 電子發燒友App
電子發燒友App


宏定義是C語言提供的三種預處理功能的其中一種,這三種預處理包括:宏定義、文件包含、條件編譯。宏定義和操作符的區別是:宏定義是替換,不做計算,也不做表達式求解。
宏定義又稱為宏代換、宏替換,簡稱“宏”。
#define 標識符 字符串
其中的標識符就是所謂的符號常量,也稱為“宏名”。
預處理(預編譯)工作也叫做宏展開:將宏名替換為字符串。
掌握“宏”概念的關鍵是“換”。一切以換為前提、做任何事情之前先要換,準確理解之前就要“換”。
即在對相關命令或語句的含義和功能作具體分析之前就要換:
例:
#define Pi 3.1415926
把程序中出現的Pi全部換成3.1415926
說明:
(1)宏名一般用大寫
(2)使用宏可提高程序的通用性和易讀性,減少不一致性,減少輸入錯誤和便于修改。例如:數組大小常用宏定義
(3)預處理是在編譯之前的處理,而編譯工作的任務之一就是語法檢查,預處理不做語法檢查。
(4)宏定義末尾不加分號;
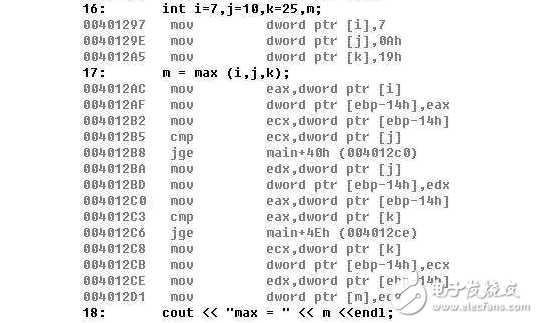
(5)宏定義寫在函數的花括號外邊,作用域為其后的程序,通常在文件的最開頭。
(6)可以用#undef命令終止宏定義的作用域
(7)宏定義允許嵌套
(8)字符串( “ ” )中永遠不包含宏
(9)宏定義不分配內存,變量定義分配內存。
(10)宏定義不存在類型問題,它的參數也是無類型的。
內聯函數與宏定義
在C中,常用預處理語句#define來代替一個函數定義。例如:
#define MAX(a,b) ((a)》(b)?(a):(b))
該語句使得程序中每個出現MAX(a,b)函數調用的地方都被宏定義中后面的表達式((a)》(b)?(a):(b))所替換。
宏定義語句的書寫格式有過分的講究, MAX與括號之間不能有空格,所有的參數都要
放在括號里。盡管如此,它還是有麻煩:
int a=1,b=0;
MAX(a++,b); //a被增值2次
MAX(a++,b+10); //a被增值1次
MAX(a,“Hello”); //錯誤地比較int和字符串,沒有參數類型檢查
MAX( )函數的求值會由于兩個參數值的大小不同而產生不同的副作用。
MAX(a++,b)的值為2,同時a的值為3;
MAX(a++,b+10)的值為10,同時a的值為2。
如果是普通函數,則MAX(a,“HellO”)會受到函數調用的檢查,但此處不會因為兩個參數類型不同而被編譯拒之門外。幸運的是,通過一個內聯函數可以得到所有宏的替換效能和 所有可預見的狀態以及常規函數的類型檢查:
inline int MAX(int a,int b)
{
return a》b?a:b;
}
1.內聯函數與宏的區別:
傳統的宏定義函數可能會引起一些麻煩。
ex:
#define F(x) x+x
void main(){int i=1;F(i++);}
這里x將被加兩次。
內聯函數被編譯器自動的用函數的形勢添加進代碼,而不會出現這種情況。
內聯函數的使用提高了效率(省去了很多函數調用匯編代碼如:call和ret等)。
2.內聯函數的使用:
所有在類的聲明中定義的函數將被自動認為是內聯函數。
class A()
{
void c();// not a inline function;
void d(){ print(“d() is a inline function.”);}
}
如果想將一個全局函數定義為內聯函數可用,inline 關鍵字。
inline a(){print(“a() is a inline function.”);}
注意:
在內聯函數中如果有復雜操作將不被內聯。如:循環和遞歸調用。
總結:
將簡單短小的函數定義為內聯函數將會提高效率。
用內聯取代宏代碼
C++ 語言支持函數內聯,其目的是為了提高函數的執行效率(速度)。
在 C程序中,可以用宏代碼提高執行效率。宏代碼本身不是函數,但使用起來象函數。預處理器用復制宏代碼的方式代替函數調用,省去了參數壓棧、生成匯編語言的 CALL調用、返回參數、執行return等過程,從而提高了速度。使用宏代碼最大的缺點是容易出錯,預處理器在復制宏代碼時常常產生意想不到的邊際效應。例如
