 電子發(fā)燒友App
電子發(fā)燒友App


隨著計(jì)算機(jī)應(yīng)用的日益普及,用戶對(duì)計(jì)算機(jī)的處理能力的需求成指數(shù)級(jí)增長(zhǎng)。為了滿足用戶的需求,處理器生產(chǎn)廠商采用了諸如超流水、分支預(yù)測(cè)、超標(biāo)量、亂序執(zhí)行及緩存等技術(shù)以提高處理器的性能。但是這些技術(shù)的采用增加了微處理器的復(fù)雜性,帶來(lái)了諸如材料、功耗、光刻、電磁兼容性等一系列問題。因此處理器設(shè)計(jì)人員開始尋找新的途徑來(lái)提高處理器的性能。Intel公司于2002年底推出了超線程技術(shù),通過(guò)共享處理器的執(zhí)行資源,提高CPU的利用率,讓處理單元獲得更高的吞吐量。
1 超線程技術(shù)背景
傳統(tǒng)的處理器內(nèi)部存在著多種并行操作方式。①指令級(jí)并行ILP(Instruction Level Paramllelism):同時(shí)執(zhí)行幾條指令,單CPU就能完成。但是,傳統(tǒng)的單CPU處理器只能同時(shí)執(zhí)行一個(gè)線程,很難保證CPU資源得到100%的利用,性能提高只能通過(guò)提升時(shí)鐘頻率和改進(jìn)架構(gòu)來(lái)實(shí)現(xiàn)。②線程級(jí)并行TLP(Thread Level
Paramllesim):可以同時(shí)執(zhí)行多個(gè)線程,但是需要多處理器系統(tǒng)的支持,通過(guò)增加CPU的數(shù)量來(lái)提高性能。
超線程微處理器將同時(shí)多線程技術(shù)SMT(Simultaneous Multi-Threading)引入Intel體系結(jié)構(gòu),支持超線程技術(shù)的操作系統(tǒng)將一個(gè)物理處理器視為兩個(gè)邏輯處理器,并且為每個(gè)邏輯處理器分配一個(gè)線程運(yùn)行。物理處理器在兩個(gè)邏輯處理器之間分配高速緩存、執(zhí)行單元、總線等執(zhí)行資源,讓暫時(shí)閑置的運(yùn)算單元去執(zhí)行其他線程代碼,從而最大限度地提升CPU資源的利用率。
Intel 超線程技術(shù)通過(guò)復(fù)制、劃分、共享Intel的Netburst微架構(gòu)的資源讓一個(gè)物理CPU中具有兩個(gè)邏輯CPU。(1)復(fù)制的資源:每個(gè)邏輯CPU都維持一套完整的體系結(jié)構(gòu)狀態(tài),包括通用寄存器、控制寄存器、高級(jí)可編程寄存器(APIC)以及一些機(jī)器狀態(tài)寄存器,體系結(jié)構(gòu)狀態(tài)對(duì)程序或線程流進(jìn)行跟蹤。從軟件的角度,一旦體系結(jié)構(gòu)狀態(tài)被復(fù)制,就可以將一個(gè)物理CPU視為兩個(gè)邏輯CPU。(2)劃分的資源:包括重定序(re-order)緩沖、Load/Store緩沖、隊(duì)列等。劃分的資源在多任務(wù)模式時(shí)分給兩個(gè)邏輯CPU使用,在單任務(wù)模式時(shí)合并起來(lái)給一個(gè)邏輯CPU使用。(3)共享的資源:包括cache及執(zhí)行單元等,邏輯CPU共享物理CPU的執(zhí)行單元進(jìn)行加、減、取數(shù)等操作。
在線程調(diào)度時(shí),體系結(jié)構(gòu)狀態(tài)對(duì)程序或線程流進(jìn)行跟蹤,各項(xiàng)工作(包括加、乘、加載等)由執(zhí)行資源(處理器上的單元)負(fù)責(zé)完成。每個(gè)邏輯處理器可以單獨(dú)對(duì)中斷作出響應(yīng)。第一個(gè)邏輯處理器跟蹤一個(gè)線程時(shí),第二個(gè)邏輯處理器可以同時(shí)跟蹤另一個(gè)線程。例如,當(dāng)一個(gè)邏輯處理器在執(zhí)行浮點(diǎn)運(yùn)算時(shí),另一個(gè)邏輯處理器可以執(zhí)行加法運(yùn)算和加載操作。擁有超線程技術(shù)的CPU可以同時(shí)執(zhí)行處理兩個(gè)線程,它可以將來(lái)自兩個(gè)線程的指令同時(shí)發(fā)送到處理器內(nèi)核執(zhí)行。處理器內(nèi)核采用亂序指令調(diào)度并發(fā)執(zhí)行兩個(gè)線程,以確保其執(zhí)行單元在各時(shí)鐘周期均處于運(yùn)行狀態(tài)。
