 電子發(fā)燒友App
電子發(fā)燒友App


學過編譯原理課程的同學應該有體會,各種文法、各種詞法語法分析算法,非常消磨人的耐心和興致;中間代碼生成和優(yōu)化,其實在很多應用場景下并不重要(當然這一塊對于“編譯原理”很重要);語義分析要處理很多很多細節(jié),特別對于比較復雜的語言;最后的指令生成,可能需要讀各種手冊,也比較枯燥。
我覺得對普通的程序員來說,編譯原理里面有實際用途的,是parser和codegen,但是因為這兩個領域,到了2016年都沒什么好研究的了,而且也被搞PLT的人所鄙視,所以你們看到的那些經(jīng)典的教材,都沒有好好講。
一、 編譯程序
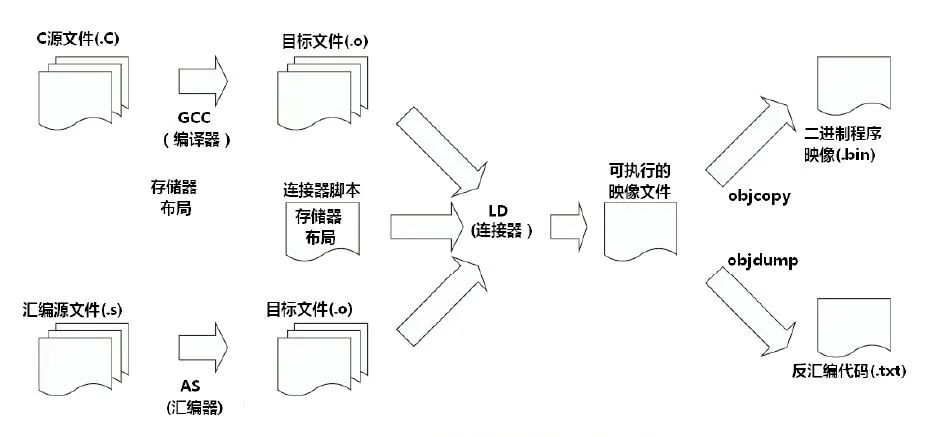
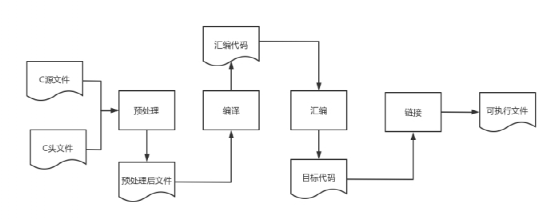
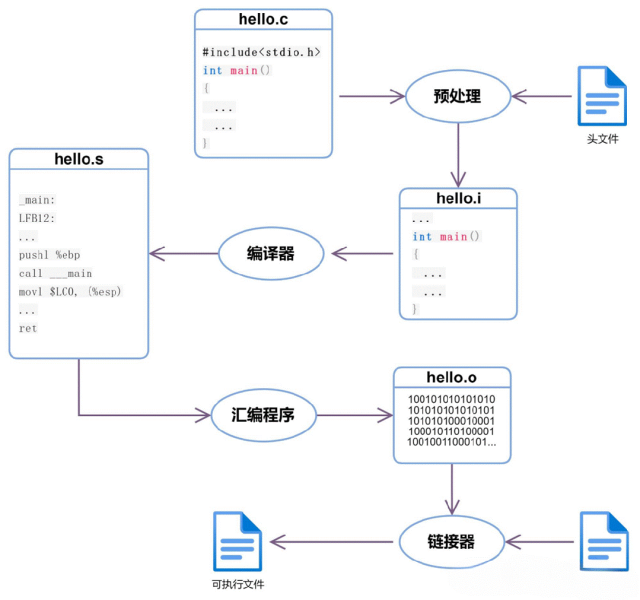
1、 編譯器是一種翻譯程序,它用于將源語言(即用某種程序設計語言寫成的)程序翻譯為目標語言(即用二進制數(shù)表示的偽機器代碼寫成的)程序。后者在windows操作系統(tǒng)平臺下,其文件的擴展名通常為.obj。該文件通常還要經(jīng)過進一步的連接,生成可執(zhí)行文件(機器代碼寫成的程序,文件擴展名為.exe)。通常有兩種方式進行這種翻譯,一種是編譯,另一種是解釋。后者并不生成可執(zhí)行文件,只是翻譯一條語句、執(zhí)行一條語句。這兩種方式相編譯比解釋運行的速度要快得多。
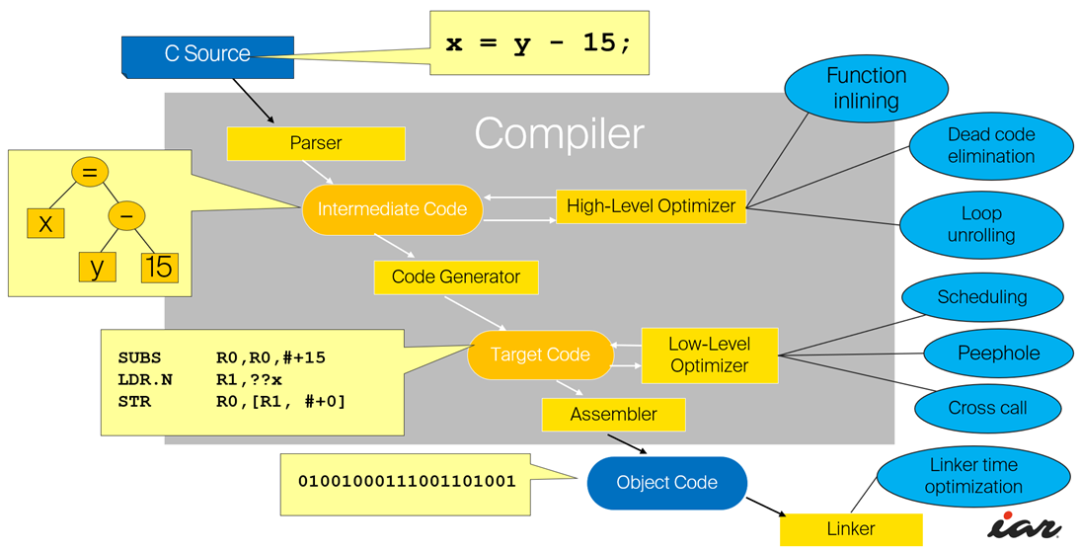
2、 編譯過程的5個階段:詞法分析;語法分析;語義分析與中間代碼產(chǎn)生;優(yōu)化;目標代碼生成。
3、 在這五個階段中,詞法分析的任務是識別源程序中的單詞是否有誤,編譯程序中實現(xiàn)這種功能的部分一般稱為詞法分析器。在編譯器中,詞法分析器通常僅作為語法分析程序的一個子程序以便在它需要單詞符號時調(diào)用。在這一編譯階段中發(fā)現(xiàn)的源程序錯誤,稱為詞法錯誤。
4、 語法分析階段的目的是識別出源程序的語法結(jié)構(gòu)(即語句或句子)是否錯誤,所以有時又常為句子分析。編譯程序中負責這一功能的程序稱為語法分析器或語法分析程序。在這一階段中發(fā)現(xiàn)的錯誤稱為語法錯誤。
