 電子發燒友App
電子發燒友App


作者簡介:余華兵,在網絡通信行業工作十多年,負責IPv4協議棧、IPv6協議棧和Linux內核。在工作中看著2.6版本的專業書籍維護3.x和4.x版本的Linux內核,感覺不方便,于是自己分析4.x版本的Linux內核整理出一本書,書名叫《Linux內核深度解析》,2019年5月出版,希望對同行有幫助。
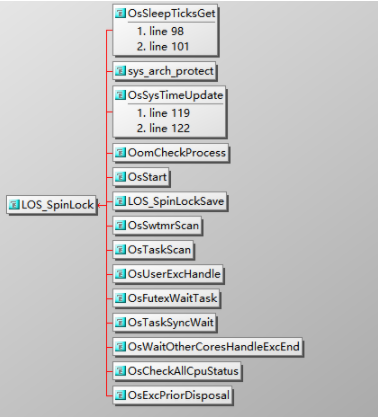
自旋鎖用于處理器之間的互斥,適合保護很短的臨界區,并且不允許在臨界區睡眠。申請自旋鎖的時候,如果自旋鎖被其他處理器占有,本處理器自旋等待(也稱為忙等待)。
進程、軟中斷和硬中斷都可以使用自旋鎖。
自旋鎖的實現經歷了3個階段:
(1) 最早的自旋鎖是無序競爭的,不保證先申請的進程先獲得鎖。
(2) 第2個階段是入場券自旋鎖,進程按照申請鎖的順序排隊,先申請的進程先獲得鎖。
(3) 第3個階段是MCS自旋鎖。入場券自旋鎖存在性能問題:所有申請鎖的處理器在同一個變量上自旋等待,緩存同步的開銷大,不適合處理器很多的系統。MCS自旋鎖的策略是為每個處理器創建一個變量副本,每個處理器在自己的本地變量上自旋等待,解決了性能問題。
入場券自旋鎖和MCS自旋鎖都屬于排隊自旋鎖(queued spinlock),進程按照申請鎖的順序排隊,先申請的進程先獲得鎖。
1. 數據結構
自旋鎖的定義如下:
include/linux/spinlock_types.h
typedef struct spinlock {
union {
struct raw_spinlock rlock;
…
};
} spinlock_t;
typedef struct raw_spinlock {
arch_spinlock_t raw_lock;
…
} raw_spinlock_t;
可以看到,數據類型spinlock對raw_spinlock做了封裝,然后數據類型raw_spinlock對arch_spinlock_t做了封裝,各種處理器架構需要自定義數據類型arch_spinlock_t。
spinlock和raw_spinlock(原始自旋鎖)有什么關系?
Linux內核有一個實時內核分支(開啟配置宏CONFIG_PREEMPT_RT)來支持硬實時特性,內核主線只支持軟實時。
對于沒有打上實時內核補丁的內核,spinlock只是封裝raw_spinlock,它們完全一樣。如果打上實時內核補丁,那么spinlock使用實時互斥鎖保護臨界區,在臨界區內可以被搶占和睡眠,但raw_spinlock還是自旋鎖。
目前主線版本還沒有合并實時內核補丁,說不定哪天就會合并進來,為了使代碼可以兼容實時內核,最好堅持3個原則:
(1)盡可能使用spinlock。
(2)絕對不允許被搶占和睡眠的地方,使用raw_spinlock,否則使用spinlock。
(3)如果臨界區足夠小,使用raw_spinlock。
2. 使用方法
定義并且初始化靜態自旋鎖的方法是:
DEFINE_SPINLOCK(x);
在運行時動態初始化自旋鎖的方法是:
spin_lock_init(x);
申請自旋鎖的函數是:
(1)void spin_lock(spinlock_t *lock);
申請自旋鎖,如果鎖被其他處理器占有,當前處理器自旋等待。
(2)void spin_lock_bh(spinlock_t *lock);
申請自旋鎖,并且禁止當前處理器的軟中斷。
(3)void spin_lock_irq(spinlock_t *lock);
申請自旋鎖,并且禁止當前處理器的硬中斷。
(4)spin_lock_irqsave(lock, flags);
申請自旋鎖,保存當前處理器的硬中斷狀態,并且禁止當前處理器的硬中斷。
(5)int spin_trylock(spinlock_t *lock);
申請自旋鎖,如果申請成功,返回1;如果鎖被其他處理器占有,當前處理器不等待,立即返回0。
釋放自旋鎖的函數是:
(1)void spin_unlock(spinlock_t *lock);
(2)void spin_unlock_bh(spinlock_t *lock);
釋放自旋鎖,并且開啟當前處理器的軟中斷。
(3)void spin_unlock_irq(spinlock_t *lock);
釋放自旋鎖,并且開啟當前處理器的硬中斷。
(4)void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags);