#define MAX(a, b) (a) 》 (b) ? (a) : (b)
語句
result = MAX(i, j) + 2 ;
將被預處理器解釋為
result = (i) 》 (j) ? (i) : (j) + 2 ;
由于運算符‘+‘比運算符‘:’的優先級高,所以上述語句并不等價于期望的
result = ( (i) 》 (j) ? (i) : (j) ) + 2 ;
如果把宏代碼改寫為
#define MAX(a, b) ( (a) 》 (b) ? (a) : (b) )
則可以解決由優先級引起的錯誤。但是即使使用修改后的宏代碼也不是萬無一失的,例如語句
result = MAX(i++, j);
將被預處理器解釋為
result = (i++) 》 (j) ? (i++) : (j);
對于C++ 而言,使用宏代碼還有另一種缺點:無法操作類的私有數據成員。
讓我們看看C++ 的“函數內聯”是如何工作的。對于任何內聯函數,編譯器在符號表里放入函數的聲明(包括名字、參數類型、返回值類型)。如果編譯器沒有發現內聯函數存在錯誤,那么該函數的代碼也被放入符號表里。在調用一個內聯函數時,編譯器首先檢查調用是否正確(進行類型安全檢查,或者進行自動類型轉換,當然對所有的函數都一樣)。如果正確,內聯函數的代碼就會直接替換函數調用,于是省去了函數調用的開銷。這個過程與預處理有顯著的不同,因為預處理器不能進行類型安全檢查,或者進行自動類型轉換。假如內聯函數是成員函數,對象的地址(this)會被放在合適的地方,這也是預處理器辦不到的。
C++ 語言的函數內聯機制既具備宏代碼的效率,又增加了安全性,而且可以自由操作類的數據成員。所以在C++ 程序中,應該用內聯函數取代所有宏代碼,“斷言assert”恐怕是唯一的例外。assert是僅在Debug版本起作用的宏,它用于檢查“不應該”發生的情況。為了不在程序的Debug版本和Release版本引起差別,assert不應該產生任何副作用。如果assert是函數,由于函數調用會引起內存、代碼的變動,那么將導致Debug版本與Release版本存在差異。所以assert不是函數,而是宏。(參見6.5節“使用斷言”)
內聯函數的編程風格
關鍵字inline必須與函數定義體放在一起才能使函數成為內聯,僅將inline放在函數聲明前面不起任何作用。如下風格的函數Foo不能成為內聯函數:
inline void Foo(int x, int y); // inline僅與函數聲明放在一起
void Foo(int x, int y)
{
…
}
而如下風格的函數Foo則成為內聯函數:
void Foo(int x, int y);
inline void Foo(int x, int y) // inline與函數定義體放在一起
{
…
}
所以說,inline是一種“用于實現的關鍵字”,而不是一種“用于聲明的關鍵字”。一般地,用戶可以閱讀函數的聲明,但是看不到函數的定義。盡管在大多數教科書中內聯函數的聲明、定義體前面都加了inline關鍵字,但我認為inline不應該出現在函數的聲明中。這個細節雖然不會影響函數的功能,但是體現了高質量C++/C程序設計風格的一個基本原則:聲明與定義不可混為一談,用戶沒有必要、也不應該知道函數是否需要內聯。
定義在類聲明之中的成員函數將自動地成為內聯函數,例如
class A
{
public:
void Foo(int x, int y) { … } // 自動地成為內聯函數
}
將成員函數的定義體放在類聲明之中雖然能帶來書寫上的方便,但不是一種良好的編程風格,上例應該改成:
// 頭文件
class A
{
public:
void Foo(int x, int y);
}
// 定義文件
inline void A::Foo(int x, int y)
{
…
}
慎用內聯
內聯能提高函數的執行效率,為什么不把所有的函數都定義成內聯函數?
