 電子發燒友App
電子發燒友App


1. 墊話
本文乃《Illustrated Guide to Monitoring and Tuning the Linux Networking Stack: Receiving Data》一文的翻譯,是系列文章的第二篇。
2. 前言
本文為《[譯 1] linux 網絡棧監控及調優:數據接收》一文添加圖解,旨在幫助讀者更清晰地了解 linux 網絡棧。 在 linux 網絡棧的監控及調優上沒有捷徑可言,如果你想做有效的調優,就必須搞清楚各個系統之間是怎么交互的。上一篇文章因為篇幅的緣故,可能會讓讀者難以從大圖上了解各系統之間是怎么拉通的,希望本文可以。
3. 開始
本文的圖解旨在描繪 linux 網絡棧工作原理的大圖,會忽略大量細節。如果想要全面了解,還是推薦閱讀上一篇文章,其中包含了網絡棧的各方面細節。本文的圖解,旨在幫助讀者建立起 high level 的內核子系統交互的思維模型。 咱們從初始化工作開始,這是理解 packet 處理的必要前提。
4. 初始化
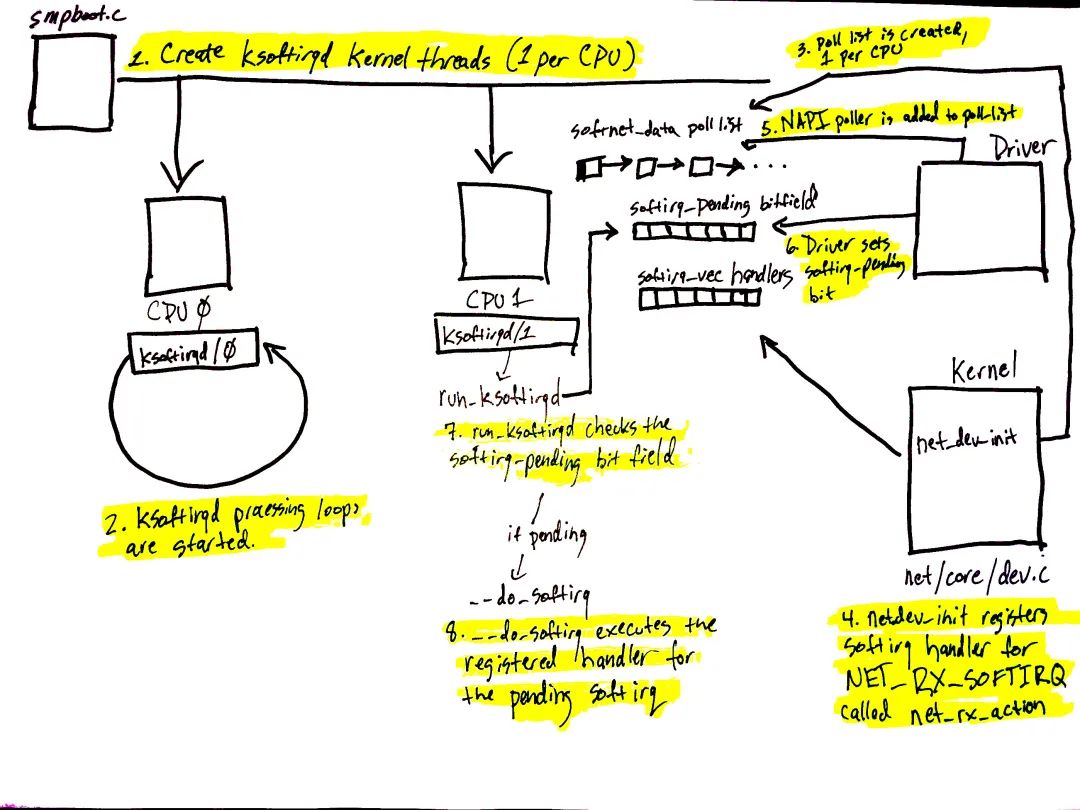
圖 1 網絡設備在 packet 到達并需要處理時,通常會觸發一個 IRQ。IRQ 處理函數是在很高的優先級下執行的,一般會阻塞其他 IRQs 的觸發(譯者注:often blocks additional IRQs from being generated。個人覺得原文這里并不準確,中斷上下文中關中往往只是讓 CPU 不響應中斷,而不是讓其他設備直接不發出中斷)。故而,設備驅動中的 IRQ 處理函數必須越快越好,并將比較耗時的工作挪到中斷上下文之外去執行,這就是為啥會有軟中斷系統。 linux 內核軟中斷系統支持在設備驅動的中斷上下文之外處理工作。網絡設備場景下,軟中斷系統用作處理 incoming packets。內核在 boot 階段做軟中斷系統的初始化。 圖 1 對應前文“軟中斷”一節,展示的是軟中斷系統及其 per-CPU 內核線程的初始化。 軟中斷系統的初始化流程如下:
spawn_ksoftirqd(kernel/softirq.c)調用 smpboot_register_percpu_thread(kernel/smpboot.c)創建軟中斷內核線程(每個 CPU 一個)。如代碼所示,run_ksoftirqd 作為 smp_hotplug_thread 的 thread_fn,會在一個 loop 中被執行。
