 電子發燒友App
電子發燒友App


隨著網絡技術和多媒體技術的發展.視頻通信的需求逐漸增加.同時最新的視頻壓縮標準不斷推出。MPEG-4 ( Moving Pictures Expcrts Group-4)是國際運動圖像像編碼專家組(MPEG Moving Picture Experts Group)在1998年11月制定[1]的,它不同于其他標準.是個而向多媒體應用的壓縮標準. 第1次提出了基于對象的壓縮方法.使交互功能的實現成為可能。日前基于PC平臺的MPEG-4視頻編碼器[2]在互聯網的遠程教育和高清晰電影等方面己經有較多的應用.但在硬盤錄像機、多媒體通信等視頻業務的嵌入式系統應用更為廣泛。以DSP為嵌入式圖像處理核心的系統,具有開發周期短,編程靈活的特點,因此DSP圖像處理系統成為了研究熱點。
DSPs結構特點
TMS320C6455是TI ( Tcxas Instrumcnts Incorporatcd)公司推出的最新高速DSP芯片[3]。具體結構見圖1。最主要的特點從是結構[4]上采用了VLIW(VLIW: VeryLong Instruction Word)超長指令字內核結構.具有1200 MHz的CPU,每個周期可以同時執行8條32bit的指令。速度可達到9600 MIPS ( 1200 MHz X 8條指令=4 800 MIPS) 。片內采用2級高速緩存結構.片外存儲器有很強大的外部存儲器接口EMIF ( Extcrnal Mcm ory Intcrfacc)。 這些性能能滿足視頻圖像處理的實時性要求.確立了它在高端多媒體應用中的地位。
?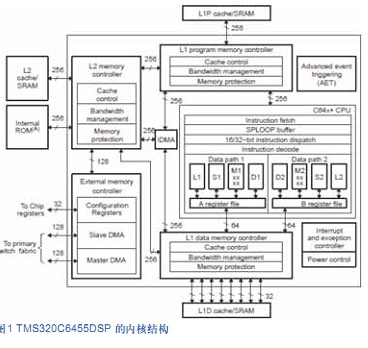
圖1 TMS320C6455DSP 的內核結構
對Cache的優化
最大程度地發揮Cache效率是達到期望編碼器性能的一個關鍵因素[5]。Cache高速的存儲訪問速度可以減少CPU延遲周期.提高處理器的效率。TMS320C64xDSP有兩級存儲結構應用片內數據和程序存儲。對于L1Cache能夠以CPU的同樣速度訪問。L2Cache既可以作數據空間也可以作為程序空間使用.L2是片外空間與L1的橋梁。
MPEG-4視頻編碼器是以宏塊為單位進行編碼處理 ,只有當前宏塊處理完成所有的過程后,視頻編碼器才能傳送一個宏塊。直接出現的缺點是: 一個視頻編碼器整個代碼大于 L1P。每個宏塊在 L1P和 L2之間的傳送過程 ,導致嚴重的Cache缺失。而一個單獨的宏塊從片外存儲空間到片內空間的搬移 , 也不能發揮 EDMA (Extended Direct Memony Access )的優勢。
為避免發生的Cache大量缺失,采取 3種方法[6] 。
1.整個編碼算法應該分成 3個模塊: 宏塊編碼、運動估計、運動重建 , 這樣使每個模塊代碼都適合 L1P。每次循環以宏塊組為單位 , 宏塊組的大小由 L1D大小決定。在宏塊編碼模塊中, 當宏塊組被傳送到片內,他們一起經過 DCT Direct Cosine Transform 、量化、熵編碼 , 直到宏塊組編碼模塊結束為止,L1D才刷新這組宏塊。同時對應的程序包括 DCT、量化、熵編碼也被保存到 L1P。
2.盡量減少數據類型的大小。可以用 8位數據就不用 16位數據 , 這樣不但節省空間 ,而且能提高L1D的使用效率。因為 L1D行的大小是固定的, 在一行內如果采用 8位數據 比 16位數據可多放一倍 , 從而減少程序中 Cache缺失情況的發生。
3.采用乒乓緩存結構, 提高 Cache命中率 , 減少 CPU等待時間。
在視頻編碼模塊中,當前幀和參考幀數據放在片外存儲器,在編碼過程中需要依次對圖像幀中的每個宏塊進行操作。但宏塊直接從片外內存讀取,這就會發生CPU等待。可以設置兩對片上緩存,一對存放當前幀宏塊,一對存放參考幀宏塊,它們以乒乓方式工作。乒乓緩沖工作模式如圖1所示。編碼前E DMA將片外的當前幀中編碼宏塊數據和在搜索范圍內的參考幀宏塊數據搬移到片上內存。在用EDMA搬移數據到其中一塊片內緩存的同時,,處理器可以對另一塊緩存中的數據進行處理。經過這樣的修改,CPU一直從片上讀取存儲器數據大大減少了CPU阻塞情況的發生,提高了編碼速度。
?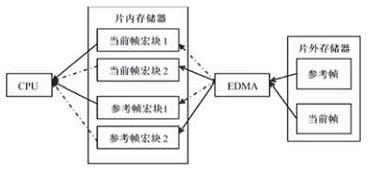
圖2 乒乓緩沖存儲器結構
SAD和像素插值的優化
SAD(Sum ofAbsolute Difference)是運動估計模塊[7]關鍵模塊 , 而 DM642提供了一套豐富的視頻和圖像專用指令可以高效實現運動估計算法。
LDNDW (Load Non2alignedDoubleWord)指令,可以一次讀取 64位無邊界數據。這個指令可以從當前幀中和參考幀一次讀取8個 8位像素數據。因此可以提高當前幀和參考幀宏塊數據的搬移速度。
SUBABS4(Subtractwith Absolute)指令,計算在兩組 8位數據包之間的 4個絕對值之差。
DOPTPU4是個計算 4對 8位數據乘積求和的運算。兩個 DOPTPU4可在單周期內并行 , 所以可極大地提高 SAD的計算速度。具體步驟如下:
1)兩個 LDNDW指令從當前幀和參考幀取 8個像素;
2)兩個 SUBABS4計算 8個像素的差值;
3)兩個 DOTPU4計算 8個像素乘積求和。
像素插值也是個計算量大的模塊。AVG4指令可執行 4個 8位數值平均值計算。AVG2可以執行 2個 16位數據的平均計算。SHRMB(Shift Right andMerge Byte) 右移第 2個寄存器 , 把第 1個寄存器的低位作為高字節。AVG4計算平均值,SHRMB處理結果。
此外筆者參考 TI提供的 IMGLIB支持庫 該庫中還包括了許多常用的圖像和視頻處理的函數 ,以完成 DCT、 IDCT (Inverse Direct Cosine Transform)、中值濾波等功能 , 這些函數都是經過匯編優化。完全能夠實現軟件流水, 執行效率很高。采用標準序列 Coastguard.yuv編碼 5幀數據,主要函數優化前后性能比較,如表 1所示。
表 1 各個函數優化性能比較

