 電子發(fā)燒友App
電子發(fā)燒友App


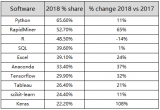
Python 近幾年在數(shù)據(jù)科學(xué)行業(yè)獲得了人們的極大青睞,各種資源也層出不窮。數(shù)據(jù)科學(xué)解決方案公司 ActiveWizards 近日根據(jù)他們自己的應(yīng)用開發(fā)經(jīng)驗,總結(jié)了數(shù)據(jù)科學(xué)家和工程師將在 2017 年最常使用的 Python 庫。
?
核心庫
1)NumPy
當(dāng)使用 Python 開始處理科學(xué)任務(wù)時,不可避免地需要求助 Python 的 SciPy Stack,它是專門為 Python 中的科學(xué)計算而設(shè)計的軟件的集合(不要與 SciPy 混淆,它只是這個 stack 的一部分,以及圍繞這個 stack 的社區(qū))。這個 stack 相當(dāng)龐大,其中有十幾個庫,所以我們想聚焦在核心包上(特別是最重要的)。
NumPy(代表 Numerical Python)是構(gòu)建科學(xué)計算 stack 的最基礎(chǔ)的包。它為 Python 中的 n 維數(shù)組和矩陣的操作提供了大量有用的功能。該庫還提供了 NumPy 數(shù)組類型的數(shù)學(xué)運算向量化,可以提升性能,從而加快執(zhí)行速度。
2)SciPy
SciPy 是一個工程和科學(xué)軟件庫。除此以外,你還要了解 SciPy Stack 和 SciPy 庫之間的區(qū)別。SciPy 包含線性代數(shù)、優(yōu)化、集成和統(tǒng)計的模塊。SciPy 庫的主要功能建立在 NumPy 的基礎(chǔ)之上,因此它的數(shù)組大量使用了 NumPy。它通過其特定的子模塊提供高效的數(shù)值例程操作,比如數(shù)值積分、優(yōu)化和許多其他例程。SciPy 的所有子模塊中的函數(shù)都有詳細(xì)的文檔,這也是一個優(yōu)勢。
3)Pandas
Pandas 是一個 Python 包,旨在通過「標(biāo)記(labeled)」和「關(guān)系(relational)」數(shù)據(jù)進行工作,簡單直觀。Pandas 是 data wrangling 的完美工具。它設(shè)計用于快速簡單的數(shù)據(jù)操作、聚合和可視化。庫中有兩個主要的數(shù)據(jù)結(jié)構(gòu):

Series:一維

Data Frames:二維
例如,當(dāng)你要從這兩種類型的結(jié)構(gòu)中接收到一個新的「Dataframe」類型的數(shù)據(jù)時,你將通過傳遞一個「Series」來將一行添加到「Dataframe」中來接收這樣的 Dataframe:

這里只是一小撮你可以用 Pandas 做的事情:
輕松刪除并添加「Dataframe」中的列
將數(shù)據(jù)結(jié)構(gòu)轉(zhuǎn)換為「Dataframe」對象
處理丟失數(shù)據(jù),表示為 NaN(Not a Number)
功能強大的分組
可視化
4)Matplotlib
Matplotlib 是另一個 SciPy Stack 核心軟件包和另一個 Python 庫,專為輕松生成簡單而強大的可視化而量身定制。它是一個頂尖的軟件,使得 Python(在 NumPy、SciPy 和 Pandas 的幫助下)成為 MatLab 或 Mathematica 等科學(xué)工具的顯著競爭對手。然而,這個庫比較底層,這意味著你需要編寫更多的代碼才能達到高級的可視化效果,通常會比使用更高級工具付出更多努力,但總的來說值得一試。花一點力氣,你就可以做到任何可視化:
線圖
散點圖
條形圖和直方圖
餅狀圖
莖圖
輪廓圖
場圖
頻譜圖
還有使用 Matplotlib 創(chuàng)建標(biāo)簽、網(wǎng)格、圖例和許多其他格式化實體的功能。基本上,一切都是可定制的。
該庫支持不同的平臺,并可使用不同的 GUI 工具套件來描述所得到的可視化。許多不同的 IDE(如 IPython)都支持 Matplotlib 的功能。
還有一些額外的庫可以使可視化變得更加容易。

5)Seaborn
Seaborn 主要關(guān)注統(tǒng)計模型的可視化;這種可視化包括熱度圖(heat map),可以總結(jié)數(shù)據(jù)但也描繪總體分布。Seaborn 基于 Matplotlib,并高度依賴于它。

