 電子發燒友App
電子發燒友App


OpenGL 擴展
許多高級特性,如那些要在GPU上進行普通浮點運算的功能,都不是OpenGL內核的一部份。因此,OpenGL Extensions通過對OpenGL API的擴展, 為我們提供了一種可以訪問及使用硬件高級特性的機制。OpenGL擴展的特點:不是每一種顯卡都支持該擴展,即便是該顯卡在硬件上支持該擴展,但不同版本的顯卡驅動,也會對該擴展的運算能力造成影響,因為OpenGL擴展設計出來的目的,就是為了最大限度地挖掘顯卡運算的能力,提供給那些在該方面有特別需求的程序員來使用。在實際編程的過程中,我們必須小心檢測當前系統是否支持該擴展,如果不支持的話,應該及時把錯誤信息返回給軟件進行處理。當然,為了降低問題的復雜性,本教程的代碼跳過了這些檢測步驟。
OpenGL Extension Registry OpenGL擴展注冊列表中,列出了幾乎所有的OpenGL可用擴展,有需要的朋友可能的查看一下。
當我們要在程序中使用某些高級擴展功能的時候,我們必須在程序中正確引入這些擴展的擴展函數名。有一些小工具可以用來幫助我們檢測一下某個給出的擴展函數是否被當前的硬件及驅動所支持,如:glewinfo, OpenGL extension viewer等等,甚至OpenGL本身就可以(在上面的連接中,就有一個相關的例子)。
如何獲取這些擴展函數的入口指針,是一個比較高級的問題。下面這個例子,我們使用GLEW來作為擴展載入函數庫,該函數庫把許多復雜的問題進行了底層的封裝,給我們使用高級擴展提供了一組簡潔方便的訪問函數。
[cpp] view plaincopyvoid initGLEW (void) {
// init GLEW, obtain function pointers
int err = glewInit();
// Warning: This does not check if all extensions used
// in a given implementation are actually supported.
// Function entry points created by glewInit() will be
// NULL in that case!
if (GLEW_OK != err) {
printf((char*)glewGetErrorString(err));
exit(ERROR_GLEW);
}
}
OpenGL離屏渲染的準備工作
在傳統的GPU渲染流水線中,每次渲染運算的最終結束點就是幀緩沖區。所謂幀緩沖區,其實是顯卡內存中的一塊,它特別這處在于,保存在該內存區塊中的圖像數據,會實時地在顯示器上顯示出來。根據顯示器設置的不同,幀緩沖區最大可以取得32位的顏色深度,也就是說紅、綠、藍、alpha四個顏色通道共享這32位的數據,每個通道占8位。當然用32位來記錄顏色,如果加起來的話,可以表示160萬種不同的顏色,這對于顯示器來說可能是足夠了,但是如果我們要在浮點數字下工作,用8位來記錄一個浮點數,其數學精度是遠遠不夠的。另外還有一個問題就是,幀緩存中的數據最大最小值會被限定在一個范圍內,也就是 [0/255; 255/255]
如何解決以上的一些問題呢?一種比較苯拙的做法就是用有符號指數記數法,把一個標準的IEEE 32位浮點數映射保存到8位的數據中。不過幸運的是,我們不需要這樣做。首先,通過使用一些OpenGL的擴展函數,我們可以給GPU提供32位精度的浮點數。另外有一個叫EXT_framebuffer_object 的OpenGL的擴展, 該擴展允許我們把一個離屏緩沖區作為我們渲染運算的目標,這個離屏緩沖區中的RGBA四個通道,每個都是32位浮點的,這樣一來, 要想GPU上實現四分量的向量運算就比較方便了,而且得到的是一個全精度的浮點數,同時也消除了限定數值范圍的問題。我們通常把這一技術叫FBO,也就是Frame Buffer Object的縮寫。
要使用該擴展,或者說要把傳統的幀緩沖區關閉,使用一個離屏緩沖區作我們的渲染運算區,只要以下很少的幾行代碼便可以實現了。有一點值得注意的是:當我用使用數字0,來綁定一個FBO的時候,無論何時,它都會還原window系統的特殊幀緩沖區,這一特性在一些高級應用中會很有用,但不是本教程的范圍,有興趣的朋友可能自已研究一下。
