 電子發燒友App
電子發燒友App


懂得“?數據結構與算法?” 寫出?高效的代碼?,懂得“?設計模式?”寫出?高質量的代碼?。
何為高質量的代碼?
下面這些詞匯是我們常用的形容好代碼的詞匯:
靈活性(flexibility)、可擴展性(extensibility)、可維護性(maintainability)、可讀性(readability)、可理解性(understandability)、易修改性(changeability)、可復用(reusability)、可測試性(testability)、模塊化(modularity)、高內聚低耦合(high cohesion loose coupling)、高效(high effciency)、高性能(high performance)、安全性(security)、兼容性(compatibility)、易用性(usability)、整潔(clean)、清晰(clarity)、簡單(simple)、直接(straightforward)、少即是多(less code is more)、文檔詳盡(well-documented)、分層清晰(well-layered)、正確性(correctness、bug free)、健壯性(robustness)、魯棒性(robustness)、可用性(reliability)、可伸縮性(scalability)、穩定性(stability)、優雅(elegant)、好(good)、
如何寫出高質量代碼?
面向對象編程因為其具有豐富的特性(封裝、抽象、繼承、多態),可以實現很多復雜的設計思路,是很多設計原則、設計模式等編碼實現的基礎。
設計原則是指導我們代碼設計的一些經驗總結,對于某些場景下,是否應該應用某種設計模式,具有指導意義。
設計模式是針對軟件開發中經常遇到的一些設計問題,總結出來的一套解決方案或者設計思路。應用設計模式的主要目的是提高代碼的可擴展性。
編程規范主要解決的是代碼的可讀性問題。
重構作為保持代碼質量不下降的有效手段。
面向對象
含義
面向對象編程的英文縮寫是 OOP,全稱是 Object Oriented Programming。對應地,面向對象編程語言的英文縮寫是 OOPL,全稱是 Object Oriented Programming Language。
面向對象編程中有兩個非常重要、非常基礎的概念,那就是類(class)和對象(object)。這兩個概念最早出現在 1960 年,在 Simula 這種編程語言中第一次使用。而面向對象編程這個概念第一次被使用是在 Smalltalk 這種編程語言中。Smalltalk 被認為是第一個真正意義上的面向對象編程語言。
Systemverilog作為面向對象的語言,相比C++, 更"像“ Java. Java語言并不直接運行在真實機器上,而是有一個虛擬機(即?Java Virtual Machine ,JVM?)來承載其運行,JVM使用C++編寫的,而C++是C的超集。
UML
UML(Unified Model Language),統一建模語言。用畫圖表達面向對象或設計模式的設計思路。對于UML的使用,純軟件人員之間仍存在一些爭議。
示例:
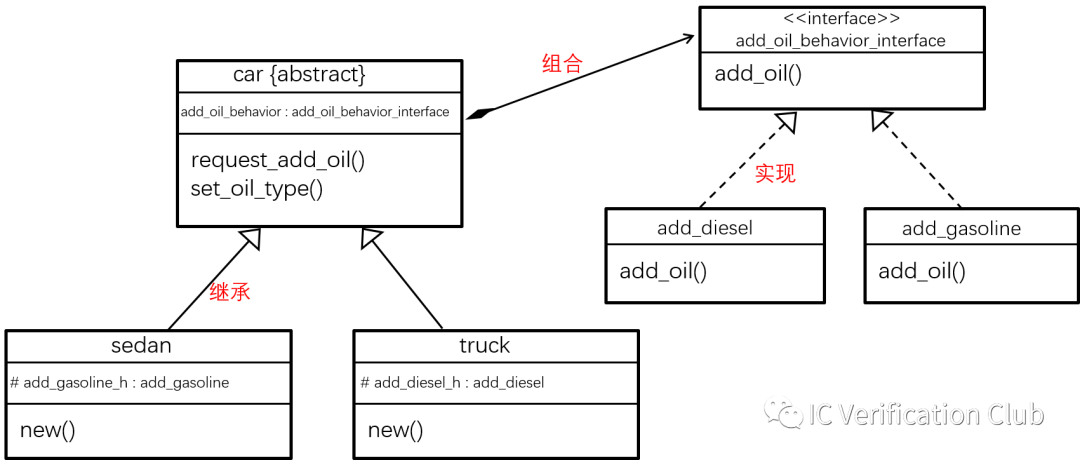
封裝(Encapsulation)
將屬性和方法封裝到到類中,但類中的屬性并不需要全部暴露出去,可以通過加上訪問權限控制這一語法機制,限制對類屬性的訪問,修改。
Java中的權限修飾符:
private?修飾的函數或者成員變量,只能在類內部使用。
protected?修飾的函數或者成員變量,可以在類及其子類內使用。
public?修飾的函數或者成員變量,可以被任意訪問。
