 電子發(fā)燒友App
電子發(fā)燒友App


??過去十年是深度學(xué)習(xí)的“黃金十年”,它徹底改變了人類的工作和娛樂方式,并且廣泛應(yīng)用到醫(yī)療、教育、產(chǎn)品設(shè)計(jì)等各行各業(yè),而這一切離不開計(jì)算硬件的進(jìn)步,特別是GPU的革新。
深度學(xué)習(xí)技術(shù)的成功實(shí)現(xiàn)取決于三大要素:第一是算法。20世紀(jì)80年代甚至更早就提出了大多數(shù)深度學(xué)習(xí)算法如深度神經(jīng)網(wǎng)絡(luò)、卷積神經(jīng)網(wǎng)絡(luò)、反向傳播算法和隨機(jī)梯度下降等。

第二是數(shù)據(jù)集。訓(xùn)練神經(jīng)網(wǎng)絡(luò)的數(shù)據(jù)集必須足夠大,才能使神經(jīng)網(wǎng)絡(luò)的性能優(yōu)于其他技術(shù)。直至21世紀(jì)初,諸如Pascal和ImageNet等大數(shù)據(jù)集才得以現(xiàn)世。
第三是硬件。只有硬件發(fā)展成熟,才能將大型數(shù)據(jù)集訓(xùn)練大型神經(jīng)網(wǎng)絡(luò)的所需時(shí)間控制在合理的范圍內(nèi)。業(yè)內(nèi)普遍認(rèn)為:比較“合理”的訓(xùn)練時(shí)間大概是兩周。至此,深度學(xué)習(xí)領(lǐng)域燃起了燎原之火。
如果把算法和數(shù)據(jù)集看作是深度學(xué)習(xí)的混合燃料,那么GPU就是點(diǎn)燃它們的火花,當(dāng)強(qiáng)大的GPU可用來訓(xùn)練網(wǎng)絡(luò)時(shí),深度學(xué)習(xí)技術(shù)才變得實(shí)用。
此后,深度學(xué)習(xí)取代了其他算法,被廣泛應(yīng)用在圖像分類、圖像檢測、語音識別、自然語言處理、時(shí)序分析等領(lǐng)域,甚至在圍棋和國際象棋方面也能看到它的身影。隨著深度學(xué)習(xí)潛入人類生活的方方面面,模型訓(xùn)練和推理對硬件的要求也越來越高。
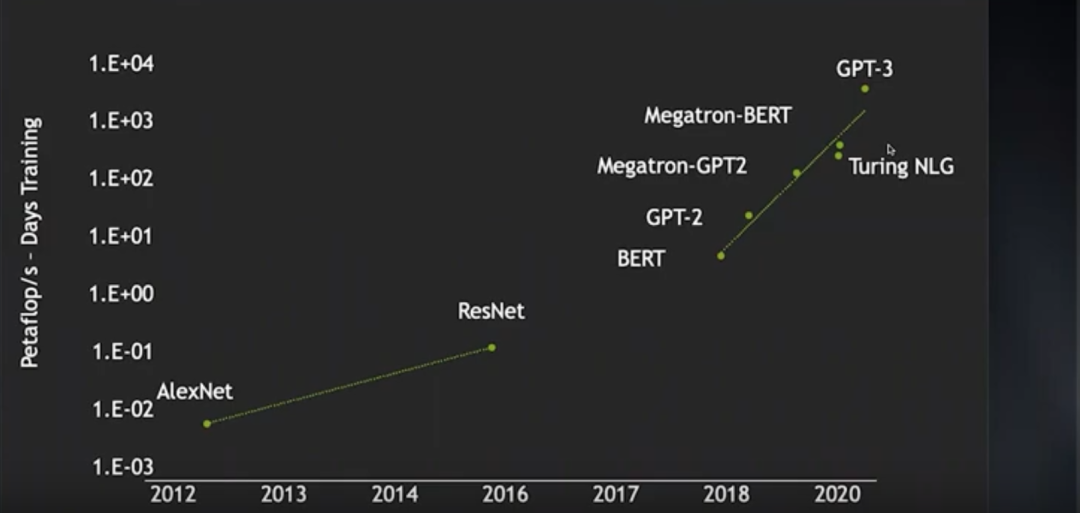
從2012年AlexNet出現(xiàn)到2016年ResNet問世,圖像神經(jīng)網(wǎng)絡(luò)的訓(xùn)練算力消耗(以petaflop/s-day為單位)增長了將近2個(gè)數(shù)量級,而從2018年的BERT到近年的GPT-3,訓(xùn)練算力消耗增加了近4個(gè)數(shù)量級。在此期間,得益于某些技術(shù)的進(jìn)步,神經(jīng)網(wǎng)絡(luò)的訓(xùn)練效率明顯提升,由此節(jié)省了不少算力,否則算力消耗的增長還會更夸張。
研究人員想用更大的無監(jiān)督語言數(shù)據(jù)集訓(xùn)練更大的語言模型,然而,盡管他們已經(jīng)擁有4000個(gè)節(jié)點(diǎn)的GPU集群,但在合理訓(xùn)練時(shí)間內(nèi)能處理的運(yùn)算還是非常有限。這就意味著,深度學(xué)習(xí)技術(shù)的發(fā)展有多快,取決于硬件發(fā)展有多快。
如今,深度學(xué)習(xí)模型不但越來越復(fù)雜,而且應(yīng)用范圍越來越廣泛。因此,還需要持續(xù)提升深度學(xué)習(xí)的性能。
那么,深度學(xué)習(xí)硬件究竟如何繼續(xù)提升?英偉達(dá)首席科學(xué)家Bill Dally無疑是回答這一問題的權(quán)威,在H100 GPU發(fā)布前,他在一次演講中回顧了深度學(xué)習(xí)硬件的現(xiàn)狀,并探討摩爾定律失效的情況下持續(xù)提升性能擴(kuò)展的若干方向。OneFlow社區(qū)對此進(jìn)行了編譯。
01?GPU架構(gòu)演進(jìn)史
從2012年的K20X到2020年的A100,GPU的推理性能提高到原來的317倍。這就是我們所說的“黃氏定律”,這種發(fā)展速度比“摩爾定律”快得多。
