 電子發燒友App
電子發燒友App


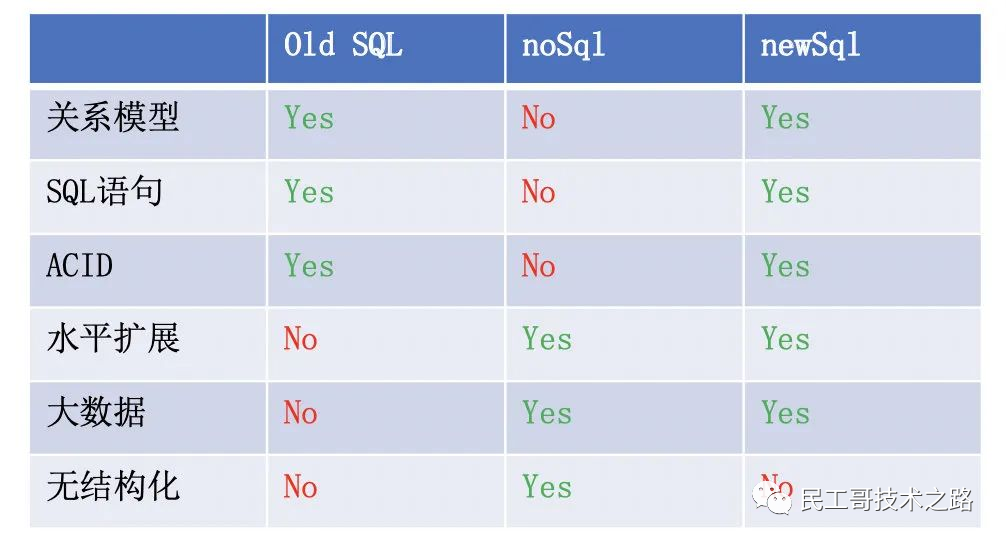
什么是NewSQL
數據庫發展至今已經有3代了:
SQL,傳統關系型數據庫,例如 MySQL
noSQL,例如 MongoDB,Redis
newSQL
傳統SQL的問題
互聯網在本世紀初開始迅速發展,互聯網應用的用戶規模、數據量都越來越大,并且要求7X24小時在線。
傳統關系型數據庫在這種環境下成為了瓶頸,通常有2種解決方法:
升級服務器硬件
雖然提升了性能,但總有天花板。
數據分片
使用分布式集群結構
對單點數據庫進行數據分片,存放到由廉價機器組成的分布式的集群里,可擴展性更好了,但也帶來了新的麻煩。
以前在一個庫里的數據,現在跨了多個庫,應用系統不能自己去多個庫中操作,需要使用數據庫分片中間件。
分片中間件做簡單的數據操作時還好,但涉及到跨庫join、跨庫事務時就很頭疼了,很多人干脆自己在業務層處理,復雜度較高。
NoSQL 的問題
后來 noSQL 出現了,放棄了傳統SQL的強事務保證和關系模型,重點放在數據庫的高可用性和可擴展性。
優點
高可用性和可擴展性,自動分區,輕松擴展
不保證強一致性,性能大幅提升
沒有關系模型的限制,極其靈活
缺點
不保證強一致性,對于普通應用沒問題,但還是有不少像金融一樣的企業級應用有強一致性的需求。
不支持 SQL 語句,兼容性是個大問題,不同的 NoSQL 數據庫都有自己的 api 操作數據,比較復雜。
NewSQL 特性
NewSQL 提供了與 noSQL 相同的可擴展性,而且仍基于關系模型,還保留了極其成熟的 SQL 作為查詢語言,保證了ACID事務特性。
簡單來講,NewSQL 就是在傳統關系型數據庫上集成了 NoSQL 強大的可擴展性。
傳統的SQL架構設計基因中是沒有分布式的,而 NewSQL 生于云時代,天生就是分布式架構。
NewSQL 的主要特性
SQL 支持,支持復雜查詢和大數據分析。
支持 ACID 事務,支持隔離級別。
彈性伸縮,擴容縮容對于業務層完全透明。
高可用,自動容災。
三種SQL的對比
什么是 TiDB
TiDB 是一個分布式 NewSQL 數據庫。它支持水平彈性擴展、ACID 事務、標準 SQL、MySQL 語法和 MySQL 協議,具有數據強一致的高可用特性,是一個不僅適合 OLTP 場景還適合 OLAP 場景的混合數據庫。
TiDB是 PingCAP公司自主設計、研發的開源分布式關系型數據庫,是一款同時支持在線事務處理與在線分析處理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式數據庫產品,具備水平擴容或者縮容、金融級高可用、實時 HTAP、云原生的分布式數據庫、兼容 MySQL 5.7 協議和 MySQL 生態等重要特性。
