 電子發(fā)燒友App
電子發(fā)燒友App


到目前為止,在本博客系列中,我們已經(jīng)討論了 Accellera 便攜式測試和刺激標(biāo)準(zhǔn) (PSS) 的一些基礎(chǔ)知識,以及它如何增強通用驗證方法 (UVM) 流程。這是一種非常有效的塊級驗證策略,允許重復(fù)使用現(xiàn)有的驗證 IP (VIP) 模型。然而,一旦幾個設(shè)計 IP 模塊集成在一起,幾乎可以肯定一個或多個處理器將成為子系統(tǒng)的一部分。一旦發(fā)生這種情況,就需要一種新的驗證策略。
軟件通常代表系統(tǒng)功能的一個重要方面,它的一部分可能需要包含在驗證過程中。能夠按照 UVM 流程的要求直接操作總線,意味著可以進行更徹底的測試,而不是在將多個模塊集成在一起之后的驗證重點。您不會嘗試重復(fù)在每個塊上單獨進行的驗證。相反,您正在嘗試確保模塊之間正確通信并且可以執(zhí)行產(chǎn)品的更高級別功能。事實上,一旦處理器和總線協(xié)議在設(shè)計中固定下來,就不可能訪問連接到總線的每個 IP 塊的所有功能。
在模擬環(huán)境中,每個處理器都可能由指令集模擬器 (ISS) 或某種其他形式的行為模型來表示。這些可從所有處理器供應(yīng)商和第三方處輕松獲得。這些模型提供了功能準(zhǔn)確性,雖然它們在時間意義上并不完美,但它們通常足以滿足大多數(shù)目的。最重要的是,它們的運行速度比寄存器傳輸級 (RTL) 模型快幾個數(shù)量級,并且已集成到您最喜歡的 RTL 仿真環(huán)境中。
您應(yīng)該在這些處理器上運行什么軟件?過去,會編寫專用測試代碼來以一小套定向測試的形式來測試子系統(tǒng)。經(jīng)驗豐富的驗證工程師知道開發(fā)這些測試并在硬件發(fā)生變化時對其進行維護需要多長時間。使用 PSS 和測試綜合,這個問題幾乎變得微不足道。
