輝達(NVIDIA)CEO黃仁勛昨(7)日宣布,推出全球最快ARM架構應用處理器Tegra 4,該晶片采用臺積電28納米制程生產,Tegra 4將支援全球首創的運算攝影(Computational Photography)架構
2013-01-08 09:06:06 1156
1156 NVIDIA (輝達) 22日宣布推出全新 NVIDIA TITAN X 繪圖卡,採用最新Pascal架構,為有史以來最大的 GPU 芯片,并擁有 3,584 顆 CUDA 核心的創新紀錄。
2016-07-25 11:23:101850 2017年3月9日 ─ Imagination Technologies 宣布推出新一代的 PowerVR Furian 架構,這是專為滿足下一代消費類設備持續演進的圖形與運算需求所設計的全新 GPU 架構。
2017-03-10 08:06:28799 源訊、戴爾科技,技嘉科技、慧與、浪潮、聯想和超微成為首批將基于NVIDIA Grace的HGX系統用于HPC和AI的制造商 ? ? ? NVIDIA于今日宣布,多家全球領先的計算機制造商正在采用全新
2022-05-31 14:46:331024 
——2023年5月29日—— NVIDIA今天宣布推出一款新型大內存AI超級計算機——由NVIDIA? GH200 Grace Hopper超級芯片和NVIDIA NVLink? Switch System
2023-05-30 14:15:36422 
NVIDIA CUDA參考文件
2019-03-05 08:00:00
- Tegra K1 將 Cortex A15 這一先進的 ARM CPU 與第三代節電核心相結合,可實現創紀錄的性能水平和電池續航能力。 NVIDIA 的這種可變 SMP (對稱多重處理) 架構讓四個高性能
2016-05-09 15:44:19
首發極術社區如對Arm相關技術感興趣,歡迎私信 aijishu20加入技術微信群。分享內容NVIDIA Jetson是嵌入式計算平臺,具有低功耗、高性能和小體積等特點,可加速各行業的AI應用落地
2021-12-14 08:05:01
.comWechat :hrallenlinGPU高性能計算架構師 (功能驗證)- 校招/社招工作職責: * 深入了解下一代GPU架構與GPU高性能計算領域的最新功能* 與GPU架構設計者深入溝通以制定架構驗證測試計劃* 基于測試計劃和隨機
2017-09-01 17:22:28
目前NVIDIA在中國熱招解決方案架構師, 該崗位致力于協同客戶經理將NVIDIA最新的深度學習/高性能計算解決方案與技術帶給我們的客戶, 幫助客戶通過實施NVIDIA技術解決方案來提升整體效率
2017-08-25 17:02:47
使用超級計算機模擬核彈或天氣預報。對并行處理軟件進行編程非常困難。Nvidia于13年前推出了CUDA軟件平臺,現在已經是第11代,這一切都改變了。英偉達專有的CUDA軟件平臺使開發人員可以利用英偉達
2020-09-07 09:49:42
相機、智能醫療視覺、智能駕駛等行業有著極大市場需求,英碼在視頻圖像技術上有著豐富的產品開發經驗,基于多年對行業需求的深刻洞察,為行業打造了新一代AI ISP視頻處理產品和解決方案。英碼重磅推出新一代低
2022-06-07 15:12:36
導讀:日前,TDK公司宣布推出新一代PCB基板式開關電源--CUT75系列產品。CUT75系列新品是伴隨著市場對更輕薄、更高效率,更高性價比的三路輸出開關電源的需求而問世,為客戶系統的小型化
2018-09-27 15:24:27
新一代PON以及云數據中心的未來
2021-06-07 06:30:00
新一代軍用通信系統挑戰
2021-03-02 06:21:46
制造商而言,新一代 RG 必須具備可再配置的靈活架構,能以適應全球各所有地區電信服務供應商和與有線公司的要求。
2009-10-05 09:18:53
新一代視頻編碼器怎么樣?
2021-06-02 06:39:01
新一代視頻編碼標準H,264/AVC有哪幾種關鍵技術?