目標是為用戶提供一站式 OLTP (Online Transactional Processing)、OLAP (Online Analytical Processing)、HTAP 解決方案。TiDB 適合高可用、強一致要求較高、數據規模較大等各種應用場景。
TiDB分為社區版以及企業版,企業版收費提供服務以及安全性的支持。

TIDB核心特性
水平彈性擴展
通過簡單地增加新節點即可實現 TiDB 的水平擴展,按需擴展吞吐或存儲,輕松應對高并發、海量數據場景。
得益于 TiDB 存儲計算分離的架構的設計,可按需對計算、存儲分別進行在線擴容或者縮容,擴容或者縮容過程中對應用運維人員透明。
分布式事務支持
TiDB 100% 支持標準的 ACID 事務
金融級高可用
相比于傳統主從 (M-S) 復制方案,基于 Raft 的多數派選舉協議可以提供金融級的 100% 數據強一致性保證,且在不丟失大多數副本的前提下,可以實現故障的自動恢復 (auto-failover),無需人工介入
數據采用多副本存儲,數據副本通過 Multi-Raft 協議同步事務日志,多數派寫入成功事務才能提交,確保數據強一致性且少數副本發生故障時不影響數據的可用性。可按需配置副本地理位置、副本數量等策略滿足不同容災級別的要求。
實時 HTAP
TiDB 作為典型的 OLTP 行存數據庫,同時兼具強大的 OLAP 性能,配合 TiSpark,可提供一站式 HTAP 解決方案,一份存儲同時處理 OLTP & OLAP 無需傳統繁瑣的 ETL 過程。
提供行存儲引擎 TiKV、列存儲引擎 TiFlash 兩款存儲引擎,TiFlash 通過 Multi-Raft Learner 協議實時從 TiKV 復制數據,確保行存儲引擎 TiKV 和列存儲引擎 TiFlash 之間的數據強一致。TiKV、TiFlash 可按需部署在不同的機器,解決 HTAP 資源隔離的問題。
云原生的分布式數據庫
TiDB 是為云而設計的數據庫,同 Kubernetes 深度耦合,支持公有云、私有云和混合云,使部署、配置和維護變得十分簡單。TiDB 的設計目標是 100% 的 OLTP 場景和 80% 的 OLAP 場景,更復雜的 OLAP 分析可以通過 TiSpark 項目來完成。TiDB 對業務沒有任何侵入性,能優雅的替換傳統的數據庫中間件、數據庫分庫分表等 Sharding 方案。同時它也讓開發運維人員不用關注數據庫 Scale 的細節問題,專注于業務開發,極大的提升研發的生產力。