釋放自旋鎖,并且恢復當前處理器的硬中斷狀態。
定義并且初始化靜態原始自旋鎖的方法是:
DEFINE_RAW_SPINLOCK(x);
在運行時動態初始化原始自旋鎖的方法是:
raw_spin_lock_init (x);
申請原始自旋鎖的函數是:
(1)raw_spin_lock(lock)
申請原始自旋鎖,如果鎖被其他處理器占有,當前處理器自旋等待。
(2)raw_spin_lock_bh(lock)
申請原始自旋鎖,并且禁止當前處理器的軟中斷。
(3)raw_spin_lock_irq(lock)
申請原始自旋鎖,并且禁止當前處理器的硬中斷。
(4)raw_spin_lock_irqsave(lock, flags)
申請原始自旋鎖,保存當前處理器的硬中斷狀態,并且禁止當前處理器的硬中斷。
(5)raw_spin_trylock(lock)
申請原始自旋鎖,如果申請成功,返回1;如果鎖被其他處理器占有,當前處理器不等待,立即返回0。
釋放原始自旋鎖的函數是:
(1)raw_spin_unlock(lock)
(2)raw_spin_unlock_bh(lock)
釋放原始自旋鎖,并且開啟當前處理器的軟中斷。
(3)raw_spin_unlock_irq(lock)
釋放原始自旋鎖,并且開啟當前處理器的硬中斷。
(4)raw_spin_unlock_irqrestore(lock, flags)
釋放原始自旋鎖,并且恢復當前處理器的硬中斷狀態。
3. 入場券自旋鎖
入場券自旋鎖(ticket spinlock)的算法類似于銀行柜臺的排隊叫號:
(1)鎖擁有排隊號和服務號,服務號是當前占有鎖的進程的排隊號。
(2)每個進程申請鎖的時候,首先申請一個排隊號,然后輪詢鎖的服務號是否等于自己的排隊號,如果等于,表示自己占有鎖,可以進入臨界區,否則繼續輪詢。
(3)當進程釋放鎖時,把服務號加一,下一個進程看到服務號等于自己的排隊號,退出自旋,進入臨界區。
ARM64架構定義的數據類型arch_spinlock_t如下所示:
arch/arm64/include/asm/spinlock_types.h
typedef struct {
#ifdef __AARCH64EB__ /* 大端字節序(高位存放在低地址) */
u16 next;
u16 owner;
#else /* 小端字節序(低位存放在低地址) */
u16 owner;
u16 next;
#endif
} __aligned(4) arch_spinlock_t;
成員next是排隊號,成員owner是服務號。
在多處理器系統中,函數spin_lock()負責申請自旋鎖,ARM64架構的代碼如下所示:
spin_lock() -》 raw_spin_lock() -》 _raw_spin_lock() -》 __raw_spin_lock() -》 do_raw_spin_lock() -》 arch_spin_lock()
arch/arm64/include/asm/spinlock.h
1 static inline void arch_spin_lock(arch_spinlock_t *lock)
2 {
3 unsigned int tmp;
4 arch_spinlock_t lockval, newval;
5
6 asm volatile(
7 ARM64_LSE_ATOMIC_INSN(
8 /* LL/SC */
9 “ prfm pstl1strm, %3\n”
10 “1: ldaxr %w0, %3\n”
11 “ add %w1, %w0, %w5\n”
12 “ stxr %w2, %w1, %3\n”
13 “ cbnz %w2, 1b\n”,
14 /* 大系統擴展的原子指令 */
15 “ mov %w2, %w5\n”
16 “ ldadda %w2, %w0, %3\n”
17 __nops(3)
18 )
19
20 /* 我們得到鎖了嗎?*/
21 “ eor %w1, %w0, %w0, ror #16\n”
22 “ cbz %w1, 3f\n”
23 “ sevl\n”
24 “2: wfe\n”
25 “ ldaxrh %w2, %4\n”
26 “ eor %w1, %w2, %w0, lsr #16\n”
27 “ cbnz %w1, 2b\n”
28 /* 得到鎖,臨界區從這里開始*/
29 “3:”
