 電子發(fā)燒友App
電子發(fā)燒友App


大家好,今天我們來介紹一個(gè)用于億級(jí)實(shí)時(shí)數(shù)據(jù)分析架構(gòu)Lambda架構(gòu)。
Lambda架構(gòu)
Lambda架構(gòu)(Lambda Architecture)是由Twitter工程師南森·馬茨(Nathan Marz)提出的大數(shù)據(jù)處理架構(gòu)。這一架構(gòu)的提出基于馬茨在BackType和Twitter上的分布式數(shù)據(jù)處理系統(tǒng)的經(jīng)驗(yàn)。
Lambda架構(gòu)使開發(fā)人員能夠構(gòu)建大規(guī)模分布式數(shù)據(jù)處理系統(tǒng)。它具有很好的靈活性和可擴(kuò)展性,也對(duì)硬件故障和人為失誤有很好的容錯(cuò)性。
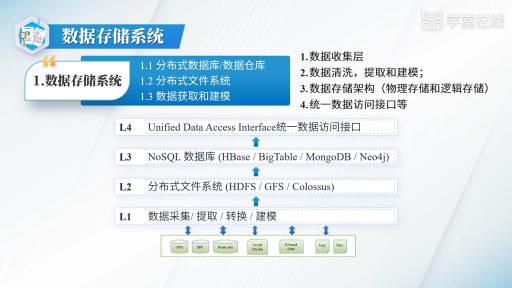
Lambda架構(gòu)總共由三層系統(tǒng)組成:批處理層 (Batch Layer), 速度處理層 (Speed Layer),以及用于響應(yīng)查詢的 服務(wù)層 (Serving Layer)。
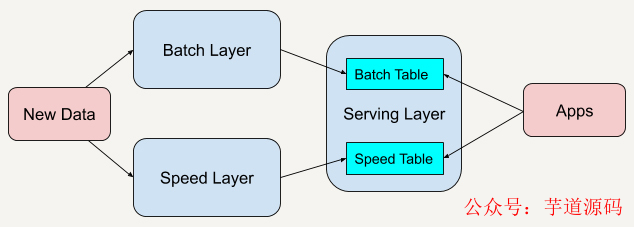
在Lambda架構(gòu)中,每層都有自己所肩負(fù)的任務(wù)。
批處理層存儲(chǔ)管理主數(shù)據(jù)集(不可變的數(shù)據(jù)集)和預(yù)先批處理計(jì)算好的視圖。
批處理層使用可處理大量數(shù)據(jù)的分布式處理系統(tǒng)預(yù)先計(jì)算結(jié)果。它通過處理所有的已有歷史數(shù)據(jù)來實(shí)現(xiàn)數(shù)據(jù)的準(zhǔn)確性。這意味著它是基于完整的數(shù)據(jù)集來重新計(jì)算的,能夠修復(fù)任何錯(cuò)誤,然后更新現(xiàn)有的數(shù)據(jù)視圖。輸出通常存儲(chǔ)在只讀數(shù)據(jù)庫中,更新則完全取代現(xiàn)有的預(yù)先計(jì)算好的視圖。
速度處理層會(huì)實(shí)時(shí)處理新來的大數(shù)據(jù)。
速度層通過提供最新數(shù)據(jù)的實(shí)時(shí)視圖來最小化延遲。速度層所生成的數(shù)據(jù)視圖可能不如批處理層最終生成的視圖那樣準(zhǔn)確或完整,但它們幾乎在收到數(shù)據(jù)后立即可用。而當(dāng)同樣的數(shù)據(jù)在批處理層處理完成后,在速度層的數(shù)據(jù)就可以被替代掉了。
本質(zhì)上,速度層彌補(bǔ)了批處理層所導(dǎo)致的數(shù)據(jù)視圖滯后。比如說,批處理層的每個(gè)任務(wù)都需要1個(gè)小時(shí)才能完成,而在這1個(gè)小時(shí)里,我們是無法獲取批處理層中最新任務(wù)給出的數(shù)據(jù)視圖的。而速度層因?yàn)槟軌驅(qū)崟r(shí)處理數(shù)據(jù)給出結(jié)果,就彌補(bǔ)了這1個(gè)小時(shí)的滯后。
所有在批處理層和速度層處理完的結(jié)果都輸出存儲(chǔ)在服務(wù)層中,服務(wù)層通過返回預(yù)先計(jì)算的數(shù)據(jù)視圖或從速度層處理構(gòu)建好數(shù)據(jù)視圖來響應(yīng)查詢。
我們舉個(gè)這樣的例子:假如用戶A的電腦暫時(shí)借給用戶B使用了一下,而用戶B瀏覽了一些新的網(wǎng)站類型(與用戶A不同)。這種情況下,我們無法判斷用戶A實(shí)際上是否對(duì)這類型的廣告感興趣,所以不能根據(jù)這些新的瀏覽記錄給用戶A推送廣告。那么我們?nèi)绾巫龅郊饶軐?shí)時(shí)分析用戶新的網(wǎng)站瀏覽行為又能兼顧到用戶的網(wǎng)站瀏覽行為歷史呢?這就可以利用Lambda架構(gòu)。
