為p ,q ,k.規(guī)則如下:先拋硬幣A,如果為正面就選擇B,否則選擇C,然后再將選擇的硬幣(B或者C拋),然后觀測(cè)結(jié)果。正面為1 反面為0.獨(dú)立重復(fù)實(shí)驗(yàn)10次結(jié)果如下:1,1,1,0,0,0,1,1,1,0。我們并不知道拋A硬幣時(shí)為正面還是方面,只知道最后的結(jié)果,問(wèn)如何估計(jì)p,q,k的值?
如果我們知道拋的是哪個(gè)硬幣就可以使用最大似然估計(jì)來(lái)估計(jì)這些參數(shù),但是我們不知道。因?yàn)橛衟的原因,所以無(wú)法估計(jì),這個(gè)p就是隱變量
log(Θ)=Σlogp(x;Θ)=Σlogp(x,p;Θ),Θ就是要求的q,k 待定參數(shù),x為觀測(cè)數(shù)據(jù),因?yàn)檫@個(gè)p導(dǎo)致我們無(wú)法求解MaxΣlogp(x;Θ)。
還比如說(shuō)調(diào)查 男生 女生身高的問(wèn)題。身高肯定是服從高斯分布。以往我們可以通過(guò)對(duì)男生抽樣進(jìn)而求出高斯分布的參數(shù),女生也是,但是如果我們只能知道某個(gè)人的高度,卻不能知道他是男生或者女生(隱含變量),這時(shí)候就無(wú)法使用似然函數(shù)估計(jì)了。這個(gè)時(shí)候就可以使用EM方法。
分為E和M兩步:
E步:
首先通過(guò)隨機(jī)賦值一個(gè)我們要求的參數(shù),然后求出另外一個(gè)隱含參數(shù)的后驗(yàn)概率。這是期望計(jì)算過(guò)程,我們首先通過(guò)隨便賦予模型參數(shù)的初始值p,q,k,求出各個(gè)數(shù)據(jù)到模型的結(jié)果。
M步
