 電子發燒友App
電子發燒友App


SQL是用來存取關系數據庫的語言,具有查詢、操縱、定義和控制關系型數據庫的四方面功能。常見的關系數據庫有Oracle,SQLServer,DB2,Sybase。開源不收費的有MYSQL,SQLLite等。今天我們主要以MYSQL為例子,講解SQL常用的SQL語句。
下列語句部分是Mssql語句,不可以在access中使用。
SQL分類:
DDL—數據定義語言(CREATE,ALTER,DROP,DECLARE)
DML—數據操縱語言(SELECT,DELETE,UPDATE,INSERT)
DCL—數據控制語言(GRANT,REVOKE,COMMIT,ROLLBACK)
首先,簡要介紹基礎語句:
1、說明:創建數據庫
CREATE DATABASE database-name
2、說明:刪除數據庫
drop database dbname
3、說明:備份sql server
--- 創建 備份數據的 device
USE master
EXEC sp_addumpdevice ’disk’, ’testBack’, ’c:\mssql7backup\MyNwind_1.dat’
--- 開始 備份
BACKUP DATABASE pubs TO testBack
4、說明:創建新表
create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],。。)
根據已有的表創建新表:
A:create table tab_new like tab_old (使用舊表創建新表)
B:create table tab_new as select col1,col2… from tab_old definition only
5、說明:
刪除新表:drop table tabname
6、說明:
增加一個列:Alter table tabname add column col type
注:列增加后將不能刪除。DB2中列加上后數據類型也不能改變,唯一能改變的是增加varchar類型的長度。
7、說明:
添加主鍵:Alter table tabname add primary key(col)
說明:
刪除主鍵:Alter table tabname drop primary key(col)
8、說明:
創建索引:create [unique] index idxname on tabname(col…。)
刪除索引:drop index idxname
注:索引是不可更改的,想更改必須刪除重新建。
9、說明:
創建視圖:create view viewname as select statement
刪除視圖:drop view viewname
10、說明:幾個簡單的基本的sql語句
選擇:select * from table1 where 范圍
插入:insert into table1(field1,field2) values(value1,value2)
刪除:delete from table1 where 范圍
更新:update table1 set field1=value1 where 范圍
查找:select * from table1 where field1 like ’%value1%’ ---like的語法很精妙,查資料!
排序:select * from table1 order by field1,field2 [desc]
總數:select count * as totalcount from table1
求和:select sum(field1) as sumvalue from table1
平均:select avg(field1) as avgvalue from table1
最大:select max(field1) as maxvalue from table1
最小:select min(field1) as minvalue from table1
11、說明:幾個高級查詢運算詞
A: UNION 運算符
UNION 運算符通過組合其他兩個結果表(例如 TABLE1 和 TABLE2)并消去表中任何重復行而派生出一個結果表。當 ALL 隨 UNION 一起使用時(即 UNION ALL),不消除重復行。兩種情況下,派生表的每一行不是來自 TABLE1 就是來自 TABLE2。
B: EXCEPT 運算符
EXCEPT 運算符通過包括所有在 TABLE1 中但不在 TABLE2 中的行并消除所有重復行而派生出一個結果表。當 ALL 隨 EXCEPT 一起使用時 (EXCEPT ALL),不消除重復行。
C: INTERSECT 運算符
INTERSECT 運算符通過只包括 TABLE1 和 TABLE2 中都有的行并消除所有重復行而派生出一個結果表。當 ALL 隨 INTERSECT 一起使用時 (INTERSECT ALL),不消除重復行。
注:使用運算詞的幾個查詢結果行必須是一致的。
12、說明:使用外連接
A、left outer join:
左外連接(左連接):結果集幾包括連接表的匹配行,也包括左連接表的所有行。
SQL: select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
B:right outer join:
右外連接(右連接):結果集既包括連接表的匹配連接行,也包括右連接表的所有行。
C:full outer join:
全外連接:不僅包括符號連接表的匹配行,還包括兩個連接表中的所有記錄。
其次,大家來看一些不錯的sql語句
1、說明:復制表(只復制結構,源表名:a 新表名:b) (Access可用)
法一:select * into b from a where 1《》1
法二:select top 0 * into b from a
2、說明:拷貝表(拷貝數據,源表名:a 目標表名:b) (Access可用)
insert into b(a, b, c) select d,e,f from b;
3、說明:跨數據庫之間表的拷貝(具體數據使用絕對路徑) (Access可用)
insert into b(a, b, c) select d,e,f from b in ‘具體數據庫’ where 條件
例子:。.from b in ’“&Server.MapPath(”。“)&”\data.mdb“ &”’ where.。
4、說明:子查詢(表名1:a 表名2:b)
select a,b,c from a where a IN (select d from b ) 或者: select a,b,c from a where a IN (1,2,3)
5、說明:顯示文章、提交人和最后回復時間
select a.title,a.username,b.adddate from table a,(select max(adddate) adddate from table where table.title=a.title) b