[cpp] view plaincopyGLuint fb;
void initFBO(void) {
// create FBO (off-screen framebuffer)
glGenFramebuffersEXT(1, &fb);
// bind offscreen buffer
glBindFramebufferEXT(GL_FRAMEBUFFER_EXT, fb);
}
Back to top
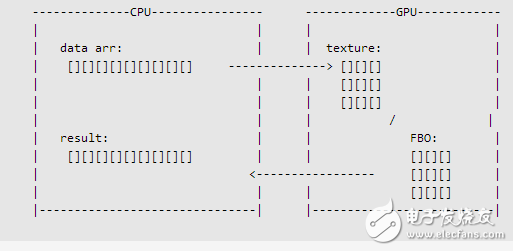
GPGPU 概念
1: 數組 = 紋理
一維數組是本地CPU最基本的數據排列方式,多維的數組則是通過對一個很大的一維數組的基準入口進行坐標偏移來訪問的(至少目前大多數的編譯器都是這樣做的)。一個小例子可以很好說明這一點,那就是一個MxN維的數組 a[i][j] = a[i*M+j];我們可能把一個多維數組,映射到一個一維數組中去。這些數組我開始索引都被假定為0;
而對于GPU,最基本的數據排列方式,是二維數組。一維和三維的數組也是被支持的,但本教程的技術不能直接使用。數組在GPU內存中我們把它叫做紋理或者是紋理樣本。紋理的最大尺寸在GPU中是有限定的。每個維度的允許最大值,通過以下一小段代碼便可能查詢得到,這些代碼能正確運行,前提是OpenGL的渲染上下文必須被正確初始化。
[cpp] view plaincopyint maxtexsize;
glGetIntegerv(GL_MAX_TEXTURE_SIZE,&maxtexsize);
printf(“GL_MAX_TEXTURE_SIZE, %d ”,maxtexsize);
就目前主流的顯卡來說,這個值一般是2048或者4096每個維度,值得提醒大家的就是:一塊顯卡,雖然理論上講它可以支持4096*4096*4096的三維浮點紋理,但實際中受到顯卡內存大小的限制,一般來說,它達不到這個數字。
在CPU中,我們常會討論到數組的索引,而在GPU中,我們需要的是紋理坐標,有了紋理坐標才可以訪問紋理中每個數據的值。而要得到紋理坐標,我們又必須先得到紋理中心的地址。
傳統上講,GPU是可以四個分量的數據同時運算的,這四個分量也就是指紅、綠、藍、alpha(RGBA)四個顏色通道。稍后的章節中,我將會介紹如何使用顯卡這一并行運算的特性,來實現我們想要的硬件加速運算。
在CPU上生成數組
讓我們來回顧一下前面所要實現的運算:也就是給定兩個長度為N的數組,現在要求兩數組的加權和y=y+alpha*x,我們現在需要兩個數組來保存每個浮點數的值,及一個記錄alpha值的浮點數。
[cpp] view plaincopyfloat* dataY = (float*)malloc(N*sizeof(float)); float* dataX = (float*)malloc(N*sizeof(float)); float alpha;
雖然我們的實際運算是在GPU上運行,但我們仍然要在CPU上分配這些數組空間,并對數組中的每個元素進行初始化賦值。
在GPU上生成浮點紋理
這個話題需要比較多的解釋才行,讓我們首先回憶一下在CPU上是如何實現的,其實簡單點來說,我們就是要在GPU上建立兩個浮點數組,我們將使用浮點紋理來保存數據。
有許多因素的影響,從而使問題變得復雜起來。其中一個重要的因素就是,我們有許多不同的紋理對像可供我們選擇。即使我們排除掉一些非本地的目標,以及限定只能使用2維的紋理對像。我們依然還有兩個選擇,GL_TEXTURE_2D是傳統的OpenGL二維紋理對像,而ARB_texture_rectangle則是一個OpenGL擴展,這個擴展就是用來提供所謂的texture rectangles的。對于那些沒有圖形學背景的程序員來說,選擇后者可能會比較容易上手。texture2Ds 和 texture rectangles 在概念上有兩大不同之處。我們可以從下面這個列表來對比一下,稍后我還會列舉一些例子。

