 電子發燒友App
電子發燒友App


1. 前言
從我們的直觀感受來說,DMA并不是一個復雜的東西,要做的事情也很單純直白。因此Linux kernel對它的抽象和實現,也應該簡潔、易懂才是。不過現實卻不甚樂觀(個人感覺),Linux kernel dmaengine framework的實現,真有點晦澀的感覺。為什么會這樣呢?
如果一個軟件模塊比較復雜、晦澀,要么是設計者的功力不夠,要么是需求使然。當然,我們不敢對Linux kernel的那些大神們有絲毫懷疑和不敬,只能從需求上下功夫了:難道Linux kernel中的driver對DMA的使用上,有一些超出了我們日常的認知范圍?
要回答這些問題并不難,將dmaengine framework為consumers提供的功能和API梳理一遍就可以了,這就是本文的目的。當然,也可以借助這個過程,加深對DMA的理解,以便在編寫那些需要DMA傳輸的driver的時候,可以更游刃有余。
2. Slave-DMA API和Async TX API
從方向上來說,DMA傳輸可以分為4類:memory到memory、memory到device、device到memory以及device到device。Linux kernel作為CPU的代理人,從它的視角看,外設都是slave,因此稱這些有device參與的傳輸(MEM2DEV、DEV2MEM、DEV2DEV)為Slave-DMA傳輸。而另一種memory到memory的傳輸,被稱為Async TX。
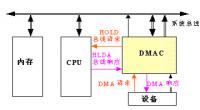
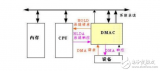
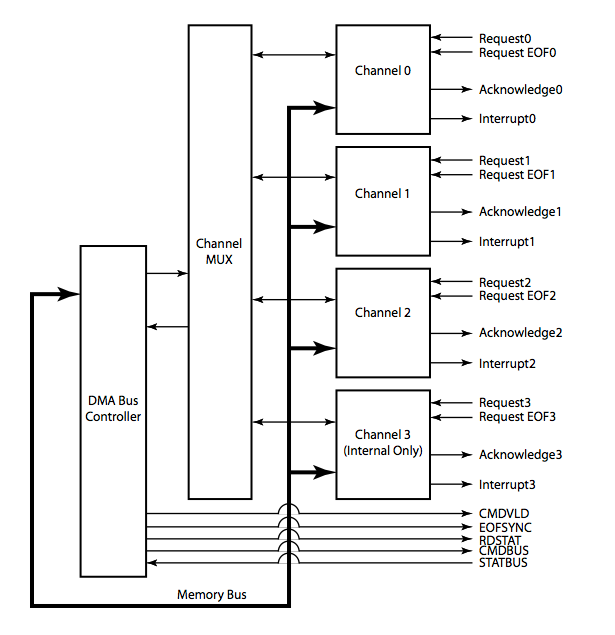
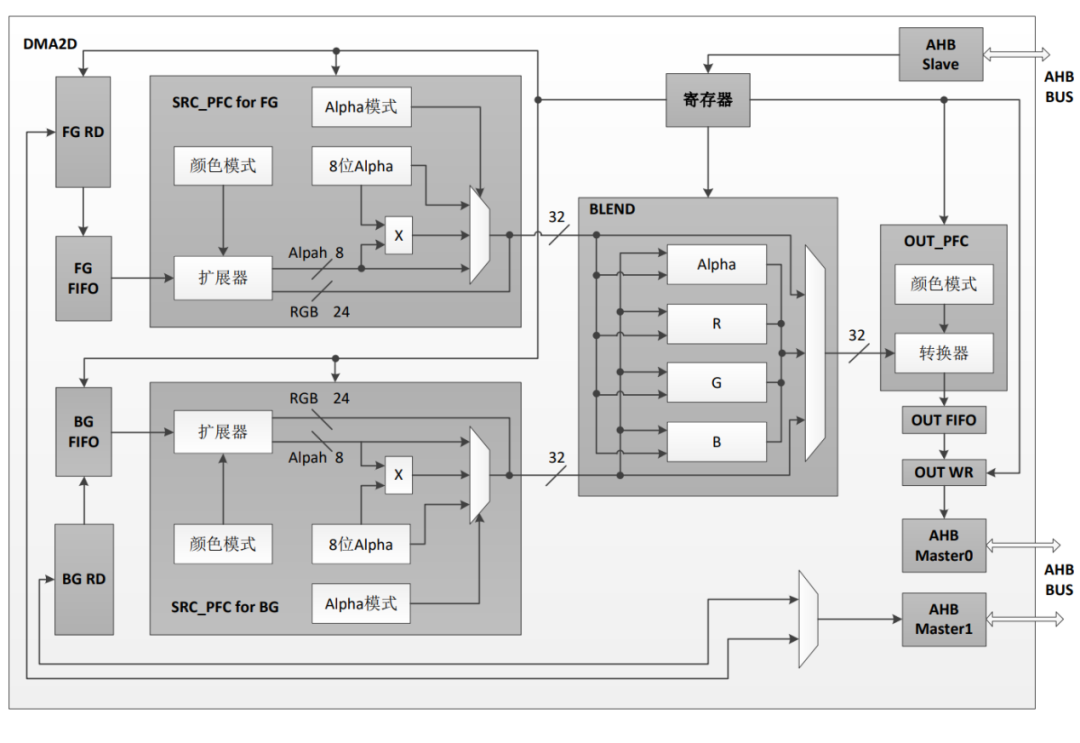
為什么強調這種差別呢?因為Linux為了方便基于DMA的memcpy、memset等操作,在dma engine之上,封裝了一層更為簡潔的API(如下面圖片1所示),這種API就是Async TX API(以async_開頭,例如async_memcpy、async_memset、async_xor等)。

圖片1 DMA Engine API示意圖
最后,因為memory到memory的DMA傳輸有了比較簡潔的API,沒必要直接使用dma engine提供的API,最后就導致dma engine所提供的API就特指為Slave-DMA API(把mem2mem剔除了)。
本文主要介紹dma engine為consumers提供的功能和API,因此就不再涉及Async TX API了(具體可參考本站后續的文章。
注1:Slave-DMA中的“slave”,指的是參與DMA傳輸的設備。而對應的,“master”就是指DMA controller自身。一定要明白“slave”的概念,才能更好的理解kernel dma engine中有關的術語和邏輯。
3. dma engine的使用步驟
注2:本文大部分內容翻譯自kernel document[1],喜歡讀英語的讀者可以自行參考。
對設備驅動的編寫者來說,要基于dma engine提供的Slave-DMA API進行DMA傳輸的話,需要如下的操作步驟:
1)申請一個DMA channel。
2)根據設備(slave)的特性,配置DMA channel的參數。
3)要進行DMA傳輸的時候,獲取一個用于識別本次傳輸(transaction)的描述符(descriptor)。
4)將本次傳輸(transaction)提交給dma engine并啟動傳輸。
5)等待傳輸(transaction)結束。
然后,重復3~5即可。
上面5個步驟,除了3有點不好理解外,其它的都比較直觀易懂,具體可參考后面的介紹。
3.1 申請DMA channel
任何consumer(文檔[1]中稱作client,也可稱作slave driver,意思都差不多,不再特意區分)在開始DMA傳輸之前,都要申請一個DMA channel(有關DMA channel的概念,請參考[2]中的介紹)。
DMA channel(在kernel中由“struct dma_chan”數據結構表示)由provider(或者是DMA controller)提供,被consumer(或者client)使用。對consumer來說,不需要關心該數據結構的具體內容(我們會在dmaengine provider的介紹中在詳細介紹)。
consumer可以通過如下的API申請DMA channel:
struct dma_chan *dma_request_chan(struct device *dev, const char *name);