5、 C語言的(源)程序必須經(jīng)過編譯才能生成目標代碼,再經(jīng)過鏈接才能運行。PASCAL語言、FORTRAN語言的源程序也要經(jīng)過這樣的過程。通常將C、PASCAL、FORTRAN這樣的語言統(tǒng)稱為高級語言。而將最終的可執(zhí)行程序稱為機器語言程序。
6、 在編譯C語言程序的過程中,發(fā)現(xiàn)源程序中的一個標識符過長,超過了編譯程序允許的范圍,這個錯誤應在詞法分析階段發(fā)現(xiàn),這種錯誤通常被稱作詞法錯誤。
6.1. 詞法分析器的任務是以詞法規(guī)則為依據(jù)對輸入的源程序進行單詞及其屬性的識別,識別出一個個單詞符號。
6.2. 詞法分析的輸入是源程序,輸出是一個個單詞的特殊符號,稱為Token(標記或符號)。
6.3.語法分析器的類型有:自下而上、自上而下。常用的語法分析器有:遞歸下降分析方法是一種自上而下分析方法, 算符優(yōu)先分析法屬于自下而上分析方法,LR分析法屬于自下而上分析方法等等。
6.4.通常用正規(guī)文法或正規(guī)式來描述程序設計語言的詞法規(guī)則,而使用上下文無關文法來描述程序設計語言的語法規(guī)則。
6.5.語法分析階段中,處理的輸入數(shù)據(jù)是來自詞法分析階段的單詞符號。它們是詞法分析階段的終結(jié)符。
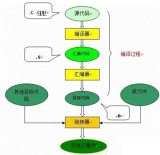
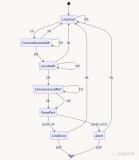
7、 編譯程序總框
8、 在計算機發(fā)展的早期階段,內(nèi)存較小的不能一次完成程序的編譯。這時通常將編譯過程分成若干遍來完成。每一遍完成一部分功能,稱為多遍編譯。
與采用高級程序設計語言寫的詞法分析器相比,用匯編語言寫的詞法分析通常分析速度要快些。
二。 詞法與語法
1、 程序語言主要由語法和語義兩個方面來定義。
2、 任何語言的程序都可看成是某字符集上的一個長字符串。
3、 語言的語法:是指這樣的一組規(guī)則(即產(chǎn)生式),用它可以生成和產(chǎn)生一個良定的程序。這些規(guī)則的一部分稱為詞法規(guī)則,另一部分稱為語法規(guī)則。
4、 詞法規(guī)則:單詞符號的形成規(guī)則;語法規(guī)則:語法單位(句子)的形成規(guī)則。語義規(guī)則:定義程序句子的意義。
5、 一個程序語言的基本功能是描述數(shù)據(jù)和對數(shù)據(jù)的運算。