6、說明:外連接查詢(表名1:a 表名2:b)
select a.a, a.b, a.c, b.c, b.d, b.f from a LEFT OUT JOIN b ON a.a = b.c
7、說明:在線視圖查詢(表名1:a )
select * from (SELECT a,b,c FROM a) T where t.a 》 1;
8、說明:between的用法,between限制查詢數據范圍時包括了邊界值,not between不包括
select * from table1 where time between time1 and time2
select a,b,c, from table1 where a not between 數值1 and 數值2
9、說明:in 的使用方法
select * from table1 where a [not] in (‘值1’,’值2’,’值4’,’值6’)
10、說明:兩張關聯表,刪除主表中已經在副表中沒有的信息
delete from table1 where not exists ( select * from table2 where table1.field1=table2.field1 )
11、說明:四表聯查問題:
select * from a left inner join b on a.a=b.b right inner join c on a.a=c.c inner join d on a.a=d.d where 。。。。。
12、說明:日程安排提前五分鐘提醒
SQL: select * from 日程安排 where datediff(’minute’,f開始時間,getdate())》5
13、說明:一條sql 語句搞定數據庫分頁
select top 10 b.* from (select top 20 主鍵字段,排序字段 from 表名 order by 排序字段 desc) a,表名 b where b.主鍵字段 = a.主鍵字段 order by a.排序字段
14、說明:前10條記錄
select top 10 * form table1 where 范圍
15、說明:選擇在每一組b值相同的數據中對應的a最大的記錄的所有信息(類似這樣的用法可以用于論壇每月排行榜,每月熱銷產品分析,按科目成績排名,等等。)
select a,b,c from tablename ta where a=(select max(a) from tablename tb where tb.b=ta.b)
16、說明:包括所有在 TableA 中但不在 TableB和TableC 中的行并消除所有重復行而派生出一個結果表
(select a from tableA ) except (select a from tableB) except (select a from tableC)
17、說明:隨機取出10條數據
select top 10 * from tablename order by newid()
18、說明:隨機選擇記錄
select newid()
19、說明:刪除重復記錄
Delete from tablename where id not in (select max(id) from tablename group by col1,col2,。。。)
20、說明:列出數據庫里所有的表名
select name from sysobjects where type=’U’
21、說明:列出表里的所有的
select name from syscolumns where id=object_id(’TableName’)
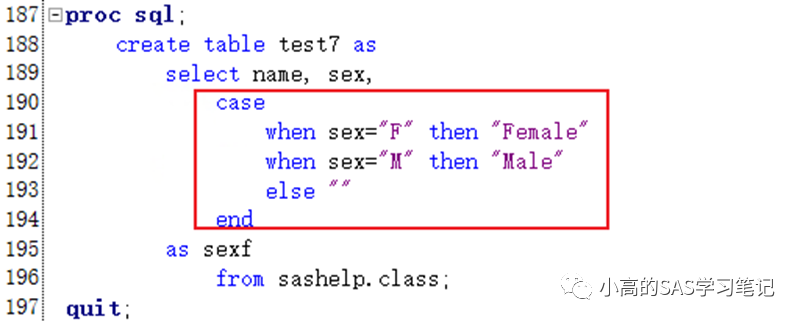
22、說明:列示type、vender、pcs字段,以type字段排列,case可以方便地實現多重選擇,類似select 中的case。
select type,sum(case vender when ’A’ then pcs else 0 end),sum(case vender when ’C’ then pcs else 0 end),sum(case vender when ’B’ then pcs else 0 end) FROM tablename group by type
顯示結果:
type vender pcs
電腦 A 1
電腦 A 1
光盤 B 2
光盤 A 2
手機 B 3
手機 C 3
23、說明:初始化表table1
TRUNCATE TABLE table1
24、說明:選擇從10到15的記錄
select top 5 * from (select top 15 * from table order by id asc) table_別名 order by id desc
隨機選擇數據庫記錄的方法(使用Randomize函數,通過SQL語句實現)
對存儲在數據庫中的數據來說,隨機數特性能給出上面的效果,但它們可能太慢了些。你不能要求ASP“找個隨機數”然后打印出來。實際上常見的解決方案是建立如下所示的循環:
Randomize
RNumber = Int(Rnd*499) +1
While Not objRec.EOF
If objRec(“ID”) = RNumber THEN
。。。 這里是執行腳本 。。。
end if
objRec.MoveNext
Wend
這很容易理解。首先,你取出1到500范圍之內的一個隨機數(假設500就是數據庫內記錄的總數)。然后,你遍歷每一記錄來測試ID 的值、檢查其是否匹配RNumber。滿足條件的話就執行由THEN 關鍵字開始的那一塊代碼。假如你的RNumber 等于495,那么要循環一遍數據庫花的時間可就長了。雖然500這個數字看起來大了些,但相比更為穩固的企業解決方案這還是個小型數據庫了,后者通常在一個數據庫內就包含了成千上萬條記錄。這時候不就死定了?
采用SQL,你就可以很快地找出準確的記錄并且打開一個只包含該記錄的recordset,如下所示:
Randomize
RNumber = Int(Rnd*499) + 1
SQL = “SELECT * FROM Customers WHERE ID = ” & RNumber
set objRec = ObjConn.Execute(SQL)
Response.WriteRNumber & “ = ” & objRec(“ID”) & “ ” & objRec(“c_email”)
不必寫出RNumber 和ID,你只需要檢查匹配情況即可。只要你對以上代碼的工作滿意,你自可按需操作“隨機”記錄。Recordset沒有包含其他內容,因此你很快就能找到你需要的記錄這樣就大大降低了處理時間。
再談隨機數










 工商網監
工商網監
評論