該接口會返回綁定在指定設備(dev)上名稱為name的dma channel。dma engine的provider和consumer可以使用device tree、ACPI或者struct dma_slave_map類型的match table提供這種綁定關系,具體可參考XXXX章節的介紹。
最后,申請得到的dma channel可以在不需要使用的時候通過下面的API釋放掉:
void dma_release_channel(struct dma_chan *chan);
3.2 配置DMA channel的參數
driver申請到一個為自己使用的DMA channel之后,需要根據自身的實際情況,以及DMA controller的能力,對該channel進行一些配置。可配置的內容由struct dma_slave_config數據結構表示(具體可參考4.1小節的介紹)。driver將它們填充到一個struct dma_slave_config變量中后,可以調用如下API將這些信息告訴給DMA controller:
int dmaengine_slave_config(struct dma_chan *chan, struct dma_slave_config *config)
3.3 獲取傳輸描述(tx descriptor)
DMA傳輸屬于異步傳輸,在啟動傳輸之前,slave driver需要將此次傳輸的一些信息(例如src/dst的buffer、傳輸的方向等)提交給dma engine(本質上是dma controller driver),dma engine確認okay后,返回一個描述符(由struct dma_async_tx_descriptor抽象)。此后,slave driver就可以以該描述符為單位,控制并跟蹤此次傳輸。
struct dma_async_tx_descriptor數據結構可參考4.2小節的介紹。根據傳輸模式的不同,slave driver可以使用下面三個API獲取傳輸描述符(具體可參考Documentation/dmaengine/client.txt[1]中的說明):
struct dma_async_tx_descriptor *dmaengine_prep_slave_sg(
struct dma_chan *chan, struct scatterlist *sgl,
unsigned int sg_len, enum dma_data_direction direction,
unsigned long flags);
struct dma_async_tx_descriptor *dmaengine_prep_dma_cyclic(
struct dma_chan *chan, dma_addr_t buf_addr, size_t buf_len,
size_t period_len, enum dma_data_direction direction);
struct dma_async_tx_descriptor *dmaengine_prep_interleaved_dma(
struct dma_chan *chan, struct dma_interleaved_template *xt,
unsigned long flags);
dmaengine_prep_slave_sg用于在“scatter gather buffers”列表和總線設備之間進行DMA傳輸,參數如下:
注3:有關scatterlist 我們在[3][2]中有提及,后續會有專門的文章介紹它,這里暫且按下不表。
chan,本次傳輸所使用的dma channel。
sgl,要傳輸的“scatter gather buffers”數組的地址;
sg_len,“scatter gather buffers”數組的長度。
direction,數據傳輸的方向,具體可參考enum dma_data_direction (include/linux/dma-direction.h)的定義。
flags,可用于向dma controller driver傳遞一些額外的信息,包括(具體可參考enum dma_ctrl_flags中以DMA_PREP_開頭的定義):
DMA_PREP_INTERRUPT,告訴DMA controller driver,本次傳輸完成后,產生一個中斷,并調用client提供的回調函數(可在該函數返回后,通過設置struct dma_async_tx_descriptor指針中的相關字段,提供回調函數,具體可參考4.2小節的介紹);
DMA_PREP_FENCE,告訴DMA controller driver,后續的傳輸,依賴本次傳輸的結果(這樣controller driver就會小心的組織多個dma傳輸之間的順序);
DMA_PREP_PQ_DISABLE_P、DMA_PREP_PQ_DISABLE_Q、DMA_PREP_CONTINUE,PQ有關的操作,TODO。