圖1和圖2分別為傳統(tǒng)的雙處理器系統(tǒng)和支持超線程的雙處理器系統(tǒng)。傳統(tǒng)的雙處理器系統(tǒng)中,每個(gè)處理器有一套獨(dú)立的體系結(jié)構(gòu)狀態(tài)和處理器執(zhí)行資源,每個(gè)處理器上只能同時(shí)執(zhí)行一個(gè)線程。支持超線程的雙處理器系統(tǒng)中,每個(gè)處理器有兩套獨(dú)立體系結(jié)構(gòu)狀態(tài),可以獨(dú)立地響應(yīng)中斷。

2 Linux超線程感知調(diào)度優(yōu)化
Linux從2.4.17版開始支持超線程技術(shù),傳統(tǒng)的Linux O(1)調(diào)度器不能區(qū)分物理CPU和邏輯CPU,因此不能充分利用超線程處理器的特性。Ingo Monlar編寫了“HT-aware scheduler patch”,針對(duì)超線程技術(shù)對(duì)O(1)調(diào)度器進(jìn)行了調(diào)度算法優(yōu)化:優(yōu)先安排線程在空閑的物理CPU的邏輯CPU上運(yùn)行,避免資源競(jìng)爭(zhēng)帶來(lái)的性能下降;在線程調(diào)度時(shí)考慮了在兩個(gè)邏輯CPU之間進(jìn)行線程遷移的開銷遠(yuǎn)遠(yuǎn)小于物理CPU之間的遷移開銷以及邏輯CPU共享cache等資源的特性。這些優(yōu)化的相關(guān)算法被Linux的后期版本所吸收,具體如下:
(1)共享運(yùn)行隊(duì)列
在對(duì)稱多處理SMP(Symmetrical Multi-Processing)環(huán)境中,O(1)調(diào)度器為每個(gè)CPU分配了一個(gè)運(yùn)行隊(duì)列,避免了多CPU共用一個(gè)運(yùn)行隊(duì)列帶來(lái)的資源競(jìng)爭(zhēng)。Linux會(huì)將超線程CPU中的兩個(gè)邏輯CPU視為SMP的兩個(gè)獨(dú)立CPU,各維持一個(gè)運(yùn)行隊(duì)列。但是這兩個(gè)邏輯CPU共享cache等資源,沒有體現(xiàn)超線程CPU的特性。因此引入了共享運(yùn)行隊(duì)列的概念。HT-aware scheduler patch在運(yùn)行隊(duì)列struct runqueue結(jié)構(gòu)中增加了nr_cpu和cpu兩個(gè)屬性,nr_cpu記錄物理CPU中的邏輯CPU數(shù)目,CPU則指向同屬CPU(同一個(gè)物理CPU上的另一個(gè)邏輯CPU)的運(yùn)行隊(duì)列,如圖3所示。

在Linux中通過(guò)調(diào)用sched_map_runqueue( )函數(shù)實(shí)現(xiàn)兩個(gè)邏輯CPU的運(yùn)行隊(duì)列的合并。sched_map_runqueue( )首先會(huì)查詢系統(tǒng)的CPU隊(duì)列,通過(guò)phys_proc_id(記錄邏輯CPU所屬的物理CPU的ID)判斷當(dāng)前CPU的同屬邏輯CPU。如果找到同屬邏輯CPU,則將當(dāng)前CPU運(yùn)行隊(duì)列的cpu屬性指向同屬邏輯CPU的運(yùn)行隊(duì)列。
(2)支持“被動(dòng)的”負(fù)載均衡
用中斷驅(qū)動(dòng)的均衡操作必須針對(duì)各個(gè)物理 CPU,而不是各個(gè)邏輯 CPU。否則可能會(huì)出現(xiàn)兩種情況:一個(gè)物理 CPU 運(yùn)行兩個(gè)任務(wù),而另一個(gè)物理 CPU 不運(yùn)行任務(wù);現(xiàn)有的調(diào)度程序不會(huì)將這種情形認(rèn)為是“失衡的”。在調(diào)度程序看來(lái),似乎是第一個(gè)物理處理器上的兩個(gè) CPU運(yùn)行1-1任務(wù),而第二個(gè)物理處理器上的兩個(gè) CPU運(yùn)行0-0任務(wù)。