Tab1Performance of functions by analysis
利用 EDMA進行數據搬移, 提高存儲速度
TMS320C6455DSP支持 EDMA功能 , 是在沒有 CPU介入的情況下 , 訪問存儲器的一種工作方式。它可以直接通過 EDMA通道 , 提前把外設或片外存儲器中的數據直接搬移到片上內存。對 CPU來說 , 所訪問的數據總是在片內的 , 沒有阻塞的情況發生 , 減少了 CPU等待時間[8]。
使用 TI的 CSL (Chip SupportLibrary )支持功能[9,10]。它有專門的 DMA模塊 , 便于對 DMA的各個存儲器控制。主要使用 DAT函數 , 進行 DMA存儲器間數據傳送。其中使用 DAT copy ( )和DAT fill ( )。
就象常用的內存操作 memcpy 、memset 一樣 , 只需要在 API接口指出源地址、目的地址、長度、維數屬性等 , 而不需要再去考慮具體的寄存器。
下面的代碼就是把 SDRAM中的 90幀 CIF 288 ×352 格式視頻序列中的一幀 , 利用 EDMA在緩存中進行搬移。
DAT_open(DAT_CHANNY, DAT_ PRI_ LOW,DAT_OPEN_2D);
Copy2FrameBuf(Unit8*framebuf)
{
if((tempbuf_rawbuf)>13685852)
if (tempbuf!=NULL)
free(tempbuf);
return 1;
}
DAT.copy(tempbuf,framebuf,152064);
Tembuf+=152064;
return 0;
}
編碼器的總體性能
表2 MPEG-4編碼器的性能
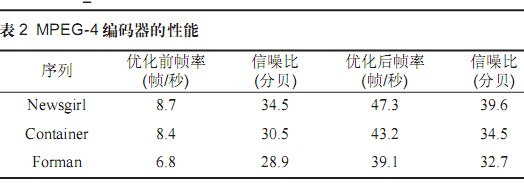
從表2數據可以看出,對于不同的視頻序列幀率提高至少5倍以上,信噪比雖然有所降低,但是由于頻幀的大幅度提高并達到實時要求而得到彌補,顯示效果更好。
結語
筆者論述了TMS32OC6455DSP 平臺上進行視頻編碼算法優化的措施。主要考慮根據DSP自身特點和視頻算法進行優化,通過實驗可以驗證達到30幀/秒以上的實時性要求,隨著IC 技術的發展和DSP 價格的降低,基于DSP的視頻編碼器的商用價值越來越明顯。









 工商網監
工商網監
評論