 電子發燒友App
電子發燒友App


一、前言
其實兩年前,本站已經有了一篇關于進程標識的文檔,不過非常的簡陋,而且代碼是來自2.6內核。隨著linux container、pid namespace等概念的引入,進程標識方面已經有了天翻地覆的變化,因此我們需要對這部分的內容進行重新整理。
本文主要分成四個部分來描述進程標識這個主題:在初步介紹了一些入門的各種IDs基礎知識后,在第三章我們描述了pid、pid number、pid namespace等基礎的概念。第四章重點描述了內核如何將這些基本概念抽象成具體的數據結構,最后我們簡單分析了內核關于進程標識的源代碼(代碼來自linux4.4.6版本)。
二、各種ID概述
所謂進程其實就是執行中的程序而已,和靜態的程序相比,進程是一個運行態的實體,擁有各種各樣的資源:地址空間(未必使用全部地址空間,而是排布在地址空間上的一段段的memory mappings)、打開的文件、pending的信號、一個或者多個thread of execution,內核中數據實體(例如一個或者多個task_struct實體),內核棧(也是一個或者多個)等。針對進程,我們使用進程ID,也就是pid(process ID)。通過getpid和getppid可以獲取當前進程的pid以及父進程的pid。
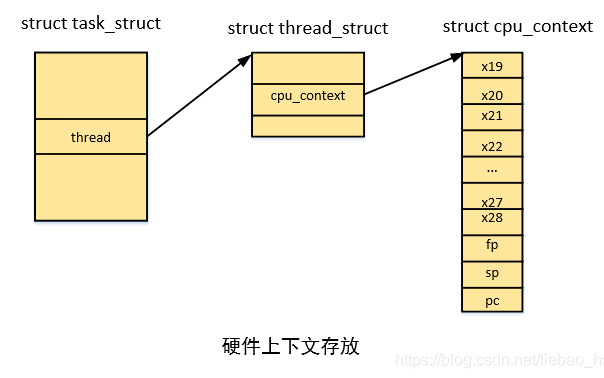
進程中的thread of execution被稱作線程(thread),線程是進程中活躍狀態的實體。一方面進程中所有的線程共享一些資源,另外一方面,線程又有自己專屬的資源,例如有自己的PC值,用戶棧、內核棧,有自己的hw context、調度策略等等。我們一般會說進程調度什么的,但是實際上線程才是是調度器的基本單位。對于Linux內核,線程的實現是一種特別的存在,和經典的unix都不一樣。在linux中并不區分進程和線程,都是用task_struct來抽象,只不過支持多線程的進程是由一組task_struct來抽象,而這些task_struct會共享一些數據結構(例如內存描述符)。我們用thread ID來唯一標識進程中的線程,POSIX規定線程ID在所屬進程中是唯一的,不過在linux kernel的實現中,thread ID是全系統唯一的,當然,考慮到可移植性,Application software不應該假設這一點。在用戶空間,通過gettid函數可以獲取當前線程的thread ID。對于單線程的進程,process ID和thread ID是一樣的,對于支持多線程的進程,每個線程有自己的thread ID,但是所有的線程共享一個PID。
為了方便shell進行Job controll,我們需要把一組進程組織起來形成進程組。關于這方面的概念,在進程和終端文檔中描述的很詳細,這里就不贅述了。為了標識進程組,我們需要引入進程組ID的概念。我們一般把進程組中的第一個進程的ID作為進程組的ID,進程組中的所有進程共享一個進程組ID。在用戶空間,通過setpgid、getpgid、setpgrp和getpgrp等接口函數可以訪問process group ID。
經過thread ID、process ID、process group ID的層層遞進,我們終于來到最頂層的ID,也就是session ID,這個ID實際上是用來標識計算機系統中的一次用戶交互過程:用戶登錄入系統,不斷的提交任務(即Job或者說是進程組)給計算機系統并觀察結果,最后退出登錄,銷毀該session。關于session的概念,在進程和終端文檔中描述的也很詳細,大家可以參考那份文檔,這里就不贅述了。在用戶空間,我們可以通過getsid、setsid來操作session ID。
三、基礎概念
1、用戶空間如何看到process ID