另外一個重要的影響因素就是紋理格式,我們必須謹慎選擇。在GPU中可能同時處理標量及一到四分量的向量。本教程主要關注標量及四分量向量的使用。比較簡單的情況下我們可以在中紋理中為每個像素只分配一個單精度浮點數的儲存空間,在OpenGL中,GL_LUMNANCE就是這樣的一種紋理格式。但是如果我們要想使用四個通道來作運算的話,我們就可以采用GL_RGBA這種紋理格式。使用這種紋理格式,意味著我們會使用一個像素數據來保存四個浮點數,也就是說紅、綠、藍、alpha四個通道各占一個32位的空間,對于LUMINANCE格式的紋理,每個紋理像素只占有32位4個字節的顯存空間,而對于RGBA格式,保存一個紋理像素需要的空間是4*32=128位,共16個字節。
接下來的選擇,我們就要更加小心了。在OpenGL中,有三個擴展是真正接受單精度浮點數作為內部格式的紋理的。分別是:NV_float_buffer,ATI_texture_float 和ARB_texture_float.每個擴展都就定義了一組自已的列舉參數及其標識,如:(GL_FLOAT_R32_NV) ,( 0x8880),在程序中使用不同的參數,可以生成不同格式的紋理對像,下面會作詳細描述。
在這里,我們只對其中兩個列舉參數感興趣,分別是GL_FLOAT_R32_NV和GL_FLOAT_RGBA32_NV. 前者是把每個像素保存在一個浮點值中,后者則是每個像素中的四個分量分別各占一個浮點空間。這兩個列舉參數,在另外兩個擴展(ATI_texture_float andARB_texture_float )中也分別有其對應的名稱:GL_LUMINANCE_FLOAT32_ATI,GL_RGBA_FLOAT32_ATI 和 GL_LUMINANCE32F_ARB,GL_RGBA32F_ARB 。在我看來,他們名稱不同,但作用都是一樣的,我想應該是多個不同的參數名稱對應著一個相同的參數標識。至于選擇哪一個參數名,這只是看個人的喜好,因為它們全部都既支持NV顯卡也支持ATI的顯卡。
最后還有一個要解決的問題就是,我們如何把CPU中的數組元素與GPU中的紋理元素一一對應起來。這里,我們采用一個比較容易想到的方法:如果紋理是LUMINANCE格式,我們就把長度為N的數組,映射到一張大小為sqrt(N) x sqrt(N)和紋理中去(這里規定N是剛好能被開方的)。如果采用RGBA的紋理格式,那么N個長度的數組,對應的紋理大小就是sqrt(N/4) x sqrt(N/4),舉例說吧,如果N=1024^2,那么紋理的大小就是512*512 。
以下的表格總結了我們上面所討論的問題,作了一下分類,對應的GPU分別是: NVIDIA GeForce FX (NV3x), GeForce 6 and 7 (NV4x, G7x) 和 ATI.
(*) Warning: 這些格式作為紋理是被支持的,但是如果作為渲染對像,就不一定全部都能夠得到良好的支持(seebelow)。
講完上面的一大堆基礎理論這后,是時候回來看看代碼是如何實現的。比較幸運的是,當我們弄清楚了要用那些紋理對像、紋理格式、及內部格式之后,要生成一個紋理是很容易的。
[cpp] view plaincopy// create a new texture name
GLuint texID;
glGenTextures (1, &texID);
// bind the texture name to a texture target
glBindTexture(texture_target,texID);
// turn off filtering and set proper wrap mode
// (obligatory for float textures atm)
glTexParameteri(texture_target, GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(texture_target, GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(texture_target, GL_TEXTURE_WRAP_S, GL_CLAMP);
glTexParameteri(texture_target, GL_TEXTURE_WRAP_T, GL_CLAMP);
// set texenv to replace instead of the default modulate
