 電子發燒友App
電子發燒友App


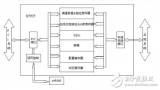
隨著網絡的飛速發展,人們可獲取的信息量日益增長,數據的處理及存儲速率的要求也越來越高。萬兆網(10Gb以太網)的普及,高速存儲設備的應用(如DDR2,傳輸速率可達800M)對系統帶寬帶來極大的挑戰。
伴隨著FPGA技術的大規模的應用,越來越多的大型系統采用PCI Express總線連接FPGA處理板和PC以實現數據的交互。盡管很多FPGA公司推出了基于PCI Express協議相關的IP硬核,但是掌握這些硬核的使用需要對PCI Express 協議具有一定的了解,而且直接使用硬核,帶寬很小,開發難度大,移植性差等缺點這些都是造成目前PCI Express接口設計的瓶頸。為了降低開發難度,提高帶寬和移植性,許多現有的方案是在PCI Express硬核中加入高速DMA控制器單元,以此來達到設計需求。
文中介紹了一種基于高速的I/O串行互聯技術,PCI-Express(簡稱PCIe),提出了在系統設計中基于FPGA的PCIe總線接口設計及應用于該總線的高速DMAEngine設計方案。
PCI Express總線簡介
PCI Express總線技術是取代PCI的第三代I/O技術。PCIExpress總線是為計算機和通訊平臺定義的一種高性能、通用I/O互聯總線。至今已經發布了3個正式版本:PCI Express 1.0、PCIExpress 2.0、PCI Express 3.0。單向單通道帶寬分別為:250MB/s, 500MB/s, 1GB/s。PCI Express體系結構的設計非常先進,采用了類似網絡體系結構中OSI分層體系結構設計方案,如圖2.1所示。按照協議規范,PCI Express總線的層次結構分為物理層(Physical Layer)、數據鏈路層(Data Link Layer)和事物層(Transaction Layer)體系結構。
在性能方面,相比PCI總線,PCI Express總線具有以下特點:
(1)在數據傳輸模式上,PCI Express 采用差分串行傳輸方式,一條PCI Express通道(稱為PCI Express X1)由2對差分信號線來實現數據的發送和接收。
(2)PCI Express具有高速串行通信接口所特有的時鐘恢復核心,將時鐘融合到傳輸的數據中,這樣既減去了時鐘管腳,又能大大提高傳輸速度,突破了并行傳輸帶寬的瓶頸。
(3)PCI Express是采用點到點的互連方法,每個設備都由獨立的鏈路連接,獨享帶寬,大大提高傳輸效率。
(4)具有很好的靈活性,一個PCI Express物理連接可以根據實際需要配置成X1,X2,X4,X8,X16 及X32鏈路模式。因此傳輸的速度也就相應的成倍增長。
(5)PCI Express傳輸的數據以協議定義的數據包(packet)的形式進行傳輸,保障了數據傳輸的完整性和可靠性。
(6)PCI Express協議加入了數據重傳機制,提高了數據傳輸的可靠性。
正是由于PCI Express的這些技術特點,使得其越來越廣泛的應用在計算機系統架構及海量數據傳輸接口領域,特別是在加入了高速DMA控制器傳輸方式下,PCI Express帶寬及傳輸效率大大提高,因此在高速系統領域具有廣闊的前景。