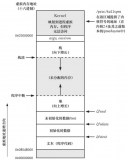
我們用下面這個block diagram來描述用戶空間和內核空間如何看待process ID的:

從用戶空間來看,每一個進程都可以調用getpid來獲取標識該進程的ID,我們稱之PID,其類型是pid_t。因此,我們知道在用戶空間可以通過一個正整數來唯一標識一個進程(我們稱這個正整數為pid number)。在引入容器之后,事情稍微復雜一點,pid這個正整數只能是唯一標識容器內的進程。也就是說,如果有容器1和容器2存在于系統中,那么可以同時存在兩個pid等于a的進程,分別位于容器1和容器2。當然,進程也可以不在容器里,例如進程x和進程y,它們就類似傳統的linux系統中的進程。當然,你也可以認為進程x和進程y位于一個系統級別的頂層容器0,其中包括進程x和進程y以及兩個容器。同樣的概念,容器2中也可以嵌套一個容器,從而形成了一個container hierarchy。
容器(linux container)是一個OS級別的虛擬化方法,基本上是屬于純軟件的方法來實現虛擬化,開銷小,量級輕,當然也有自己的局限。linux container主要應用了內核中的cgroup和namespace隔離技術,當然這些內容不是我們這份文檔關心的,我們這里主要關心pid namespace。
當一個進程運行在linux OS之上的時候,它擁有了很多的系統資源,例如pid、user ID、網絡設備、協議棧、IP以及端口號、filesystem hierarchy。對于傳統的linux,這些資源都是全局性的,一個進程umount了某一個文件系統掛載點,改變了自己的filesystem hierarchy視圖,那么所有進程看到的文件系統目錄結構都變化了(umount操作被所有進程感知到了)。有沒有可能把這些資源隔離開呢?這就是namespace的概念,而PID namespace就是用來隔離pid的地址空間的。
進程是感知不到pid namespace的,它只是知道能夠通過getpid獲取自己的ID,并不知道自己實際上被關在一個pid namespace的牢籠。從這個角度看,用戶空間是簡單而幸福的,內核空間就沒有這么幸運了,我們需要使用復雜的數據結構來抽象這些形成層次結構的PID。
最后順便說一句,上面的描述是針對pid而言的,實際上,tid、pgid和sid都是一樣的概念,原來直接使用這些ID就可以唯一標識一個實體,現在我們需要用(pid namespace,ID)來唯一標識一個實體。
2、內核空間如何看到process ID
雖然從用戶空間看,一個pid用一個正整數表示就足夠了,但是在內核空間,一個正整數肯定是不行的,我們用一個2個層次的pid namespace來描述(也就是上面圖片的情形)。pid namespace 0是pid namespace 1和2的parent namespace,在pid namespace 1中的pid等于a的那進程,對應pid namespace 0中的pid等于m的那進程,也就是說,內核態實際需要兩個不同namespace中的正整數來記錄一個進程的ID信息。推廣開來,我們可以這么描述,在一個n個level的pid namespace hieraray中,位于x level的進程需要x個正整數ID來表示該該進程。
除此之外,內核還有記錄pid namespace之間的關系:誰是根,誰是葉,父子關系……
四、內核態的數據抽象
1、如何抽象pid number?
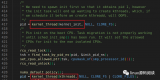
struct upid {?
??? int nr;?
??? struct pid_namespace *ns;?
??? struct hlist_node pid_chain;?