用求出來(lái)的隱含參數(shù)的后驗(yàn)概率進(jìn)行對(duì)傳統(tǒng)的似然函數(shù)估計(jì),對(duì)要求參數(shù)進(jìn)行修正。迭代直到前后兩次要求的參數(shù)一樣為止
其實(shí)可以這么簡(jiǎn)單理解:就是在無(wú)監(jiān)督聚類(lèi)的時(shí)候,我們不知道模型的參數(shù)(比如為高斯分布),這時(shí)候我們就隨便賦值給模型的待定參數(shù)(u和ó)。然后我們就可以計(jì)算出各個(gè)數(shù)據(jù)分別屬于那一類(lèi)。然后我們用這些分類(lèi)好的數(shù)據(jù)重新估計(jì)u和ó。
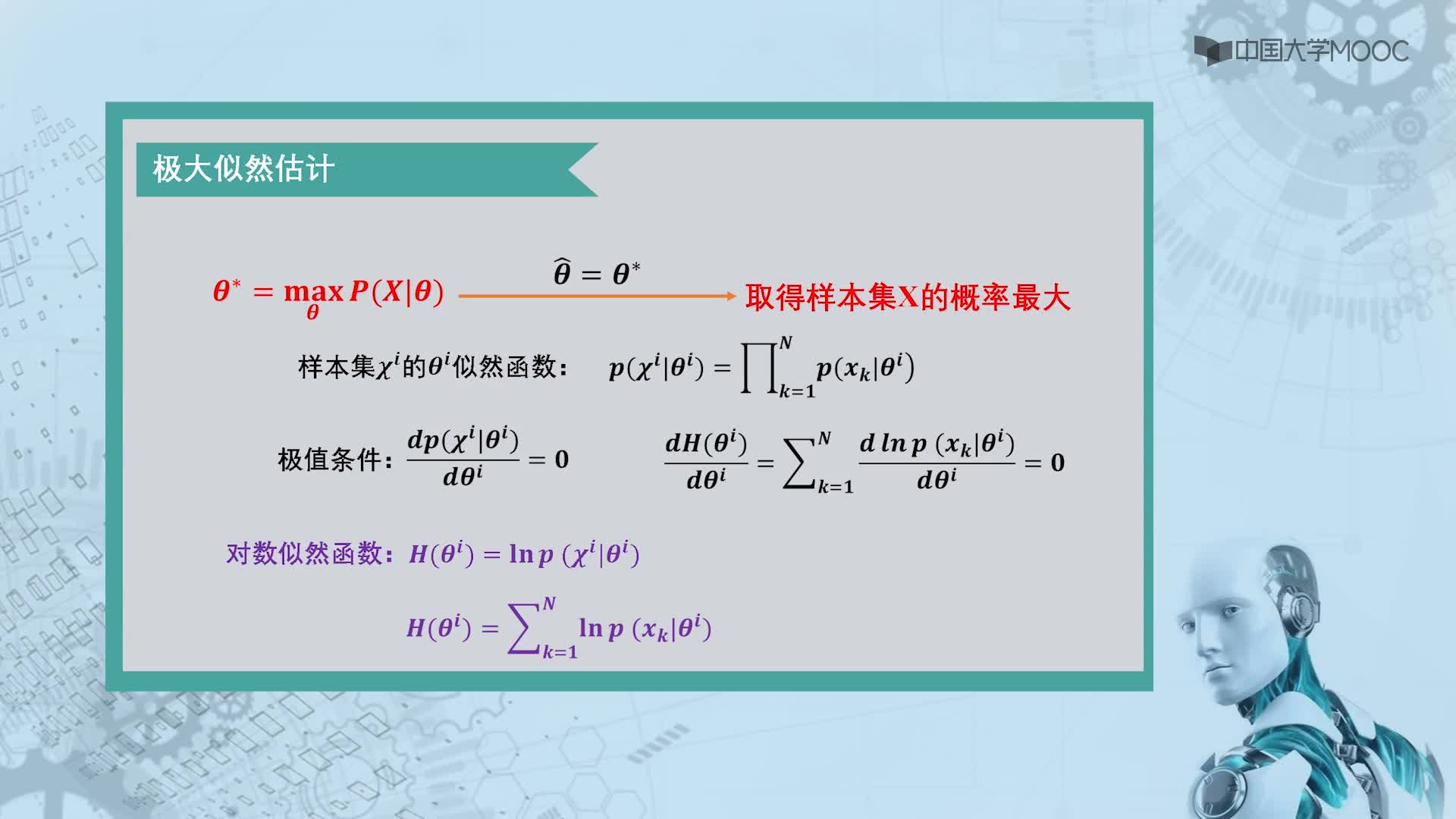
EM算法推導(dǎo)
假設(shè)我們有一個(gè)樣本集{x(1),…,x(m)},包含m個(gè)獨(dú)立的樣本。但每個(gè)樣本i對(duì)應(yīng)的類(lèi)別z(i)是未知的(相當(dāng)于聚類(lèi)),也即隱含變量。故我們需要估計(jì)概率模型p(x,z)的參數(shù)θ,但是由于里面包含隱含變量z,所以很難用最大似然求解,但如果z知道了,那我們就很容易求解了。
對(duì)于參數(shù)估計(jì),我們本質(zhì)上還是想獲得一個(gè)使似然函數(shù)最大化的那個(gè)參數(shù)θ,現(xiàn)在與最大似然不同的只是似然函數(shù)式中多了一個(gè)未知的變量z,見(jiàn)下式(1)。也就是說(shuō)我們的目標(biāo)是找到適合的θ和z讓L(θ)最大。那我們也許會(huì)想,你就是多了一個(gè)未知的變量而已啊,我也可以分別對(duì)未知的θ和z分別求偏導(dǎo),再令其等于0,求解出來(lái)不也一樣嗎?