6、 高級語言的分類:強制式語言;應用式語言;基于規(guī)則的語言;面向?qū)ο蟮恼Z言。
7、 一個語言的字母表為{a,b},則字符串a(chǎn)b的前綴有a、ε,其中ε不是真前綴。
8、 字符串的連接運算一般不滿足交換率。
9、 文法G是一個四元組,或者說由四個元素構(gòu)成,即非終結(jié)符集合VN、非終結(jié)符號集合VT 、開始符號S、產(chǎn)生式集合P,它可以形式化地表示成G =(VN,VT,S,P)。
按照文法的定義,這4個元素中終結(jié)符號集合是這個文法所規(guī)定的語言的字母表,產(chǎn)生式集合代表文法所規(guī)定的語言語法實體的集合。對上下文無關文法,通常我們只需要寫出這個文法的產(chǎn)生式集合就可以確定這個文法的其他所有元素。其中,第一條產(chǎn)生式的左部符號為開始符號,而所有產(chǎn)生式的左部符號構(gòu)成的集合就是該文法的非終結(jié)符集合。
文法的例子:
設文法G=(VN,VT, S,P),其中P為產(chǎn)生式集合,它的每個元素的形式為產(chǎn)生式。
10、如果文法G的一個句子存在兩棵不同的最左語法分析樹,則這個文法是無二義的。
11、如果文法G的一個句子存在兩棵不同的最右語法分析樹,則這個文法是無二義的。
12、如果文法G的一個句子存在兩棵不同的語法分析樹,則這個文法是無法判斷是否是二義的。
13、A為非終結(jié)符,如果文法存在產(chǎn)生式 ,則稱 可以推導出 ;反之,稱 可歸約為 。
14、喬姆斯基(Chomsky)將文法分為四類,即0型文法、1文法、2文法、3文法。
按照喬姆斯基對方法的分類,上下文無關文法是2型文法,2型文法的描述能力最強,3型文法又稱為正規(guī)文法。
15、產(chǎn)生式S→Sa | a產(chǎn)生的語言為L(G) = {an | n ≥ 1}。
16、確定有限自動機DFA是非確定有限自動機NFA的特例;對任一非確定有限自動機能找到一個與之等價的確定有限自動機。
17、DFA和NFA的主要區(qū)別有三點:一、DFA初態(tài)唯一,NFA初態(tài)不唯一;二、DFA弧標記為Σ上的元素,NFA弧標記為Σ*上的元素;三、DFA的函數(shù)為單射,NFA函數(shù)不是單射。
18、有限自動機中兩個狀態(tài)S1和S2是等價的是指,無論是從S1還是S2出發(fā),停于終態(tài)時,所識別的輸入字的集合相同。