ksoftirqd 線程會在 run_ksoftirqd 中運行其 processing loop。
隨后,創建 softnet_data 數據結構(前文“struct softnet_data 數據結構初始化”一節),每個 CPU 一個。此數據結構包含在網絡數據處理時所需要的重要信息。另外還有一個 poll_list,下文會說。設備驅動調用 napi_schedule 或其他 NAPI APIs,將 NAPI poll 數據結構添加至 poll_list 上。
net_dev_init 調用 open_softirq 向軟中斷系統注冊 NET_RX_SOFTIRQ 軟中斷,被注冊的軟中斷處理函數是 net_rx_action(前文“軟中斷處理函數初始化”一節)。軟中斷內核線程會調用此函數來處理 packets。
圖 1 中的第 5 - 8 步與數據的到達有關,下一節會說。
5. 數據到達
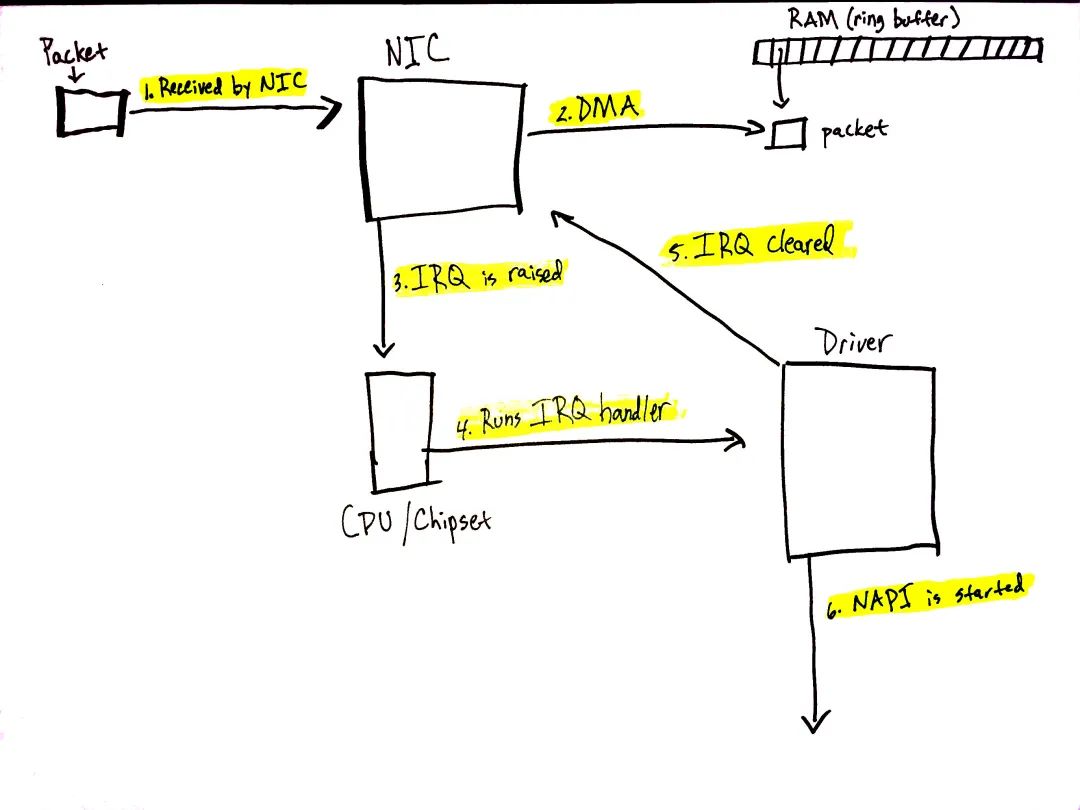
圖 2 數據從網絡上來了(前文“數據到達”一節)! 網絡數據到達 NIC 時,NIC 會通過 DMA 將 packet 數據寫入 RAM。igb 網絡驅動會在 RAM 中構建一個 ring buffer,其指向接收到的 packets。值得注意的是,有些 NIC 支持 "multiqueue",這些 NIC 可以使用多個處理器來處理 incoming 網絡數據(前文“準備從網絡接收數據”一節)。簡化起見,圖 2 只畫了一個 ring buffer,但取決于 NIC 以及硬件配置,你的系統可能使用的是多個隊列。 下面流程的細節參閱前文“數據到達”一節。 我們來過一遍數據接收流程:
數據從網絡到達 NIC。
NIC 通過 DMA 將網絡數據寫入 RAM。
NIC 觸發一個 IRQ。
執行設備驅動注冊的 IRQ 處理函數(前文“中斷處理”一節)。
NIC 清除 IRQ,這樣新 packet 到來時可以繼續觸發 IRQs。
調用 napi_schedule 拉起 NAPI 軟中斷 poll loop(前文“NAPI 與 napi_schedule”一節)。