FPGA系統設計方案
傳統FPGA設計方案
傳統FPGA并不具備LVDS信號驅動能力。一般以PEX8311橋接芯片實現PCIe物理層接口,再配合CPLD實現用戶邏輯設計。PEX8311提供2個端口,一個為兼容PCIExpress1.0標準的PCIe接口,另一個為LocalBus總線接口,用于與CPLD相連。LocalBus總線工作于66MHz時鐘,32-bit總線寬度,可以提供266MB/s帶寬。同時,PEX8311還提供了2組DMA通道。使用PEX8311可以方便地從PCI平滑過渡到PCIe,從而降低開發成本,因此被廣泛使用。
然而,PEX8311并不能有效發揮出PCIe高帶寬優勢,也缺乏可配置性和靈活性,難以提高系統整體性能。
基于PCIe硬核接口設計
Xilinx新推出Virtex-6系列的FPGA,集成了PCIeIP硬核模塊。該模塊兼容PCIExpress2.0標準分層協議(為物理層、數據鏈路層和事物層,又稱傳輸層),提供了系統接口(SYS)、外部傳輸接口(PCIEXP)、配置接口(CFG)、事物接口(TRN)和物理鏈路接口(PL)。其Virtex-6GTX可配置高速串行傳輸器為PCIe信號可靠傳輸提供了保障。文中便是針對該硬核的事物層提出片上系統的PCIe設計方案。
PCI-Express接口及應用層設計
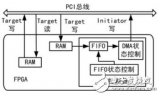
一個基本的高速數據采集系統,由微處理器(CPU)、FPGA和外部存儲器等組成。CPU與FPGA通過PCIe總線進行數據傳輸,FPGA通過DMA方式對外部存儲器進行數據讀寫操作。文中給出基于PCIex1傳輸方式的接口設計方案。
PCIe接口及事物層設計
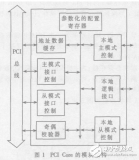
較之使用PEX8311橋接芯片的系統設計,采用基于Xilinx的IP核的設計方案,用戶可以根據自己的需求靈活設計面向事物層接口電路,并方便加入特殊功能,如與內部總線連接、實現DMA傳輸等。該設計充分利用FPGA集成度高、可配置性強等特點來發揮PCIe接口性能。FPGA的PCIe接口設計包括XilinxPCIe端點硬核和面向事物層的應用邏輯設計2個部分,這里將詳細給出應用層設計,如圖1所示。
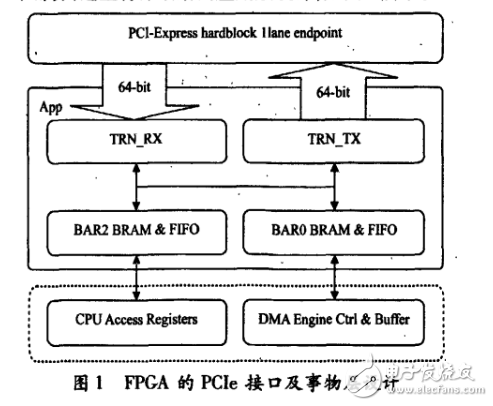
XilinxPCIe硬核支持64-bit數據通路,分別用于發送和接收數據。該硬核提供6個32-bit基地址寄存器BAR0~BAR5(BassAddressRegister,簡稱BAR),可以根據用戶設計需求進行配置。在本設計中使用BAR0和BAR1組成一組64-bit地址空間,用于存儲外部CPU訪問FPGA內部寄存器地址。使用BAR2和BAR3組成另一組64-bit地址空間,用于存儲DMAEngine控制器和緩存器地址。通過判斷trn_rbar_hit_n[6:0]來區分BAR0和BAR2,其主要代碼如下:
? ?
‘TRN _RX_M EM _RD64_DW 1DW 2: begin
? ?
req_bar0_o 《 = ~trn_rbar_hit_n_q [ 0 ] ; req_bar2_o 《 = ~trn_rbar_hit_n_q [ 2 ] ;
? ?