SV中的訪問權限控制qualifiers限定符:
local?:表示的成員或方法只對該類的對象可見,子類以及類外不可見。
protected?:表示的成員或方法對該類以及子類可見,對類外不可見。
除此之外,我們還常見?const?,?static修飾變量。
const:分為兩種:全局性、instance性的 (const 在run-time階段,而 localparam需要在elaboration-time
被賦值)
全局性const:在聲明時即賦值,之后不可修改;
instace性const:只使用const進行聲明,賦值發生在new()中
const修飾的變量,不允許被修改,否則編譯器報錯。
為什么const修飾的變量不可以被修改呢??其實無論SV,C++還是C語言,各種語言的語法不同,但是最終都是通過編譯器編譯后,程序運行在系統內存里,如果const修飾的變量被編譯器分配到了一個.rodata只讀的內存段,那么就可以很好的解釋為什么不可以被修改了。同理,static對應靜態分配的地址(?存儲在全局數據區?),該段地址相對automatic屬性的地址段,不會被釋放內存,自然可以在整個仿真過程一直存在。
為了地址對齊,SV仿真器會把byte放在32bit的地址空間。
對于task/function調用,則對應?棧空間?,如果使用的是input,output類型的參數,開始調用時“input” 變量 copy到棧中,結束調用時“ouput” 變量再pop出棧。所以在task/function中修改變量,修改的結果對其他調用函數不可見。如果使用SV中的?ref?,一方面對于數據量較大的數組,不用copy到棧空間,可以獲得更佳的性能,同時修改變量的結果對外可見。
對于上述諸多的變量修飾符,從編譯存儲的角度分析,可以加深理解。C語言相對其他語言OOP語言,更接近硬件,可以通過objdump –dS a.out 反匯編查看各個變量的
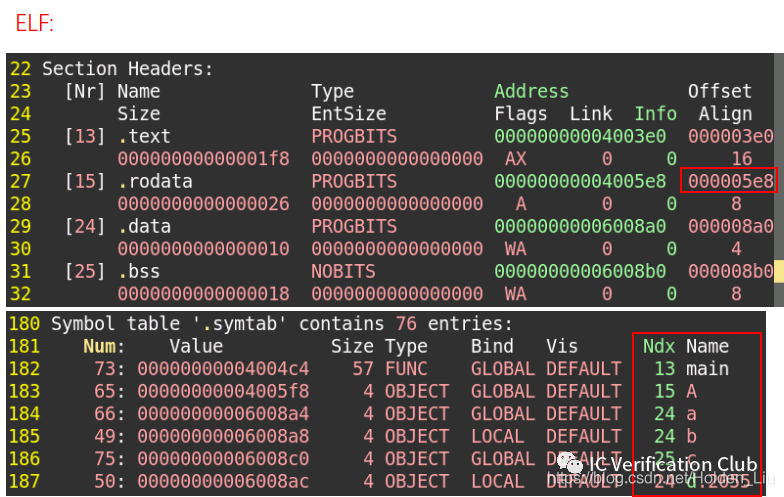
main 函數位于.text段,GLOBAL修飾屬于External Linkage
‘A’ 位于 .rodata段
‘Hello World” 也位于.rodata段 hexdump –C a.out可以查看。
程序加載運行時, .rodata段和.text段通常合并到一個Segment中,操作系統將這個Segment的頁面只讀保護起來,防止意外的改寫。
.data段中有 ‘a’, ‘b’, ‘d’ , 其中a是GLOBAL全局變量,b被static修飾,為LOCAL,不會被鏈接器處理。d被static修飾,并位于main函數中,靜態分配。
.bss段緊挨著.data段,被0填充,不占內存。所以c位于.bss段,未賦值初始化為0. .data 和.bss在加載時合并到一個Segment中,這個Segment是可讀可寫的。
‘e’ 位于函數內部,放在棧上存儲, 省略auto修飾
參考:Linux C編程一站式學習 宋勁杉 *19.3 *變量的存儲布局
抽象(Abstraction)
OOP中抽象這一特性本身就很“抽象”,如果單單從語法上看,SV在《IEEE Standard for SystemVerilog 1800-2012》才加入了像Java語言那樣支持抽象(面向接口編程)的語法。關鍵詞是 interface class, implements。
當一個class implements 一個 interface class時,必須override interface class 中的純虛(pure virtual)方法,這也很符合 implements這個單詞本身的含義。
下面看一個列子(?from?IEEE Standard for SystemVerilog 1800-2012 8.26?):