dmaengine_prep_dma_cyclic常用于音頻等場景中,在進行一定長度的dma傳輸(buf_addr&buf_len)的過程中,每傳輸一定的byte(period_len),就會調用一次傳輸完成的回調函數,參數包括:
chan,本次傳輸所使用的dma channel。
buf_addr、buf_len,傳輸的buffer地址和長度。
period_len,每隔多久(單位為byte)調用一次回調函數。需要注意的是,buf_len應該是period_len的整數倍。
direction,數據傳輸的方向。
dmaengine_prep_interleaved_dma可進行不連續的、交叉的DMA傳輸,通常用在圖像處理、顯示等場景中,具體可參考struct dma_interleaved_template結構的定義和解釋(這里不再詳細介紹,需要用到的時候,再去學習也okay)。
3.4 啟動傳輸
通過3.3章節介紹的API獲取傳輸描述符之后,client driver可以通過dmaengine_submit接口將該描述符放到傳輸隊列上,然后調用dma_async_issue_pending接口,啟動傳輸。
dmaengine_submit的原型如下:
dma_cookie_t dmaengine_submit(struct dma_async_tx_descriptor *desc)
參數為傳輸描述符指針,返回一個唯一識別該描述符的cookie,用于后續的跟蹤、監控。
dma_async_issue_pending的原型如下:
void dma_async_issue_pending(struct dma_chan *chan);
參數為dma channel,無返回值。
注4:由上面兩個API的特征可知,kernel dma engine鼓勵client driver一次提交多個傳輸,然后由kernel(或者dma controller driver)統一完成這些傳輸。
3.5 等待傳輸結束
傳輸請求被提交之后,client driver可以通過回調函數獲取傳輸完成的消息,當然,也可以通過dma_async_is_tx_complete等API,測試傳輸是否完成。不再詳細說明了。
最后,如果等不及了,也可以使用dmaengine_pause、dmaengine_resume、dmaengine_terminate_xxx等API,暫停、終止傳輸,具體請參考kernel document[1]以及source code。
4. 重要數據結構說明
4.1 struct dma_slave_config
中包含了完成一次DMA傳輸所需要的所有可能的參數,其定義如下:
/* include/linux/dmaengine.h */
struct dma_slave_config {
enum dma_transfer_direction direction;
phys_addr_t src_addr;
phys_addr_t dst_addr;
enum dma_slave_buswidth src_addr_width;
enum dma_slave_buswidth dst_addr_width;
u32 src_maxburst;
u32 dst_maxburst;
bool device_fc;
unsigned int slave_id;
};
direction,指明傳輸的方向,包括(具體可參考enum dma_transfer_direction的定義和注釋):
DMA_MEM_TO_MEM,memory到memory的傳輸;
DMA_MEM_TO_DEV,memory到設備的傳輸;
DMA_DEV_TO_MEM,設備到memory的傳輸;
DMA_DEV_TO_DEV,設備到設備的傳輸。
注5:controller不一定支持所有的DMA傳輸方向,具體要看provider的實現。
注6:參考第2章的介紹,MEM to MEM的傳輸,一般不會直接使用dma engine提供的API。
src_addr,傳輸方向是dev2mem或者dev2dev時,讀取數據的位置(通常是固定的FIFO地址)。對mem2dev類型的channel,不需配置該參數(每次傳輸的時候會指定);
dst_addr,傳輸方向是mem2dev或者dev2dev時,寫入數據的位置(通常是固定的FIFO地址)。對dev2mem類型的channel,不需配置該參數(每次傳輸的時候會指定);
src_addr_width、dst_addr_width,src/dst地址的寬度,包括1、2、3、4、8、16、32、64(bytes)等(具體可參考enum dma_slave_buswidth 的定義)。
src_maxburst、dst_maxburst,src/dst最大可傳輸的burst size(可參考[2]中有關burst size的介紹),單位是src_addr_width/dst_addr_width(注意,不是byte)。