2021-06-03 06:33:58
本文介紹了歐勝微電子公司最新一代音頻數字-模擬轉換器(DAC)的架構,專注于設計用于消費電子應用中提供高電壓線驅動器輸出的新器件系列。
2019-07-22 06:45:00
GPU計算平臺。阿里云推出國內首個基于英偉達NGC的GPU優化容器3月28日,在2018云棲大會·深圳峰會上,阿里云宣布與英偉達GPU 云 合作 (NGC),開發者可以在云市場下載NVIDIA
2018-04-04 14:39:24
問題。AMD桌面CPU市場總監Don Woligroski在接受Joker Production的采訪中表示,將來的Zen架構處理器會有更高的IPC和更強的超頻能力。 AMD談新一代Zen處理器:更高
2017-09-07 09:43:48
ARK推出新一代250V MOS器件 近日,成都方舟微電子有限公司(ARK Microelectronics, Co., Ltd.,簡稱ARK)推出新一代250V MOSFET系列產品,包括N型
2011-04-19 15:01:29
Grace CPU 基于我們的下一代 Armv9 架構,將作為 Grace CPU 超級芯片和 Grace Hopper 超級芯片的一部分首先上市。Grace 系列處理器旨在在 AI 最苛刻的任務中提
2022-03-29 14:40:21
,新一代基站設施成為二者競爭的焦點,同時Femtocell的發展潛力也吸引了FPGA和DSP廠商。 飛思卡爾是第一個向市場推出商用四核心DSP的廠商。飛思卡爾現在在市場上主推的產品是第二代四核DSP
2019-07-19 06:10:44
Hifn公司日前宣布,在服務應用型處理器(ASP)領域推出SentryXL系列安全處理器,為受制于空間、功耗和成本的新一代通信和消費產品提高性能數據加密、壓縮和散列計算。
2019-07-25 06:06:39
POWER8芯片和支持芯片來幫助浪潮進行開發,并提供其它技術協助。浪潮董事長孫丕恕和IBM大中華區CEO錢大群(D.C. Chien)在聲明中承諾,未來將進一步加強合作。IBM在今年4月稱,今年第一季度中國營收下降20%。不過IBM在近幾個月宣布了一系列合作,凸顯出他們在中國市場擁有長期生存能力。
2014-08-28 08:41:49
此前幾個月,我們推出了新一代顯示處理器特別的預覽,代號為“Cetus”。當時,我們已經明確討論過該款顯示處理器可以為整體的圖形流水線和Mali多媒體家族(包括圖形,視頻和顯示處理器)所帶來的改善
2019-07-24 07:18:29
PLC新一代超小型控制器(LOGO!)的編程方法與操作
2020-04-07 09:00:02
21ic訊 意法半導體(STMicroelectronics,簡稱ST)宣布,日本知名網絡/IPTV服務商NTT Plala株式會社于4月17日推出的新一代先進機頂盒采用了意法半導體Orly 系統級
2013-09-22 11:35:00
21ic訊 意法半導體(STMicroelectronics,簡稱ST)宣布,日本知名網絡/IPTV服務商NTT Plala株式會社于4月17日推出的新一代先進機頂盒采用了意法半導體Orly 系統級
2013-11-08 10:36:06
全球最大的純閃存解決方案供應商Spansion(NASDAQ:SPSN)與專注于為互聯網數據中心提供節能、可拓展系統解決方案的創新者 Virident 宣布共同開發和推出新一代存儲解決方案。專為
2019-07-23 07:01:13
`TI新一代5V無線充電發射、接收芯片 bq500211、bq51013簡介 德州儀器推出首款符合 Qi 標準的 5V 無線電源發送器;新一代電源電路促進 USB 連接無線充電板普及日前,德州儀器
2013-02-21 10:55:57
近日,山特電子(深圳)有限公司(以下簡稱山特)宣布,將推出新一代城堡EX系列
2010-04-27 16:25:36
摘要: 阿里云宣布全新一代FPGA云服務器F3正式上線,并且開通邀測!近期,阿里云宣布全新一代FPGA云服務器F3正式上線,并且開通邀測。實現云上 FPGA 加速業務的快速研發、安全分發、一鍵部署
2018-05-18 22:10:44
處理器共同推出米爾MYC-YD9360核心板及開發板,賦能新一代車載智能、電力智能、工業控制、新能源、機器智能等行業發展,滿足多屏的顯示需求。
2023-12-22 18:07:58
1、引言隨著科學技術的發展和社會的進步,移動通信技術正在經歷著日新月異的變化。當人們還在研究和部署第三代移動通信系統的同時,為了適應將來通信的要求,國際通信界已經開始著手研究新一代的移動通信系統
2019-07-17 06:47:32
12月7日下午,奇虎360特供機官方微博承認將與諾基亞合作,推出新一代 360 特供機。諾基亞和奇虎 360安全衛士官方微博也隨后轉發此微博,證實合作的可能性。奇虎360和諾基亞此次合作極為保密
2012-12-09 17:40:48
新一代數據中心有哪些實踐操作范例?如何去推進新一代數據中心的發展?