在2.6.0版之前,Linux只有通過(guò)load_balance( )函數(shù)才能進(jìn)行CPU之間負(fù)載均衡。當(dāng)某個(gè)CPU負(fù)載過(guò)輕而另一個(gè)CPU負(fù)載較重時(shí),系統(tǒng)會(huì)調(diào)用load_balance( )函數(shù)從重載CPU上遷移線程到負(fù)載較輕的CPU上。只有系統(tǒng)最繁忙的CPU的負(fù)載超過(guò)當(dāng)前CPU負(fù)載的 25% 時(shí)才進(jìn)行負(fù)載平衡。找到最繁忙的CPU(源CPU)之后,確定需要遷移的線程數(shù)為源CPU負(fù)載與本CPU負(fù)載之差的一半,然后按照從 expired 隊(duì)列到 active 隊(duì)列、從低優(yōu)先級(jí)線程到高優(yōu)先級(jí)線程的順序進(jìn)行遷移。
在超線程系統(tǒng)中進(jìn)行負(fù)載均衡時(shí),如果也是將邏輯CPU等同于SMP環(huán)境中的單個(gè)CPU進(jìn)行調(diào)度,則可能會(huì)將線程遷移到同一個(gè)物理CPU的兩個(gè)邏輯CPU上,從而導(dǎo)致物理CPU的負(fù)載過(guò)重。
在2.6.0版之后,Linux開始支持NUMA(Non-Uniform Memory Access Architecture)體系結(jié)構(gòu)。進(jìn)行負(fù)載均衡時(shí)除了要考慮單個(gè)CPU的負(fù)載,還要考慮NUMA下各個(gè)節(jié)點(diǎn)的負(fù)載情況。
Linux的超線程調(diào)度借鑒NUMA的算法,將物理CPU當(dāng)作NUMA中的一個(gè)節(jié)點(diǎn),并且將物理CPU中的邏輯CPU映射到該節(jié)點(diǎn),通過(guò)運(yùn)行隊(duì)列中的node_nr_running屬性記錄當(dāng)前物理CPU的負(fù)載情況。
Linux通過(guò)balance_node( )函數(shù)進(jìn)行物理CPU之間的負(fù)載均衡。物理CPU間的負(fù)載平衡作為rebalance_tick( )函數(shù)中的一部分在 load_balance( )之前啟動(dòng),避免了出現(xiàn)一個(gè)物理CPU運(yùn)行1-1任務(wù),而第二個(gè)物理CPU運(yùn)行0-0任務(wù)的情況。balance_node( )函數(shù)首先調(diào)用 find_busiest_node( )找到系統(tǒng)中最繁忙的節(jié)點(diǎn),然后在該節(jié)點(diǎn)和當(dāng)前CPU組成的CPU集合中進(jìn)行 load_balance( ),把最繁忙的物理CPU中的線程遷移到當(dāng)前CPU上。之后rebalance_tick( )函數(shù)再調(diào)用load_balance(工作集為當(dāng)前的物理CPU中的所有邏輯CPU)進(jìn)行邏輯CPU之間的負(fù)載均衡。
(3)支持“主動(dòng)的”負(fù)載均衡
當(dāng)一個(gè)邏輯 CPU 變成空閑時(shí),可能造成一個(gè)物理CPU的負(fù)載失衡。例如:系統(tǒng)中有兩個(gè)物理CPU,一個(gè)物理CPU上運(yùn)行一個(gè)任務(wù)并且剛剛結(jié)束,另一個(gè)物理CPU上正在運(yùn)行兩個(gè)任務(wù),此時(shí)出現(xiàn)了一個(gè)物理CPU空閑而另一個(gè)物理CPU忙的現(xiàn)象。
Linux中通過(guò)active_load_balance( )函數(shù)進(jìn)行主動(dòng)的負(fù)載均衡,active_load_balance( )函數(shù)用于在所有的邏輯CPU中查詢?cè)揅PU的忙閑情況。如果發(fā)現(xiàn)由于超線程引起的負(fù)載不平衡(一個(gè)物理CPU的兩個(gè)邏輯CPU都空閑,另一個(gè)物理CPU的兩個(gè)邏輯CPU都在運(yùn)行兩個(gè)線程),則喚醒一個(gè)需要遷移的線程,將它從一個(gè)忙的物理CPU遷移到一個(gè)空閑的物理CPU上。