6)Bokeh
Bokeh 也是一個很好的可視化庫,其目的是交互式可視化。與之前的庫相反,這個庫獨立于 Matplotlib。正如我們已經(jīng)提到的那樣,Bokeh 的重點是交互性,它通過現(xiàn)代瀏覽器以數(shù)據(jù)驅(qū)動文檔(d3.js)的風(fēng)格呈現(xiàn)。

7)Plotly
最后談?wù)?Plotly。它是一個基于 Web 的工具箱,用于構(gòu)建可視化,將 API 呈現(xiàn)給某些編程語言(其中包括 Python)。在 plot.ly 網(wǎng)站上有一些強大的、開箱即用的圖形。為了使用 Plotly,你需要設(shè)置你的 API 密鑰。圖形處理會放在服務(wù)器端,并在互聯(lián)網(wǎng)上發(fā)布,但也有一種方法可以避免這么做。

機器學(xué)習(xí)
8)SciKit-Learn
Scikits 是 SciPy Stack 的附加軟件包,專為特定功能(如圖像處理和輔助機器學(xué)習(xí))而設(shè)計。在后者方面,其中最突出的一個是 scikit-learn。該軟件包構(gòu)建于 SciPy 之上,并大量使用其數(shù)學(xué)操作。
scikit-learn 有一個簡潔和一致的接口,可利用常見的機器學(xué)習(xí)算法,讓我們可以簡單地在生產(chǎn)中應(yīng)用機器學(xué)習(xí)。該庫結(jié)合了質(zhì)量很好的代碼和良好的文檔,易于使用且有著非常高的性能,是使用 Python 進行機器學(xué)習(xí)的實際上的行業(yè)標(biāo)準(zhǔn)。
深度學(xué)習(xí):Keras / TensorFlow / Theano
在深度學(xué)習(xí)方面,Python 中最突出和最方便的庫之一是 Keras,它可以在 TensorFlow 或者 Theano 之上運行。讓我們來看一下它們的一些細(xì)節(jié)。
9)Theano
首先,讓我們談?wù)?Theano。Theano 是一個 Python 包,它定義了與 NumPy 類似的多維數(shù)組,以及數(shù)學(xué)運算和表達式。該庫是經(jīng)過編譯的,使其在所有架構(gòu)上能夠高效運行。這個庫最初由蒙特利爾大學(xué)機器學(xué)習(xí)組開發(fā),主要是為了滿足機器學(xué)習(xí)的需求。
要注意的是,Theano 與 NumPy 在底層的操作上緊密集成。該庫還優(yōu)化了 GPU 和 CPU 的使用,使數(shù)據(jù)密集型計算的性能更快。
效率和穩(wěn)定性調(diào)整允許更精確的結(jié)果,即使是非常小的值也可以,例如,即使 x 很小,log(1+x) 也能得到很好的結(jié)果。
10)TensorFlow
TensorFlow 來自 Google 的開發(fā)人員,它是用于數(shù)據(jù)流圖計算的開源庫,專門為機器學(xué)習(xí)設(shè)計。它是為滿足 Google 對訓(xùn)練神經(jīng)網(wǎng)絡(luò)的高要求而設(shè)計的,是基于神經(jīng)網(wǎng)絡(luò)的機器學(xué)習(xí)系統(tǒng) DistBelief 的繼任者。然而,TensorFlow 并不是谷歌的科學(xué)專用的——它也足以支持許多真實世界的應(yīng)用。
TensorFlow 的關(guān)鍵特征是其多層節(jié)點系統(tǒng),可以在大型數(shù)據(jù)集上快速訓(xùn)練人工神經(jīng)網(wǎng)絡(luò)。這為 Google 的語音識別和圖像識別提供了支持。
11)Keras
最后,我們來看看 Keras。它是一個使用高層接口構(gòu)建神經(jīng)網(wǎng)絡(luò)的開源庫,它是用 Python 編寫的。它簡單易懂,具有高級可擴展性。它使用 Theano 或 TensorFlow 作為后端,但 Microsoft 現(xiàn)在已將 CNTK(Microsoft 的認(rèn)知工具包)集成為新的后端。
其簡約的設(shè)計旨在通過建立緊湊型系統(tǒng)進行快速和容易的實驗。