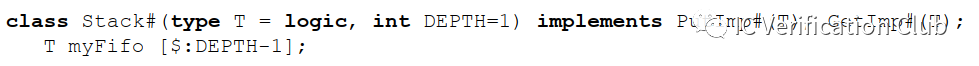

兩個interface class,PutImp, GetImp 分別包含純虛方法put, get的原型。class Fifo 和 class Stack 使用關鍵詞 implementes來實現這兩個interface class中的純虛方法。
class Fifo and class Stack share common behaviors without sharing a common implementation.
classs Fifo 和 class Stack 都有 put, get的操作,但是實現的具體方式不同(?FIFO:先進后出,Stack:先進先出?)。這就體現了“抽象”的含義,interface僅僅暴露出的是common behavirs,調用人員不需要關心具體的實現。
實際上,如果上升一個思考層面的話,抽象及其前面講到的封裝都是人類處理復雜性的有效手段。在面對復雜系統的時候,人腦能承受的信息復雜程度是有限的,所以我們必須忽略掉一些非關鍵性的實現細節。而抽象作為一種只關注功能點不關注實現的設計思路,正好幫我們的大腦過濾掉許多非必要的信息。
可能因為intreface class這一語法加入SV較晚,并且EDA工具支持有一定延遲, 在UVM源碼中,并沒有使用 interface class這一語法。但抽象僅僅是一個非常通用的設計思想, 比如一個上報錯誤的function, 命名為report_error()就比命名為report_size_mismatch_error()抽象,具體的錯誤類型,不必體現在函數命名上。(?2016 DVCon US : SystemVerilog Interface Classes - More Useful Than You Thought?涉及 interface classes 在實際項目中的使用)
在SV沒有加入接口類(intreface class)之前,也有抽象類(virtual class)可以代替抽象的特性。
抽象類不能直接例化,一個由抽象類擴展而來的類只有在所有虛方法都有實體的時候才能被例化。抽象類中可以定義非純虛方法,但是接口類不行。
接口類的一些特性,抽象類并不具備。比如一個類可以實現多個接口類,并同時繼承某一個類。比如下面這個用例。

extends 和 implements還是有本質區別的,extends繼承,是?is-a的關系,而implements更像是has-a的關系。所以SV中加入interface class,使其更接近高級語言所具備的特性。
抽象類和接口類如何選擇呢?抽象類是is-a的關系,解決代碼復用問題,接口類是has-a的關系,更側重于解耦,隔離接口和具體的實現,提高代碼的擴展性。
基于接口而非實現編程(Program to an interface, not an implementation),將接口(interface)和實現(implements)相分離,封裝不穩定的實現,暴露穩定的接口。
上游系統面向接口而非實現編程,不依賴不穩定的實現細節,這樣當實現發生變化的時候,上游系統的代碼基本上不需要做改動,以此來降低耦合性,提高擴展性。
UVM驗證平臺,已規定好了hierarchy結構和各component功能,驗證工程師只需根據實際業務“填充”具體內容,屬于硬件?驗證?,而純軟件要實現多交互的復雜業務側重?設計?,所以一般工作中沒有需求用到抽象類和接口類。對于沒有使用UVM方法學,自己寫Systemverilog搭建的驗證平臺, 接口類,抽象類,純虛方法可以建立具有統一觀感的測試平臺,這就使任何一個工程師都可以讀懂你的代碼并且快速理解其結構。