2021-05-25 06:16:40
自動化測試系統的設計挑戰有哪些?如何去設計新一代自動化測試系統?
2021-05-11 06:52:57
如何確保新一代車載網絡的性能和一致性?
2021-06-17 11:17:17
德州儀器(TI)推出新一代KeyStone II架構
2021-05-19 06:23:29
斯巴魯近日宣布將從明年起運用其新一代EyeSight安全系統,并在10月2日首先透露了新一代產品的細節。
2020-08-26 07:28:47
軟件無線電的基本結構是什么?新一代SOPC的特點是什么?基于新一代SOPC的軟件無線電資源共享自適應結構
2021-05-07 06:17:33
在 8 月 14 日的 SIGGRAPH 2018 大會上,英偉達 CEO 黃仁勛正式發布了新一代 GPU 架構 Turing(圖靈),以及一系列基于圖靈架構的 GPU,包括全球首批支持即時光線追蹤
2018-08-15 10:59:45
MAX3232EUE+T號為Paulson的新一代安騰9500處理器性能達到達到上一代產品的2.4倍,內核達到上一代的兩倍,但能耗卻有所降低。 惠普安騰服務器的主要用戶是有著嚴格計算需求的大企業。以上資料由元器件提供
2012-11-09 15:48:19
NVIDIA(英偉達)21 日宣布推出 Pascal 架構深度學習平臺的最新生力軍 NVIDIA Tesla P4 及 P40 GPU 加速器與全新軟件,在效能及速度提供大幅度的提升以加速人工智能服務的推論生產作業負載。
2016-12-30 19:41:11619 NetApp宣布推出NetApp? ONTAP?AI架構,該架構基于NVIDIA DGX?超級計算機和NetApp AFF A800云互聯全閃存存儲,可簡化、加速并擴展邊緣、核心及云端的數據管道以助力深度學習部署,并助力客戶通過AI在業務方面真正收獲成效。
2018-08-03 16:33:154146 NVIDIA 副總裁兼加速計算總經理 Ian Buck 表示:“中國采用 T4 的速度之快并不令人意外,以前我們從未推出過這樣的 GPU,為公共云和私有云提供所需的綜合性能和能效,可大規模、更經濟地運行計算密集型工作負載。并且,中國的市場‘規模’無可比擬,我們預測 T4 將非常受歡迎。”
2018-11-23 10:47:294780 全球領先的云數據中心基礎架構產品及方案提供商浪潮與企業云計算領導者Nutanix宣布,推出首款浪潮inMerge1000超融合一體機。該產品深度融合浪潮高品質硬件、Nutanix領先的虛擬化解
2019-04-25 18:50:223102 
來自國外的最新爆料稱,NVIDIA的下一代GPU核心架構是Ampere(安培),下下代將是Hopper,用于紀念Grace Hopper(格蕾絲·赫柏)。
2019-06-12 15:53:201853 在最新的超級計算大會上,NVIDIA創始人兼CEO黃仁勛宣布了一套用于構建GPU加速ARM服務器的參考設計,從而大大擴展GPU加速對于超級計算機的支持。
2019-11-20 15:30:042704 11月28日,龍芯中科官方宣布將于12月24日在國家會議中心召開龍芯中科2019產品發布暨用戶大會,推出龍芯新一代處理器架構產品。
2019-11-29 14:18:44823 盡管AMD已經推出了7nm工藝、RDNA架構的新一代Navi家族顯卡,但是NVIDIA在高端GPU市場上的地位依然無可動搖,12nm工藝的圖靈Turing顯卡在性能及能效上還是占據上風。
2019-12-10 10:44:131863 在德國慕尼黑舉行的GPU技術會議上,高性能GPU和人工智能領域的領導者Nvidia宣布推出了一套新的開源RAPIDS庫,用于GPU加速的分析和機器學習,這又邁出了一步。
2020-03-25 15:38:052092 當地時間5月14日,NVIDIA將會放出黃仁勛原計劃在GTC 2020大會上的主題演講,重頭戲當然是新一代安培(Ampere) GPU架構的官宣。
2020-05-08 12:03:402764 5月14日,全球領先的AI計算基礎架構廠商浪潮宣布全新發布5款AI服務器,全面支持全新的NVIDIA A100 Tensor Core GPU。浪潮此次發布的5款AI服務器將應對多種人工智能計算場景,可支持8到16顆最新NVIDIA A100 Tensor Core GPU。
2020-05-18 14:58:272565 英偉達(Nvidia)周四宣布,其加速計算平臺將用于構建其聲稱將成為世界上最快的AI超級計算機的東西。
2020-10-17 11:07:161984 計算機圖形芯片制造商NVIDIA近日表示,歐洲高性能計算共同計劃(EuroHPC Joint Undertaking)將采用NVIDIA加速計算平臺和架構來打造四臺新的超級計算機,從而推動歐洲走到超級計算研究的最前沿。
