 電子發(fā)燒友App
電子發(fā)燒友App


? ? ? ?現(xiàn)在市面上有很多64位多核A53的卡片電腦,比如樹莓派3、香橙派win、友善之臂K1+等。這些神奇的小電腦在功耗方面的表現(xiàn)非常好,CPU的性能也尚可,所以有不少玩家用它們DIY了筆記本,代替那些X86的高耗電機(jī)器,當(dāng)日常的個人電腦用。
但是,大家都在抱怨ARM桌面的用戶體驗不好。CPU還是不夠快;另外,顯卡實在是太垃圾了。
X86的Linux機(jī)器一般使用Intel、ATI或NVIDIA的顯卡,桌面操作、視頻播放或游戲娛樂的體驗都比較好。ARM的機(jī)器的圖形處理器就稍微寒酸一些,使用Mali 400、Mali450等低性能GPU,更糟的是在一些主線內(nèi)核里還經(jīng)常不帶驅(qū)動。
我也覺得不能玩H264硬解和OpenGL的電腦不是一臺好游戲機(jī)。。。
其實呢,友善之臂的代碼小哥也嫌棄自己過去做的桌面系統(tǒng)固件太不好用,所以他最近給自己新做了一整套真正好用的ARM桌面Linux系統(tǒng)。
代碼小哥找出了他們團(tuán)隊里最牛逼的硬件——Nano PC T4(基于RK3399)。
然后開發(fā)了整整七七四十九天,終于煉成了新固件——FriendlyDesktop18.04
這是首個支持GPU/VPU加速和4K硬解播放的Friendly系統(tǒng),也是目前驅(qū)動和應(yīng)用支持最完善的RK3399固件。鏡像文件分享在百度網(wǎng)盤上RK3399-sd-開頭的用于TF啟動運(yùn)行;RK3399-eflasher-開頭的用于卡刷;RK3399-TypeC-開頭的用于線刷。
代碼小哥對自己的作品非常自豪,所以強(qiáng)烈建議我趕緊試用一下。
他說,這次的系統(tǒng)固件,有以下幾點(diǎn)特性:
1) 帶X桌面 LXDE,基于64位Ubuntu 18.04系統(tǒng)構(gòu)建,支持OpenGLES加速,支持硬解播放
2) 支持SD卡啟動運(yùn)行,支持TF卡刷機(jī)或Type-C刷機(jī)
3) 完全保留FriendlyCore18.04 for RK3399的特性,集成帶GPU和VPU加速的Qt 5.10.0
4) 內(nèi)置開源硬解的4K視頻播放器 QtVideoPlayer(Menu->Sound & Video->Qt5-VideoPlayer)
5) 內(nèi)置 QtCreator IDE,Arduino 和 Scratch等流行開發(fā)和學(xué)習(xí)工具,開箱即用
6) 支持雙屏異顯 (可選擇eDP/DP/HDMI 任意兩路同時輸出)
7) 支持eDP電容觸摸屏 (HD702E)
8) 支持AP6356S無線模塊 (802.11a/b/g/n/AC,BLE4.0)
9) 支持升兆以太網(wǎng)即插即用
10) 支持OpenCV 3.4 一鍵安裝
11) 內(nèi)置gcc版本:7.3.0