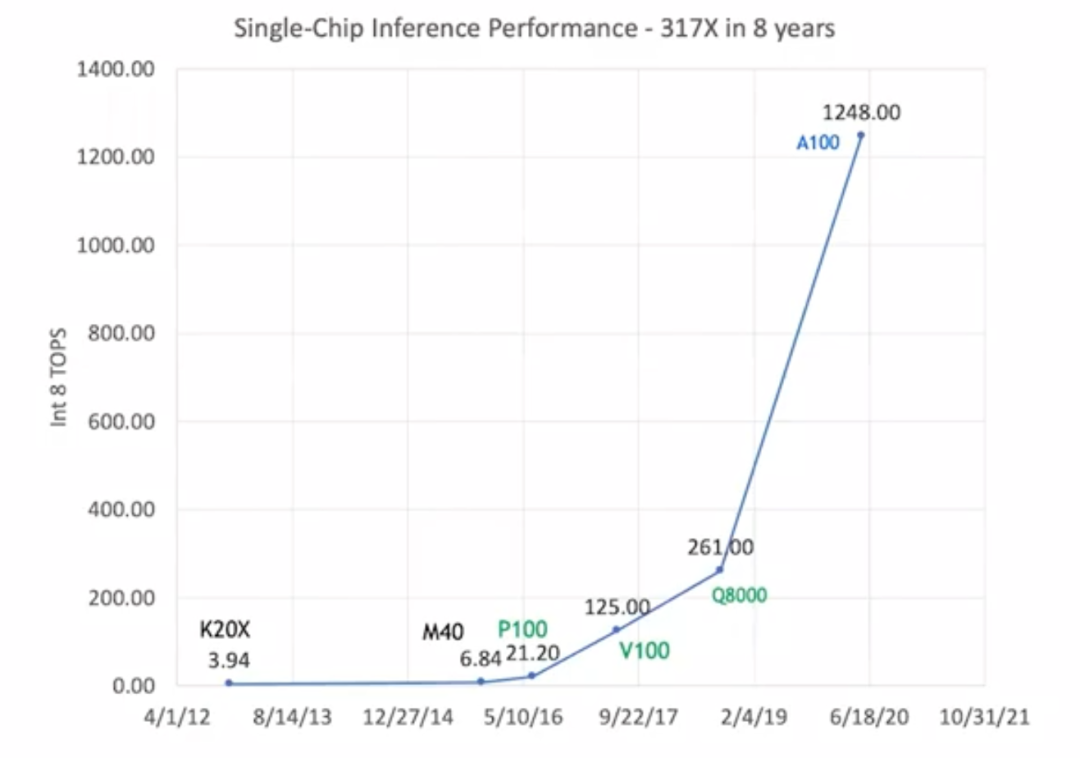
?GPU的推理性能提升
但不同于“摩爾定律”,在“黃氏定律”中,GPU的性能提升不完全依賴制程技術(shù)的進(jìn)步。上圖用黑、綠、藍(lán)三色分別標(biāo)注了這幾種GPU,分別代表它們使用了三種不同的制程技術(shù)。早期的K20X和M40使用的是28納米制程;P100、V100和Q8000使用的是16納米制程;A100使用的是7納米制程。制程技術(shù)的進(jìn)步大概只能讓GPU的性能提高到原來的1.5或2倍。而總體317倍的性能提升絕大部分歸功于GPU架構(gòu)和線路設(shè)計(jì)的完善。
2012年,英偉達(dá)推出了一款Kepler架構(gòu)GPU,但它并不是專為深度學(xué)習(xí)設(shè)計(jì)的。英偉達(dá)在2010年才開始接觸深度學(xué)習(xí),當(dāng)時(shí)還沒有考慮為深度學(xué)習(xí)量身定制GPU產(chǎn)品。

Kepler (2012)
Kepler的目標(biāo)使用場景是圖像處理和高性能運(yùn)算,但主要還是用于圖像處理。因此,它的特點(diǎn)是高浮點(diǎn)運(yùn)算能力,它的FP32計(jì)算(單精度浮點(diǎn)數(shù)計(jì)算)速度達(dá)到近4 TFLOPS,內(nèi)存帶寬達(dá)到250 GB/s。基于Kepler出色的性能表現(xiàn),英偉達(dá)也將它視為自家產(chǎn)品的基準(zhǔn)線。

Pascal (2016)
后來,英偉達(dá)在2016年推出了Pascal架構(gòu),它的設(shè)計(jì)更適合深度學(xué)習(xí)。英偉達(dá)經(jīng)過一些研究后發(fā)現(xiàn),不少神經(jīng)網(wǎng)絡(luò)都可以用FP16(半精度浮點(diǎn)數(shù)計(jì)算)訓(xùn)練,因此Pascal架構(gòu)的大部分型號都支持FP16計(jì)算。下圖這款Pascal GPU的FP32計(jì)算速度可達(dá)10.6 TFLOPS,比前一款Kepler GPU高出不少,而它的FP16計(jì)算則更快,速度是FP32的兩倍。
Pascal架構(gòu)還支持更多復(fù)雜指令,例如FDP4,這樣就可以將獲取指令、解碼和獲取操作數(shù)的開銷分?jǐn)偟?個(gè)算術(shù)運(yùn)算中。相較于之前的融合乘加(Fuse Multiply-Add)指令只能將開銷分?jǐn)偟?個(gè)算術(shù)運(yùn)算,Pascal架構(gòu)可以減少額外開銷帶來的能耗,轉(zhuǎn)而將其用于數(shù)學(xué)運(yùn)算。
Pascal架構(gòu)還使用了HBM顯存,帶寬達(dá)到732 GB/s,是Kepler的3倍。之所以增加帶寬,是因?yàn)閮?nèi)存帶寬是深度學(xué)習(xí)性能提升的主要瓶頸。此外,Pascal使用了NVLink,可以連接更多機(jī)器和GPU集群,從而更好地完成大規(guī)模訓(xùn)練。英偉達(dá)為深度學(xué)習(xí)推出的DGX-1系統(tǒng)就使用了8個(gè)基于Pascal架構(gòu)的GPU。

Volta (2017)
2017年,英偉達(dá)推出了適用于深度學(xué)習(xí)的Volta架構(gòu),它的設(shè)計(jì)重點(diǎn)之一是可以更好地分?jǐn)傊噶铋_銷。Volta架構(gòu)中引入了Tensor Core,用于深度學(xué)習(xí)的加速。Tensor Core可以用指令的形式與GPU連接,其中的關(guān)鍵指令是HMMA (Half Precision Matrix Multiply Accumulate,半精度矩陣乘積累加),它將2個(gè)4×4 FP16矩陣相乘,然后將結(jié)果加和到一個(gè)FP32矩陣中,這種運(yùn)算在深度學(xué)習(xí)中很常見。通過HMMA指令,就可以將獲取指令和解碼的開銷通過分?jǐn)偨档偷皆瓉淼?0%到20%。