2020-10-18 09:12:081633 合法的女兒,被譽為第一位計算機科學家、編寫了歷史上第一個計算機程序。 細心的N飯還挖掘出,Lovelace和Hopper都曾印在NVIDIA的官方文化衫“英
2020-12-21 18:07:531704 Ampere安培架構之后,NVIDIA的下一代產品原本是Hopper(霍珀),但根據最新消息,在那之前又增加了一代“Ada Lovelace”。
2020-12-29 10:55:101449 超級計算機是一項重要的投資,對于研究人員和科學家來說,它們是必不可少的寶貴工具。為了有效和安全地共享這些數據中心的計算能力, NVIDIA 引入了云原生超級計算架構。它結合了裸機性能、多租戶和性能
2021-11-21 10:43:181794 GTC2022大會黃仁勛:Hopper 實現首個GPU機密計算,是處理器架構和軟件的結合,每個Hopper 實例都支持在受信任執行環境中進行機密計算。
2022-03-23 17:47:261805 
GTC2022大會亮點:NVIDIA正在打造EOS,將于數月后推出,這是NVIDIA打造的首個Hopper AI工廠,將會是先進AI基礎架構的藍圖。
2022-03-24 15:26:281352 
今日在 GTC 上發布的 NVIDIA Hopper GPU 架構利用全新 DPX 指令,將動態編程速度提高多達 40 倍。動態編程是一種應用于基因組學、量子計算、路線優化等領域算法中,用以解決問題的技術。
2022-03-25 16:28:511676 今日凌晨,NVIDIA(英偉達)發布了基于最新Hopper架構的H100系列GPU和Grace CPU超級芯片!
2022-03-26 09:07:052380 全球的超級計算中心都在紛紛利用 NVIDIA Quantum InfiniBand 網絡上的 NVIDIA BlueField DPU 將加速計算提升到一個新的水平。
2022-06-01 10:29:26966 今年的 GTC22 上 NVIDIA 發布其首款基于 Hopper 架構的 GPU —NVIDIA H100。
2022-07-18 10:35:231300 NVIDIA 于今日宣布 NVIDIA H100 Tensor Core GPU 全面投產,NVIDIA 全球技術合作伙伴計劃于 10 月推出首批基于開創性 NVIDIA Hopper 架構的產品和服務。
2022-09-22 10:45:01956 NVIDIA Grace Hopper Superchip 架構是第一個真正的異構加速平臺,適用于高性能計算(HPC) 和AI工作負載。它利用 GPU 和 CPU 的優勢加速應用程序,同時提供迄今為止最簡單、最高效的分布式異構編程模型。
2022-11-14 10:13:52830 NVIDIA NVLink-C2C 是一種 NVIDIA 內存一致性、高帶寬和低延遲的超級芯片互連。它是 Grace Hopper Superchip 的核心,提供高達 900 GB/s 的總帶寬。這比加速系統中常用的 x16 PCIe Gen5 通道高 7 倍。
2022-11-18 10:15:18559 春 NVIDIA 網絡事業部亞太區市場開發高級總監 NVIDIA Modulus 加速 AI 和科學計算 戴志翔 NVIDIA 解決方案架構師 NVIDIA DPU 加速云原生超級計算? 馮高鋒 NVI
2022-12-12 19:10:06808 的突破成果.NVIDIA宣布推出一項將加速計算引入計算光刻技術領域的突破性成果。在當前生產工藝接近物理極限的情況下,這項突破使ASML、TSMC和Synopsys等半導體行業領導者能夠加快新一代芯片的設計和制造。 官網直播截圖 在2023GTC大會上黃仁勛表示:“芯片行業是全球幾乎所有其
2023-03-22 19:29:3110234 
了一個革命性的新架構。 全球首個 GPU 加速的量子計算系統—— NVIDIA DGX Quantum 結合了由 NVIDIA Grace Hopper 超級芯片和 CUDA Quantum 開源編程模型構建的全球最強加速計算平臺
2023-03-23 06:55:02389 GPU 架構升級過程計算能力不斷強化,Hopper 架構適用于高性能計算(HPC)和 AI 工作負載。英偉達在架構設計上,不斷加強 GPU 的計算能力和能源效率。在英偉達 GPU 架構的演變
2023-05-15 11:16:381261 
公布了一個基于 NVIDIA Grace CPU 超級芯片 的超級計算機,為基于 Arm Neoverse 平臺的新型節能超級計算機掀起了一輪新的浪潮。 Isambard 3 超級計算機位于英國布里斯托和巴斯科學