所有的新用戶行為數(shù)據(jù)都可以同時(shí)流入批處理層和速度層。批處理層會(huì)永久保存數(shù)據(jù)并且對(duì)數(shù)據(jù)進(jìn)行預(yù)處理,得到我們想要的用戶行為模型并寫入服務(wù)層。而速度層也同時(shí)對(duì)新用戶行為數(shù)據(jù)進(jìn)行處理,得到實(shí)時(shí)的用戶行為模型。
而當(dāng)“應(yīng)該對(duì)用戶投放什么樣的廣告”作為一個(gè)查詢(Query)來到時(shí),我們從服務(wù)層既查詢服務(wù)層中保存好的批處理輸出模型,也對(duì)速度層中處理的實(shí)時(shí)行為進(jìn)行查詢,這樣我們就可以得到一個(gè)完整的用戶行為歷史了。
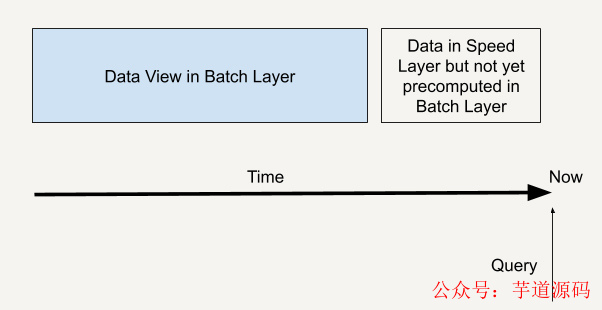
一個(gè)查詢就如下圖所示,既通過批處理層兼顧了數(shù)據(jù)的完整性,也可以通過速度層彌補(bǔ)批處理層的高延時(shí)性,讓整個(gè)查詢具有實(shí)時(shí)性。
Lambda架構(gòu)在硅谷一線大公司的應(yīng)用已經(jīng)十分廣泛,我來帶你一起看看一些實(shí)際的應(yīng)用場(chǎng)景。
Twitter的數(shù)據(jù)分析案例
Twitter在歐美十分受歡迎,而Twitter中人們所發(fā)Tweet里面的Hashtag也常常能引爆一些熱搜詞匯,也就是Most Popular Hashtags。下面我來給你講述一下如何利用Lambda架構(gòu)來實(shí)時(shí)分析這些Hashtags。
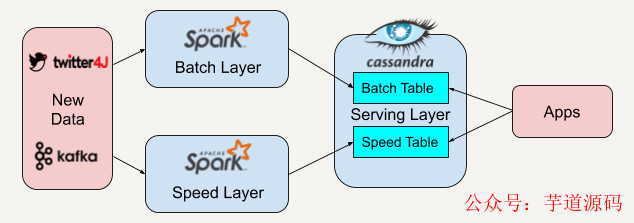
在這個(gè)實(shí)際案例里,我們先用twitter4J的流處理API抓取實(shí)時(shí)的Twitter推文,同時(shí)利用Apache Kafka將抓取到的數(shù)據(jù)保存并實(shí)時(shí)推送給批處理層和速度層。
因?yàn)锳pache Spark平臺(tái)中既有批處理架構(gòu)也兼容了流處理架構(gòu),所以我們選擇在批處理層和速度層都采用Apache Spark來讀取來自Apache Kafka的數(shù)據(jù)。
批處理層和速度層在分析處理好數(shù)據(jù)后會(huì)將數(shù)據(jù)視圖輸出存儲(chǔ)在服務(wù)層中,我們將使用Apache Cassandra平臺(tái)來存儲(chǔ)他們的數(shù)據(jù)視圖。Apache Cassandra將批處理層的視圖數(shù)據(jù)和速度層的實(shí)時(shí)視圖數(shù)據(jù)結(jié)合起來,就可以得到一系列有趣的數(shù)據(jù)。
例如,我們根據(jù)每一條Tweet中元數(shù)據(jù)(Metadata)里的location field,可以得知發(fā)推文的人的所在地。而服務(wù)層中的邏輯可以根據(jù)這個(gè)地址信息進(jìn)行分組,然后統(tǒng)計(jì)在不同地區(qū)的人所關(guān)心的Hashtag是什么。
時(shí)間長(zhǎng)達(dá)幾周或者的幾個(gè)月的數(shù)據(jù),我們可以結(jié)合批處理層和速度層的數(shù)據(jù)視圖來得出,而快至幾個(gè)小時(shí)的數(shù)據(jù)我們又可以根據(jù)速度層的數(shù)據(jù)視圖來獲知,怎么樣?這個(gè)架構(gòu)是不是十分靈活?