19、自下而上的分析方法,是一個不斷歸約的過程。
20、遞歸下降分析器:當一個文法滿足LL(1)條件時,我們就可以為它構(gòu)造一個不帶回溯的自上而下分析程序。這個分析程序是由一組遞歸過程組成的,每個過程對應文法的一個非終結(jié)符。
這個產(chǎn)生式中含有的左遞歸是直接左遞歸。遞歸下降分析法中,必須要消除所有的左遞歸。遞歸下降分析法中的試探分析法之所以要不斷用一個產(chǎn)生式的多個候選式進行逐個試探,最根本的原因是這些候選式有公共左因子。
21、算符優(yōu)先分析法是一種自下而上的分析方法,它適合分析各種程序設計語中的表達式,并宜于手工實現(xiàn)。目前最廣泛的無回溯的“移進—歸約”方法是自下而上分析方法。
22、在表驅(qū)動預測分析器中,
1)讀入一個終結(jié)符a,若該終結(jié)符與棧項的終結(jié)符相同,并且不是結(jié)束標志$,則此時棧頂符號出棧;
2)若此時棧項符號是終結(jié)符并且是,并且讀入的終結(jié)符不是,說明源程序有語法錯誤;
3)若此時棧頂符號為,并且讀入的終結(jié)符也是,則分析成功。
23、算符優(yōu)先分析方法不存在使用形如 這樣的產(chǎn)生式進行的歸約,即只要求終結(jié)符的位置與產(chǎn)生式結(jié)構(gòu)一致,從而使得分析速度比LR分析法更快。
24、LR(0)的例子:
產(chǎn)生式E→ E+T對應的LR(0)項目中,待歸約的項目是E→ E+?T,移進項目是E→ E?+T,還有兩個項目為E→ ?E+T和E→ E+T?。
當一個LR(0)項目集中含有兩個歸約項目時,稱這個項目集中含有歸約-歸約沖突。
25、LL(1)文法的產(chǎn)生式中一定沒有公共左因子,即LL(1)文法中一定沒有左遞歸。為了避免回溯,在LL(1)文法的預測分析表中,一個表項中至多只有一個產(chǎn)生式。
預測分析方法(即LL(1)方法),由一個棧,一個總控程序和一個預測分析表組成。其中構(gòu)造出預測分析表是該分析方法的關鍵。
26、LR(0)與SLR(1)兩種分析方法相比,SLR(1)的能力更強。
27、靜態(tài)語義檢查一般包括以下四個部分,即類型檢查、控制流檢查、名字匹配檢查、一致性檢查。
C語言編譯過程中下述常見的錯誤都屬于檢查的范圍:
a) 將字符型指針的值賦給結(jié)構(gòu)體類型的指針變量:類型檢查。