30 : “=&r” (lockval), “=&r” (newval), “=&r” (tmp), “+Q” (*lock)
31 : “Q” (lock-》owner), “I” (1 《《 TICKET_SHIFT)
32 : “memory”);
33 }
第6~18行代碼,申請排隊號,然后把自旋鎖的排隊號加1,這是一個原子操作,有兩種實現方法:
1)第9~13行代碼,使用指令ldaxr(帶有獲取語義的獨占加載)和stxr(獨占存儲)實現,指令ldaxr帶有獲取語義,后面的加載/存儲指令必須在指令ldaxr完成之后開始執行。
2)第15~16行代碼,如果處理器支持大系統擴展,那么使用帶有獲取語義的原子加法指令ldadda實現,指令ldadda帶有獲取語義,后面的加載/存儲指令必須在指令ldadda完成之后開始執行。
第21~22行代碼,如果服務號等于當前進程的排隊號,進入臨界區。
第24~27行代碼,如果服務號不等于當前進程的排隊號,那么自旋等待。使用指令ldaxrh(帶有獲取語義的獨占加載,h表示halfword,即2字節)讀取服務號,指令ldaxrh帶有獲取語義,后面的加載/存儲指令必須在指令ldaxrh完成之后開始執行。
第23行代碼,sevl(send event local)指令的功能是發送一個本地事件,避免錯過其他處理器釋放自旋鎖時發送的事件。
第24行代碼,wfe(wait for event)指令的功能是使處理器進入低功耗狀態,等待事件。
函數spin_unlock()負責釋放自旋鎖,ARM64架構的代碼如下所示:
spin_unlock() -》 raw_spin_unlock() -》 _raw_spin_unlock() -》 __raw_spin_unlock() -》 do_raw_spin_unlock() -》 arch_spin_unlock()
arch/arm64/include/asm/spinlock.h
1 static inline void arch_spin_unlock(arch_spinlock_t *lock)
2 {
3 unsigned long tmp;
4
5 asm volatile(ARM64_LSE_ATOMIC_INSN(
6 /* LL/SC */
7 “ ldrh %w1, %0\n”
8 “ add %w1, %w1, #1\n”
9 “ stlrh %w1, %0”,
10 /* 大多統擴展的原子指令 */
11 “ mov %w1, #1\n”
12 “ staddlh %w1, %0\n”
13 __nops(1))
14 : “=Q” (lock-》owner), “=&r” (tmp)
15 :
16 : “memory”);
17 }
把自旋鎖的服務號加1,有兩種實現方法:
(1)第7~9行代碼,使用指令ldrh(加載,h表示halfword,即2字節)和stlrh(帶有釋放語義的存儲)實現,指令stlrh帶有釋放語義,前面的加載/存儲指令必須在指令stlrh開始執行之前執行完。因為一次只能有一個進程進入臨界區,所以只有一個進程把自旋鎖的服務號加1,不需要是原子操作。
(2)第11~12行代碼,如果處理器支持大系統擴展,那么使用帶有釋放語義的原子加法指令staddlh實現,指令staddlh帶有釋放語義,前面的加載/存儲指令必須在指令staddlh開始執行之前執行完。
在單處理器系統中,自旋鎖是空的。
include/linux/spinlock_types_up.h
typedef struct { } arch_spinlock_t;
函數spin_lock()只是禁止內核搶占。
spin_lock() -》 raw_spin_lock() -》 _raw_spin_lock()
include/linux/spinlock_api_up.h
#define _raw_spin_lock(lock) __LOCK(lock)
#define __LOCK(lock) \
do { preempt_disable(); ___LOCK(lock); } while (0)
#define ___LOCK(lock) \
do { __acquire(lock); (void)(lock); } while (0)
4. MCS自旋鎖
入場券自旋鎖存在性能問題:所有等待同一個自旋鎖的處理器在同一個變量上自旋等待,申請或者釋放鎖的時候會修改鎖,導致其他處理器存放自旋鎖的緩存行失效,在擁有幾百甚至幾千個處理器的大型系統中,處理器申請自旋鎖時競爭可能很激烈,緩存同步的開銷很大,導致系統性能大幅度下降。