napi_schedule 的調用觸發了 圖 1 中的 5 - 8 步。如后面所見,NAPI 軟中斷 poll loop 拉起的原理,就是翻轉一個 bit 域,并向 poll_list 上添加一個數據結構。napi_schedule 沒干什么其他事,這就是驅動將處理工作轉交給軟中斷系統的原理。 繼續分析 圖 1,對照圖中相應的數字:
驅動調用 napi_schedule 將驅動的 NAPI poll 數據結構添加至當前 CPU 的 poll_list 上。
軟中斷 pending bit 會被置上,如此該 CPU 上的 ksoftirqd 線程知曉有 packets 需要處理。
執行 run_ksoftirqd 函數(在 ksoftirqd 內核線程的 loop 中執行)。
調用 __do_softirq 檢查是否有 pending 的 bit 域,以此確認是否有 pending 的軟中斷,進而調用 pending 軟中斷的處理函數:net_rx_action,該函數干了所有的 incoming 網絡數據處理的臟活。
需要注意的是,軟中斷內核線程執行的是 net_rx_action,而不是設備驅動的 IRQ 處理函數。
6. 網絡數據處理的開始
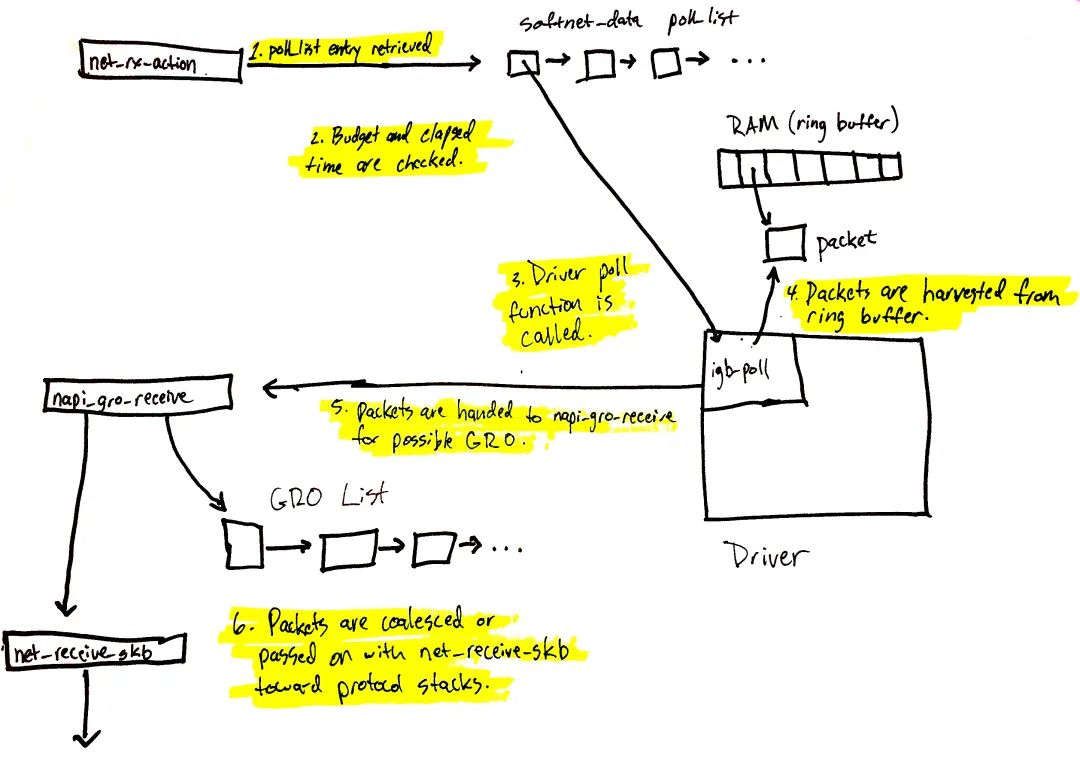
圖 3 至此開始數據的處理。net_rx_action 函數(在 ksoftirqd 內核線程中調用)會執行當前 CPU poll_list 上注冊的 NAPI poll 數據結構。poll 數據結構的注冊一般有兩種情況:
設備驅動調用 napi_schedule。
Receive Packet Steering 場景(前文“Receive Packet Steering(RPS)”一節)下使用 Inter-processor Interrupt。
我們將從 poll_list 獲取驅動 NAPI 數據結構的流程串起來(下一節會講 RPS 是怎么通過 IPIs 注冊 NAPI 數據結構的)。 圖 3 流程在前文有詳細拆解過,總結一下就是:
net_rx_action poll 檢查 NAPI poll list 中的 NAPI 數據結構。
校驗 budget 及消耗的時間,以確保軟中斷不會霸占 CPU。
調用注冊的 poll 函數(前文“NAPI poll 函數及權重”一節)。本文場景下,igb 驅動注冊的是 igb_poll 函數。