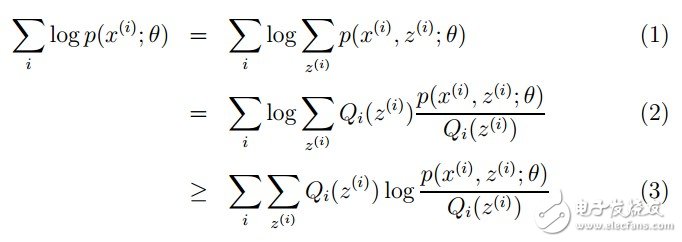
本質(zhì)上我們是需要最大化(1)式(對(duì)(1)式,我們回憶下聯(lián)合概率密度下某個(gè)變量的邊緣概率密度函數(shù)的求解,注意這里z也是隨機(jī)變量。對(duì)每一個(gè)樣本i的所有可能類(lèi)別z求等式右邊的聯(lián)合概率密度函數(shù)和,也就得到等式左邊為隨機(jī)變量x的邊緣概率密度),也就是似然函數(shù),但是可以看到里面有“和的對(duì)數(shù)”,求導(dǎo)后形式會(huì)非常復(fù)雜(自己可以想象下log(f1(x)+ f2(x)+ f3(x)+…)復(fù)合函數(shù)的求導(dǎo)),所以很難求解得到未知參數(shù)z和θ。那OK,我們可否對(duì)(1)式做一些改變呢?我們看(2)式,(2)式只是分子分母同乘以一個(gè)相等的函數(shù),還是有“和的對(duì)數(shù)”啊,還是求解不了,那為什么要這么做呢?咱們先不管,看(3)式,發(fā)現(xiàn)(3)式變成了“對(duì)數(shù)的和”,那這樣求導(dǎo)就容易了。我們注意點(diǎn),還發(fā)現(xiàn)等號(hào)變成了不等號(hào),為什么能這么變呢?這就是Jensen不等式的大顯神威的地方。
Jensen不等式:
設(shè)f是定義域?yàn)閷?shí)數(shù)的函數(shù),如果對(duì)于所有的實(shí)數(shù)x。如果對(duì)于所有的實(shí)數(shù)x,f(x)的二次導(dǎo)數(shù)大于等于0,那么f是凸函數(shù)。當(dāng)x是向量時(shí),如果其hessian矩陣H是半正定的,那么f是凸函數(shù)。如果只大于0,不等于0,那么稱(chēng)f是嚴(yán)格凸函數(shù)。
Jensen不等式表述如下:
如果f是凸函數(shù),X是隨機(jī)變量,那么:E[f(X)]》=f(E[X])
特別地,如果f是嚴(yán)格凸函數(shù),當(dāng)且僅當(dāng)X是常量時(shí),上式取等號(hào)。
如果用圖表示會(huì)很清晰:
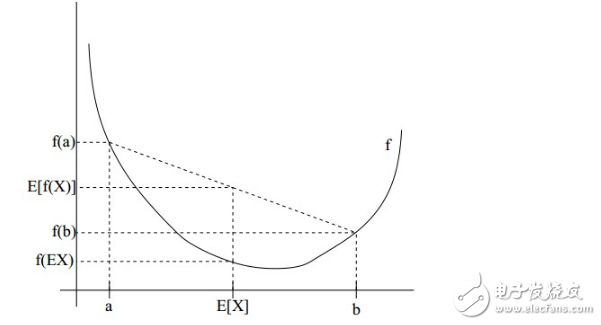
圖中,實(shí)線f是凸函數(shù),X是隨機(jī)變量,有0.5的概率是a,有0.5的概率是b。(就像擲硬幣一樣)。X的期望值就是a和b的中值了,圖中可以看到E[f(X)]》=f(E[X])成立。
當(dāng)f是(嚴(yán)格)凹函數(shù)當(dāng)且僅當(dāng)-f是(嚴(yán)格)凸函數(shù)。
Jensen不等式應(yīng)用于凹函數(shù)時(shí),不等號(hào)方向反向。
回到公式(2),因?yàn)閒(x)=log x為凹函數(shù)(其二次導(dǎo)數(shù)為-1/x2《0)。
(2)式中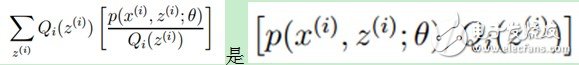 的期望,(考慮到E(X)=∑x*p(x),f(X)是X的函數(shù),則E(f(X))=∑f(x)*p(x)),又
的期望,(考慮到E(X)=∑x*p(x),f(X)是X的函數(shù),則E(f(X))=∑f(x)*p(x)),又![]() ,所以就可以得到公式(3)的不等式了(若不明白,請(qǐng)拿起筆,呵呵):
,所以就可以得到公式(3)的不等式了(若不明白,請(qǐng)拿起筆,呵呵):

OK,到這里,現(xiàn)在式(3)就容易地求導(dǎo)了,但是式(2)和式(3)是不等號(hào)啊,式(2)的最大值不是式(3)的最大值啊,而我們想得到式(2)的最大值,那怎么辦呢?