MCS(MCS是“Mellor-Crummey”和“Scott”這兩個發明人的名字的首字母縮寫)自旋鎖解決了這個缺點,它的策略是為每個處理器創建一個變量副本,每個處理器在申請自旋鎖的時候在自己的本地變量上自旋等待,避免緩存同步的開銷。
4.1. 傳統的MCS自旋鎖
傳統的MCS自旋鎖包含:
(1)一個指針tail指向隊列的尾部。
(2)每個處理器對應一個隊列節點,即mcs_lock_node結構體,其中成員next指向隊列的下一個節點,成員locked指示鎖是否被其他處理器占有,如果成員locked的值為1,表示鎖被其他處理器占有。
結構體的定義如下所示:
typedef struct __mcs_lock_node {
struct __mcs_lock_node *next;
int locked;
} ____cacheline_aligned_in_smp mcs_lock_node;
typedef struct {
mcs_lock_node *tail;
mcs_lock_node nodes[NR_CPUS];/* NR_CPUS是處理器的數量 */
} spinlock_t;
其中“____cacheline_aligned_in_smp”的作用是:在多處理器系統中,結構體的起始地址和長度都是一級緩存行長度的整數倍。
當沒有處理器占有或者等待自旋鎖的時候,隊列是空的,tail是空指針。
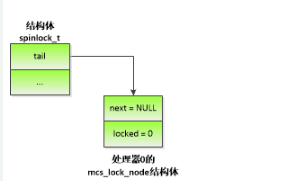
圖 4.1 處理器0申請MCS自旋鎖
如圖 4.1所示,當處理器0申請自旋鎖的時候,執行原子交換操作,使tail指向處理器0的mcs_lock_node結構體,并且返回tail的舊值。tail的舊值是空指針,說明自旋鎖處于空閑狀態,那么處理器0獲得自旋鎖。
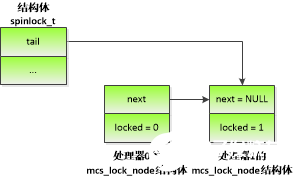
圖 4.2 處理器1申請MCS自旋鎖
如圖 4.2所示,當處理器0占有自旋鎖的時候,處理器1申請自旋鎖,執行原子交換操作,使tail指向處理器1的mcs_lock_node結構體,并且返回tail的舊值。tail的舊值是處理器0的mcs_lock_node結構體的地址,說明自旋鎖被其他處理器占有,那么使處理器0的mcs_lock_node結構體的成員next指向處理器1的mcs_lock_node結構體,把處理器1的mcs_lock_node結構體的成員locked設置為1,然后處理器1在自己的mcs_lock_node結構體的成員locked上面自旋等待,等待成員locked的值變成0。
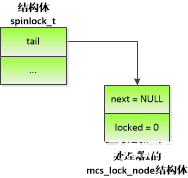
圖 4.3 處理器0釋放MCS自旋鎖
如圖 4.3所示,處理器0釋放自旋鎖,發現自己的mcs_lock_node結構體的成員next不是空指針,說明有申請者正在等待鎖,于是把下一個節點的成員locked設置為0,處理器1獲得自旋鎖。
處理器1釋放自旋鎖,發現自己的mcs_lock_node結構體的成員next是空指針,說明自己是最后一個申請者,于是執行原子比較交換操作:如果tail指向自己的mcs_lock_node結構體,那么把tail設置為空指針。
4.2. 小巧的MCS自旋鎖
傳統的MCS自旋鎖存在的缺陷是:結構體的長度太大,因為mcs_lock_node結構體的起始地址和長度都必須是一級緩存行長度的整數倍,所以MCS自旋鎖的長度是(一級緩存行長度 + 處理器數量 * 一級緩存行長度),而入場券自旋鎖的長度只有4字節。自旋鎖被嵌入到內核的很多結構體中,如果自旋鎖的長度增加,會導致這些結構體的長度增加。
經過內核社區技術專家的努力,成功地把MCS自旋鎖放進4個字節,實現了小巧的MCS自旋鎖。自旋鎖的定義如下所示:
include/asm-generic/qspinlock_types.h
typedef struct qspinlock {
atomic_t val;
} arch_spinlock_t;
另外,為每個處理器定義1個隊列節點數組,如下所示:
kernel/locking/qspinlock.c
#ifdef CONFIG_PARAVIRT_SPINLOCKS
#define MAX_NODES 8
#else
#define MAX_NODES 4