讓我們不要太快得意忘形了。僅僅因為我們有一條路徑可以自動生成在這些處理器上運行的軟件,問題并沒有完全解決,也沒有回答有關(guān)要使用的軟件級別的所有問題。
嵌入式處理器可以以實際運行的軟件可以訪問的確切方式訪問設(shè)計中的所有內(nèi)容。我們?yōu)槭裁床恢苯舆\行它?這有幾個原因。首先,生產(chǎn)軟件可能還沒有準(zhǔn)備好。雖然左移運動試圖推動軟件開發(fā),但并不總是可以同時開發(fā)它們。其次,您不希望您的測試僅限于當(dāng)前版本的軟件對硬件所做的事情。如果預(yù)計稍后會通過軟件更新發(fā)布附加功能怎么辦?如果產(chǎn)品最初發(fā)布時尚未驗證硬件,則可能會影響您將來添加更新的能力。
這并不意味著您永遠不應(yīng)該使用任何生產(chǎn)軟件。當(dāng)您接近完成設(shè)計并且驗證接近覆蓋目標(biāo)時,您可能希望使用生產(chǎn)驅(qū)動程序、協(xié)議棧的其他一些層,甚至操作系統(tǒng)的元素。例如,Breker 提供了一個可在測試綜合期間使用的函數(shù)庫。這些功能,例如內(nèi)存管理,構(gòu)成了我們將在以后的博客中討論的多層硬件/軟件接口抽象層的基礎(chǔ)。
在軟件運行時讓測試臺運行是另一個問題。您如何協(xié)調(diào)子系統(tǒng)或芯片的外部輸入的活動?必須有一種方法在處理器和 VIP 之間進行通信,以便協(xié)調(diào)活動。我們在 Breker 使用 TrekBox 完成了這項工作(參見圖 1)。
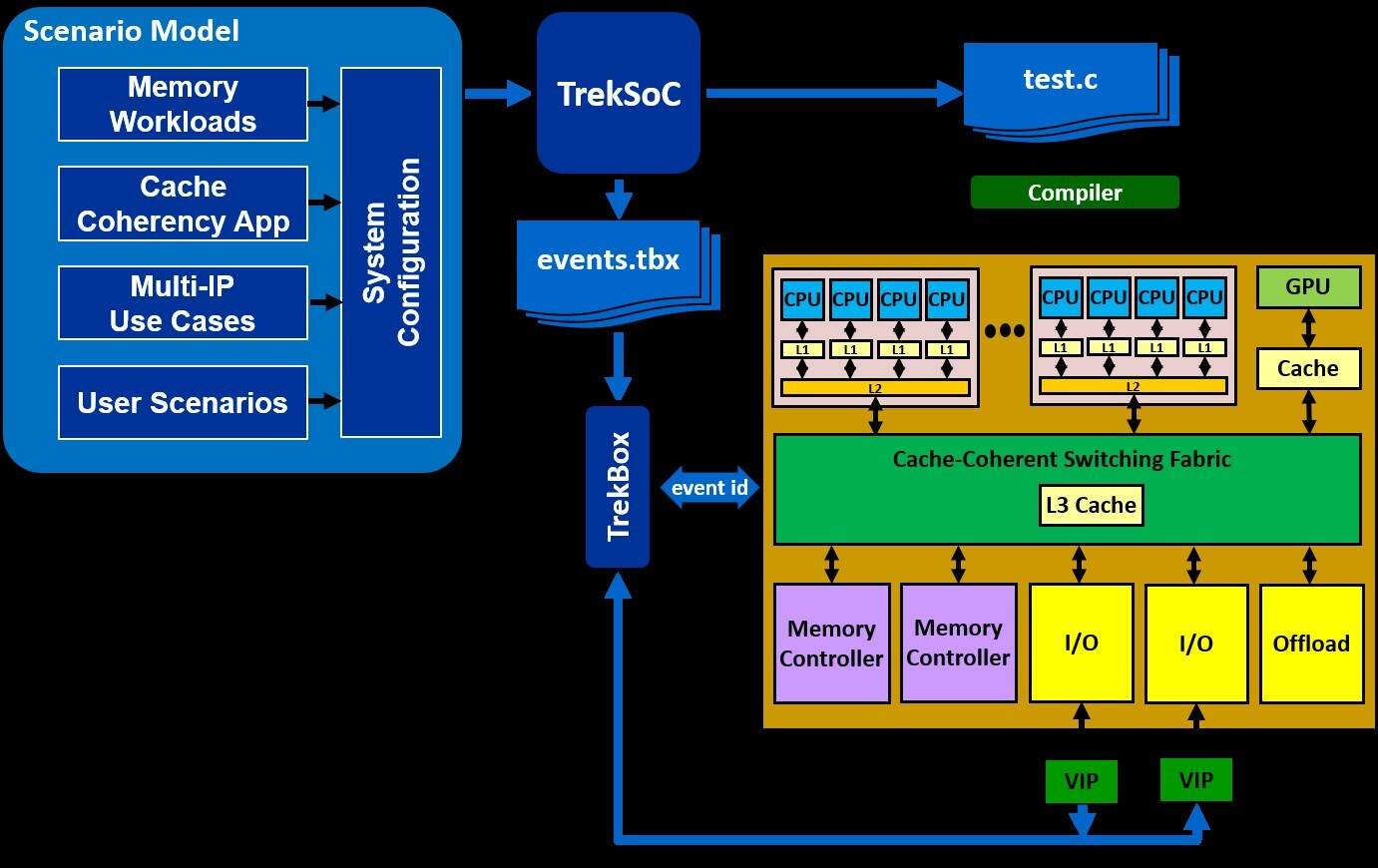
圖 1 標(biāo)題:在此示例中,工具協(xié)調(diào)軟件和外部 VIP 之間的活動。