剩下的就是負(fù)載問題。如果想要超越Tensor Core的性能,那就應(yīng)該在負(fù)載上下功夫。在Volta架構(gòu)中,大量的能耗和空間都被用于深度學(xué)習(xí)加速,所以即使?fàn)奚?a href="http://www.xsypw.cn/v/tag/1315/" target="_blank">編程性,也不能帶來太多性能提升。
Volta還升級了HBM顯存,內(nèi)存帶寬達(dá)到900 GB/s,還使用了新版本的NVLink,可以讓構(gòu)建集群時(shí)的帶寬增加到2倍。此外,Volta架構(gòu)還引進(jìn)了NVSwitch,可以連接多個(gè)GPU,理論上NVSwitch最多可以連接1024個(gè)GPU,構(gòu)建一個(gè)大型共享內(nèi)存機(jī)器。

Turing (2018)
2018年,英偉達(dá)推出了Turing架構(gòu)。由于之前的Tensor Core大獲成功,所以英偉達(dá)又順勢推出了Integer Tensor Core。因?yàn)榇蟛糠值纳窠?jīng)網(wǎng)絡(luò)用FP16即可訓(xùn)練,做推理時(shí)也不需要太高的精度和太大的動態(tài)范圍,用Int8即可。所以,英偉達(dá)在Turing架構(gòu)中引進(jìn)了Integer Tensor Core,使性能提高到原來的2倍。
Turing架構(gòu)還使用了GDDR顯存,以支持那些有高帶寬需求的NLP模型和推薦系統(tǒng)。當(dāng)時(shí)有人質(zhì)疑稱,Turing架構(gòu)的能源效率比不上市面上的其他加速器。但如果仔細(xì)計(jì)算,會發(fā)現(xiàn)其實(shí)Turing架構(gòu)的能源效率更高,因?yàn)門uring用的是G5顯存,而其他加速器用的是LPDDR內(nèi)存。我認(rèn)為,選擇G5顯存是一個(gè)正確的決定,因?yàn)樗梢灾С滞惍a(chǎn)品沒能支持的高帶寬需求的模型。
我對Turing架構(gòu)深感驕傲的一點(diǎn)是,它還配備了支持光線追蹤(Ray Tracing)的RT Core。英偉達(dá)在2013年才開始研究RT Core,在短短5年后就正式推出了RT Core。

Ampere (2020)
2020年,英偉達(dá)發(fā)布了Ampere架構(gòu),讓當(dāng)年發(fā)布的A100實(shí)現(xiàn)了性能飛躍,推理速度可達(dá)1200 Teraflops以上。Ampere架構(gòu)的一大優(yōu)點(diǎn)是,它支持稀疏性。我們發(fā)現(xiàn),大部分神經(jīng)網(wǎng)絡(luò)都是可以稀疏化的,也就是說,可以對神經(jīng)網(wǎng)絡(luò)進(jìn)行“剪枝”,將大量權(quán)重設(shè)置為0而不影響它的準(zhǔn)確率。但不同神經(jīng)網(wǎng)絡(luò)的可稀疏化程度不同,這就有些棘手。比如,在保證不損失準(zhǔn)確率的前提下,卷積神經(jīng)網(wǎng)絡(luò)的密度可以降低至30%到40%,而全連接神經(jīng)網(wǎng)絡(luò)則可降低至10%到20%。
傳統(tǒng)觀點(diǎn)認(rèn)為,由于運(yùn)算稀疏矩陣包的開銷較大,所以如果密度不能降到10%以下,權(quán)衡之下不如運(yùn)算密集矩陣包。我們一開始和斯坦福大學(xué)合作研究稀疏性,后來做出了很好的機(jī)器,它們在矩陣密度達(dá)到50%時(shí)也能高效運(yùn)行,但要想讓稀疏矩陣在電源門控(power gating)方面比密集矩陣更優(yōu)越還是很困難,這是我們一直想突破的地方。最終,我們攻破難題研發(fā)出了Ampere,而秘訣就是結(jié)構(gòu)化稀疏。