看到這里,你可能會(huì)問,我在上面所講的例子都是來自些科技巨頭公司,如果我在開發(fā)中面對(duì)的數(shù)據(jù)場(chǎng)景沒有這么巨大,又或者說我的公司還在創(chuàng)業(yè)起步階段,我是否可以用到Lambda架構(gòu)呢?
答案是肯定的!我們一起來看一個(gè)在硅谷舊金山創(chuàng)業(yè)公司的App后臺(tái)架構(gòu)。
Smart Parking案例分析
在硅谷地區(qū)上班生活,找停車位是一大難題。這里地少車多,每次出行,特別是周末,找停車位都要繞個(gè)好幾十分鐘才能找得到。
智能停車App就是在這樣的背景下誕生的。這個(gè)App可以根據(jù)大規(guī)模數(shù)據(jù)所構(gòu)建的視圖推薦最近的車位給用戶。
看到這里,我想先請(qǐng)你結(jié)合之前所講到的廣告精準(zhǔn)投放案例,思考一下Lambda架構(gòu)是如何應(yīng)用在這個(gè)App里的,然后再聽我娓娓道來。
好,我們來梳理一下各種可以利用到的大數(shù)據(jù)。
首先是可以拿到各類停車場(chǎng)的數(shù)據(jù)。這類數(shù)據(jù)的實(shí)時(shí)性雖然不一定高,但是數(shù)據(jù)的準(zhǔn)確性高。那我們能不能只通過這類大數(shù)據(jù)來推薦停車位呢?
我舉個(gè)極端的例子。假設(shè)在一個(gè)區(qū)域有三個(gè)停車場(chǎng),停車場(chǎng)A現(xiàn)在只剩下1個(gè)停車位了。
停車場(chǎng)B和C還有非常多的空位。而在這時(shí)候距離停車場(chǎng)比A較近的位置有10位車主在使用這個(gè)App尋求推薦停車位。如果只通過車主和停車場(chǎng)的距離和停車場(chǎng)剩余停車位來判斷的話,App很有可能會(huì)將這個(gè)只剩下一個(gè)停車位的停車場(chǎng)A同時(shí)推薦給這10位用戶。
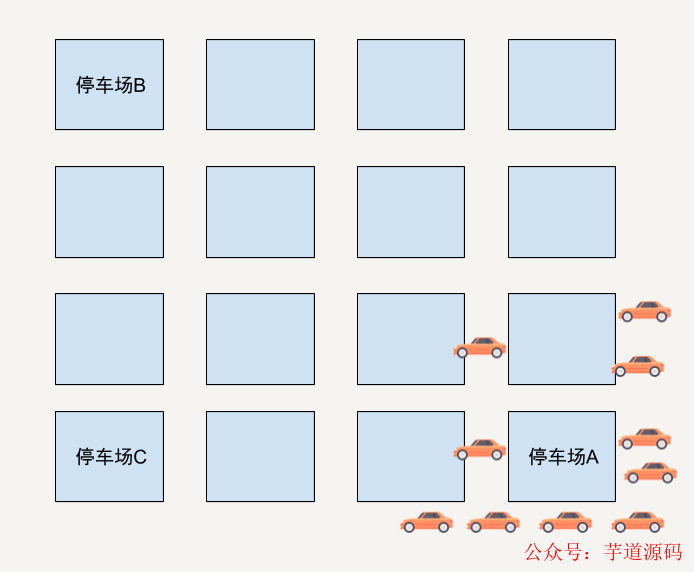
結(jié)果可想而知,只有一位幸運(yùn)兒能找到停車位,剩下的9位車主需要重新尋找停車位。
如果附近又出現(xiàn)了只有一個(gè)停車位的停車場(chǎng)呢?同理,這個(gè)App又會(huì)推薦這個(gè)停車場(chǎng)給剩下的9位用戶。這時(shí)又只能有一位幸運(yùn)兒找到停車位。
如此反復(fù)循環(huán),用戶體驗(yàn)會(huì)非常差,甚至?xí)?dǎo)致用戶放棄這個(gè)App。
那我們有沒有辦法可以改進(jìn)推薦的準(zhǔn)確度呢?