TrekBox 使用模擬器的后門內(nèi)存 API 監(jiān)控模擬器中的內(nèi)存。當(dāng)處理器寫入某個地址時,它表示要發(fā)送給特定 VIP 的命令。在該消息中可能包含有關(guān)所需確切操作的更多信息。因此,處理器可以協(xié)調(diào)外部活動。如果您想測試,例如,當(dāng)軟件進入中斷服務(wù)程序時,將數(shù)據(jù)洪流到所有外部端口,這很有用。
在上一篇博客中,我們?yōu)閳D 2 所示的示例設(shè)計開發(fā)了一個測試平臺。VIP 為兩個 UART 提供數(shù)據(jù)。處理器已被移除,取而代之的是由測試平臺驅(qū)動的總線接口模型。一切都由測試臺控制。
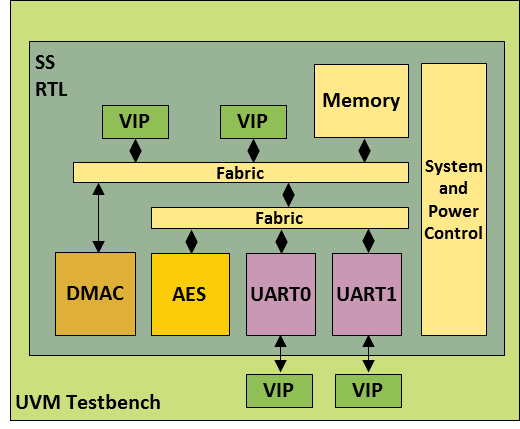
圖 2 說明:示例設(shè)計說明了 VIP 如何為測試平臺驅(qū)動的 UARTS 和總線接口模型提供數(shù)據(jù)。
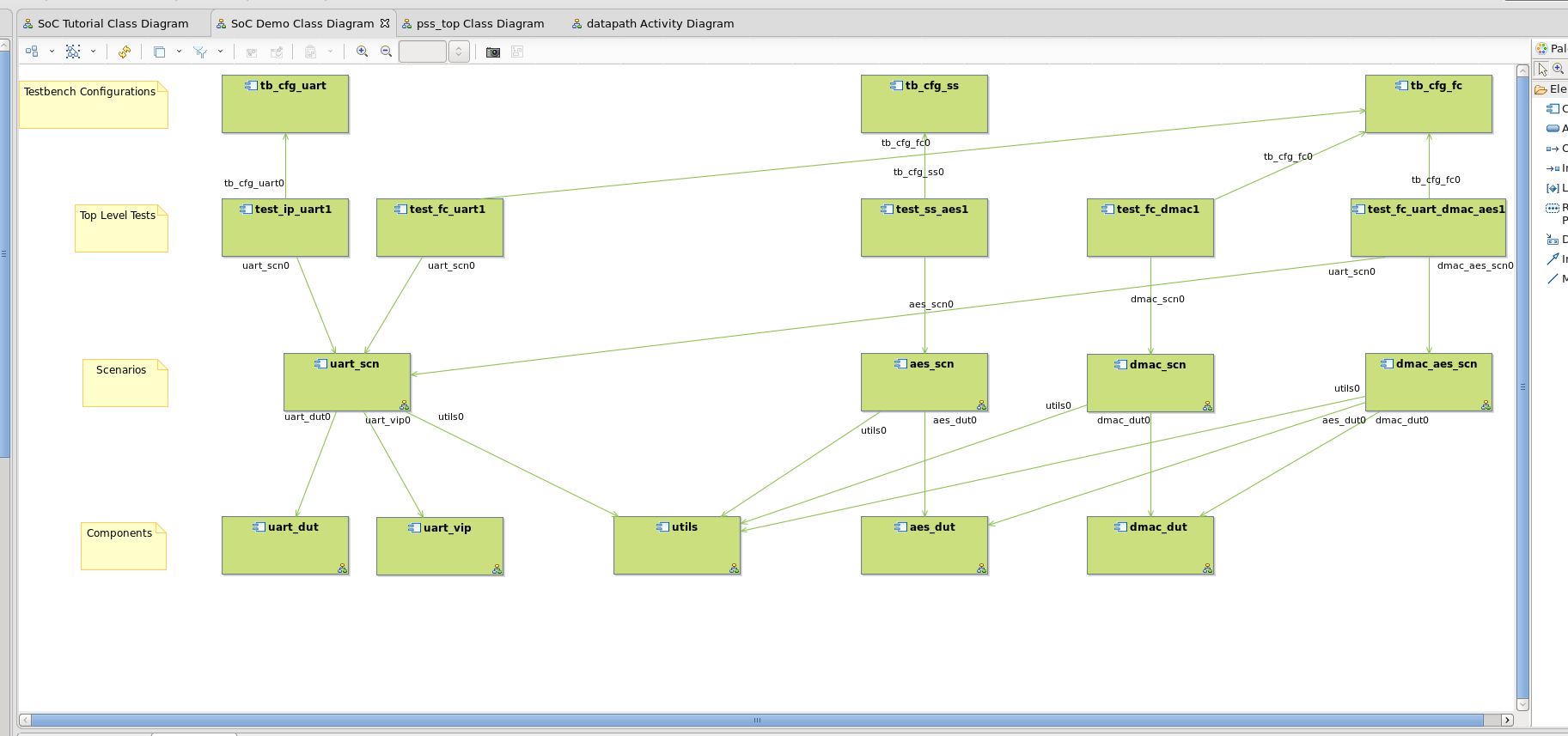
圖 3 標(biāo)題:類圖突出顯示了如何通過圖形輸入工具輸入測試。它也可以使用便攜式刺激標(biāo)準(zhǔn) (PSS) 語言編寫。
在圖 3 中,顯示了測試平臺的三種配置tb_cfg_uart、tb_cfg_ss和tb_cfg_fc。第一個配置以前與一個處理器一起使用,運行四個線程并通過事務(wù)級建模 (TLM) 進行通信。TLM 名稱表明它們在設(shè)計中不是真正的 CPU,而是為 TLM 接口生成流量。與此相關(guān)的代碼如下所示。
8 組件 tb_cfg_uart {
9
10 // 用戶代碼的開始 Component_tb_cfg_uart
11 處理器 cpu0 {“cpu0”, 4, Processor::TLM};