#endif
static DEFINE_PER_CPU_ALIGNED(struct mcs_spinlock, mcs_nodes[MAX_NODES]);
配置宏CONFIG_PARAVIRT_SPINLOCKS用來啟用半虛擬化的自旋鎖,給虛擬機使用,本文不考慮這種使用場景。每個處理器需要4個隊列節點,原因如下:
(1) 申請自旋鎖的函數禁止內核搶占,所以進程在等待自旋鎖的過程中不會被其他進程搶占。
(2) 進程在等待自旋鎖的過程中可能被軟中斷搶占,然后軟中斷等待另一個自旋鎖。
(3) 軟中斷在等待自旋鎖的過程中可能被硬中斷搶占,然后硬中斷等待另一個自旋鎖。
(4) 硬中斷在等待自旋鎖的過程中可能被不可屏蔽中斷搶占,然后不可屏蔽中斷等待另一個自旋鎖。
綜上所述,一個處理器最多同時等待4個自旋鎖。
和入場券自旋鎖相比,MCS自旋鎖增加的內存開銷是數組mcs_nodes。
隊列節點的定義如下所示:
kernel/locking/mcs_spinlock.h
struct mcs_spinlock {
struct mcs_spinlock *next;
int locked;
int count;
};
其中成員next指向隊列的下一個節點;成員locked指示鎖是否被前一個等待者占有,如果值為1,表示鎖被前一個等待者占有;成員count是嵌套層數,也就是數組mcs_nodes已分配的數組項的數量。
自旋鎖的32個二進制位被劃分成4個字段:
(1) locked字段,指示鎖已經被占有,長度是一個字節,占用第0~7位。
(2) 一個pending位,占用第8位,第1個等待自旋鎖的處理器設置pending位。
(3) index字段,是數組索引,指示隊列的尾部節點使用數組mcs_nodes的哪一項。
(4) cpu字段,存放隊列的尾部節點的處理器編號,實際存儲的值是處理器編號加上1,cpu字段減去1才是真實的處理器編號。
index字段和cpu字段合起來稱為tail字段,存放隊列的尾部節點的信息,布局分兩種情況:
(1) 如果處理器的數量小于2的14次方,那么第9~15位沒有使用,第16~17位是index字段,第18~31位是cpu字段。
(2) 如果處理器的數量大于或等于2的14次方,那么第9~10位是index字段,第11~31位是cpu字段。
把MCS自旋鎖放進4個字節的關鍵是:存儲處理器編號和數組索引,而不是存儲尾部節點的地址。
內核對MCS自旋鎖做了優化:第1個等待自旋鎖的處理器直接在鎖自身上面自旋等待,不是在自己的mcs_spinlock結構體上自旋等待。這個優化帶來的好處是:當鎖被釋放的時候,不需要訪問mcs_spinlock結構體的緩存行,相當于減少了一次緩存沒命中。后續的處理器在自己的mcs_spinlock結構體上面自旋等待,直到它們移動到隊列的首部為止。
自旋鎖的pending位進一步擴展這個優化策略。第1個等待自旋鎖的處理器簡單地設置pending位,不需要使用自己的mcs_spinlock結構體。第2個處理器看到pending被設置,開始創建等待隊列,在自己的mcs_spinlock結構體的locked字段上自旋等待。這種做法消除了兩個等待者之間的緩存同步,而且第1個等待者沒使用自己的mcs_spinlock結構體,減少了一次緩存行沒命中。
在多處理器系統中,申請MCS自旋鎖的代碼如下所示:
spin_lock() -》 raw_spin_lock() -》 _raw_spin_lock() -》 __raw_spin_lock() -》 do_raw_spin_lock() -》 arch_spin_lock()
include/asm-generic/qspinlock.h
1 #define arch_spin_lock(l) queued_spin_lock(l)
2
3 static __always_inline void queued_spin_lock(struct qspinlock *lock)
4 {
5 u32 val;
6
7 val = atomic_cmpxchg_acquire(&lock-》val, 0, _Q_LOCKED_VAL);
8 if (likely(val == 0))
9 return;
10 queued_spin_lock_slowpath(lock, val);
11 }