你可能會(huì)想到我們可以利用這些停車場(chǎng)的歷史數(shù)據(jù),建立一個(gè)人工智能的預(yù)測(cè)模型,在推薦停車位的時(shí)候,不單單考慮到附近停車場(chǎng)的剩余停車位和用戶與停車場(chǎng)的相鄰距離,還能將預(yù)測(cè)模型應(yīng)用在推薦里,看看未來的一段時(shí)間內(nèi)這個(gè)停車場(chǎng)是否有可能會(huì)被停滿了。
這時(shí)候我們的停車位推薦系統(tǒng)就變成了一個(gè)基于分?jǐn)?shù)(Score)來推薦停車位的系統(tǒng)了。
好了,這個(gè)時(shí)候的系統(tǒng)架構(gòu)是否已經(jīng)達(dá)到最優(yōu)了呢?你有想到應(yīng)用Lambda架構(gòu)嗎?
沒錯(cuò),這些停車場(chǎng)的歷史數(shù)據(jù)或者每隔半小時(shí)拿到的停車位數(shù)據(jù),我們可以把它作為批處理層的數(shù)據(jù)。
那速度層的數(shù)據(jù)呢?我們可以將所有用戶的GPS數(shù)據(jù)聚集起來,這些需要每秒收集的GPS數(shù)據(jù)剛好又是速度層所擅長(zhǎng)的實(shí)時(shí)流處理數(shù)據(jù)。從這些用戶的實(shí)時(shí)GPS數(shù)據(jù)中,我們可以再建立一套預(yù)測(cè)模型來預(yù)測(cè)附近停車場(chǎng)位置的擁擠程度。
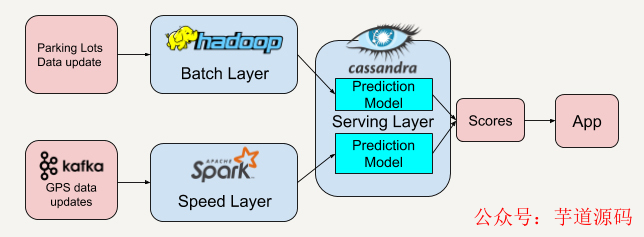
服務(wù)層將從批處理層和速度層得到的分?jǐn)?shù)結(jié)合后將得到最高分?jǐn)?shù)的停車場(chǎng)推薦給用戶。這樣利用了歷史數(shù)據(jù)(停車場(chǎng)數(shù)據(jù))和實(shí)時(shí)數(shù)據(jù)(用戶GPS數(shù)據(jù))能大大提升推薦的準(zhǔn)確率。
總結(jié)
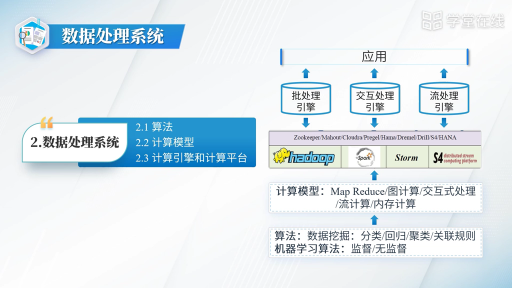
在了解Lambda架構(gòu)后,我們知道Lambda架構(gòu)具有很好的靈活性和可擴(kuò)展性。我們可以很方便地將現(xiàn)有的開源平臺(tái)套用入這個(gè)架構(gòu)中,如下圖所示。
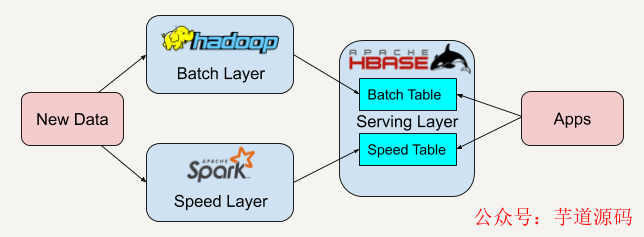
當(dāng)開發(fā)者需要遷移平臺(tái)時(shí),整體的架構(gòu)不需要改變,只需要將邏輯遷移到新平臺(tái)中。
例如,可以將Apache Spark替換成Apache Storm。而因?yàn)槲覀冇信幚韺舆@一概念,又有了很好的容錯(cuò)性。
假如某天開發(fā)者發(fā)現(xiàn)邏輯出現(xiàn)了錯(cuò)誤,只需要調(diào)整算法對(duì)永久保存好的數(shù)據(jù)重新進(jìn)行處理寫入服務(wù)層,經(jīng)過多次迭代后整體的邏輯便可以被糾正過來。現(xiàn)在有很多的開發(fā)項(xiàng)目可能已經(jīng)有了比較成熟的架構(gòu)或者算法了。
但是如果我們平時(shí)能多思考一下現(xiàn)有架構(gòu)的瓶頸,又或者想一想現(xiàn)在的架構(gòu)能不能改善得更好,有了這樣的思考,在學(xué)習(xí)到這些經(jīng)典優(yōu)秀架構(gòu)之后,說不定真的能讓現(xiàn)有的架構(gòu)變得更好。
編輯:黃飛
?













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論