2023-05-23 07:10:02352 —2023 年 5 月 29 日— NVIDIA 今天宣布推出一款新型大內存 AI 超級計算機——由 NVIDIA GH200 Grace Hopper 超級芯片和 NVIDIA NVLink
2023-05-30 01:40:011457 
由 GH200 驅動的系統將加入到全球系統制造商基于 NVIDIA Grace、Hopper、Ada Lovelace 架構的 400 多種系統配置中 COMPUTEX — 2023
2023-05-30 01:40:02634 
NVIDIA 計算架構團隊和? NVIDIA 計算專家團隊正在熱招! 如果你對加速計算領域充滿熱情,并且希望與優秀的技術專家一起合作,那么這個機會將是你展現才華的優質平臺,快來 加入
2023-06-14 18:35:01602 NVIDIA Hopper GPU 上的新 cuBLAS 12.0 功能和矩陣乘法性能
2023-07-05 16:30:381583 
深度了解 NVIDIA Grace Hopper 超級芯片架構
2023-07-05 16:30:42253 第三,詳細拆解了NVIDIA Fermi和Hopper兩大典型微架構的具體硬件實現,在頂點處理、光柵化計算、紋理貼圖、像素處理的圖形渲染流水線上對Fermi架構進行了拆分;在指令接收、調度、分配
2023-07-09 10:55:371212 
NVIDIA官方宣布了新一代GH200 Grace Hopper超級芯片平臺,全球首發采用HBM3e高帶寬內存,可滿足世界上最復雜的生成式AI負載需求。
2023-08-10 09:37:12892 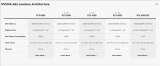
NVIDIA Grace Hopper Superchip將節能、高帶寬的 NVIDIA Grace CPU 與功能強大的 NVIDIA H100 Hopper GPU 結合使用 NVLink-C2C,以最大限度地提高強大的高性能計算 (HPC) 和巨型 AI 工作負載的能力。
2023-08-30 10:45:44915 
平臺無論是在云端還是網絡邊緣均展現出卓越的性能和通用性。 此外,NVIDIA 宣布推出全新推理軟件,該軟件將為用戶帶來性能、能效和總體擁有成本的大幅提升。 GH200 超級芯片在
2023-09-12 20:40:04249 平臺無論是在云端還是網絡邊緣均展現出卓越的性能和通用性。 ? 此外,NVIDIA宣布推出全新推理軟件,該軟件將為用戶帶來性能、能效和總體擁有成本的大幅提升。 ? GH200 超級芯
2023-09-13 09:45:40139 
也即將在 OCI Compute 上推出。 OCI 上的 NVIDIA? H100 Tensor Core GPU 實例 OCI Co mpute 裸機實例配備了具有? NVIDIA Hopper ? 架構 的 NVIDIA H
2023-09-25 20:40:02269 
NVIDIA HGX? H200,為 Hopper 這一全球領先的 AI 計算平臺再添新動力。NVIDIA HGX H200 平臺基于 NVIDIA Hopper? 架構,搭載 NVIDIA H200
2023-11-14 14:30:0185 
世界頂級服務器制造商和云服務提供商即將推出 HGX H200 系統與云實例。 11月13日,NVIDIA 宣布推出 NVIDIA HGX H200 ,為 Hopper 這一全球領先的 AI 計算平臺
2023-11-14 20:05:01269 
2023年的AWS re:Invent大會上,AWS和NVIDIA宣布AWS將成為第一個提供NVIDIA GH200 Grace Hopper超級芯片的云服務提供商。
2023-11-30 09:24:11291 
整整10年前的2013年2月19日,NVIDIA正式推出了新一代Maxwell GPU架構,它有著極高的能效,出場方式也非常特別。
2024-02-19 16:39:21398 
根據各方信息和路線圖,NVIDIA預計會在今年第二季度發布Blackwell架構的新一代GPU加速器“B100”。
2024-03-04 09:33:20475 
日 ——? NVIDIA 于今日發布新一代 AI 超級計算機 —— 搭載 NVIDIA GB200 Grace Blackwell 超級芯片的 NVIDIA DGX SuperPOD?。這臺 AI 超級計算機可以用于處理萬億參數模型,能夠保證
2024-03-19 10:56:3556 
正在加载...
 電子發燒友App
電子發燒友App










 工商網監
工商網監
評論