如果所有的函數都是內聯函數,還用得著“內聯”這個關鍵字嗎?
內聯是以代碼膨脹(復制)為代價,僅僅省去了函數調用的開銷,從而提高函數的執行效率。如果執行函數體內代碼的時間,相比于函數調用的開銷較大,那么效率的收獲會很少。另一方面,每一處內聯函數的調用都要復制代碼,將使程序的總代碼量增大,消耗更多的內存空間。以下情況不宜使用內聯:
(1)如果函數體內的代碼比較長,使用內聯將導致內存消耗代價較高。
(2)如果函數體內出現循環,那么執行函數體內代碼的時間要比函數調用的開銷大。
類的構造函數和析構函數容易讓人誤解成使用內聯更有效。要當心構造函數和析構函數可能會隱藏一些行為,如“偷偷地”執行了基類或成員對象的構造函數和析構函數。所以不要隨便地將構造函數和析構函數的定義體放在類聲明中。
一個好的編譯器將會根據函數的定義體,自動地取消不值得的內聯(這進一步說明了inline不應該出現在函數的聲明中)。
一些心得體會
C++ 語言中的重載、內聯、缺省參數、隱式轉換等機制展現了很多優點,但是這些優點的背后都隱藏著一些隱患。正如人們的飲食,少食和暴食都不可取,應當恰到好處。我們要辨證地看待C++的新機制,應該恰如其分地使用它們。雖然這會使我們編程時多費一些心思,少了一些痛快,但這才是編程的藝術。
第9章 類的構造函數、析構函數與賦值函數
構造函數、析構函數與賦值函數是每個類最基本的函數。它們太普通以致讓人容易麻痹大意,其實這些貌似簡單的函數就象沒有頂蓋的下水道那樣危險。
每個類只有一個析構函數和一個賦值函數,但可以有多個構造函數(包含一個拷貝構造函數,其它的稱為普通構造函數)。對于任意一個類A,如果不想編寫上述函數,C++編譯器將自動為A產生四個缺省的函數,如
A(void); // 缺省的無參數構造函數
A(const A &a); // 缺省的拷貝構造函數
~A(void); // 缺省的析構函數
A & operate =(const A &a); // 缺省的賦值函數
這不禁讓人疑惑,既然能自動生成函數,為什么還要程序員編寫?
原因如下:
(1)如果使用“缺省的無參數構造函數”和“缺省的析構函數”,等于放棄了自主“初始化”和“清除”的機會,C++發明人Stroustrup的好心好意白費了。
(2)“缺省的拷貝構造函數”和“缺省的賦值函數”均采用“位拷貝”而非“值拷貝”的方式來實現,倘若類中含有指針變量,這兩個函數注定將出錯。
對于那些沒有吃夠苦頭的C++程序員,如果他說編寫構造函數、析構函數與賦值函數很容易,可以不用動腦筋,表明他的認識還比較膚淺,水平有待于提高。
本章以類String的設計與實現為例,深入闡述被很多教科書忽視了的道理。String的結構如下:
class String
{
public:
String(const char *str = NULL); // 普通構造函數
String(const String &other); // 拷貝構造函數
~ String(void); // 析構函數
String & operate =(const String &other); // 賦值函數
private:
char *m_data; // 用于保存字符串
};
======================================================================================================
在程序編譯時,編譯器將程序中出現的內聯函數的調用表達式用內聯函數的函數體來進行替換。顯然,這種做法不會產生轉去轉回的問題,但是由于在編譯時將函數休中的代碼被替代到程序中,因此會增加目標程序代碼量,進而增加空間開銷,而在時間代銷上不象函數調用時那么大,可見它是以目標代碼的增加為代價來換取時間的節省。





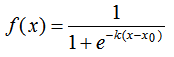





 工商網監
工商網監
評論