12 // 用戶代碼結(jié)束
我們可以修改配置,改為為兩個處理器生成測試,每個處理器運行四個線程。這需要更改配置代碼,如下所示。
8 組件 tb_cfg_ss {
9
10 // 用戶代碼的開始 Component_tb_cfg_ss
11 處理器 cpu0 {“cpu0”, 4, Processor::TLM};
12 處理器 cpu1 {“cpu1”, 4, Processor::TLM};
13
14 memory_resource ddr0 {“ddr0”, 0x1000};
雖然沒有將處理器實例化到設(shè)計中,但仍為數(shù)據(jù)讀取和寫入以及行為檢查定義了一個內(nèi)存區(qū)域。為了切換到使生成的測試軟件驅(qū)動而不是使用 UVM,我們再次更改配置代碼,如下所示。
8 組件 tb_cfg_fc {
9
10 // 用戶代碼的開始 Component_tb_cfg_fc
11 處理器 cpu0 {“cpu0”, 4, Processor::SDV};
12 處理器 cpu1 {“cpu1”, 4, Processor::SDV};
13
14 memory_resource ddr0 {“ddr0”, 0x1000};
這是唯一需要做出的改變。現(xiàn)在測試合成將輸出處理器代碼、加載到 TrekBox 的代碼以及執(zhí)行外部 VIP 協(xié)調(diào)的所有內(nèi)容,如圖 1 所示。
在下一篇博客中,我們將把這個例子轉(zhuǎn)移到模擬器上,產(chǎn)生一些新問題。正是這種模擬和仿真之間測試的可移植性是創(chuàng)建該標(biāo)準(zhǔn)的主要動機。
審核編輯:郭婷














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論