繼承(Inheritance)
繼承是用來表示類之間的 is-a 關系,比如狗是一種哺乳動物。可以通過extends 關鍵字來實現繼承(可以通過繼承+參數化的類來實現多繼承的效果,有點非常規操作,參考SystemVerilog: Reusable Class Features and Safe Initialization of Static Variables。另外interface class也可以實現多繼承),C++和Python既支持單重繼承,也支持多重繼承。
在構造用例時,一般會創建一個base_class作為父類,子類extends繼承父類的特性,使用super關鍵字指示編譯器來顯式的引用父類中定義的數據成員和方法。
SV語法規定父類的new()函數(?構造函數?),子類必須顯示調用,寫出super.new()。如果父類new()函數有參數,子類也需要傳入參數。不管子類是否重載new()函數,都要顯式調用父類的構造函數。
在實際驗證工作中,一般不會出現下述問題,基本繼承2次就足以覆蓋大部分需求了,但是純軟件編程可能會因為業務復雜,導致繼承過度,采用 *“多用組合少用繼承” *是一個規避辦法。
繼承的概念很好理解,也很容易使用。不過,過度使用繼承,繼承層次過深過復雜,就會導致代碼可讀性、可維護性變差。為了了解一個類的功能,我們不僅需要查看這個類的代碼,還需要按照繼承關系一層一層地往上查看“父類、父類的父類……”的代碼。還有,子類和父類高度耦合,修改父類的代碼,會直接影響到子類。
在SV使用中,我們也會遇到合成和繼承的選擇問題,合成使用了“有”(has-a)的關系,繼承使用了“是”(is-a)的關系。
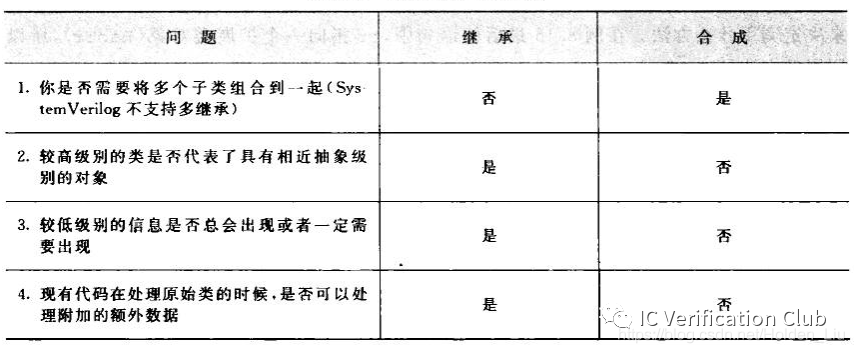
SV構建測試平臺并非標準的軟件開發項目?,除了繼承與合成之外,根據現實的場景使用,把所用變量集成在一個類中,通過條件約束達到目的。Constraint-driven?的策略更有利于我們的驗證工作。
如下示例:(?Systemverilog驗證 測試平臺編寫指南 8.4?)

多態(Polymorphism)
多態是指,子類可以替換父類,父類句柄可以指向子類的實例?。(?子類句柄不可以指向父類的實例,因為子類調用的方法,父類實例中或許并不存在?)
多態的例子這里就不再列舉了,建議學習《The UVM Primer》,這是一本很好學習OOP的書籍,足以應對工作中的絕大部分內容。
當父類句柄指向子類的實例時,通過父類句柄調用方法,如果方法使用virtual修飾,則會動態的調用子類的方法(?雖然是父類句柄,但是實例是子類,實際調用子類?override?(重寫or覆蓋)的方法?)。如果方法沒有使用virtual修飾,則是靜態的根據句柄調用方法(?動態:實例 靜態:句柄?)。
父類的task/function已經用virtual修飾,子類沒有必要在加上virtual了。
所以多態的實現要依賴虛函數virtual,總結就是“繼承加方法重寫?”。
SV語法目前還不支持overload(重載),override指的是重寫,也可以理解成覆蓋,一般不做詳細區分。
對于多態的底層實現及virtual, function override,$cast()轉化的底層原理,需要深入研究編程語言的編譯原理。檢索并沒有介紹Systemverilog的相關文章,可以通過學習C++或者Jave擴充學習,檢索內存模型或者對象模型獲取相關知識。
除了上述“繼承加方法重寫”實現多態的方法,Systemverilog也可以采用之前介紹的 interface class實現多態。還有一種是利用 duck-typing 語法,SV并不支持,動態語言Python才支持。
實例如下:
?