b)switch語句中,有兩個case語句中出現(xiàn)了相同的常量:一致性檢查。
c)break語句在既不是循環(huán)體內(nèi)、又不是break語句出現(xiàn)的地方出現(xiàn):控制流檢查。
d)goto語句中的標號在程序的函數(shù)中沒有找到:一致性檢查。
e)同一個枚舉常量出現(xiàn)在兩個枚舉類型的定義當中:相關名字檢查。
28、循環(huán)優(yōu)化中代碼外提是指對循環(huán)中的有些代碼,如果它產(chǎn)生的結(jié)果在循環(huán)過程中是不變的,就把它提到循環(huán)體外來;而強度削弱是指把程序中執(zhí)行時間較長的運算替換為執(zhí)行時間較短的運算。
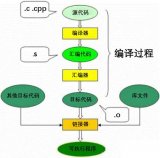
解析編譯原理主要過程
第一個編譯器由機器語言開發(fā) 然后就有了后來的各種語言寫出來的編譯器
1 編譯過程包括如下圖所示:。
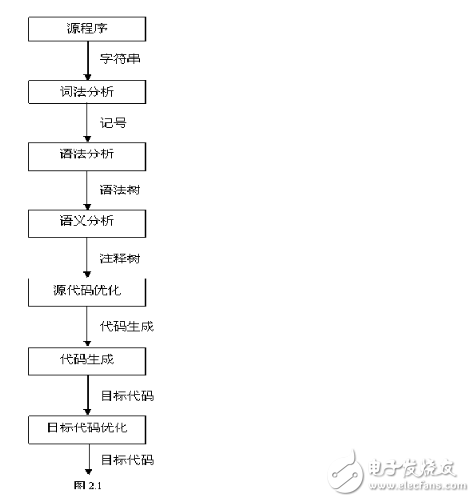
2 詞法分析作用:找出單詞 。如int a=b+c; 結(jié)果為: int,a,=,b,+,c和;
3語法分析作用:找出表達式,程序段,語句等。如int a=b=c;的語法分析結(jié)果為int a=b+c這條語句。
4語義分析作用:查看類型是否匹配等。
5注意點:詞法分析器實現(xiàn)步驟:正規(guī)式-》NFA-》簡化后的DFA-》對應程序;語法分析要用到語法樹;語義分析要用到語法制導。
編譯原理一般分為詞法分析,語法分析,語義分析和代碼優(yōu)化及目標代碼生成等一系列過程。下面我們結(jié)合來了解一下:
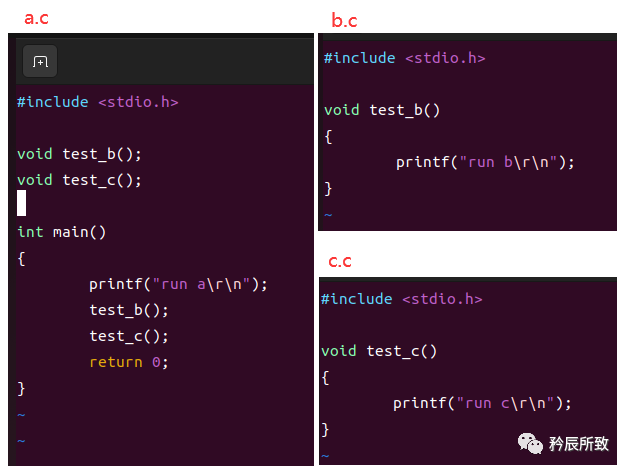
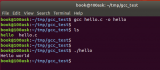
本程序可以同時在BC和Visual C++下運行。我測試過了的。下面先將代碼貼給大家。其中如果你只想先了解詞法分析部分,你可以將其余的注釋就可以。我建議大家學習時一步一步來,從詞法分析學,然后學語法分析。其他的就類似了。
如果你在DOS下運行,由于使用了漢字,請將其自行換成英文方便您的識別。
程序中的解釋就是編譯的基本原理。如果還不清楚建議大家看孫悅紅的編譯原理及實現(xiàn)清華的。




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論