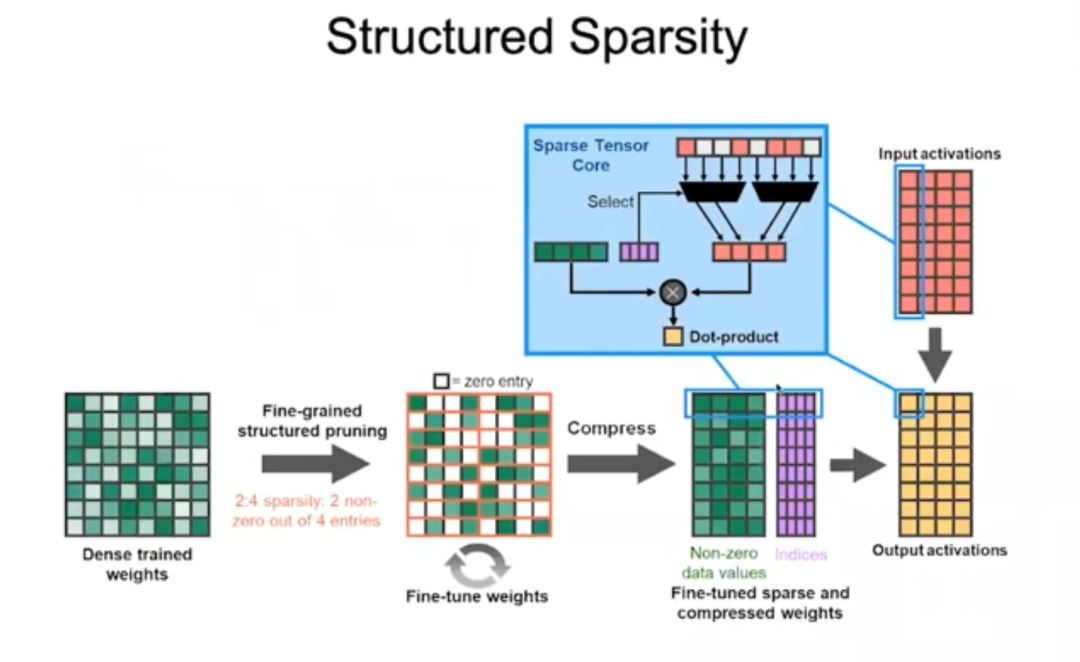
結(jié)構(gòu)化稀疏
Ampere架構(gòu)規(guī)定矩陣的每4個(gè)數(shù)值中,非零值不能超過2個(gè),也就是通過去掉非零值對權(quán)重進(jìn)行壓縮。通過輸入碼字(code word)判斷哪些權(quán)重應(yīng)被保留,并用碼字判斷這些非零權(quán)重應(yīng)該乘以哪些輸入激活,然后相加,完成點(diǎn)乘操作。這種做法非常高效,讓Ampere架構(gòu)在大多數(shù)神經(jīng)網(wǎng)絡(luò)上的性能提升到原來的2倍。
此外,Ampere架構(gòu)還有不少創(chuàng)新點(diǎn),例如Ampere內(nèi)置了TF32(即TensorFloat-32)格式,它結(jié)合了FP32的8位指數(shù)位和FP16的10位尾數(shù)位。Ampere還支持BFLOAT格式,BFLOAT的指數(shù)位與FP32相同,尾數(shù)位比FP32少,所以可以視為FP32的縮減版。上述的所有數(shù)據(jù)格式都支持結(jié)構(gòu)化稀疏,所以無論用FP16和TF32訓(xùn)練,還是用Int8和Int4推理,都可以獲得結(jié)構(gòu)化稀疏帶來的高性能。
隨著Ampere在量化方面做得越來越好,它可以應(yīng)用在很多神經(jīng)網(wǎng)絡(luò)上并保證高性能。Ampere有6個(gè)HBM堆棧,且HBM顯存的帶寬也有所升級,達(dá)到2TB/s。端到端推理時(shí),Ampere的運(yùn)算能力可達(dá)3.12 TOPS/W(Int8)和6.24 TOPS/W(Int4)。
02?GPU推理性能提升的三大因素
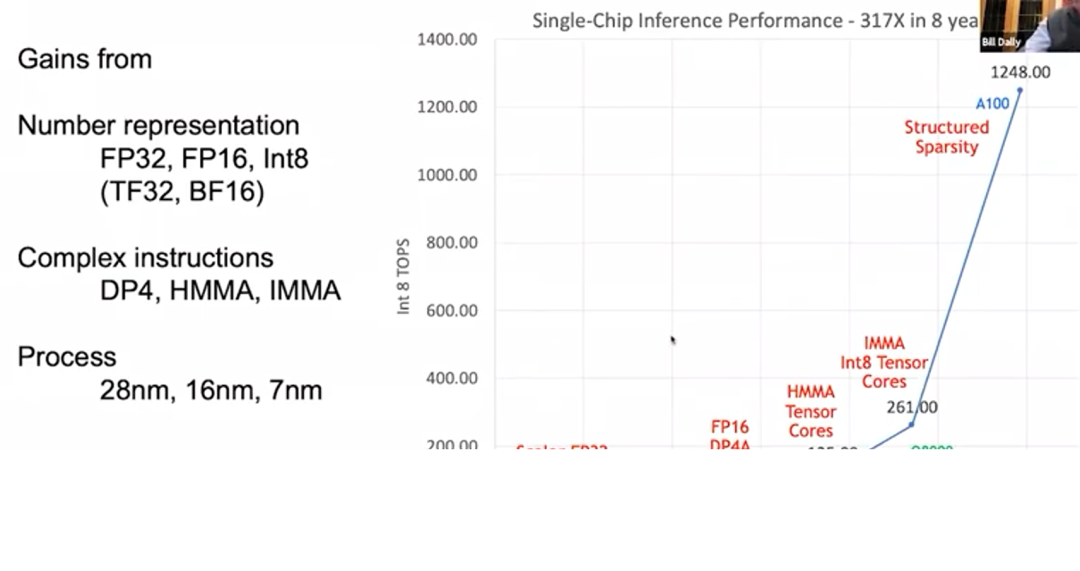
GPU推理性能提升的三大因素
總結(jié)深度學(xué)習(xí)過去的發(fā)展,GPU推理性能在8年內(nèi)提升317倍主要?dú)w功于三大因素:
首先,最重要的是數(shù)字表示(number representation)法的發(fā)展。FP32的精度太高,導(dǎo)致算術(shù)運(yùn)算的成本太高。后來Turing和Ampere架構(gòu)支持Int8,極大提升了GPU的每瓦性能。Google發(fā)表論文公布TPU1時(shí)表示,TPU1的優(yōu)勢就在于它是專門為機(jī)器學(xué)習(xí)量身定制的。實(shí)際上,Google應(yīng)該是在拿自家的TPU1和英偉達(dá)的Kepler進(jìn)行比較(如前所述,Kepler并非專門為深度學(xué)習(xí)而設(shè)計(jì)),所以TPU1的優(yōu)勢歸根結(jié)底可以說是Int8相較于FP32的優(yōu)勢。
其次,GPU支持復(fù)雜指令。Pascal架構(gòu)新增了點(diǎn)乘指令,然后Volta、Turing和Ampere架構(gòu)新增了矩陣乘積指令,讓開銷得到分?jǐn)偂T贕PU中保留可編程引擎可以帶來很多好處,它可以像加速器一樣高效,因?yàn)槊宽?xiàng)指令完成的任務(wù)非常多,每項(xiàng)指令的開銷分?jǐn)値缀蹩梢院雎圆挥?jì)。
最后,制程技術(shù)的進(jìn)步。芯片制程從28納米發(fā)展到如今的7納米,為GPU性能提升作出了一定的貢獻(xiàn)。
下列例子可以讓你更好地理解開銷分?jǐn)偟男Ч喝绻麍?zhí)行HFMA操作,“乘”和“加”2個(gè)操作合計(jì)只需1.5pJ(皮焦耳,Picojoules),然而獲取指令、解碼和獲取操作數(shù)需要30pJ的開銷,分?jǐn)傁聛黹_銷就會高達(dá)2000%。
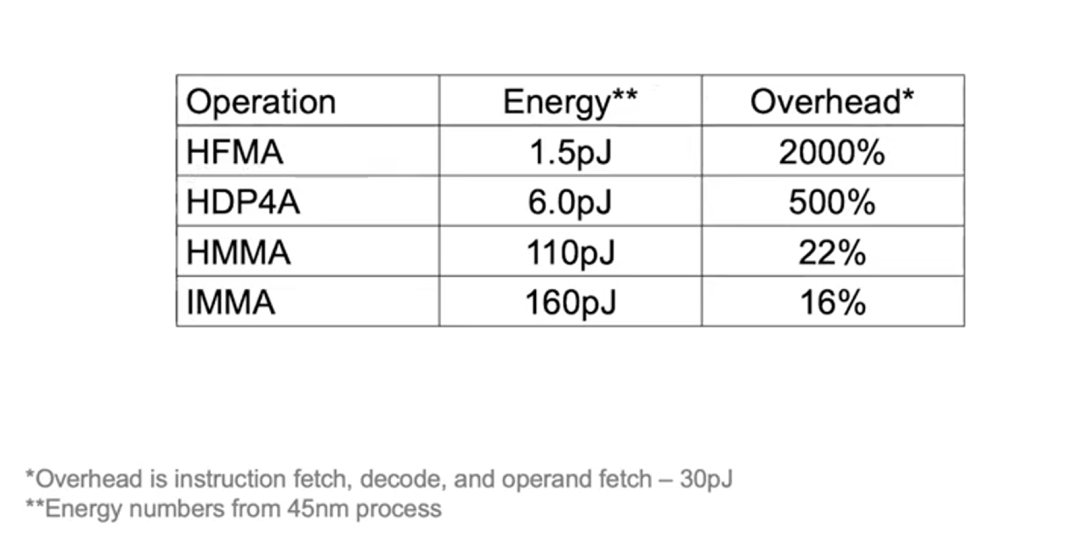
而如果執(zhí)行HDP4A操作,就可以將開銷分?jǐn)偟?個(gè)操作,使開銷下降至500%。而HMMA操作,由于絕大部分的能耗都用于負(fù)載,開銷僅為22%,IMMA則更低,為16%。因此,雖然追求可編程性會增加少量開銷,但采取不同的設(shè)計(jì)可帶來的性能提升更加重要。