現(xiàn)在我們就需要一點(diǎn)想象力了,上面的式(2)和式(3)不等式可以寫(xiě)成:似然函數(shù)L(θ)》=J(z,Q),那么我們可以通過(guò)不斷的最大化這個(gè)下界J,來(lái)使得L(θ)不斷提高,最終達(dá)到它的最大值。
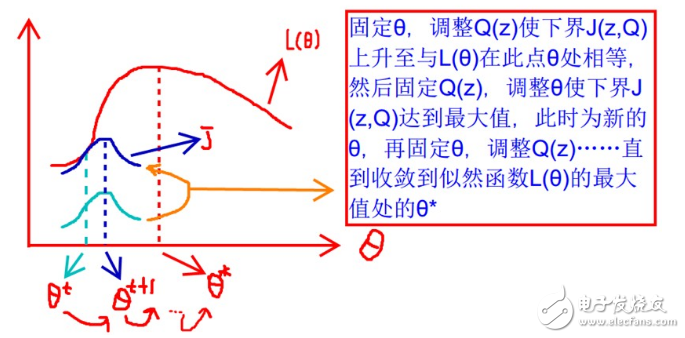
見(jiàn)上圖,我們固定θ,調(diào)整Q(z)使下界J(z,Q)上升至與L(θ)在此點(diǎn)θ處相等(綠色曲線到藍(lán)色曲線),然后固定Q(z),調(diào)整θ使下界J(z,Q)達(dá)到最大值(θt到θt+1),然后再固定θ,調(diào)整Q(z)……直到收斂到似然函數(shù)L(θ)的最大值處的θ*。這里有兩個(gè)問(wèn)題:什么時(shí)候下界J(z,Q)與L(θ)在此點(diǎn)θ處相等?為什么一定會(huì)收斂?
首先第一個(gè)問(wèn)題,在Jensen不等式中說(shuō)到,當(dāng)自變量X是常數(shù)的時(shí)候,等式成立。而在這里,即:
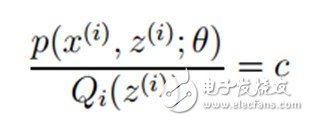
再推導(dǎo)下,由于![]() (因?yàn)镼是隨機(jī)變量z(i)的概率密度函數(shù)),則可以得到:分子的和等于c(分子分母都對(duì)所有z(i)求和:多個(gè)等式分子分母相加不變,這個(gè)認(rèn)為每個(gè)樣例的兩個(gè)概率比值都是c),則:
(因?yàn)镼是隨機(jī)變量z(i)的概率密度函數(shù)),則可以得到:分子的和等于c(分子分母都對(duì)所有z(i)求和:多個(gè)等式分子分母相加不變,這個(gè)認(rèn)為每個(gè)樣例的兩個(gè)概率比值都是c),則:

至此,我們推出了在固定參數(shù)θ后,使下界拉升的Q(z)的計(jì)算公式就是后驗(yàn)概率,解決了Q(z)如何選擇的問(wèn)題。這一步就是E步,建立L(θ)的下界。接下來(lái)的M步,就是在給定Q(z)后,調(diào)整θ,去極大化L(θ)的下界J(在固定Q(z)后,下界還可以調(diào)整的更大)。
舉個(gè)例子:
假設(shè)我們有一個(gè)袋子,里面裝著白球和黑球,但是我們不知道他們分別有多少個(gè),這時(shí)候需要我們估計(jì)每次取出一個(gè)球是白球的概率是多少?如何估計(jì)呢? 可以通過(guò)連續(xù)有放回的從袋子里面取一百次,看看是白球還是黑球。假設(shè)取100次里面 白球占70次,黑球30次。設(shè)抽取是白球的概率為P。 那么一百次抽取的總概率為 p(x;p)