驅動的 poll 函數收取 RAM ring buffer 中的 packets(前文“NAPI poll”一節)。
packets 進一步給到 napi_gro_receive,其可能會進一步被 Generic Receive Offloading 處理(前文“Generic Receive Offloading(GRO)”一節)。
packets 要么被 GRO 處理,這樣整個調用鏈也就結束了;要么 packets 通過 net_receive_skb 進一步給到上層協議棧。
下面會講 net_receive_skb 是怎么實現 Receive Packet Steering,也就是在多個 CPUs 之間分發 packet 的。
7. 網絡數據的進一步處理
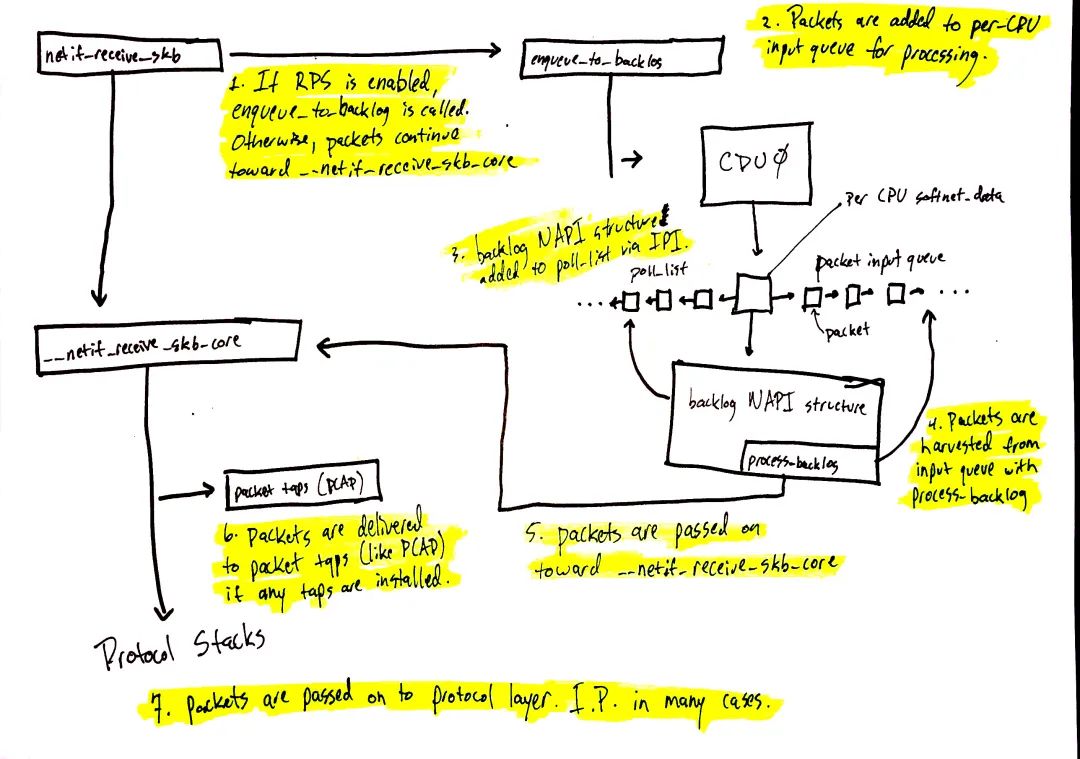
圖 4 從 netif_receive_skb 開始繼續網絡數據的處理,數據的具體路徑取決于是否使能了 Receive Packet Steering(RPS)。一個“開箱即用”的 linux 內核(譯者注:意思就是通用的發行版)默認是不使能 RPS 的,如果你想用 RPS,就必須顯式地配置及使能之。 RPS 禁能的情況下(前文“禁能 RPS 場景(默認配置)”一節),對應 圖 4 中的如下數字:
1. netif_receive_skb 將數據給到 __netif_receive_core。
6. __netif_receive_core 將數據給到系統中可能存在的 taps(前文“packet tap 投遞”一節)(比如 PCAP,https://www.tcpdump.org/manpages/pcap.3pcap.html)。
7. __netif_receive_core 將數據給到協議層注冊的 handlers(前文“協議層投遞”一節)。大多數情況下,此 handler 是 IPv4 協議棧所注冊的 ip_rcv 函數。
RPS 使能的情況下(前文“使能 RPS 場景”一節):
netif_receive_skb 將數據給到 enqueue_to_backlog。
packets 會被送到 per-CPU 的輸入隊列上以待后續處理。