03?從單卡性能到GPU集群連接
以上談?wù)摰亩际菃蝹€(gè)GPU的性能,但訓(xùn)練大型語言模型顯然需要多個(gè)GPU,因此還要改善GPU之間的連接方式。
我們在Pascal架構(gòu)中引入NVLink,后來的Volta架構(gòu)采用了NVLink 2,Ampere架構(gòu)采用了NVLink 3,每一代架構(gòu)的帶寬都翻了一倍。此外,我們在Volta架構(gòu)中推出了第一代NVSwitch,又在Ampere架構(gòu)推出了第二代。通過NVLink和NVSwitch,可以構(gòu)建超大型的GPU集群。另外,我們還推出了DGX box。

DGX box
2020年,英偉達(dá)收購了Mellanox,所以現(xiàn)在可以提供包含Switches和Interconnect在內(nèi)的整套數(shù)據(jù)中心解決方案,供構(gòu)建大型GPU集群之用。此外,我們還配備了DGX SuperPOD,它在AI性能記錄500強(qiáng)名單上排行前20。以往,用戶需要定制機(jī)器,現(xiàn)在只需要購置一臺可以部署DGX SuperPOD的預(yù)配置機(jī)器,就可以獲得DGX SuperPOD帶來的高性能。此外,這些機(jī)器還非常適用于科學(xué)計(jì)算。
從前,用單臺機(jī)器訓(xùn)練單個(gè)大型語言模型需要幾個(gè)月之久,但通過構(gòu)建GPU集群就可以大大提高訓(xùn)練效率,因此,優(yōu)化GPU集群連接和提升單個(gè)GPU的性能同樣重要。
04?深度學(xué)習(xí)加速器:新技術(shù)的試驗(yàn)場
接下來談?wù)動ミ_(dá)的加速器研發(fā)工作。英偉達(dá)把加速器視為試驗(yàn)新技術(shù)的載體,成功的技術(shù)最終會被應(yīng)用到主流GPU中。
可以這樣理解加速器:它有一個(gè)由內(nèi)存層次結(jié)構(gòu)輸入的矩陣乘法單元,接下來要做的是讓大部分的能耗用于矩陣乘法計(jì)算,而不是用于數(shù)據(jù)搬運(yùn)。
為了這個(gè)目標(biāo),我們在2013左右啟動了NVIDIA DLA項(xiàng)目,它是一款開源產(chǎn)品,配套非常完善,與其他深度學(xué)習(xí)加速器別無二致。但DLA有大型MAC陣列,支持2048次Int8、1024次Int16或1024次FP16操作。
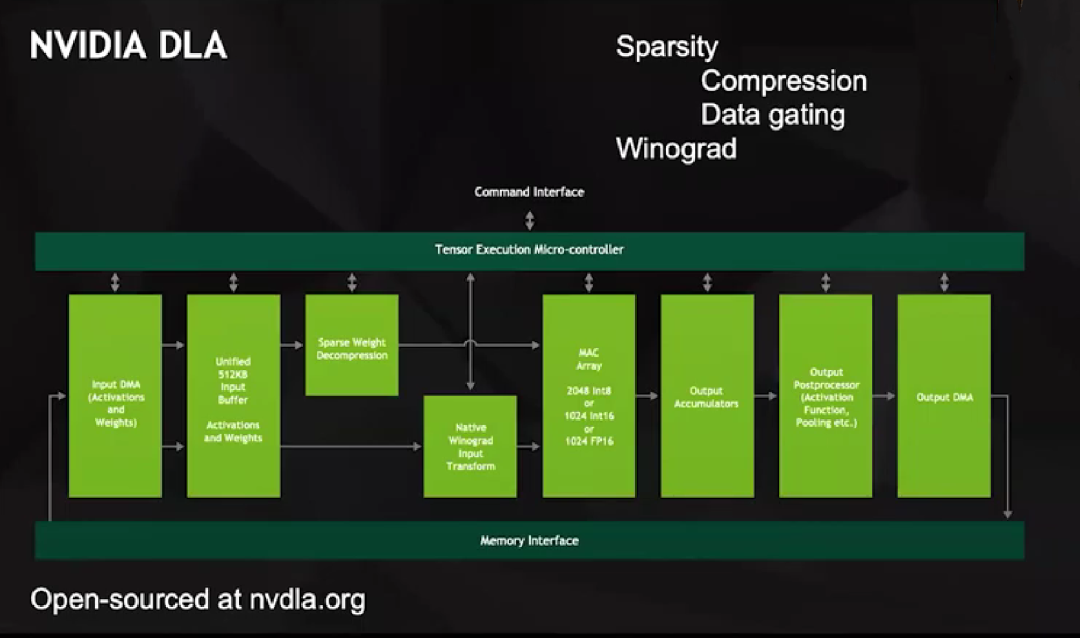
DLA有兩個(gè)獨(dú)特之處:一是支持稀疏化。我們從容易實(shí)現(xiàn)的目標(biāo)開始著手,所有的數(shù)據(jù)傳輸,包括從DMA到Unified Buffer和從Unified Buffer到MAC陣列,都只涉及非零值,通過編碼決定哪些元素被留下,然后對這些元素進(jìn)行解壓縮,再輸入MAC陣列進(jìn)行運(yùn)算。
DLA解壓縮的方式比較巧妙,它并不向MAC陣列中輸入零值,因?yàn)檫@會讓一連串的數(shù)據(jù)都變?yōu)榱恪O喾矗O(shè)置了單獨(dú)的線路表示零值,當(dāng)乘法器在任一輸入中接收到該線路時(shí),就會鎖定乘法器內(nèi)的數(shù)據(jù),然后發(fā)送輸出,輸出的數(shù)據(jù)不會增加任何數(shù)值,這種數(shù)據(jù)門控(Data Gating)的能源效率非常高。
二是在硬件層面支持Winograd變換。要知道,如果要做卷積,例如一個(gè)m×n的卷積核,在空間域就需要n的2次方個(gè)乘法器和加法器,但如果在頻域,就只需要逐點(diǎn)相乘。
所以大型卷積核在頻域運(yùn)算比在空間域運(yùn)算更高效。根據(jù)卷積核大小的不同,對部分圖像網(wǎng)絡(luò)而言,Winograd變換可以帶來4倍的性能提升。