glTexEnvi(GL_TEXTURE_ENV, GL_TEXTURE_ENV_MODE, GL_REPLACE);
// and allocate graphics memory
glTexImage2D(texture_target, 0, internal_format,
texSize, texSize, 0, texture_format, GL_FLOAT, 0);
讓我們來消化一下上面這段代碼的最后那個OpenGL函數,我來逐一介紹一下它每個參數:第一個參數是紋理對像,上面已經說過了;第二個參數是0,是告訴GL不要使用多重映像紋理。接下來是內部格式及紋理大小,上面也說過了,應該清楚了吧。第六個參數是也是0,這是用來關閉紋理邊界的,這里不需要邊界。接下來是指定紋理格式,選擇一種你想要的格式就可以了。對于參數GL_FLOAT,我們不要被它表面的意思迷惑,它并不會影響我們所保存在紋理中的浮點數的精度。其實它只與CPU方面有關系,目的就是要告訴GL稍后將要傳遞過去的數據是浮點型的。最后一個參數還是0,意思是生成一個紋理,但現在不給它指定任何數據,也就是空的紋理。該函數的調用必須按上面所說的來做,才能正確地生成一個合適的紋理。上面這段代碼,和CPU里分配內存空間的函數malloc(),功能上是很相像的,我們可能用來對比一下。
最后還有一點要提醒注意的:要選擇一個適當的數據排列映射方式。這里指的就是紋理格式、紋理大小要與你的CPU數據相匹配,這是一個非常因地制宜的問題,根據解決的問題不同,其相應的處理問題方式也不同。從經驗上看,一些情況下,定義這樣一個映射方式是很容易的,但某些情況下,卻要花費你大量的時間,一個不理想的映射方式,甚至會嚴重影響你的系統運行。
數組索引與紋理坐標的一一對應關系
在后面的章節中,我們會講到如何通過一個渲染操作,來更新我們保存在紋理中的那些數據。在我們對紋理進行運算或存取的時候,為了能夠正確地控制每一個數據元素,我們得選擇一個比較特殊的投影方式,把3D世界映射到2D屏幕上(從世界坐標空間到屏幕設備坐標空間),另外屏幕像素與紋理元素也要一一對應。這種關系要成功,關鍵是要采用正交投影及合適的視口。這樣便能做到幾何坐標(用于渲染)、紋理坐標(用作數據輸入)、像素坐標(用作數據輸出)三者一一對應。有一個要提醒大家的地方:如果使用texture2D,我們則須要對紋理坐標進行適當比例的縮放,讓坐標的值在0到1之間,前面有相關的說明。
為了建立一個一一對應的映射,我們把世界坐標中的Z坐標設為0,把下面這段代碼加入到initFBO()這個函數中
[cpp] view plaincopy// viewport for 1:1 pixel=texel=geometry mapping
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
gluOrtho2D(0.0, texSize, 0.0, texSize);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
glViewport(0, 0, texSize, texSize);
使用紋理作為渲染對像
其實一個紋理,它不僅可以用來作數據輸入對像,也還可以用作數據輸出對像。這也是提高GPU運算效率和關鍵所在。通過使用 framebuffer_object這個擴展,我們可以把數據直接渲染輸出到一個紋理上。但是有一個缺點:一個紋理對像不能同時被讀寫,也就是說,一個紋理,要么是只讀的,要么就是只寫的。顯卡設計的人提供這樣一個解釋:GPU在同一時間段內會把渲染任務分派到幾個通道并行運行, 它們之間都是相互獨立的(稍后的章節會對這個問題作詳細的討論)。如果我們允許對一個紋理同時進行讀寫操作的話,那我們需要一個相當復雜的邏輯算法來解決讀寫沖突的問題, 即使在芯片邏輯上可以做到,但是對于GPU這種沒有數據安全性約束的處理單元來說,也是沒辦法把它實現的,因為GPU并不是基von Neumann的指令流結構,而是基于數據流的結構。因此在我們的程序中,我們要用到3個紋理,兩個只讀紋理分別用來保存輸入數組x,y。一個只寫紋理用來保存運算結果。用這種方法意味著要把先前的運算公式:y = y + alpha * x 改寫為:y_new = y_old + alpha * x.