高度兼容 MySQL
兼容 MySQL 5.7 協議、MySQL 常用的功能、MySQL 生態,應用無需或者修改少量代碼即可從 MySQL 遷移到 TiDB。
提供豐富的數據遷移工具幫助應用便捷完成數據遷移,大多數情況下,無需修改代碼即可從 MySQL 輕松遷移至 TiDB,分庫分表后的 MySQL 集群亦可通過 TiDB 工具進行實時遷移。
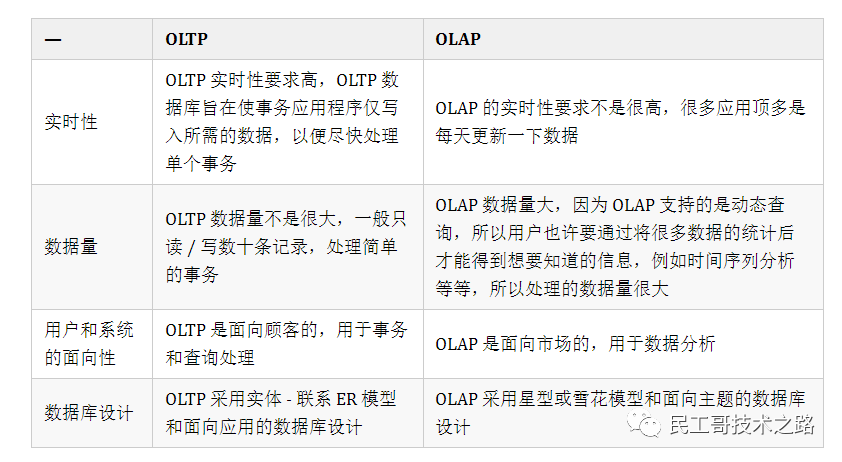
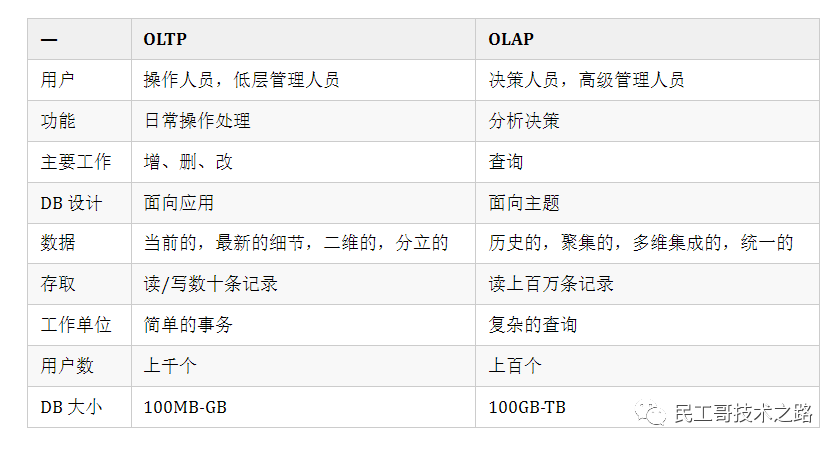
OLTP&OLAP
OLTP(聯機事務處理)
OLTP(Online Transactional Processing) 即聯機事務處理,OLTP 是傳統的關系型數據庫的主要應用,主要是基本的、日常的事務處理,記錄即時的增、刪、改、查,比如在銀行存取一筆款,就是一個事務交易。
聯機事務處理是事務性非常高的系統,一般都是高可用的在線系統,以小的事務以及小的查詢為主,評估其系統的時候,一般看其每秒執行的Transaction以及Execute SQL的數量。在這樣的系統中,單個數據庫每秒處理的Transaction往往超過幾百個,或者是幾千個,Select 語句的執行量每秒幾千甚至幾萬個。典型的OLTP系統有電子商務系統、銀行、證券等,如美國eBay的業務數據庫,就是很典型的OLTP數據庫。
OLAP(聯機分析處理)
OLAP(Online Analytical Processing) 即聯機分析處理,是數據倉庫的核心部心,支持復雜的分析操作,側重決策支持,并且提供直觀易懂的查詢結果。典型的應用就是復雜的動態報表系統。
在這樣的系統中,語句的執行量不是考核標準,因為一條語句的執行時間可能會非常長,讀取的數據也非常多。所以,在這樣的系統中,考核的標準往往是磁盤子系統的吞吐量(帶寬),如能達到多少MB/s的流量。
特性對比
OLTP和OLAP的特性對比
設計角度區別
TiDB 整體架構
TiDB的優勢
與傳統的單機數據庫相比,TiDB 具有以下優勢:
純分布式架構,擁有良好的擴展性,支持彈性的擴縮容。
支持 SQL,對外暴露 MySQL 的網絡協議,并兼容大多數 MySQL 的語法,在大多數場景下可以直接替換 MySQL。
默認支持高可用,在少數副本失效的情況下,數據庫本身能夠自動進行數據修復和故障轉移,對業務透明。
支持 ACID 事務,對于一些有強一致需求的場景友好,例如:銀行轉賬。
具有豐富的工具鏈生態,覆蓋數據遷移、同步、備份等多種場景。
TiDB的組件