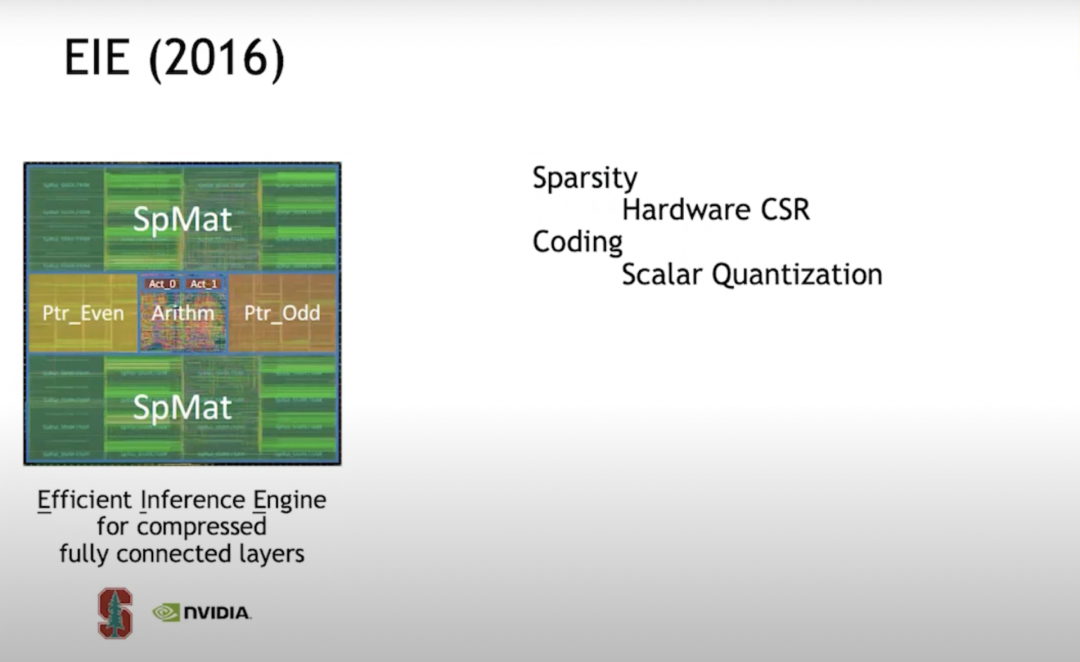
EIE(2016)
2016年,我在斯坦福和我當(dāng)時(shí)的學(xué)生韓松(MIT EECS助理教授、原深鑒科技聯(lián)合創(chuàng)始人)一起研究EIE (Efficient Inference Engine)。這是對稀疏化的初步探索之一。我們在硬件層面支持CSR(Compressed Sparse Row)矩陣表示,這種做法非常高效,在密度為50%時(shí),甚至比全密度計(jì)算還要節(jié)能。
后來發(fā)現(xiàn),如果想讓加速器更高效,應(yīng)該構(gòu)建向量單元陣列,這樣每個(gè)引擎不會只執(zhí)行單個(gè)乘加,而是每個(gè)循環(huán)每個(gè)PE(Processing Element)執(zhí)行16×16=256個(gè)乘加。但當(dāng)我們開始構(gòu)建向量單元陣列時(shí),發(fā)現(xiàn)很難高效實(shí)現(xiàn)稀疏化,于是轉(zhuǎn)而采用結(jié)構(gòu)化稀疏。
EIE處理標(biāo)量單元時(shí),它將指針結(jié)構(gòu)儲存在單獨(dú)的內(nèi)存中,然后通過流水階段來處理指針結(jié)構(gòu),決定哪些數(shù)據(jù)可以相乘,繼而執(zhí)行乘法,將運(yùn)算結(jié)果放置在合適的位置。這一整套流程運(yùn)行得非常高效。
我們還發(fā)現(xiàn),提高神經(jīng)網(wǎng)絡(luò)運(yùn)算效率的方法除了“剪枝”實(shí)現(xiàn)稀疏化之外,還有量化。因此,我們決定使用碼本量化(codebook quantization)。在用比特?cái)?shù)表示的數(shù)據(jù)方面,碼本量化是提升效率的最佳方法。所以我們對codebook(碼本)進(jìn)行了訓(xùn)練。
事實(shí)證明,如果你能使用反向傳播來捕捉梯度下降,那就可以將反向傳播運(yùn)用到任何事物中。所以我們在碼本中使用反向傳播,訓(xùn)練了給定精度的最優(yōu)碼字集。假設(shè)碼本有7個(gè)比特,那么你將得到128個(gè)碼字,我們就在神經(jīng)網(wǎng)絡(luò)中找到最優(yōu)的128個(gè)碼字進(jìn)行訓(xùn)練。
碼本量化面臨一個(gè)問題:數(shù)學(xué)運(yùn)算的開銷很高。因?yàn)椴还艽a本有多大,實(shí)際數(shù)值是多少,你都需要在RAM(隨機(jī)訪問內(nèi)存)中進(jìn)行查找。實(shí)際數(shù)值必須以高精度表示,而你無法將這些碼字準(zhǔn)確地表示出來。
因此,我們在高精度數(shù)學(xué)方面花了很多精力。從壓縮的角度來看,這樣做的效果很好,但從數(shù)學(xué)能量(math energy)的角度來看,就顯得不是很劃算,所以在后續(xù)工作中我們就放棄了這項(xiàng)技術(shù)。

Eyeriss(2016)
Joel Emer(同時(shí)供職于英偉達(dá)和麻省理工大學(xué))和麻省理工大學(xué)的Vivienne Sze一起構(gòu)建了Eyeriss,主要解決了平鋪問題,或者說是如何限制計(jì)算,以此來將數(shù)據(jù)搬運(yùn)(data movement)最小化。典型的方法是使用行固定(row stationary),在行中傳播權(quán)重,輸出在列中激活,并最大限度地減少數(shù)據(jù)搬運(yùn)消耗的能量。
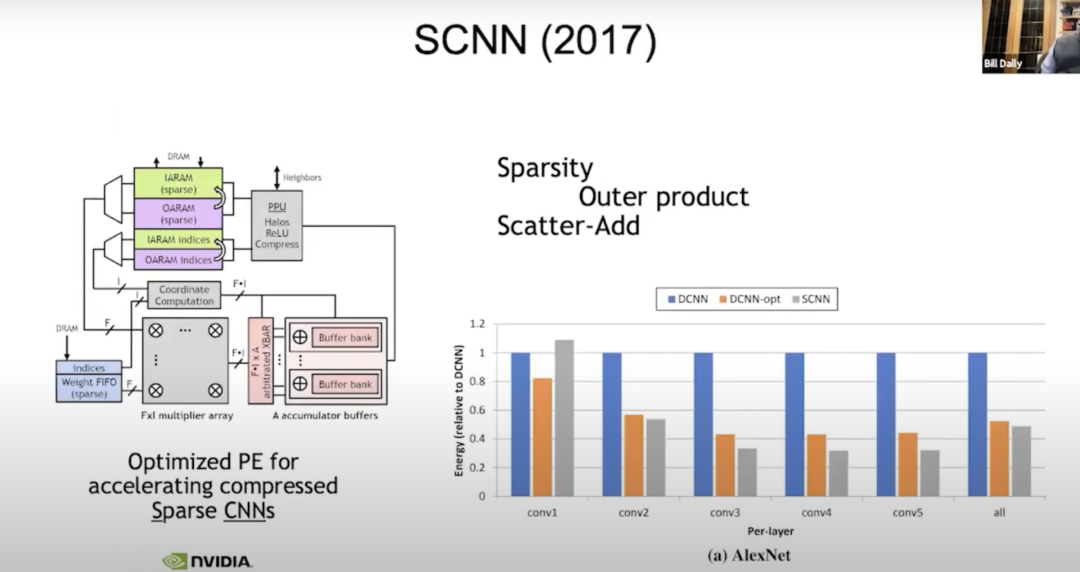
SCNN(2017)
我們現(xiàn)在仍在進(jìn)行稀疏性研究。2017年,我們?yōu)橄∈杈幾g(神經(jīng)網(wǎng)絡(luò)的進(jìn)化版)搭建了一臺名為SCNN(Sparse CNNs)的機(jī)器,我們所做的是:將與處理稀疏性相關(guān)的所有復(fù)雜問題都轉(zhuǎn)移到輸出上。讀取所有的輸入激活,同時(shí)明確它們需要去往哪里,因此這里的“f寬向量”是典型的向量輸入激活。我們一次會讀取四個(gè)輸入激活,四個(gè)權(quán)重,每個(gè)權(quán)重都需要乘以每個(gè)輸入激活。這只是一個(gè)關(guān)于把結(jié)果放在哪里的問題,所以我們用f乘f計(jì)算。