FBO 擴展提供了一個簡單的函數來實現把數據渲染到紋理。為了能夠使用一個紋理作為渲染對像,我們必須先把這個紋理與FBO綁定,這里假設離屏幀緩沖已經被指定好了。
[cpp] view plaincopyglFramebufferTexture2DEXT(GL_FRAMEBUFFER_EXT, GL_COLOR_ATTACHMENT0_EXT, texture_target, texID, 0);
第一個參數的意思是很明顯的。第二個參數是定義一個綁定點(每個FBO最大可以支持四個不同的綁定點,當然,不同的顯卡對這個最大綁定數的支持不一樣,可以用GL_MAX_COLOR_ATTACHMENTS_EXT來查詢一下)。第三和第四個參數應該清楚了吧,它們是實際紋理的標識。最后一個參數指的是使用多重映像紋理,這里沒有用到,因此設為0。
為了能成功綁定一紋理,在這之前必須先用glTexImage2D()來對它定義和分配空間。但不須要包含任何數據。我們可以把FBO想像為一個數據結構的指針,為了能夠對一個指定的紋理直接進行渲染操作,我們須要做的就調用OpenGL來給這些指針賦以特定的含義。
不幸的是,在FBO的規格中,只有GL_RGB和GL_RGBA兩種格式的紋理是可以被綁定為渲染對像的(后來更新這方面得到了改進),LUMINANCE這種格式的綁定有希望在后繼的擴展中被正式定義使用。在我定本教程的時候,NVIDIA的硬件及驅動已經對這個全面支持,但是只能結會對應的列舉參數NV_float_buffer一起來使用才行。換句話說,紋理中的浮點數的格式與渲染對像中的浮點數格式有著本質上的區別。
下面這個表格對目前不同的顯卡平臺總結了一下,指的是有哪些紋理格式及紋理對像是可能用來作為渲染對像的,(可能還會有更多被支持的格式,這里只關心是浮點數的紋理格式):
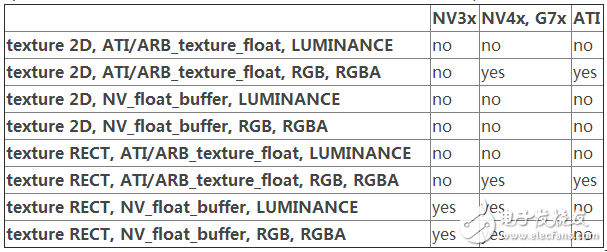
列表中最后一行所列出來的格式在目前來說,不能被所有的GPU移植使用。如果你想采用LUMINANCE格式,你必須使用ractangles紋理,并且只能在NVIDIA的顯卡上運行。想要寫出兼容NVIDIA及ATI兩大類顯卡的代是可能的,但只支持NV4x以上。幸運的是要修改的代碼比較少,只在一個switch開關,便能實現代碼的可移植性了。相信隨著ARB新版本擴展的發布,各平臺之間的兼容性將會得到進一步的提高,到時候各種不同的格式也可能相互調用了。
把數據從CPU的數組傳輸到GPU的紋理
為了把數據傳輸到紋理中去,我們必須綁定一個紋理作為紋理目標,并通過一個GL函數來發送要傳輸的數據。實際上就是把數據的首地址作為一個參數傳遞給該涵數,并指定適當的紋理大小就可以了。如果用LUMINANCE格式,則意味著數組中必須有texSize x texSize個元數。而RGBA格式,則是這個數字的4倍。注意的是,在把數據從內存傳到顯卡的過程中,是全完不需要人為來干預的,由驅動來自動完成。一但傳輸完成了,我們便可能對CPU上的數據作任意修改,這不會影響到顯卡中的紋理數據。 而且我們下次再訪問該紋理的時候,它依然是可用的。在NVIDIA的顯卡中,以下的代碼是得到硬件加速的。
[cpp] view plaincopyglBindTexture(texture_target, texID);
glTexSubImage2D(texture_target,0,0,0,texSize,texSize,
texture_format,GL_FLOAT,data);
這里三個值是0的參數,是用來定義多重映像紋理的,由于我們這里要求一次把整個數組傳輸一個紋理中,不會用到多重映像紋理,因此把它們都關閉掉。
以上是NVIDIA顯卡的實現方法,但對于ATI的顯卡,以下的代碼作為首選的技術。在ATI顯卡中,要想把數據傳送到一個已和FBO綁定的紋理中的話,只需要把OpenGL的渲染目標改為該綁定的FBO對像就可以了。
glDrawBuffer(GL_COLOR_ATTACHMENT0_EXT);glRasterPos2i(0,0);glDrawPixels(texSize,texSize,texture_format,GL_FLOAT,data);
第一個函數是改變輸出的方向,第二個函數中我們使用了起點作為參與點,因為我們在第三個函數中要把整個數據塊都傳到紋理中去。
兩種情況下,CPU中的數據都是以行排列的方式映射到紋理中去的。更詳細地說,就是:對于RGBA格式,數組中的前四個數據,被傳送到紋理的第一個元素的四個分量中,分別與R,G,B,A分量一一對應,其它類推。而對于LUMINANCE 格式的紋理,紋理中第一行的第一個元素,就對應數組中的第一個數據。其它紋理元素,也是與數組中的數據一一對應的。
把數據從GPU紋理,傳輸到CPU的數組
這是一個反方向的操作,那就是把數據從GPU傳輸回來,存放在CPU的數組上。同樣,有兩種不同的方法可供我們選擇。傳統上,我們是使用OpenGL獲取紋理的方法,也就是綁定一個紋理目標,然后調用glGetTexImage()這個函數。這些函數的參數,我們在前面都有見過。