device_fc,當外設是Flow Controller(流控制器)的時候,需要將該字段設置為true。CPU中有關DMA和外部設備之間連接方式的設計中,決定DMA傳輸是否結束的模塊,稱作flow controller,DMA controller或者外部設備,都可以作為flow controller,具體要看外設和DMA controller的設計原理、信號連接方式等,不在詳細說明(感興趣的同學可參考[4]中的介紹)。
slave_id,外部設備通過slave_id告訴dma controller自己是誰(一般和某個request line對應)。很多dma controller并不區分slave,只要給它src、dst、len等信息,它就可以進行傳輸,因此slave_id可以忽略。而有些controller,必須清晰地知道此次傳輸的對象是哪個外設,就必須要提供slave_id了(至于怎么提供,可dma controller的硬件以及驅動有關,要具體場景具體對待)。
4.2 struct dma_async_tx_descriptor
傳輸描述符用于描述一次DMA傳輸(類似于一個文件句柄)。client driver將自己的傳輸請求通過3.3中介紹的API提交給dma controller driver后,controller driver會返回給client driver一個描述符。
client driver獲取描述符后,可以以它為單位,進行后續的操作(啟動傳輸、等待傳輸完成、等等)。也可以將自己的回調函數通過描述符提供給controller driver。
傳輸描述符的定義如下:
struct dma_async_tx_descriptor {
dma_cookie_t cookie;
enum dma_ctrl_flags flags; /* not a ‘long’ to pack with cookie */
dma_addr_t phys;
struct dma_chan *chan;
dma_cookie_t (*tx_submit)(struct dma_async_tx_descriptor *tx);
int (*desc_free)(struct dma_async_tx_descriptor *tx);
dma_async_tx_callback callback;
void *callback_param;
struct dmaengine_unmap_data *unmap;
#ifdef CONFIG_ASYNC_TX_ENABLE_CHANNEL_SWITCH
struct dma_async_tx_descriptor *next;
struct dma_async_tx_descriptor *parent;
spinlock_t lock;
#endif
};
cookie,一個整型數,用于追蹤本次傳輸。一般情況下,dma controller driver會在內部維護一個遞增的number,每當client獲取傳輸描述的時候(參考3.3中的介紹),都會將該number賦予cookie,然后加一。
注7:有關cookie的使用場景,我們會在后續的文章中再詳細介紹。
flags, DMA_CTRL_開頭的標記,包括:
DMA_CTRL_REUSE,表明這個描述符可以被重復使用,直到它被清除或者釋放;
DMA_CTRL_ACK,如果該flag為0,表明暫時不能被重復使用。
phys,該描述符的物理地址??不太懂!
chan,對應的dma channel。
tx_submit,controller driver提供的回調函數,用于把改描述符提交到待傳輸列表。通常由dma engine調用,client driver不會直接和該接口打交道。
desc_free,用于釋放該描述符的回調函數,由controller driver提供,dma engine調用,client driver不會直接和該接口打交道。
callback、callback_param,傳輸完成的回調函數(及其參數),由client driver提供。
后面其它參數,client driver不需要關心,暫不描述了。
5. 參考文檔
[1] Documentation/dmaengine/client.txt
[2] Linux DMA Engine framework(1)_概述
[3] Linux MMC framework(2)_host controller driver
[4] https://forums.xilinx.com/xlnx/attachments/xlnx/ELINUX/10658/1/drivers-session4-dma-4public.pdf













 工商網監
工商網監
評論