在坐標(biāo)計(jì)算中,我們?nèi)≥斎爰せ詈蜋?quán)重的指數(shù),并計(jì)算出在輸出激活中需要求和結(jié)果的位置。然后在這些累加器緩沖區(qū)上做了一個(gè)數(shù)據(jù)發(fā)散(scatter_add)計(jì)算。在此之前,一切都非常有效。但事實(shí)證明,將不規(guī)則性轉(zhuǎn)移到輸出上不是一個(gè)好辦法,因?yàn)樵谳敵鲋校葘?shí)際上是最寬泛的。當(dāng)你傾向于累加,做了八位權(quán)重,八位激活,累加到了24位。在這里我們用寬位累加器(wide accumulators )做了大量的數(shù)據(jù)搬運(yùn),效果優(yōu)于做更密集一點(diǎn)的數(shù)據(jù)搬運(yùn)。不過提升也沒有想象的那么多,也許是密度單元能量的50%。

SIMBA(RC18)(2019)
我們要做的另一件事是:用現(xiàn)有加速器建造一個(gè)多芯片模塊——SIMBA(RC18),在2018年產(chǎn)生了做此研究的想法,同時(shí)這款芯片也展示了很多巧妙的技術(shù)。它有一個(gè)很好的PE架構(gòu),該芯片則在其中間提供了一項(xiàng)非常有效的信令技術(shù)(signaling technology)。現(xiàn)在該架構(gòu)擴(kuò)展到了完整的36個(gè)芯片,其中每個(gè)芯片都有一個(gè)4x4的PE矩陣,在這個(gè)單位中,每個(gè)PE又有8個(gè)寬矢量單位,因此我們能夠得到128 TOPS的運(yùn)算能力,每個(gè)Op有0.1 pJ,大約相當(dāng)于10 TOPS/W。從中我們學(xué)到了很多關(guān)于權(quán)衡(trade-offs)的東西。
我們意識到:構(gòu)建這些PE陣列宛如建立一個(gè)非常大的設(shè)計(jì)空間(design space),關(guān)乎如何構(gòu)建內(nèi)存層次結(jié)構(gòu),如何調(diào)度數(shù)據(jù)等等,對此我們建立了一個(gè)叫做MAGNET的系統(tǒng)。
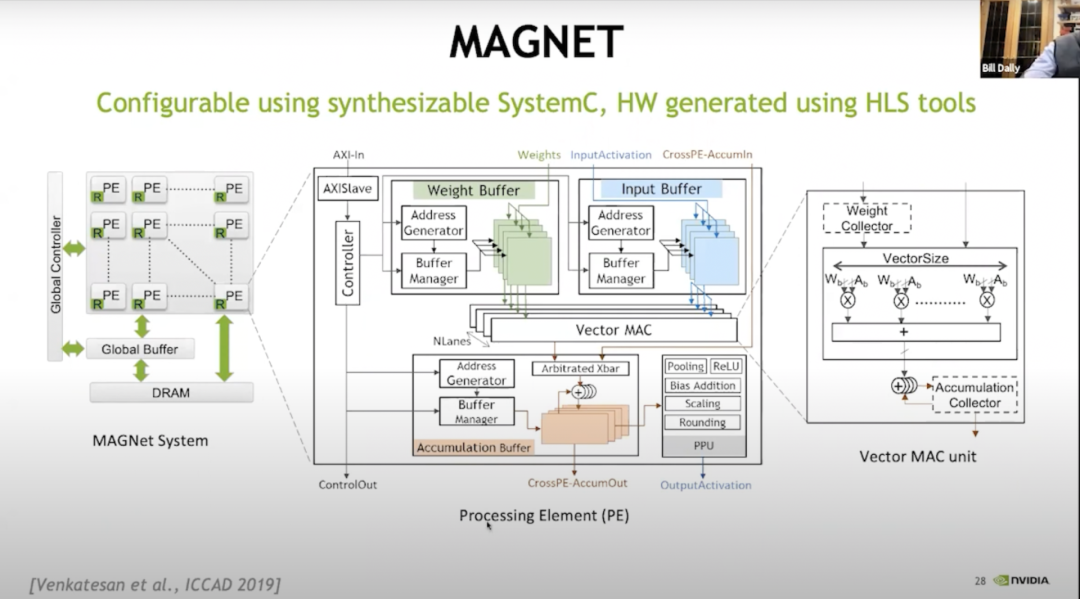
MAGNET
上圖是一個(gè)于2019年發(fā)表在ICCAD(國際計(jì)算機(jī)輔助設(shè)計(jì)會議)上的設(shè)計(jì)空間探索系統(tǒng),主要用于枚舉其設(shè)計(jì)空間,如:每個(gè)向量單元應(yīng)該有多寬,每個(gè)PE有多少向量單元,權(quán)重緩沖區(qū)有多大,累加器緩沖區(qū)有多大,激活緩沖區(qū)有多大等等。后來發(fā)現(xiàn),我們需要去做另一個(gè)級別的緩存,于是添加了權(quán)重收集器和累加器收集器。
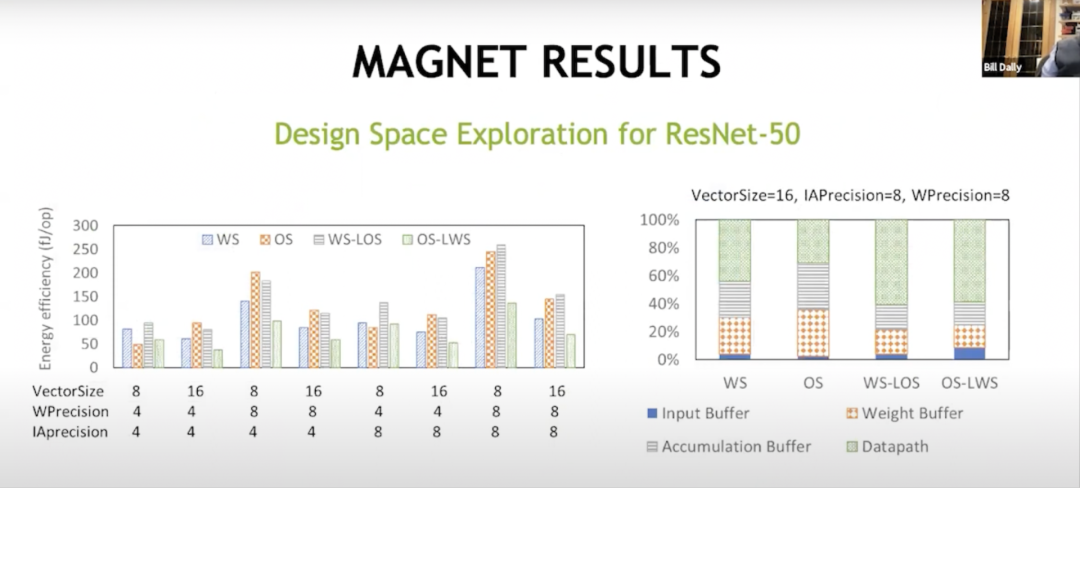
MAGNET RESULTS
通過這種額外的緩存級別,我們最終取得了成功。這表明這里的數(shù)據(jù)流是不同的,而權(quán)重固定數(shù)據(jù)流最初是由Sze和Joel來完成的。你將大部分能量投到了數(shù)據(jù)路徑以外的事情上,比如投入到累積緩沖區(qū)、權(quán)重緩沖區(qū)和輸入緩沖區(qū)中。但通過這些混合數(shù)據(jù)流,權(quán)重固定,局部輸出固定,輸出固定,局部權(quán)重固定,能夠在數(shù)學(xué)運(yùn)算中獲得幾乎三分之二的能量,并且可以減少花在這些內(nèi)存陣列中的能量,從而在內(nèi)存層次結(jié)構(gòu)的另一個(gè)層上進(jìn)行處理。這使得現(xiàn)在的每瓦性能達(dá)到約為20 TOPS。