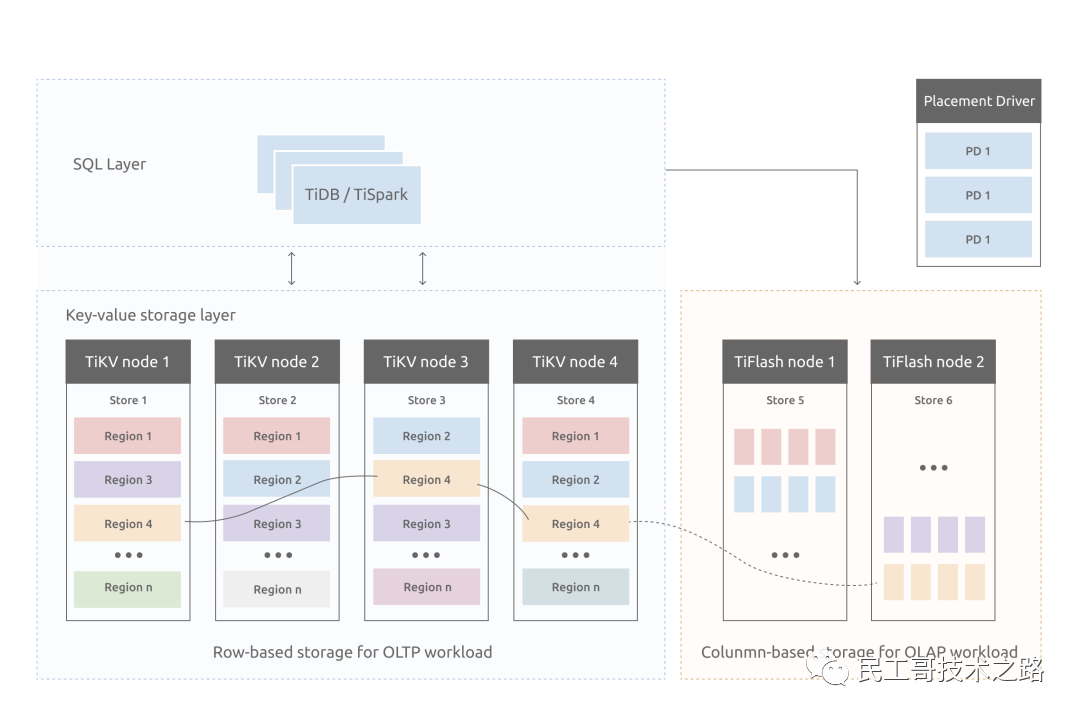
要深入了解 TiDB 的水平擴展和高可用特點,首先需要了解 TiDB 的整體架構。TiDB 集群主要包括三個核心組件:TiDB Server,PD Server 和 TiKV Server,此外,還有用于解決用戶復雜 OLAP 需求的 TiSpark 組件。
在內核設計上,TiDB 分布式數據庫將整體架構拆分成了多個模塊,各模塊之間互相通信,組成完整的 TiDB 系統。對應的架構圖如下:
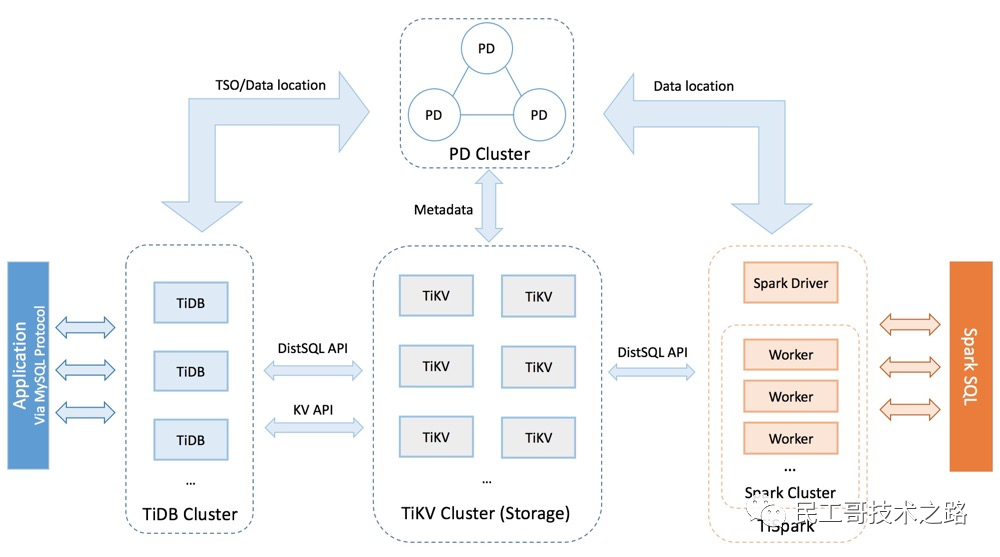
TiDB Server
TiDB Server 負責接收 SQL 請求,處理 SQL 相關的邏輯,并通過 PD 找到存儲計算所需數據的 TiKV 地址,與 TiKV 交互獲取數據,最終返回結果。TiDB Server 是無狀態的,其本身并不存儲數據,只負責計算,可以無限水平擴展,可以通過負載均衡組件(如 LVS、HAProxy 或 F5)對外提供統一的接入地址。
PD (Placement Driver) Server
Placement Driver (簡稱 PD) 是整個集群的管理模塊,其主要工作有三個:
一是存儲集群的元信息(某個 Key 存儲在哪個 TiKV 節點);
二是對 TiKV 集群進行調度和負載均衡(如數據的遷移、Raft group leader 的遷移等);
三是分配全局唯一且遞增的事務 ID。
PD 通過 Raft 協議保證數據的安全性。Raft 的 leader server 負責處理所有操作,其余的 PD server 僅用于保證高可用。建議部署奇數個 PD 節點
TiKV Server
TiKV Server 負責存儲數據,從外部看 TiKV 是一個分布式的提供事務的 Key-Value 存儲引擎。存儲數據的基本單位是 Region,每個 Region 負責存儲一個 Key Range(從 StartKey 到 EndKey 的左閉右開區間)的數據,每個 TiKV 節點會負責多個 Region。TiKV 使用 Raft 協議做復制,保持數據的一致性和容災。副本以 Region 為單位進行管理,不同節點上的多個 Region 構成一個 Raft Group,互為副本。數據在多個 TiKV 之間的負載均衡由 PD 調度,這里也是以 Region 為單位進行調度。
TiSpark
TiSpark 作為 TiDB 中解決用戶復雜 OLAP 需求的主要組件,將 Spark SQL 直接運行在 TiDB 存儲層上,同時融合 TiKV 分布式集群的優勢,并融入大數據社區生態。至此,TiDB 可以通過一套系統,同時支持 OLTP 與 OLAP,免除用戶數據同步的煩惱。