第7行代碼,執行帶有獲取語義的原子比較交換操作,如果鎖的值是0,那么把鎖的locked字段設置為1。獲取語義保證后面的加載/存儲指令必須在函數atomic_cmpxchg_acquire()完成之后開始執行。函數atomic_cmpxchg_acquire()返回鎖的舊值。
第8~9行代碼,如果鎖的舊值是0,說明申請鎖的時候鎖處于空閑狀態,那么成功地獲得鎖。
第10行代碼,如果鎖的舊值不是0,說明鎖不是處于空閑狀態,那么執行申請自旋鎖的慢速路徑。
申請MCS自旋鎖的慢速路徑如下所示:
kernel/locking/qspinlock.c
1 void queued_spin_lock_slowpath(struct qspinlock *lock, u32 val)
2 {
3 struct mcs_spinlock *prev, *next, *node;
4 u32 new, old, tail;
5 int idx;
6
7 。。.
8 if (val == _Q_PENDING_VAL) {
9 while ((val = atomic_read(&lock-》val)) == _Q_PENDING_VAL)
10 cpu_relax();
11 }
12
13 for (;;) {
14 if (val & ~_Q_LOCKED_MASK)
15 goto queue;
16
17 new = _Q_LOCKED_VAL;
18 if (val == new)
19 new |= _Q_PENDING_VAL;
20
21 old = atomic_cmpxchg_acquire(&lock-》val, val, new);
22 if (old == val)
23 break;
24
25 val = old;
26 }
27
28 if (new == _Q_LOCKED_VAL)
29 return;
30
31 smp_cond_load_acquire(&lock-》val.counter, !(VAL & _Q_LOCKED_MASK));
32
33 clear_pending_set_locked(lock);
34 return;
35
36 queue:
37 node = this_cpu_ptr(&mcs_nodes[0]);
38 idx = node-》count++;
39 tail = encode_tail(smp_processor_id(), idx);
40
41 node += idx;
42 node-》locked = 0;
43 node-》next = NULL;
44 。。.
45
46 if (queued_spin_trylock(lock))
47 goto release;
48
49 old = xchg_tail(lock, tail);
50 next = NULL;
51
52 if (old & _Q_TAIL_MASK) {
53 prev = decode_tail(old);
54 smp_read_barrier_depends();
55
56 WRITE_ONCE(prev-》next, node);
57
58 。。.
59 arch_mcs_spin_lock_contended(&node-》locked);
60
61 next = READ_ONCE(node-》next);
62 if (next)
63 prefetchw(next);
64 }
65
66 。。.
67 val = smp_cond_load_acquire(&lock-》val.counter, !(VAL & _Q_LOCKED_PENDING_MASK));
68
69 locked:
70 for (;;) {
71 if ((val & _Q_TAIL_MASK) != tail) {
72 set_locked(lock);
73 break;
74 }
75
76 old = atomic_cmpxchg_relaxed(&lock-》val, val, _Q_LOCKED_VAL);
77 if (old == val)
78 goto release;
79
80 val = old;
81 }
82
83 if (!next) {
84 while (!(next = READ_ONCE(node-》next)))
85 cpu_relax();
86 }
87
88 arch_mcs_spin_unlock_contended(&next-》locked);
89 。。.