12) 內(nèi)核版本:4.4.138
評測:我知道大家都對OpenGL感興趣,那么我們先測試一下OpenGL吧。如果GPU沒有正常驅(qū)動的話,玩游戲會非常卡。
在glmark里,主要是做各種多邊形、紋理和著色器的測試。比如下圖是個貓模型曲面漫反射渲染的測試。
下圖是個玻璃材質(zhì)著色器渲染兔子模型的測試。
不同的渲染項目下,計算量是不同的,各個測試的幀數(shù)記錄在終端輸出上。
這塊板子的處理器RK3399是大小核架構(gòu)的。其中,CPU ID號0到3的四個是低速的A53核心,CPU ID號4和5的兩個是高性能的A72核心。
在上一篇文章里,我們已經(jīng)知道大小核這種奇葩架構(gòu)的多線程能力并不好。
所以,測試時候,如果不指定核心,讓操作系統(tǒng)瞎調(diào)度,并不能發(fā)揮系統(tǒng)的真正實力(雖然幀數(shù)也挺不錯的,毫無卡頓)。比如第一項是45FPS。
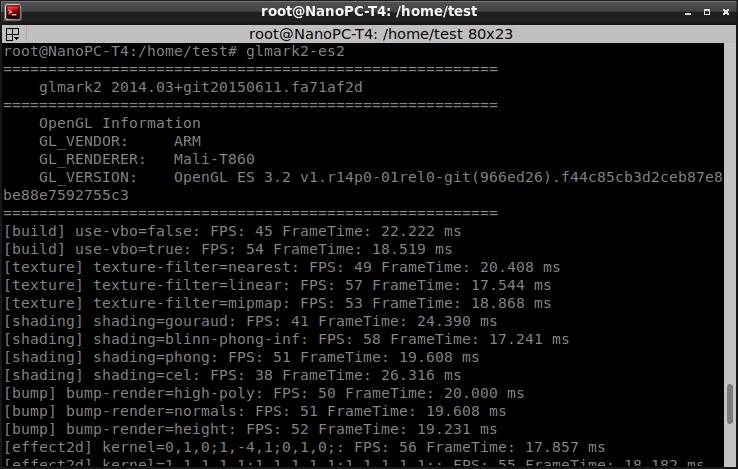
當(dāng)指定使用CPU ID號4和5的兩個高性能A72核心時候,測試得到的幀數(shù)比剛才要高一些。比如第一項是57FPS。
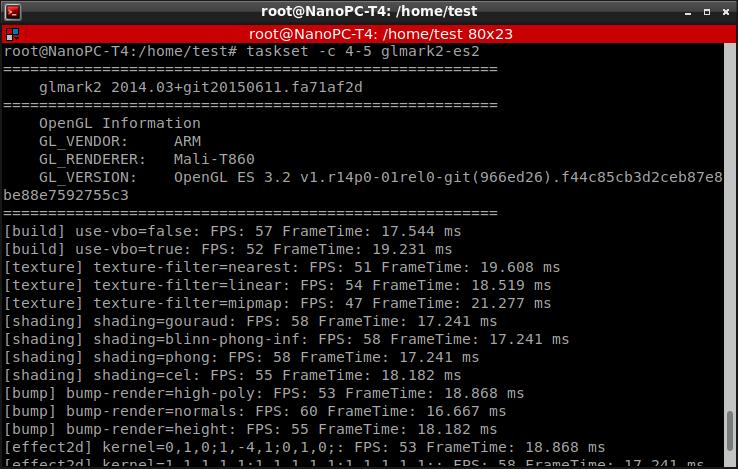
我們稍微等待一下,等所有GPU測試項目都跑完。整個過程都非常流暢,幀數(shù)都保持再30幀以上;這說明一般的OpenGL渲染程序或游戲跑起來都不會有太大的問題(這個測試模擬了你在游戲時候?qū)崟r渲染不同的場景)。
接下來我們來試一下OpenCV人臉識別的例子。我們關(guān)注一下識別的速度,大約是100毫秒,也就是說可以達(dá)到10Hz的識別速度。
對于RK3399,我們也要關(guān)注一下大小核在做OpenCV人臉識別時候的并行效果。
大小核能不能在OpenCV里正常并行加速呢?
我做了下面這幾組測試。
一個A72核心單獨(dú)跑這個算法,大約需要250毫秒。
兩個A72并行,大約需要140毫秒。速度比單個A72快。
換做是一個比較慢的A53核心單獨(dú)跑,大約需要450毫秒。
四個A53并行,大約需要140毫秒。并行提速效果不錯。
如果2個A72+4個A53一起上,時間只要大約100毫秒。在OpenCV測試?yán)铮笮『艘黄鹕系乃俣仁亲羁斓摹?/p>
在上面這個測試?yán)铮覀兛梢园l(fā)現(xiàn)RK3399的大小核在OpenCV并行計算過程中的效率還是可以的,能大幅提高計算速度;并不會因為大小核之間的速率不一致而在調(diào)度過程中浪費(fèi)太多資源。(但是我們不要高興的太早,最后面的測試?yán)飼l(fā)現(xiàn),有時會發(fā)生“逆加速”)
一個額外的小測試:前段時間,有網(wǎng)友在云漢試用群里反映Nano PC T4的DDR3內(nèi)存寫入速度只有300MB每秒,慢得跟樹莓派3的DDR2差不多。正好我這次拿到Nano PC T4實物了,我們就測試一下。