TiFlash
TiFlash 是一類特殊的存儲節點。和普通 TiKV 節點不一樣的是,在 TiFlash 內部,數據是以列式的形式進行存儲,主要的功能是為分析型的場景加速。
TiKV整體架構
與傳統的整節點備份方式不同的,TiKV是將數據按照 key 的范圍劃分成大致相等的切片(下文統稱為 Region),每一個切片會有多個副本(通常是 3 個),其中一個副本是 Leader,提供讀寫服務。TiKV 通過 PD 對這些 Region 以及副本進行調度,以保證數據和讀寫負載都均勻地分散在各個 TiKV 上,這樣的設計保證了整個集群資源的充分利用并且可以隨著機器數量的增加水平擴展。
Region分裂與合并
當某個 Region 的大小超過一定限制(默認是 144MB)后,TiKV 會將它分裂為兩個或者更多個 Region,以保證各個 Region 的大小是大致接近的,這樣更有利于 PD 進行調度決策。同樣,當某個 Region 因為大量的刪除請求導致 Region 的大小變得更小時,TiKV 會將比較小的兩個相鄰 Region 合并為一個。
Region調度
Region 與副本之間通過 Raft 協議來維持數據一致性,任何寫請求都只能在 Leader 上寫入,并且需要寫入多數副本后(默認配置為 3 副本,即所有請求必須至少寫入兩個副本成功)才會返回客戶端寫入成功。
當 PD 需要把某個 Region 的一個副本從一個 TiKV 節點調度到另一個上面時,PD 會先為這個 Raft Group 在目標節點上增加一個 Learner 副本(復制 Leader 的數據)。當這個 Learner 副本的進度大致追上 Leader 副本時,Leader 會將它變更為 Follower,之后再移除操作節點的 Follower 副本,這樣就完成了 Region 副本的一次調度。
Leader 副本的調度原理也類似,不過需要在目標節點的 Learner 副本變為 Follower 副本后,再執行一次 Leader Transfer,讓該 Follower 主動發起一次選舉成為新 Leader,之后新 Leader 負責刪除舊 Leader 這個副本。
分布式事務
TiKV 支持分布式事務,用戶(或者 TiDB)可以一次性寫入多個 key-value 而不必關心這些 key-value 是否處于同一個數據切片 (Region) 上,TiKV 通過兩階段提交保證了這些讀寫請求的 ACID 約束。
高可用架構