將遠端 CPU 的 NAPI 數據結構添加至該遠端 CPU 的 poll_list 上,并向該 CPU 發一個 IPI,進而喚醒遠端 CPU 上的軟中斷內核線程(如果其并未在運行的話)。
當遠端 CPU 上的 ksoftirqd 內核線程運行起來后,其處理模式與上一節中的相同,不同之處是,注冊進來的 poll 函數是 process_backlog,該函數會從當前(譯者注:本 CPU) CPU 的輸入隊列收取 packets。
packets 進一步給到 __net_receive_skb_core。
__net_receive_skb_core 將數據給到系統中可能存在的 taps(前文“packet tap 投遞”一節)(比如 PCAP)。
__net_receive_skb_core 將數據給到協議層注冊的 handlers(前文“協議層投遞”一節)。大多數情況下,此 handler 是 IPv4 協議棧所注冊的 ip_rcv 函數。
8. 協議棧及用戶 sockets
數據接下來要走的路徑是:協議棧、netfilter、Berkeley Packet Filters,最終到達用戶 socket。 雖然代碼路徑挺長的,但是邏輯是直白清晰的。 網絡數據路徑更詳細地拆解見前文“協議層注冊”一節。下面是 high level 的簡要總結:
IPv4 協議層通過 ip_rcv 收取 packets。
會做 netfilter 以及路由優化。
目標是本機的數據,會進一步給到更 high level 的協議層,比如 UDP。
UDP 協議層通過 udp_rcv 收取 packets,并通過 udp_queue_rcv_skb 及 sock_queue_rcv 將數據入隊到用戶 socket 的接收 buffer 中。在入隊到接收 buffer 之前,會做 Berkeley Packet Filters。
值得注意的是,netfilter 在這個過程中會被調用多次,具體位置參考前文的詳細拆解(前文“協議層注冊”一節)。
9. 總結
linux 網絡棧極其復雜,涉及到的系統很多。如果要監控這個復雜的系統就必須得搞清楚這些系統之間是怎么交互的,以及對某一系統配置的調整,會如何影響到其他系統。本文作為前文的補充,試圖把這些問題梳理的更清晰易懂一些。
審核編輯:黃飛
?













 工商網監
工商網監
評論