p(x;p)=p(x1,x2.。。。。。.x100;θ)=p(x1;θ)*p(x2;θ)。。。。。。。.p(x100;θ)
=p70*(1-p)30
那么這時(shí)候我們希望可以使這個(gè)概率最大。
求導(dǎo):logp(x;p)=logp70*(1-p)30 另導(dǎo)數(shù)為0則可以求出p=0.7(同理可以用到連續(xù)變量里面,這時(shí)候就是概率密度函數(shù)的乘積so easy)
是不是很簡(jiǎn)單,對(duì)!就是這么簡(jiǎn)單!其實(shí)最大似然估計(jì)就是在給定一組數(shù)據(jù)和一個(gè)待定參數(shù)模型,如何確定這個(gè)模型未知參數(shù),使得這個(gè)確定后的參數(shù)模型產(chǎn)生的已知數(shù)據(jù)概率最大。當(dāng)然這里我只是舉了一個(gè)只有一個(gè)未知參數(shù)的估計(jì)方法,多個(gè)未知參數(shù)的做法是一樣的,就是求似然函數(shù)求導(dǎo)取最大值。其實(shí)并不是所有似然函數(shù)都可以求導(dǎo)的,當(dāng)似然函數(shù)無(wú)法求導(dǎo)時(shí)就需要根據(jù)定義求使得L(θ)最大的θ。
舉個(gè)例子,以拋篩子為例:

.最大后驗(yàn)估計(jì) (MAP):
最大后驗(yàn)估計(jì)就是在原來(lái)的MLE的基礎(chǔ)上加上了先驗(yàn)知識(shí):

EM算法另一種理解
坐標(biāo)上升法(Coordinate ascent):
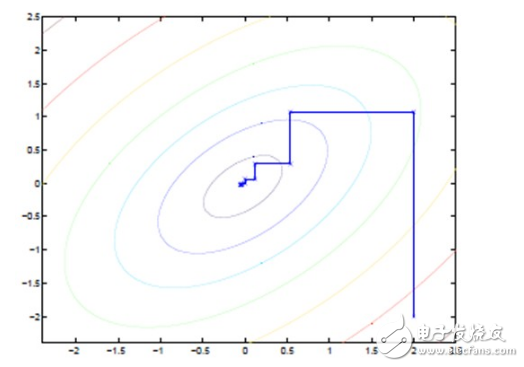
圖中的直線式迭代優(yōu)化的路徑,可以看到每一步都會(huì)向最優(yōu)值前進(jìn)一步,而且前進(jìn)路線是平行于坐標(biāo)軸的,因?yàn)槊恳徊街粌?yōu)化一個(gè)變量。
這猶如在x-y坐標(biāo)系中找一個(gè)曲線的極值,然而曲線函數(shù)不能直接求導(dǎo),因此什么梯度下降方法就不適用了。但固定一個(gè)變量后,另外一個(gè)可以通過(guò)求導(dǎo)得到,因此可以使用坐標(biāo)上升法,一次固定一個(gè)變量,對(duì)另外的求極值,最后逐步逼近極值。對(duì)應(yīng)到EM上,E步:固定θ,優(yōu)化Q;M步:固定Q,優(yōu)化θ;交替將極值推向最大。


















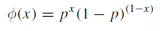



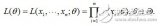





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論