高可用是 TiDB 的另一大特點,TiDB/TiKV/PD 這三個組件都能容忍部分實例失效,不影響整個集群的可用性。下面分別說明這三個組件的可用性、單個實例失效后的后果以及如何恢復。
TiDB高可用
TiDB 是無狀態的,推薦至少部署兩個實例,前端通過負載均衡組件對外提供服務。當單個實例失效時,會影響正在這個實例上進行的 Session,從應用的角度看,會出現單次請求失敗的情況,重新連接后即可繼續獲得服務。單個實例失效后,可以重啟這個實例或者部署一個新的實例。
PD高可用
PD 是一個集群,通過 Raft 協議保持數據的一致性,單個實例失效時,如果這個實例不是 Raft 的 leader,那么服務完全不受影響;如果這個實例是 Raft 的 leader,會重新選出新的 Raft leader,自動恢復服務。PD 在選舉的過程中無法對外提供服務,這個時間大約是3秒鐘。推薦至少部署三個 PD 實例,單個實例失效后,重啟這個實例或者添加新的實例。
TiKV高可用
TiKV 是一個集群,通過 Raft 協議保持數據的一致性(副本數量可配置,默認保存三副本),并通過 PD 做負載均衡調度。單個節點失效時,會影響這個節點上存儲的所有 Region。對于 Region 中的 Leader 結點,會中斷服務,等待重新選舉;對于 Region 中的 Follower 節點,不會影響服務。當某個 TiKV 節點失效,并且在一段時間內(默認 10 分鐘)無法恢復,PD 會將其上的數據遷移到其他的 TiKV 節點上。
應用場景
MySQL分片與合并
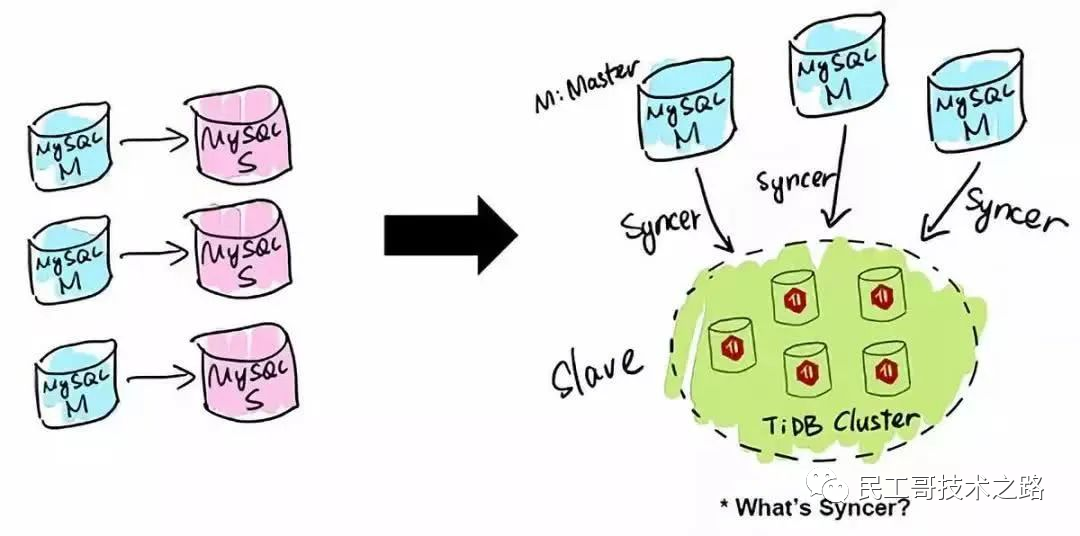
TiDB 應用的第一類場景是 MySQL 的分片與合并。對于已經在用 MySQL 的業務,分庫、分表、分片、中間件是常用手段,隨著分片的增多,跨分片查詢是一大難題。TiDB 在業務層兼容 MySQL 的訪問協議,PingCAP 做了一個數據同步的工具——Syncer,它可以把 TiDB 作為一個 MySQL Slave,將 TiDB 作為現有數據庫的從庫接在主 MySQL 庫的后方,在這一層將數據打通,可以直接進行復雜的跨庫、跨表、跨業務的實時 SQL 查詢。黃東旭提到,“過去的數據庫都是一主多從,有了 TiDB 以后,可以反過來做到多主一從。”
直接替換MySQL
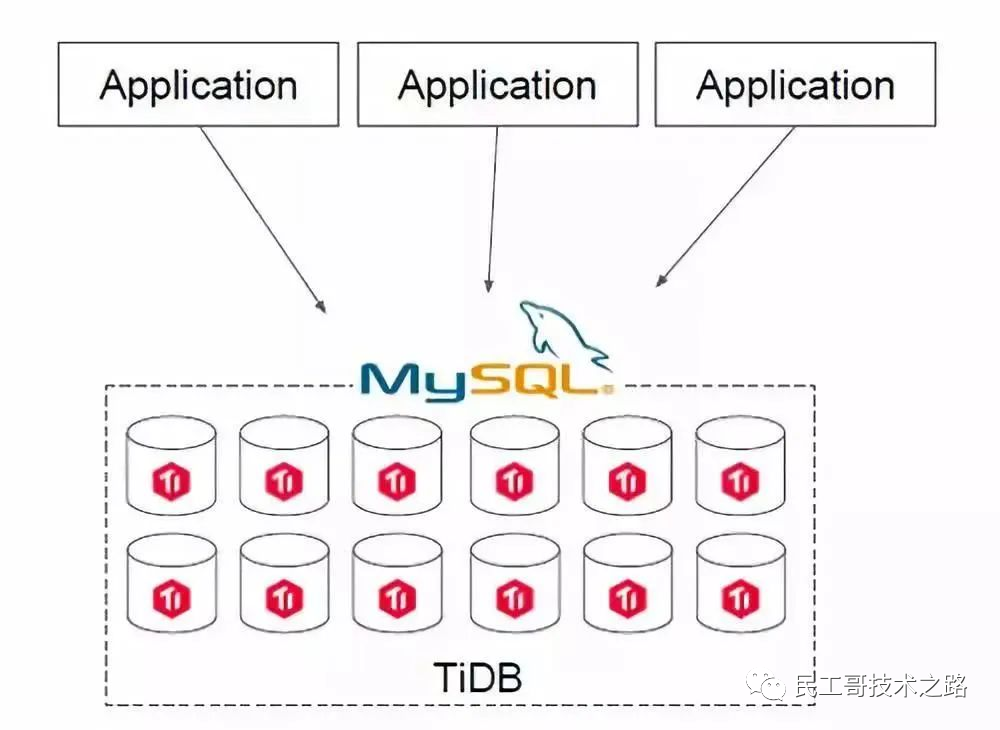
第二類場景是用 TiDB 直接去替換 MySQL。如果你的IT架構在搭建之初并未考慮分庫分表的問題,全部用了 MySQL,隨著業務的快速增長,海量高并發的 OLTP 場景越來越多,如何解決架構上的弊端呢?