end
以外部CPU讀FPGA內部寄存器為例,FPGA將收到的PCIe總線上數據幀經由硬核的事物層,以64-bit帶寬送出,應用層通過TRN_RX接收狀態機來判斷請求訪問的地址空間,然后將請求數據緩寫入一個雙端口的req_fifo;用戶邏輯通過讀取req_fifo,將有效的寄存器數據寫入另一個雙端口data_fifo中,最后通過TRN_TX發送狀態機發送給硬核事物層。
基于PCIe的DMAEngine設計
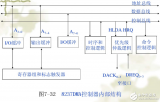
通過DMA訪問外部存儲器的最大優勢在于CPU在配置完DMAEngine后可以繼續其他指令操作,DMAEngine會通過請求PCIe總線中斷的方式,來完成數據傳輸。本設計將PCIeBAR0地址空間存儲DMAEngine控制和緩存器地址,其定義如圖2所示。
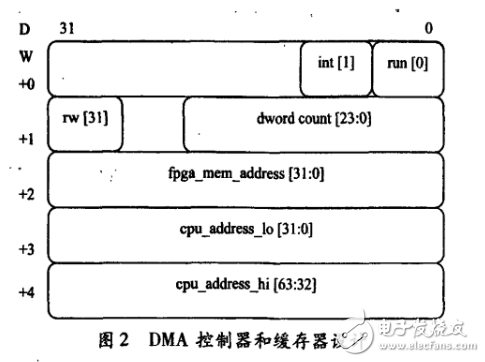
DWORD0[0],run,寫1開啟DMA;
DWORD0[1],int,寫1開啟DMA中斷方式;
DWORD1[31]rw,寫1讀fpga外部存儲器;
DWORD1[23:0]dwordcount,DMA操作數據個數,以dword為單位;
DWORD2[31:0]fpga_mem_address,fpga外部存儲器地址;
DWORD3[31:0]cpu_address_lo,cpu低32位地址;
DWORD4[31:0]cpu_address_h,icpu高32位地址。
修改PCIe數據幀類型(tlp_type《=trn_rd[62:56]),加入DMA數據幀,使其有別于對BAR的讀寫操作,部分代碼如下:
`efineTRN_RX_DMA_TLP_TYPE 7.b10_01010;/*DMA
數據類型*/
d`efineTRN_RX_DMA_DATA1 10.b01_0000_0000;/*
DMA操作狀態*/
,,
case(state)
R`ST:begin
,,
case(tlp_type)
,,
T`RN_RX_DMA_TLP_TYPE:begin
,,
state《=T`RN_RX_DMA_DATA1;
end
,,
T`RN_RX_DMA_DATA1:begin ,,
end,,
endcase
以同樣的方式在TRN_TX狀態機中加入DMA請求,其代碼如下:
d`efineTRN_TX_DMA_REQ 10.b01_0000_0000;
,,
case(state)
R`ST:begin
if(dma_tlp_ready)begin/*DMAEngine準備好讀操
作數據幀*/
state《=T`RN_TX_DMA_REQ;