glBindTexture(texture_target,texID);glGetTexImage(texture_target,0,texture_format,GL_FLOAT,data);
但是這個我們將要讀取的紋理,已經和一個FBO對像綁定的話,我們可以采用改變渲染指針方向的技術來實現。
glReadBuffer(GL_COLOR_ATTACHMENT0_EXT);glReadPixels(0,0,texSize,texSize,texture_format,GL_FLOAT,data);
由于我們要讀取GPU的整個紋理,因此這里前面兩個參數是0,0。表示從0起始點開始讀取。該方法是被推薦使用的。
一個忠告:比起在GPU內部的傳輸來說,數據在主機內存與GPU內存之間相互傳輸,其花費的時間是巨大的,因此要謹慎使用。由其是從CPU到GPU的逆向傳輸。
在前面“ 當前顯卡設備運行的問題” 中 提及到該方面的問題。
一個簡單的例子
[cpp] view plaincopy#include 《stdio.h》
#include 《stdlib.h》
#include 《GL/glew.h》
#include 《GL/glut.h》
int main(int argc, char **argv) {
// 這里聲明紋理的大小為:teSize;而數組的大小就必須是texSize*texSize*4
int texSize = 2;
int i;
// 生成測試數組的數據
float* data = (float*)malloc(4*texSize*texSize*sizeof(float));
float* result = (float*)malloc(4*texSize*texSize*sizeof(float));
for (i=0; i《texSize*texSize*4; i++)
data[i] = (i+1.0)*0.01F;
// 初始化OpenGL的環境
glutInit (&argc, argv);
glutCreateWindow(“TEST1”);
glewInit();
// 視口的比例是 1:1 pixel=texel=data 使得三者一一對應
glMatrixMode(GL_PROJECTION);
glLoadIdentity();
gluOrtho2D(0.0,texSize,0.0,texSize);
glMatrixMode(GL_MODELVIEW);
glLoadIdentity();
glViewport(0,0,texSize,texSize);
// 生成并綁定一個FBO,也就是生成一個離屏渲染對像
GLuint fb;
glGenFramebuffersEXT(1,&fb);
glBindFramebufferEXT(GL_FRAMEBUFFER_EXT,fb);
// 生成兩個紋理,一個是用來保存數據的紋理,一個是用作渲染對像的紋理
GLuint tex,fboTex;
glGenTextures (1, &tex);
glGenTextures (1, &fboTex);
glBindTexture(GL_TEXTURE_RECTANGLE_ARB,fboTex);
// 設定紋理參數
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_WRAP_S, GL_CLAMP);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_WRAP_T, GL_CLAMP);
// 這里在顯卡上分配FBO紋理的貯存空間,每個元素的初始值是0;
glTexImage2D(GL_TEXTURE_RECTANGLE_ARB,0,GL_RGBA32F_ARB,
texSize,texSize,0,GL_RGBA,GL_FLOAT,0);
// 分配數據紋理的顯存空間
glBindTexture(GL_TEXTURE_RECTANGLE_ARB,tex);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_MIN_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_MAG_FILTER, GL_NEAREST);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_WRAP_S, GL_CLAMP);
glTexParameteri(GL_TEXTURE_RECTANGLE_ARB,
GL_TEXTURE_WRAP_T, GL_CLAMP);
glTexEnvf(GL_TEXTURE_ENV,GL_TEXTURE_ENV_COLOR,GL_DECAL);