active_load_balance( )通過(guò)調(diào)用cpu_rq( )函數(shù)得到每一個(gè)邏輯CPU上的運(yùn)行隊(duì)列。如果運(yùn)行隊(duì)列上的當(dāng)前運(yùn)行線程為idle線程,則說(shuō)明當(dāng)前邏輯CPU為空閑;如果發(fā)現(xiàn)一個(gè)物理CPU兩個(gè)邏輯CPU都為空閑,而另一個(gè)物理CPU中的兩個(gè)邏輯CPU的運(yùn)行隊(duì)列為繁忙的情況,則說(shuō)明存在超線程引起的負(fù)載不均衡。這時(shí)當(dāng)前CPU會(huì)喚醒遷移服務(wù)線程(migration_thread)來(lái)完成負(fù)載均衡的線程遷移。
(4)支持超線程感知的任務(wù)挑選
在超線程處理器中,由于cache資源為兩個(gè)邏輯處理器共享,因此調(diào)度器在選取一個(gè)新任務(wù)時(shí),必須確保同組的任務(wù)盡量共享一個(gè)物理CPU,從而減少cache失效的開銷,提高系統(tǒng)的性能。而傳統(tǒng)的調(diào)度器只是簡(jiǎn)單地為邏輯CPU選取一個(gè)任務(wù),沒有考慮物理CPU的影響。
Linux進(jìn)行線程切換時(shí)會(huì)調(diào)用schedule( )函數(shù)進(jìn)行具體的操作。如果沒有找到合適的任務(wù)schedule()函數(shù),則會(huì)調(diào)度idle線程在當(dāng)前CPU上運(yùn)行。在超線程環(huán)境中Linux調(diào)度idle線程運(yùn)行之前會(huì)查詢其同屬CPU的忙閑狀況。如果同屬CPU上有等待運(yùn)行的線程,則會(huì)調(diào)用一次load_balance( )函數(shù)在兩個(gè)同屬CPU之間作一次負(fù)載均衡,將等待運(yùn)行的線程遷移到當(dāng)前CPU上,保證優(yōu)先運(yùn)行同屬CPU上的任務(wù)。
(5)支持超線程感知的CPU喚醒
傳統(tǒng)的調(diào)度器只知道當(dāng)前CPU,而不知道同屬的邏輯CPU。在超線程環(huán)境下,一個(gè)邏輯CPU正在執(zhí)行任務(wù)時(shí),其上的一個(gè)線程被喚醒了,此時(shí),如果它的同屬邏輯CPU是空閑的,則應(yīng)該在同屬邏輯CPU上運(yùn)行剛剛喚醒的任務(wù)。
Linux通過(guò)wake_up_cpu( )函數(shù)實(shí)現(xiàn)CPU喚醒,在try_o_wakeup、pull_task、move_task_away加入了wake_up_cpu( )函數(shù)的相應(yīng)調(diào)用點(diǎn)。wake_up_cpu()首先查詢當(dāng)前CPU是不是空閑的,如果當(dāng)前CPU為空閑,則調(diào)用resched_cpu( )函數(shù)啟動(dòng)調(diào)度器,將喚醒的線程調(diào)度到當(dāng)前CPU執(zhí)行;否則查找其同屬邏輯CPU。如果同屬邏輯CPU是空閑的,則將喚醒的線程調(diào)度到同屬邏輯CPU上執(zhí)行;否則比較喚醒的線程和當(dāng)前CPU上運(yùn)行的線程的優(yōu)先級(jí)。如果喚醒的線程的優(yōu)先級(jí)高,或者優(yōu)先級(jí)相等但是時(shí)間片多,則進(jìn)行線程切換,在當(dāng)前CPU上調(diào)度執(zhí)行喚醒的線程。如果上述條件都不滿足,最后比較喚醒的線程和當(dāng)前CPU的同屬邏輯CPU上運(yùn)行的線程的優(yōu)先級(jí),如果喚醒的線程的優(yōu)先級(jí)高,或者優(yōu)先級(jí)相等但是時(shí)間片多,則在同屬邏輯CPU上調(diào)度執(zhí)行喚醒的線程。
3 性能測(cè)試
Linux-2.6.0 HT-aware scheduler patch實(shí)現(xiàn)了上述超線程調(diào)度優(yōu)化。這里根據(jù)linux-2.6.0 HT-aware scheduler patch對(duì)這幾種調(diào)度優(yōu)化進(jìn)行了性能測(cè)試。
測(cè)試硬件環(huán)境:Xeon 2.2GHz處理器(支持超線程)×4,2GB SDRAM內(nèi)存。