};
雖然用戶空間使用一個正整數來表示各種IDs,但是對于內核,我們需要使用(pid namespace,ID number)這樣的二元組來表示,因為單純的pid number是沒有意義的,必須限定其pid namespace,只有這樣,那個ID number才是唯一的。這樣,upid中的nr和ns成員就比較好理解了,分別對應ID number和pid namespace。此外,當userspace傳遞ID number參數進入內核請求服務的時候(例如向某一個ID發送信號),我們必須需要通過ID number快速找到其對應的upid數據對象,為了應對這樣的需求,內核將系統內所有的upid保存在哈希表中,pid_chain成員是哈希表中的next node。
2、如何抽象tid、pid、sid、pgid?
struct pid?
{?
??? atomic_t count;?
??? unsigned int level;?
??? struct hlist_head tasks[PIDTYPE_MAX];?
??? struct rcu_head rcu;?
??? struct upid numbers[1];?
};
雖然其名字是pid,不過實際上這個數據結構抽象了不僅僅是一個thread ID或者process ID,實際上還包括了進程組ID和session ID。由于多個task struct會共享pid(例如一個session中的所有的task struct都會指向同一個表示該session ID的struct pid數據對象),因此存在count這樣的成員也就不奇怪了,表示該數據對象的引用計數。
在了解了pid namespace hierarchy之后,level成員也不難理解,任何一個系統分配的PID都是隸屬于某一個namespace的,而這個namespace又是位于整個pid namespace hierarchy的某個層次上,pid->level指明了該PID所屬的namespace的level。由于pid對其parent pid namespace也是可見的,因此,這個level值其實也就表示了這個pid對象在多少個pid namespace中可見。
在多少個pid namespace中可見,就會有多少個(pid namespace,pid number)對,numbers就是這樣的一個數組,表示了在各個level上的pid number。tasks成員和使用該struct pid的task們關聯,我們在下一節描述。
3、進程描述符中如何體現tid、pid、sid、pgid?
由于多個task共享ID(泛指上面說的四種ID),因此在設計數據結構的時候我們要考慮兩種情況:
(1)從task struct快速找到對應的struct pid
(2)從struct pid能夠遍歷所有使用該pid的task
在這樣的要求下,我們設計了一個輔助數據結構:
struct pid_link?
{?
??? struct hlist_node node;?
??? struct pid *pid;?
};
其中node是將task串接到struct pid的task struct鏈表中的節點,而pid指向具體的struct pid。這時候,我們可以在task struct中嵌入一個pid_link的數組:
struct task_struct {?
……?
struct pid_link pids[PIDTYPE_MAX];?
……?
}
Task struct中的pids成員是一個數組,分別表示該task的tid(pid)、pgid和sid。我們定義pid的類型如下:
enum pid_type?
{?
??? PIDTYPE_PID,?
??? PIDTYPE_PGID,?
??? PIDTYPE_SID,?
??? PIDTYPE_MAX?
};
一直以來我們都是說四種type,tid、pid、sid、pgid,為何這里少定義一種呢?其實開始版本的內核的確是定義了四種type的pid,但是后來為了節省內存,tid和pid合二為一了。OK,現在已經引入太多的數據結構,下面我們用一幅圖片來描述數據結構之間的關系:

對于一個進程中的多個線程而言,每一個線程都可以通過task->pids[PIDTYPE_PID].pid找到該線程對應的表示thread ID的那個struct pid數據對象。當然,任何一個線程都有其所屬的進程,也就是有表示其process id的那個struct pid數據對象。如何找到它呢?這需要一個橋梁,也就是task struct中定義的thread group 成員(task->group_leader),通過該指針,一個線程總是很容易的找到其對應的線程組leader,而線程組leader對應的pid就是該線程的process ID。因此,對于一個線程,其task->group_leader->pids[PIDTYPE_PID].pid就指向了表示其process id的那個struct pid數據對象。當然,對于線程組leader,其thread ID和process ID的struct pid數據對象是一個實體,對于非線程組leader的那些普通線程,其thread ID和process ID的struct pid數據對象指向不同的實體。