在一個 TiDB 的數據庫上,所有業務場景不需要做分庫分表,所有的分布式工作都由數據庫層完成。TiDB 兼容 MySQL 協議,所以可以直接替換 MySQL,而且基本做到了開箱即用,完全不用擔心傳統分庫分表方案帶來繁重的工作負擔和復雜的維護成本,友好的用戶界面讓常規的技術人員可以高效地進行維護和管理。另外,TiDB 具有 NoSQL 類似的擴容能力,在數據量和訪問流量持續增長的情況下能夠通過水平擴容提高系統的業務支撐能力,并且響應延遲穩定。
數據倉庫
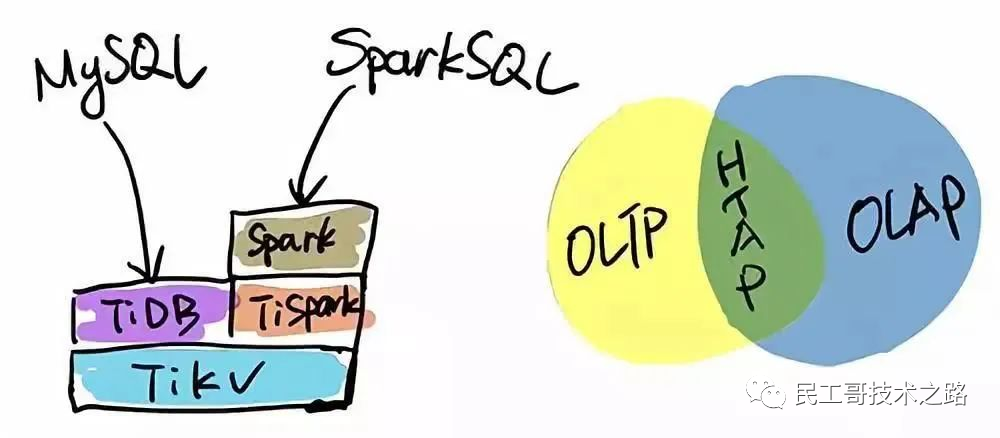
TiDB 本身是一個分布式系統,第三種使用場景是將 TiDB 當作數據倉庫使用。TPC-H 是數據分析領域的一個測試集,TiDB 2.0 在 OLAP 場景下的性能有了大幅提升,原來只能在數據倉庫里面跑的一些復雜的 Query,在 TiDB 2.0 里面跑,時間基本都能控制在 10 秒以內。當然,因為 OLAP 的范疇非常大,TiDB 的 SQL 也有搞不定的情況,為此 PingCAP 開源了 TiSpark,TiSpark 是一個 Spark 插件,用戶可以直接用 Spark SQL 實時地在 TiKV 上做大數據分析。
作為其他系統的模塊
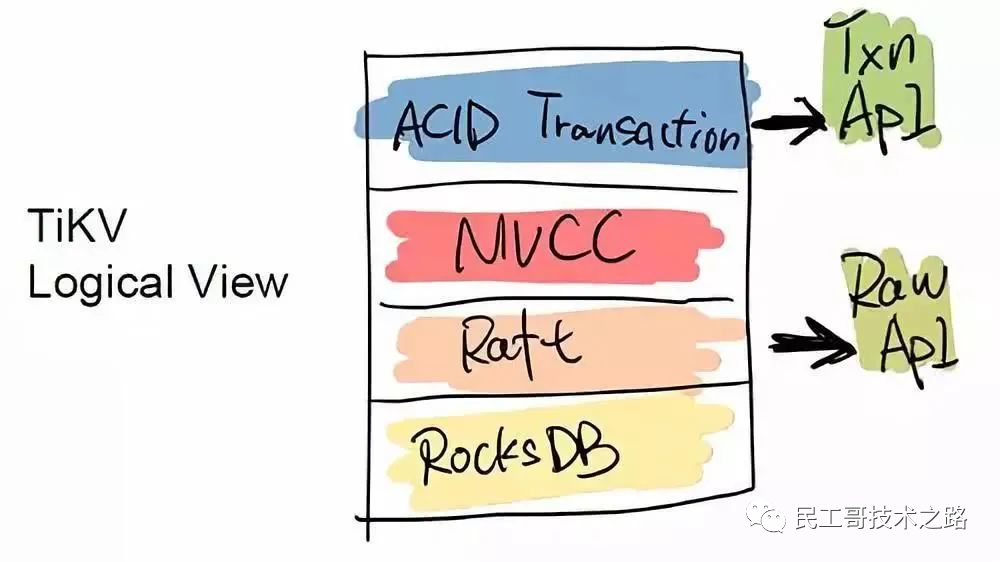
TiDB 是一個傳統的存儲跟計算分離的項目,其底層的 Key-Value 層,可以單獨作為一個 HBase 的 Replacement 來用,它同時支持跨行事務。TiDB 對外提供兩個 API 接口,一個是 ACID Transaction 的 API,用于支持跨行事務;另一個是 Raw API,它可以做單行的事務,換來的是整個性能的提升,但不提供跨行事務的 ACID 支持。用戶可以根據自身的需求在兩個 API 之間自行選擇。例如有一些用戶直接在 TiKV 之上實現了 Redis 協議,將 TiKV 替換一些大容量,對延遲要求不高的 Redis 場景。
TiDB與MySQL兼容性對比
TiDB支持MySQL?傳輸協議及其絕大多數的語法。這意味著您現有的MySQL連接器和客戶端都可以繼續使用。大多數情況下您現有的應用都可以遷移至 TiDB,無需任何代碼修改。
當前TiDB服務器官方支持的版本為MySQL 5.7?。大部分MySQL運維工具(如PHPMyAdmin, Navicat, MySQL Workbench等),以及備份恢復工具(如 mysqldump, Mydumper/myloader)等都可以直接使用。
不過一些特性由于在分布式環境下沒法很好的實現,目前暫時不支持或者是表現與MySQL有差異
一些MySQL語法在TiDB中可以解析通過,但是不會做任何后續的處理?,例如Create Table語句中Engine,是解析并忽略。
TiDB不支持的MySql特性
存儲過程與函數
觸發器
事件
自定義函數
外鍵約束
臨時表
全文/空間函數與索引
非?ascii/latin1/binary/utf8/utf8mb4?的字符集
SYS schema
MySQL 追蹤優化器
XML 函數
X-Protocol
Savepoints
列級權限
XA?語法(TiDB 內部使用兩階段提交,但并沒有通過 SQL 接口公開)
CREATE TABLE tblName AS SELECT stmt?語法
CHECK TABLE?語法