dma_tlp_rd_en《=1.b1; /*DMA緩存讀使能
*/
end
elseif(,,)
,,
end
,,
T`RN_TX_DMA_REQ:begin
,,
if(~tlp_dma_data_eof)/*
數據幀結束標志位*/
state《=T`RN_TX_DONE;
els
state《=T`RN_TX_DMA_REQ;
end
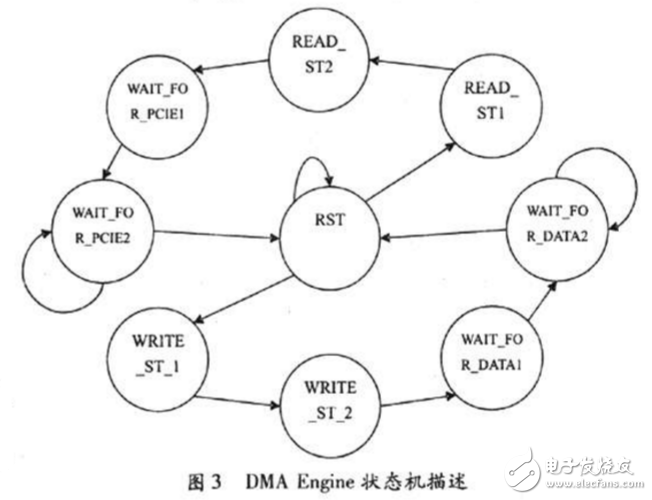
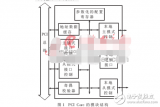
FPGA的DMAEngine狀態轉移圖如圖3所示,分DMA讀操作和寫操作2部分。DMAEngine處于RST狀態時,通過讀取DMA信息標識符來判斷當前是否處于空閑狀態,并從FPGA內部RAM中讀取DMA控制信息(讀或寫),并進入相應狀態READ_ST或WRITE_ST。以CPU寫FPGA外部存儲器為例,CPU通過PCIe總線寫BAR0地址數據來配置并開啟DMAEngine。FPGA將發出對CPU的DMA讀請求,然后等待CPU發送DMA數據。此時DMAEngine處于WAIT_FOR_DATA狀態,等待來自PCIe接口的DMA數據包。同樣,CPU讀FPGA外部存儲器時,FPGA將發出對CPU的DMA寫請求,并當DMA完成讀操作后,等待PCIe接口發送DMA數據包,并由中斷標志位判斷是否開啟PCIe中斷。
仿真及測試結果
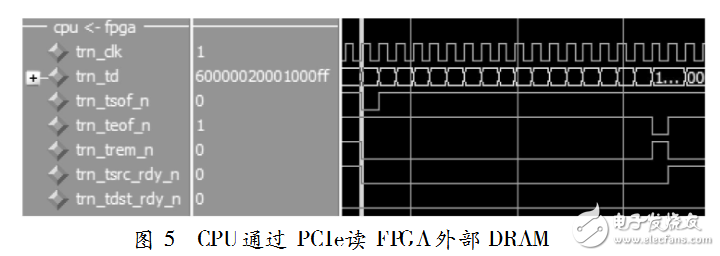
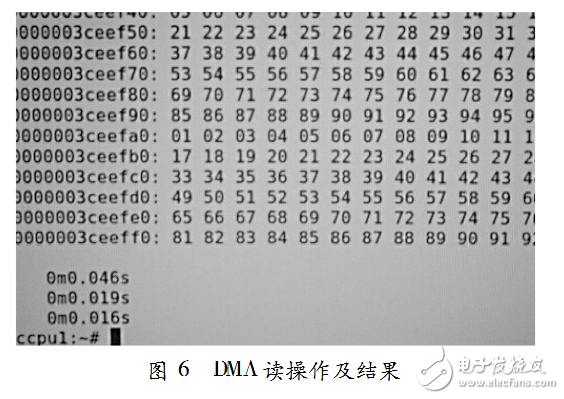
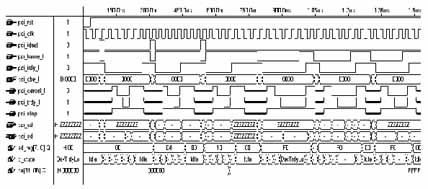
為了測試該DMAEngine設計,對FPGA外部64-bitDDR2DRAM進行32個dwords(128bytes)讀與寫操作,得到的仿真波形如圖4和圖5所示。圖4是對DMA進行寫操作的PCIe事物層接口波形。圖5是對DMA進行讀操作的PCIe事物層接口波形。該設計方案在questasmi6.3f下驗證通過。可以估算出一次PCIex1寫操作為1720Mb/s,讀為1684Mb/s。同樣,在實際的應用環境中測試本文DMAEngine設計,也獲得比較好的結果。圖6就是系統以本文DMA方式進行4096bytes讀外部存儲器的結果。

FPGA較ASIC的強大之處,在于靈活性和可配置性。文中憑借XilinxPCIe硬核,很好地實現了PCIex1總線接口,并在此基礎上加入高速DMAEngine設計,可以有效地提高系統數據存儲效率。
該設計方案通過簡單修改也同樣適用于32-bit帶寬傳輸系統設計。














 工商網監
工商網監
評論