struct pid有三個鏈表頭,如果該pid僅僅是標識一個thread ID,那么其pid鏈表頭指向的鏈表中只有一個元素,就是使用該pid的task struct。如果該pid表示的是一個process ID,那么pid鏈表頭指向的鏈表中多個task struct,每一個元素表示了屬于該進程的線程的task struct,鏈表中第一個task struct是thread group leader。如果該pid并不表示一個process group ID或者session ID,那么struct pid中的pgid鏈表頭和session鏈表頭都是指向null。如果該pid表示一個process group ID的時候,其結構如下圖所示:
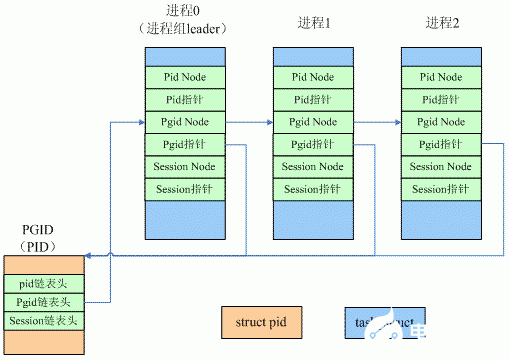
對于那些multi-thread進程,內核有若干個task struct和進程對應,不過為了簡單,在上面圖片中,進程x 對應的task struct實際上是thread group leader對應的那個task struct。這些task struct的pgid指針(task->pids[PIDTYPE_PGID].pid)指向了該進程組對應的struct pid數據對象。而該pid中的pgid鏈表頭串聯了所有使用該pid的task struct(僅僅是串聯thread group leader對應的那些task struct),而鏈表中的第一個節點就是進程組leader。
session pid的概念是類似的,大家可以自行了解學習。
4、如何抽象 pid namespace?
好吧,這個有點復雜,暫時TODO吧。
五、代碼分析
1、如何根據一個task struct得到其對應的thread ID?
static inline struct pid *task_pid(struct task_struct *task)?
{?
??? return task->pids[PIDTYPE_PID].pid;?
}
同樣的道理,我們也可以很容易得到一個task對應的pgid和sid。process ID有一點繞,我們首先要找到該task的thread group leader對應的task,其實一個線程的thread group leader對應的那個task的thread ID就是該線程的process ID。
2、如何根據一個task struct得到當前的pid namespace?
struct pid_namespace *task_active_pid_ns(struct task_struct *tsk)?
{?
??? return ns_of_pid(task_pid(tsk));?
}
這個操作可以分成兩步,第一步首先找到其對應的thread ID,然后根據thread ID找到當前的pid namespace,代碼如下:
static inline struct pid_namespace *ns_of_pid(struct pid *pid)?
{?
??? struct pid_namespace *ns = NULL;?
??? if (pid)?
??????? ns = pid->numbers[pid->level].ns;?
??? return ns;?
}
一個struct pid實體是有層次的,對應了若干層次的(pid namespace,pid number)二元組,最頂層是root pid namespace,最底層(葉節點)是當前的pid namespace,pid->level表示了當前的層次,因此pid->numbers[pid->level].ns說明的就是當前的pid namespace。
3、getpid是如何實現的?
當陷入內核后,我們很容易獲取當前的task struct(根據sp_svc的值),這是起點,后續的代碼如下:
static inline pid_t task_tgid_vnr(struct task_struct *tsk)?
{?
??? return pid_vnr(task_tgid(tsk));?
}
通過task_tgid可以獲取該task對應的thread group leader的thread ID,其實也就是process ID。此外,通過task_active_pid_ns亦可以獲取當前的pid namespace,有了這兩個參數,可以調用pid_nr_ns獲取該task對應的pid number:
pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns)?
{?
??? struct upid *upid;?
??? pid_t nr = 0;
if (pid && ns->level <= pid->level) {?
??????? upid = &pid->numbers[ns->level];?
??????? if (upid->ns == ns)?
??????????? nr = upid->nr;?
??? }?
??? return nr;?