class Logger:
def record(self):
print(“I write a log into file.”)
class DB:
def record(self):
print(“I insert data into db. ”)
def test(recorder):
recorder.record()
def demo():
logger = Logger()
db = DB()
test(logger)
test(db)
?
設計模式之美 從這段代碼中,我們發現,duck-typing 實現多態的方式非常靈活。Logger 和 DB 兩個類沒有任何關系,既不是繼承關系,也不是接口和實現的關系,但是只要它們都有定義了 record() 方法,就可以被傳遞到 test() 方法中,在實際運行的時候,執行對應的 record() 方法。
設計原則
純軟件設計中的設計原則,對于IC的驗證和設計工作也有指導意義,我們日常工作中的一些“習慣”,可能就是在踐行某一個設計原則。依次列舉如下:
單一職責原則
一個類只負責一個功能,避免設計大而全的類,避免不相關的功能耦合,提高內聚性。也可以延申到驗證的測試用例,每個用例應該對應一個場景或者功能。
開閉原則
對擴展開放,對修改關閉。對于新加的功能,應在已有代碼基礎上擴展,而非修改已有代碼。所以在最初代碼編寫時,就應該充分考慮可擴展性,當然也不是完全杜絕修改,要把握“粗細粒度”。對于已經充分驗證的rtl模塊,側重在原來基礎上新加功能,而不是“大修”原來的模塊,容易引入bug, 相應的測試用例也可以做到最小修改。
里式替換原則
子類對象可以替換程序中出現的父類對象,并保證原來程序的邏輯行為的正確性。這一原則跟多態比較像,側重于繼承關系中子類該如何設計。
接口隔離原則
接口的調用者不應該強迫依賴ta不需要的接口。如果B模塊內包含B-1,B-2兩個模塊,A模塊的正常工作依賴于B-1模塊的初始配置,C模塊的正常工作依賴于B-2模塊的初始配置。B模塊的驗證人員可以將B模塊的初始配置流程寫到一個函數中,這個函數供A,C模塊的驗證人員調用,這個函數就像API接口一樣,調用者只負責調用,不用關心具體實現。如果B模塊的函數同時包含B-1,B-2的初始配置,A模塊的驗證人員調用,雖然不會影響功能驗證,但是B-2模塊與A模塊并無聯系,恰當的做法應該是將B-1,B-2模塊的初始配置隔離開來,供使用者按需調用。
依賴倒置原則
程序要依賴于抽象接口,不要依賴于具體實現。簡單的說就是要求對抽象進行編程,不要對實現進行編程,這樣就降低了客戶與實現模塊間的耦合。高層次的模塊不應該依賴于低層次的模塊,他們都應該依賴于抽象。和依賴接口編程的含義相近。
KISS、YANGI ,DRY原則
KISS: Keep It Stupid Simple 不要使用同事不懂的技術;不要重復造輪子,使用現有的方法;不要過度優化;
YANGI: You Ain't Gonna Need It 不要過度設計
DRT: Don't repeat yourself 減少重復的代碼。對于重復的代碼,思考是否可以通過封裝到函數中,通過傳參的方式實現。
迪米特法則
Talk only to your immediate friends and not to strangers,只與你的直接朋友交談,不跟“陌生人”說話。
如果兩個模塊實體無須直接通信,那么就不應當發生直接的相互調用,可以通過第三方轉發該調用。其目的是降低類之間的耦合度,提高模塊的相對獨立性。“高內聚,松耦合”
規范與重構
代碼風格與規范?:Easier UVM Coding Guidelines
代碼測試?:SV單元測試方法SVUnit SVUnit Download SVUnit blog
SVUnit采用了一種特別的方式來生成task。一般task負責時序相關的驅動和采樣,開發者根據設計文檔中的時序圖編寫task代碼,但是代碼的準確性有待驗證。SVUnit從另一個思路出發,直接通過時序圖,來生成對應task。這樣便保證了task中時序的準確性,畢竟時序圖要是都錯了,那只能通過review發現了。
SVUnit將時序圖轉化成task的方法,是通過編寫wavdrom可識別的?json格式?(?有固定格式,但是很容易上手,支持網頁,linux, window平臺。UserGuide?). 然后調用SVUnit中的腳本wavedromSVUnit.py解析json文件,生成時序圖對應的代碼。SVUnit對json文件做了額外描述,可以參照 test/wavedrom_0/1下面的json文件深入理解。
示例:
json描述:
?