Keras 極其容易上手,而且可以進行快速的原型設(shè)計。它完全使用 Python 編寫的,所以本質(zhì)上很高層。它是高度模塊化和可擴展的。盡管它簡單易用且面向高層,但 Keras 也非常深度和強大,足以用于嚴(yán)肅的建模。
Keras 的一般思想是基于神經(jīng)網(wǎng)絡(luò)的層,然后圍繞層構(gòu)建一切。數(shù)據(jù)以張量的形式進行準(zhǔn)備,第一層負(fù)責(zé)輸入張量,最后一層用于輸出。模型構(gòu)建于兩者之間。
自然語言處理
12)NLTK
這套庫的名稱是 Natural Language Toolkit(自然語言工具包),顧名思義,它可用于符號和統(tǒng)計自然語言處理的常見任務(wù)。NLTK 旨在促進 NLP 及相關(guān)領(lǐng)域(語言學(xué)、認(rèn)知科學(xué)和人工智能等)的教學(xué)和研究,目前正被重點關(guān)注。
NLTK 允許許多操作,例如文本標(biāo)記、分類和 tokenizing、命名實體識別、建立語語料庫樹(揭示句子間和句子內(nèi)的依存性)、詞干提取、語義推理。所有的構(gòu)建塊都可以為不同的任務(wù)構(gòu)建復(fù)雜的研究系統(tǒng),例如情緒分析、自動摘要。
13)Gensim
這是一個用于 Python 的開源庫,實現(xiàn)了用于向量空間建模和主題建模的工具。這個庫為大文本進行了有效的設(shè)計,而不僅僅可以處理內(nèi)存中內(nèi)容。其通過廣泛使用 NumPy 數(shù)據(jù)結(jié)構(gòu)和 SciPy 操作而實現(xiàn)了效率。它既高效又易于使用。
Gensim 的目標(biāo)是可以應(yīng)用原始的和非結(jié)構(gòu)化的數(shù)字文本。Gensim 實現(xiàn)了諸如分層 Dirichlet 進程(HDP)、潛在語義分析(LSA)和潛在 Dirichlet 分配(LDA)等算法,還有 tf-idf、隨機投影、word2vec 和 document2vec,以便于檢查一組文檔(通常稱為語料庫)中文本的重復(fù)模式。所有這些算法是無監(jiān)督的——不需要任何參數(shù),唯一的輸入是語料庫。
數(shù)據(jù)挖掘與統(tǒng)計
14)Scrapy
Scrapy 是用于從網(wǎng)絡(luò)檢索結(jié)構(gòu)化數(shù)據(jù)(如聯(lián)系人信息或 URL)的爬蟲程序(也稱為 spider bots)的庫。它是開源的,用 Python 編寫。它最初是為 scraping 設(shè)計的,正如其名字所示的那樣,但它現(xiàn)在已經(jīng)發(fā)展成了一個完整的框架,可以從 API 收集數(shù)據(jù),也可以用作通用的爬蟲。
該庫在接口設(shè)計上遵循著名的 Don』t Repeat Yourself 原則——提醒用戶編寫通用的可復(fù)用的代碼,因此可以用來開發(fā)和擴展大型爬蟲。
Scrapy 的架構(gòu)圍繞 Spider 類構(gòu)建,該類包含了一套爬蟲所遵循的指令。
15)Statsmodels
statsmodels 是一個用于 Python 的庫,正如你可能從名稱中猜出的那樣,其讓用戶能夠通過使用各種統(tǒng)計模型估計方法以及執(zhí)行統(tǒng)計斷言和分析來進行數(shù)據(jù)探索。
許多有用的特征是描述性的,并可通過使用線性回歸模型、廣義線性模型、離散選擇模型、穩(wěn)健的線性模型、時序分析模型、各種估計器進行統(tǒng)計。
該庫還提供了廣泛的繪圖函數(shù),專門用于統(tǒng)計分析和調(diào)整使用大數(shù)據(jù)統(tǒng)計數(shù)據(jù)的良好性能。
結(jié)論
這個列表中的庫被很多數(shù)據(jù)科學(xué)家和工程師認(rèn)為是最頂級的,了解和熟悉它們是很有價值的。這里有這些庫在 GitHub 上活動的詳細(xì)統(tǒng)計:

當(dāng)然,這并不是一份完全詳盡的列表,還有其它很多值得關(guān)注的庫、工具包和框架。比如說用于特定任務(wù)的 SciKit 包,其中包括用于圖像的 SciKit-Image。











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論