glTexImage2D(GL_TEXTURE_RECTANGLE_ARB,0,GL_RGBA32F_ARB,
texSize,texSize,0,GL_RGBA,GL_FLOAT,0);
//把當前的FBO對像,與FBO紋理綁定在一起
glFramebufferTexture2DEXT(GL_FRAMEBUFFER_EXT,
GL_COLOR_ATTACHMENT0_EXT,
GL_TEXTURE_RECTANGLE_ARB,fboTex,0);
// 把本地數據傳輸到顯卡的紋理上。
glBindTexture(GL_TEXTURE_RECTANGLE_ARB,tex);
glTexSubImage2D(GL_TEXTURE_RECTANGLE_ARB,0,0,0,texSize,texSize,
GL_RGBA,GL_FLOAT,data);
//--------------------begin-------------------------
//以下代碼是渲染一個大小為texSize * texSize矩形,
//其作用就是把紋理中的數據,經過處理后,保存到幀緩沖中去,
//由于用到了離屏渲染,這里的幀緩沖區指的就是FBO紋理。
//在這里,只是簡單地把數據從紋理直接傳送到幀緩沖中,
//沒有對這些流過GPU的數據作任何處理,但是如果我們會用CG、
//GLSL等高級著色語言,對顯卡進行編程,便可以在GPU中
//截獲這些數據,并對它們進行任何我們所想要的復雜運算。
//這就是GPGPU技術的精髓所在。問題討論:www.physdev.com
glColor4f(1.00f,1.00f,1.00f,1.0f);
glBindTexture(GL_TEXTURE_RECTANGLE_ARB,tex);
glEnable(GL_TEXTURE_RECTANGLE_ARB);
glBegin(GL_QUADS);
glTexCoord2f(0.0, 0.0);
glVertex2f(0.0, 0.0);
glTexCoord2f(texSize, 0.0);
glVertex2f(texSize, 0.0);
glTexCoord2f(texSize, texSize);
glVertex2f(texSize, texSize);
glTexCoord2f(0.0, texSize);
glVertex2f(0.0, texSize);
glEnd();
//--------------------end------------------------
// 從幀緩沖中讀取數據,并把數據保存到result數組中。
glReadBuffer(GL_COLOR_ATTACHMENT0_EXT);
glReadPixels(0, 0, texSize, texSize,GL_RGBA,GL_FLOAT,result);
// 顯示最終的結果
printf(“Data before roundtrip: ”);
for (i=0; i《texSize*texSize*4; i++)
printf(“%f ”,data[i]);
printf(“Data after roundtrip: ”);
for (i=0; i《texSize*texSize*4; i++)
printf(“%f ”,result[i]);
// 釋放本地內存
free(data);
free(result);
// 釋放顯卡內存
glDeleteFramebuffersEXT (1,&fb);
glDeleteTextures (1,&tex);
glDeleteTextures(1,&fboTex);
return 0;
}
現在是時候讓我們回頭來看一下前面要解決的問題,我強烈建議在開始一個新的更高級的話題之前,讓我們先弄一個顯淺的例子來實踐一下。下面通過一個小的程序,嘗試著使用各種不同的紋理格式,紋理對像以及內部格式,來把數據發送到GPU,然后再把數據從GPU取回來,保存在CPU的另一個數組中。在這里,兩個過程都沒有對數據作任何運算修該,目的只是看一下數據GPU和CPU之間相互傳輸,所需要使用到的技術及要注意的細節。也就是把前面提及到的幾個有迷惑性的問題放在同一個程序中來運行一下。在稍后的章節中將會詳細討論如何來解決這些可能會出現的問題。
由于趕著要完成整個教程,這里就只寫了一個最為簡單的小程序,采用rectangle紋理、ARB_texture_float作紋理對像并且只能在NVIDIA的顯卡上運行。
你可以在這里下載到為ATI顯卡寫的另一個版本。

![]()
以上代碼是理解GPU編程的基礎,如果你完全看得懂,并且能對這代碼作簡單的修改運用的話,那恭喜你,你已經向成功邁進了一大步,并可以繼續往下看,走向更深入的學習了。但如看不懂,那回頭再看一編吧。
Back to top












 工商網監
工商網監
評論