{
"name": "read",
"signal": [
{"name": "clk", "wave": "p|...|." , "node": ".ab...d"},
{"name": "psel", "wave": "0.1...0" },
{"name": "penable", "wave": "0..1..0" },
{"name": "paddr", "wave": "x.=...x" , "data": ["addr"] },
{"name": "pready", "wave": "0....10" , "input": "True", "node": "......c"},
{"name": "prdata", "wave": "x....=x" , "output": "True", "data": ["data"] }
],
"input": [
{"name": "addr", "type": "logic [7:0]"}
],
"output": [
{"name": "data", "type": "logic [31:0]"}
],
"edge": ["a~>b 8,12", "c->d pready==1"],
config: { hscale: 3 }
}
?
waverom生成的時序圖:

自動生成的task:
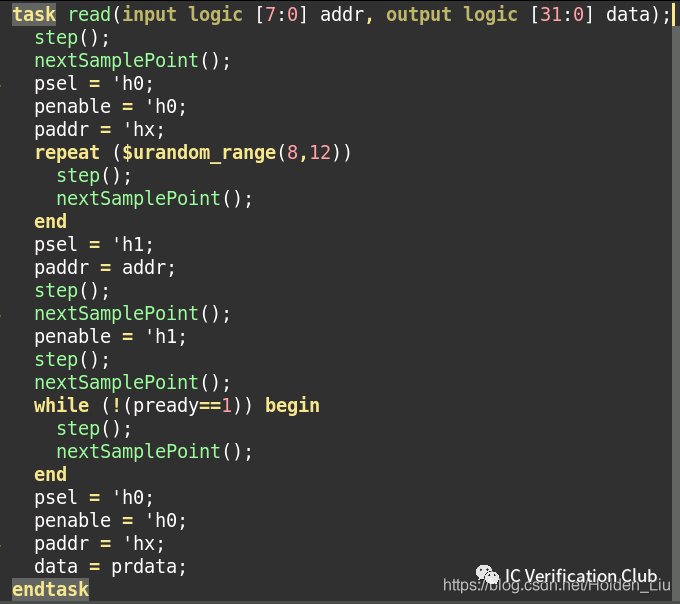
這種方式的限制就是僅適用于直接測試用例。
絕大部分驗證人員開發UVC,都是一遍debug DUT, 一遍調試驗證平臺,并不會專門使用SVUnit對UVC進行驗證。但是對于sv庫的開發,使用SVUnit是一個很好的選擇。
不過仍建議在monitor, driver開發初期,同時RTL還沒有ready的情況下,使用SVUnit將波形轉化成直接的時序激勵,做一些直接用例的測試,及早發現問題。如果設計文檔中的波形也是使用wavedrom繪制的,那么對于驗證人員的工作又省了一步,可以直接拿設計人員波形的json文件生成用例。
重構?:隨著項目的推進,迭代,原來的代碼也會慢慢變“差”,重構可能是一條"挽回“路徑。在項目初期,盡可能地劃分好驗證平臺的組件,目錄,文件調用,宏定義,腳本等,重構的同時也在引入不確定性。
審核編輯:湯梓紅


















 工商網監
工商網監
評論