Benchmark:(1)Volanomark是一個(gè)純Java的benchmark,專門用于測(cè)試系統(tǒng)調(diào)度器和線程環(huán)境的綜合性能。它建立一個(gè)模擬Client/Server方式的Java聊天室,通過(guò)獲取每秒平均發(fā)送的消息數(shù)來(lái)評(píng)測(cè)宿主機(jī)綜合性能(數(shù)值越大性能越好)。Volanomark測(cè)試與Java虛擬機(jī)平臺(tái)相關(guān),本文使用Sun Java SDK 1.4.2作為測(cè)試用Java平臺(tái),Volanomark版本2.5.0.9。(2)LMBench是一個(gè)用于評(píng)價(jià)系統(tǒng)綜合性能的多平臺(tái)開源benchmark,對(duì)其進(jìn)行修改后實(shí)現(xiàn)了lat_thread_ctx接口,用來(lái)測(cè)試線程的切換開銷。
圖4表明開啟超線程后Volanomark在Linux-2.6.0平臺(tái)下平均吞吐量提高了25.5%。由于Linux的O(1)內(nèi)核調(diào)度器比較好地實(shí)現(xiàn)了SMP負(fù)載均衡算法,所以在超線程環(huán)境下整個(gè)系統(tǒng)的性能也有了比較好的提升。
圖5顯示出Linux在進(jìn)行了超線程調(diào)度優(yōu)化后,在支持超線程的平臺(tái)上所獲得的性能加速比。在Linux-2.6.0加入HT-aware scheduler patch后Volanomark的平均吞吐提高了 8.5%,分別實(shí)現(xiàn)主動(dòng)負(fù)載均衡、被動(dòng)的負(fù)載均衡、CPU喚醒和任務(wù)挑選的相關(guān)代碼后,吞吐量分別提高了1.8.%、2.5%、2.3%和2.1%。


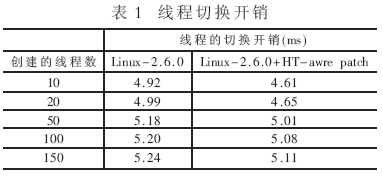
使用Lmbench創(chuàng)建10~150個(gè)線程,在不同的負(fù)載條件下測(cè)試線程的切換開銷。表1的數(shù)據(jù)顯示HT-aware scheduler patch可以將線程的切換開銷減少3%~7%。數(shù)據(jù)顯示:在輕負(fù)載情況下,系統(tǒng)可以獲得更多的加速比。這是因?yàn)楸粍?dòng)的負(fù)載均衡以及主動(dòng)的負(fù)載均衡只有在系統(tǒng)有CPU空閑時(shí)才能發(fā)揮比較好的作用。

4 相關(guān)工作和展望
采用支持超線程技術(shù)的Linux可以獲得較大的性能提升。但是其調(diào)度算法還要根據(jù)實(shí)際的應(yīng)用進(jìn)一步研究。參考文獻(xiàn)[7]中提出了用“Symbiosis”概念來(lái)衡量多個(gè)線程在SMT環(huán)境中同時(shí)執(zhí)行的有效性。參考文獻(xiàn)[8]中提出了線程敏感的調(diào)度算法,用一組硬件性能計(jì)數(shù)器計(jì)算兩個(gè)邏輯CPU上運(yùn)行不同作業(yè)子集的執(zhí)行信息,利用這些信息來(lái)預(yù)測(cè)不同作業(yè)子集的執(zhí)行性能,并選擇具有最好預(yù)測(cè)性能的作業(yè)子集調(diào)度同一個(gè)物理CPU執(zhí)行。參考文獻(xiàn)[9]中主要研究了適合SMT 結(jié)構(gòu)并考慮作業(yè)優(yōu)先級(jí)的調(diào)度器。研究結(jié)果表明,這些調(diào)度算法能有效地提高超線程系統(tǒng)的性能。
Intel的超線程技術(shù)是其企業(yè)產(chǎn)品線中的重要特征,并將會(huì)集成到越來(lái)越多的產(chǎn)品中,它標(biāo)志著Intel微處理器一個(gè)新的時(shí)代:從指令級(jí)并行到線程級(jí)并行,這樣可使微處理器運(yùn)行模式與多線程應(yīng)用的運(yùn)行模式更加接近,應(yīng)用程序可以充分利用線程級(jí)并行和指令級(jí)并行進(jìn)行優(yōu)化。隨著超線程處理器的發(fā)展,可能會(huì)出現(xiàn)操作系統(tǒng)使用處理器系統(tǒng)中硬件性能監(jiān)視器估算系統(tǒng)在某一時(shí)間段的某些性能指標(biāo),然后利用這些性能指標(biāo)來(lái)指導(dǎo)線程的調(diào)度策略。
STM32/STM8
意法半導(dǎo)體/ST/STM













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論