內(nèi)存寫入速度的測試代碼如下。這是個6線程寫入的例子,稍作修改就可以改成4線程寫入。程序的算法很簡單,分配1GB的內(nèi)存空間并填滿1,測多少時間完成。

代碼編譯運(yùn)行結(jié)果如下(絕無作弊)
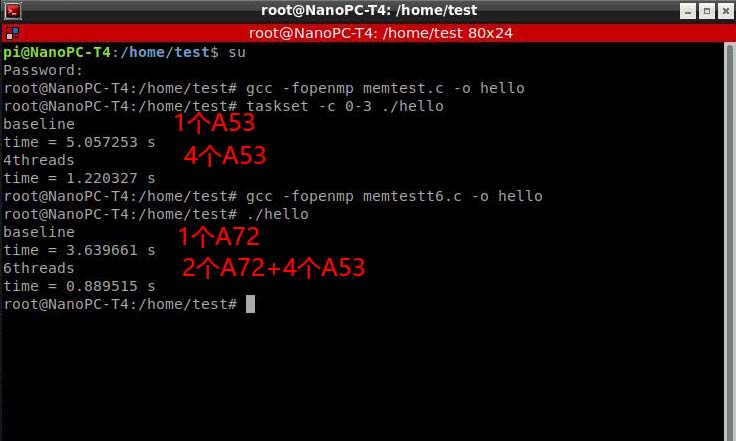
我們可以發(fā)現(xiàn),不管是1個A53還是4個A53并行寫入,都不能把內(nèi)存的寫入帶寬耗盡。當(dāng)2個A72和4個A53一起并行寫入時,速度大約是1.125GB每秒。大家可能對這個速度沒有概念,1.125GB每秒有多快呢?我們跟搭載DDR4的RK3328板子比較一下吧,那個板子的評測地址在http://www.ickey.cc/e/video/detail/57.html。
3328板子的DDR4內(nèi)存寫入速度是1.089GB每秒。Nano Pi T4的DDR3內(nèi)存寫入速度是1.125GB每秒。
大家可以發(fā)現(xiàn)T4雖然內(nèi)存規(guī)格低了一些,但是實際使用時候也是一點(diǎn)都不吃虧的。因為內(nèi)存寫入瓶頸是在處理器,RK3399的處理器比較好,往內(nèi)存寫入數(shù)據(jù)的速度快。
所以,那天在云漢試用群里的那個大兄弟,是冤枉Nano PC T4 了。
另一個額外的小測試:上一篇文章《大小核的OpenMP多線程并行計算測試》里,我們已經(jīng)知道大小核在并行時候是會浪費(fèi)很多資源在不同速度進(jìn)程的調(diào)度上的。我們今天再做個測試,如果指定用哪幾個CPU做并行,效果是不是能好一些?
測試代碼如下。

測試過程的截圖如下,分別對不指定CPU(系統(tǒng)自動調(diào)度),指定只用A53,和只用A72做了對比。
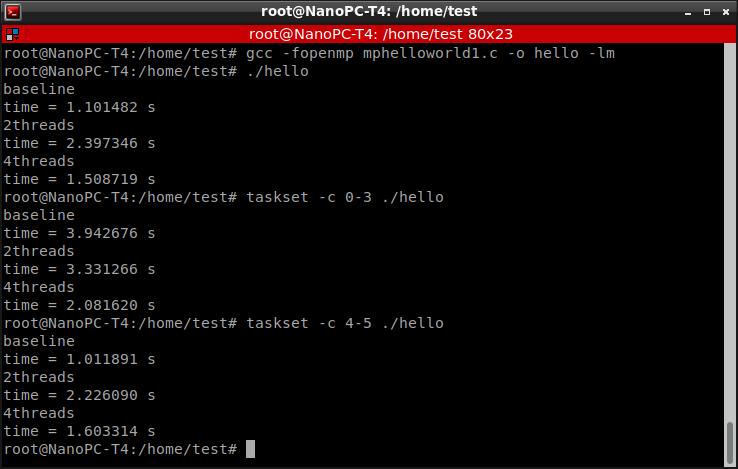
如果不指定CPU,單線程耗時1.10秒;這個速度介于指定A53單線程(3.94秒)和指定A72單線程(1.01秒)之間,但是更接近A72單線程時候的耗時。這說明系統(tǒng)的自動調(diào)度效率還是比較高的,能主動讓A72去執(zhí)行大計算量的工作。
所以,對于單線程的工作,我們只要讓系統(tǒng)自己去調(diào)度就好了。
A53的單核計算速度很慢,但是4核并行時候的提速效果較好,計算耗時從3.94秒降至2.08秒,耗時減少一半。
所以,對于那種又需要省電又需要一定計算能力的工作,可以采用指定4個A53并行的方式來做。
A72的單核能力不錯,但是越并越慢。單核A72時候速度最快,只要1.01秒。指定兩個A72并行時候,速度反而變慢了。
可能是ARM得罪了OpenMP吧,所以O(shè)penMP對ARM的最新A72內(nèi)核做了坑爹的“逆優(yōu)化”
但是不管怎么說,速度依然是很快的,日常游戲和看視頻娛樂都沒有問題。











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論