CHECKSUM TABLE?語法
GET_LOCK?和?RELEASE_LOCK?函數
自增ID
TiDB 的自增列僅保證唯一,也能保證在單個 TiDB server 中自增,但不保證多個 TiDB server 中自增,不保證自動分配的值的連續性,建議不要將缺省值和自定義值混用,若混用可能會收?Duplicated Error的錯誤信息。
TiDB 可通過?tidb_allow_remove_auto_inc?系統變量開啟或者關閉允許移除列的?AUTO_INCREMENT?屬性。刪除列屬性的語法是:alter table modify?或?alter table change。
TiDB 不支持添加列的AUTO_INCREMENT屬性,移除該屬性后不可恢復。
SELECT 的限制
不支持?SELECT ... INTO @變量?語法。
不支持?SELECT ... GROUP BY ... WITH ROLLUP?語法。
TiDB 中的?SELECT .. GROUP BY expr?的返回結果與 MySQL 5.7 并不一致。MySQL 5.7 的結果等價于?GROUP BY expr ORDER BY expr。而 TiDB 中該語法所返回的結果并不承諾任何順序,與 MySQL 8.0 的行為一致。
視圖
目前TiDB不支持?對視圖進行UPDATE、INSERT、DELETE等寫入操作?。
默認設置差異
字符集
TiDB 默認:utf8mb4。
MySQL 5.7 默認:latin1。
MySQL 8.0 默認:utf8mb4。
排序規則
TiDB 中?utf8mb4?字符集默認:utf8mb4_bin。
MySQL 5.7 中?utf8mb4?字符集默認:utf8mb4_general_ci?。
MySQL 8.0 中?utf8mb4?字符集默認:utf8mb4_0900_ai_ci。
大小寫敏感
關于lower_case_table_names的配置
TiDB 默認:2,且僅支持設置該值為?2。
MySQL 默認如下:
Linux 系統中該值為?0
Windows 系統中該值為?1
macOS 系統中該值為?2
參數解釋
lower_case_table_names=0 表名存儲為給定的大小和比較是區分大小寫的。
lower_case_table_names = 1 表名存儲在磁盤是小寫的,但是比較的時候是不區分大小寫。
lower_case_table_names=2 表名存儲為給定的大小寫但是比較的時候是小寫的。
timestamp類型字段更新
默認情況下,timestamp類型字段所在數據行被更新時,該字段會自動更新為當前時間,而參數explicit_defaults_for_timestamp控制這一種行為。
TiDB 默認:ON,且僅支持設置該值為?ON。
MySQL 5.7 默認:OFF。
MySQL 8.0 默認:ON。
參數解釋
explicit_defaults_for_timestamp=off,數據行更新時,timestamp類型字段更新為當前時間
explicit_defaults_for_timestamp=on,數據行更新時,timestamp類型字段不更新為當前時間。
外鍵支持
TiDB 默認:OFF,且僅支持設置該值為?OFF。
MySQL 5.7 默認:ON。
編輯:黃飛
?









 工商網監
工商網監
評論