}
一個pid可以貫穿多個pid namespace,但是并非所有的pid namespace都可以檢視pid,獲取相應的pid number。因此,在代碼的開始會進行驗證,如果pid namespace的層次(ns->level)低于pid當前的pid namespace的層次,那么直接返回0。如果pid namespace的level是OK的,那么要檢查該namespace是不是pid當前的那個pid namespace,如果是,直接返回對應的pid number,否則,返回0。
對于gettid和getppid這兩個接口,整體的概念是和getpid類似的,不再贅述。
4、給定線程ID number的情況下,如何找對應的task struct?
這里給定的條件包括ID number、當前的pid namespace,在這樣的條件下如何找到對應的task呢?我們分成兩個步驟,第一個步驟是先找到對應的struct pid,代碼如下:
struct pid *find_pid_ns(int nr, struct pid_namespace *ns)?
{?
??? struct upid *pnr;
hlist_for_each_entry_rcu(pnr,?
??????????? &pid_hash[pid_hashfn(nr, ns)], pid_chain)?
??????? if (pnr->nr == nr && pnr->ns == ns)?
??????????? return container_of(pnr, struct pid,?
??????????????????? numbers[ns->level]);
return NULL;?
}
整個系統有那么多的struct pid數據對象,每一個pid又有多個level的(pid namespace,pid number)對,通過pid number和namespace來找對應的pid是一件非常耗時的操作。此外,這樣的操作是一個比較頻繁的操作,一個簡單的例子就是通過kill向指定進程(pid number)發送信號。正是由于操作頻繁而且耗時,系統建立了一個全局的哈希鏈表來解決這個問題,pid_hash指向了若干(具體head的數量和內存配置有關)哈希鏈表頭。這個哈希表用來通過一個指定pid namespace和id number,來找到對應的struct upid。一旦找了upid,那么通過container_of找到對應的struct pid數據對象。
第二步是從struct pid找到task struct,代碼如下:
struct task_struct *pid_task(struct pid *pid, enum pid_type type)?
{?
??? struct task_struct *result = NULL;?
??? if (pid) {?
??????? struct hlist_node *first;?
??????? first = rcu_dereference_check(hlist_first_rcu(&pid->tasks[type]),?
????????????????????????? lockdep_tasklist_lock_is_held());?
??????? if (first)?
??????????? result = hlist_entry(first, struct task_struct, pids[(type)].node);?
??? }?
??? return result;?
}
5、getpgid是如何實現的?
SYSCALL_DEFINE1(getpgid, pid_t, pid)?
{?
??? struct task_struct *p;?
??? struct pid *grp;?
??? int retval;
rcu_read_lock();?
??? if (!pid)?
??????? grp = task_pgrp(current);?
??? else {?
??????? retval = -ESRCH;?
??????? p = find_task_by_vpid(pid);?
??????? if (!p)?
??????????? goto out;?
??????? grp = task_pgrp(p);?
??????? if (!grp)?
??????????? goto out;
retval = security_task_getpgid(p);?
??????? if (retval)?
??????????? goto out;?
??? }?
??? retval = pid_vnr(grp);?
out:?
??? rcu_read_unlock();?
??? return retval;?
}
當傳入的pid number等于0的時候,getpgid實際上是獲取當前進程的process groud ID number,通過task_pgrp可以獲取該進程的使用的表示progress group ID對應的那個pid對象。如果調用getpgid的時候給出了非0的process ID number,那么getpgid實際上是想要獲取指定pid number的gpid。這時候,我們需要調用find_task_by_vpid找到該pid number對應的task struct。一旦找到task struct結構,那么很容易得到其使用的pgid(該實體是struct pid類型)。至此,無論哪一種參數情況(傳入的參數pid number等于0或者非0),我們都找到了該pid number對應的struct pid數據對象(pgid)。當然,最終用戶空間需要的是pgid number,因此我們需要調用pid_vnr找到該pid在當前namespace中的pgid number。
getsid的代碼邏輯和getpid是類似的,不再贅述。


















 工商網監
工商網監
評論