90
91 release:
92 __this_cpu_dec(mcs_nodes[0].count);
93 }
第8~11行代碼,如果鎖的狀態是pending,即{tail=0,pending=1,locked=0},那么等待鎖的狀態變成locked,即{tail=0,pending=0,locked=1}。
第14~15行代碼,如果鎖的tail字段不是0或者pending位是1,說明已經有處理器在等待自旋鎖,那么跳轉到標號queue,本處理器加入等待隊列。
第17~21行代碼,如果鎖處于locked狀態,那么把鎖的狀態設置為locked & pending,即{tail=0,pending=1,locked=1};如果鎖處于空閑狀態(占有鎖的處理器剛剛釋放自旋鎖),那么把鎖的狀態設置為locked。
第28~29行代碼,如果上一步鎖的狀態從空閑變成locked,那么成功地獲得鎖。
第31行代碼,等待占有鎖的處理器釋放自旋鎖,即鎖的locked字段變成0。
第32行代碼,成功地獲得鎖,把鎖的狀態從pending改成locked,即清除pending位,把locked字段設置為1。
從第2個等待自旋鎖的處理器開始,需要加入等待隊列,處理如下:
(1) 第37~43行代碼,從本處理器的數組mcs_nodes分配一個數組項,然后初始化。
(2) 第46~47行代碼,如果鎖處于空閑狀態,那么獲得鎖。
(3) 第49行代碼,把自旋鎖的tail字段設置為本處理器的隊列節點的信息,并且返回前一個隊列節點的信息。
(4) 第52行代碼,如果本處理器的隊列節點不是隊列首部,那么處理如下:
1)第56行代碼,把前一個隊列節點的next字段設置為本處理器的隊列節點的地址。
2)第59行代碼,本處理器在自己的隊列節點的locked字段上面自旋等待,等待locked字段從0變成1,也就是等待本處理器的隊列節點移動到隊列首部。
(5) 第67行代碼,本處理器的隊列節點移動到隊列首部以后,在鎖自身上面自旋等待,等待自旋鎖的pending位和locked字段都變成0,也就是等待鎖的狀態變成空閑。
(6) 鎖的狀態變成空閑以后,本處理器把鎖的狀態設置為locked,分兩種情況:
1)第71行代碼,如果隊列還有其他節點,即還有其他處理器在等待鎖,那么處理如下:
q第72行代碼,把鎖的locked字段設置為1。
q第83~86行代碼,等待下一個等待者設置本處理器的隊列節點的next字段。
q第88行代碼,把下一個隊列節點的locked字段設置為1。
2)第76行代碼,如果隊列只有一個節點,即本處理器是唯一的等待者,那么把鎖的tail字段設置為0,把locked字段設置為1。
(7) 第92行代碼,釋放本處理器的隊列節點。
釋放MCS自旋鎖的代碼如下所示:
spin_unlock() -》 raw_spin_unlock() -》 _raw_spin_unlock() -》 __raw_spin_unlock() -》 do_raw_spin_unlock() -》 arch_spin_unlock()
include/asm-generic/qspinlock.h
1 #define arch_spin_unlock(l) queued_spin_unlock(l)
2
3 static __always_inline void queued_spin_unlock(struct qspinlock *lock)
4 {
5 (void)atomic_sub_return_release(_Q_LOCKED_VAL, &lock-》val);
6 }
第5行代碼,執行帶釋放語義的原子減法操作,把鎖的locked字段設置為0,釋放語義保證前面的加載/存儲指令在函數atomic_sub_return_release()開始執行之前執行完。
MCS自旋鎖的配置宏是CONFIG_ARCH_USE_QUEUED_SPINLOCKS 和CONFIG_QUEUED_SPINLOCKS,目前只有x86處理器架構使用MCS自旋鎖,默認開啟MCS自旋鎖的配置宏,如下所示:
arch/x86/kconfig
config X86
def_bool y
。。.
select ARCH_USE_QUEUED_SPINLOCKS
。。.
kernel/kconfig.locks
config ARCH_USE_QUEUED_SPINLOCKS
bool
config QUEUED_SPINLOCKS
def_bool y if ARCH_USE_QUEUED_SPINLOCKS
depends on SMP


















 工商網監
工商網監
評論