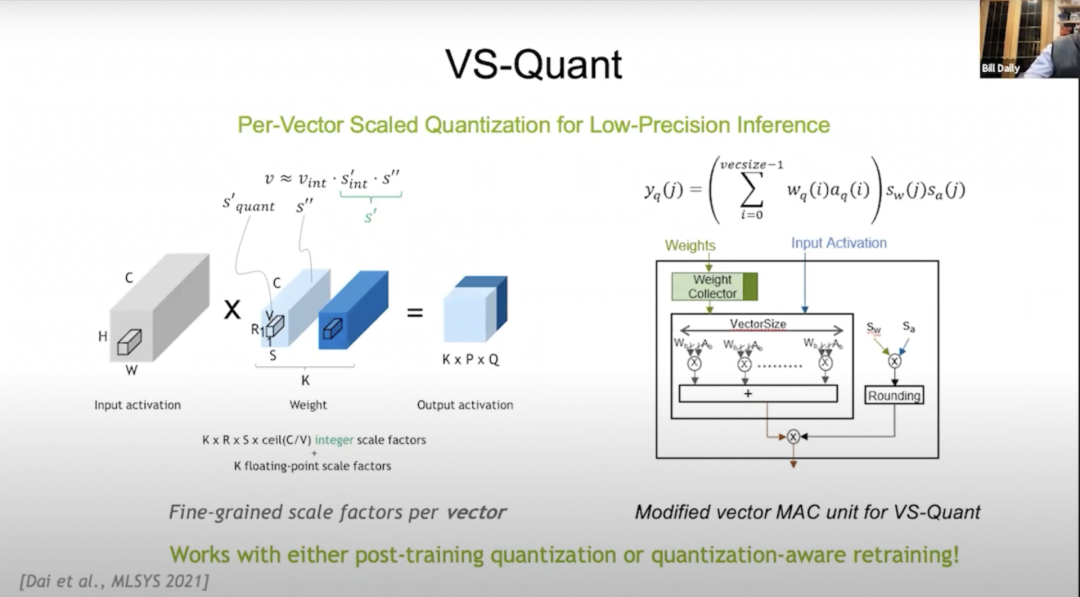
VS-Quant
2021年,在MLSYS(The Conference on Machine Learning and Systems,機(jī)器學(xué)習(xí)與系統(tǒng)會議)會議上,我們引入了VS-Quant,以此來探索出一種在壓縮比特?cái)?shù)(這方面碼本量化效果很好)和數(shù)學(xué)開銷方面都很劃算的量化方式。我們使用整數(shù)表示,但同時(shí)想要縮放該整數(shù)表示,以便可以表示出整數(shù)的動態(tài)范圍。
但事實(shí)證明,如果你現(xiàn)在將其應(yīng)用到整個(gè)神經(jīng)網(wǎng)絡(luò),那么效果不會很好,因?yàn)樯窠?jīng)網(wǎng)絡(luò)上有很多不同的動態(tài)范圍,所以VS-Quant的關(guān)鍵是:我們對一個(gè)相對較小的向量施加了一個(gè)單獨(dú)的比例因子(scale factor),大約通過在32個(gè)權(quán)重上進(jìn)行上述操作,動態(tài)范圍會小得多。我們可以把這些整數(shù)放在上面,也可以對其調(diào)整優(yōu)化。
也許我們沒有將離群值準(zhǔn)確地表示出來,但更好地表示出了其余數(shù)字。如此一來,我們就可以用相對低精度的權(quán)重和激活來換取較高的精度。所以我們現(xiàn)在有多個(gè)比例因子(scale factors ):一個(gè)是權(quán)重因子,一個(gè)是激活因子。
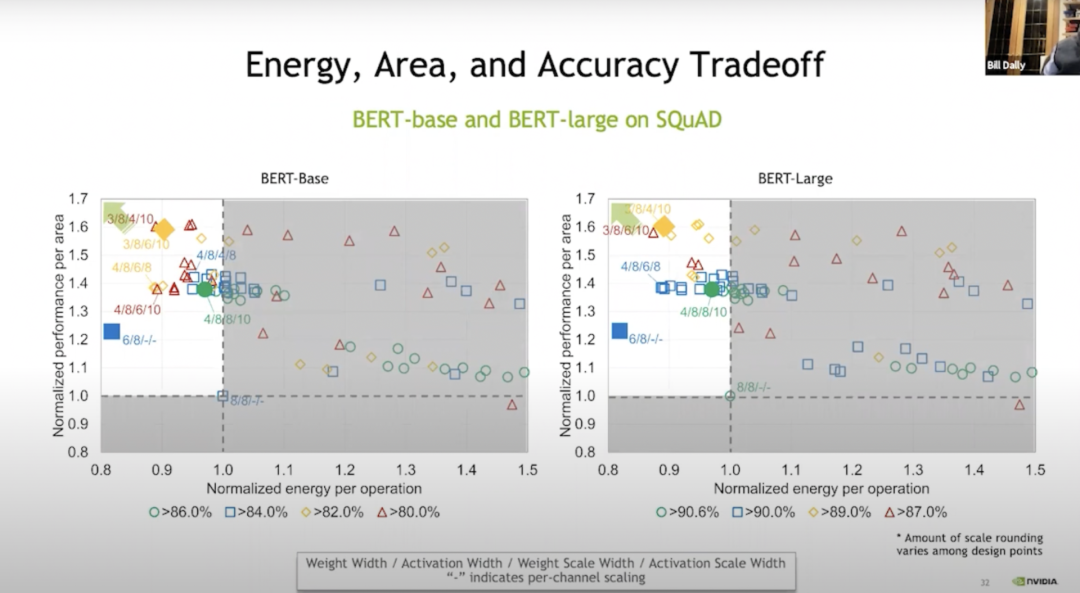
Energy, Area, and Accuracy Tradeoff
我們基本上是在向量層級進(jìn)行這些操作,結(jié)果如Bert-base所示。與不進(jìn)行權(quán)重訓(xùn)練相比,我們可以通過訓(xùn)練在某些情況下節(jié)省20%的能量和70%的空間,上圖的綠色表示基本上沒有損失準(zhǔn)確性;藍(lán)色、橙色和紅色表示準(zhǔn)確性更高或更低。但即使在藍(lán)色水平,準(zhǔn)確性也相當(dāng)高了。
通過VS-Quant和一些其他調(diào)整,我們在這些語言模型上進(jìn)行了試運(yùn)行。在語言模型上運(yùn)行比在大約為120 TOPS/W的圖像模型上運(yùn)行要困難得多。

Accelerators
所以對于加速器,要先做一個(gè)矩陣乘法器。我們需要提出一種平鋪方法,一種采用神經(jīng)網(wǎng)絡(luò)的七個(gè)嵌套循環(huán)計(jì)算方法。本質(zhì)上是將其中一些循環(huán)復(fù)制到內(nèi)存系統(tǒng)的各層,以最大限度地重復(fù)使用每層的內(nèi)存層次結(jié)構(gòu),并盡量減少數(shù)據(jù)搬運(yùn)。
我們還研究了稀疏性,在壓縮方面很不錯(cuò)。它基本上增加了內(nèi)存帶寬和通信帶寬,減少了內(nèi)存和通信的能量。稀疏性發(fā)展的下一個(gè)層次是:當(dāng)你有一個(gè)零值,只需單獨(dú)發(fā)送一條線表示零值,而不必在每個(gè)循環(huán)中切換到8或16位。
Ampere架構(gòu)可以通過使用結(jié)構(gòu)化稀疏來重用乘法器,這是一種很有效的方法,只需要幾個(gè)多路復(fù)用器的開銷(基本上可以忽略不計(jì))。在進(jìn)行指針操作時(shí),我們也可以重用乘法器,從中可獲得2倍的性能。數(shù)值表征(number representation)非常重要。我們從EIE開始(譯者注:Efficient Inference Engine,韓松博士在ISCA 2016上的論文。實(shí)現(xiàn)了壓縮的稀疏神經(jīng)網(wǎng)絡(luò)的硬件加速。與其近似方法的ESE獲得了FPGA2017的最佳論文。),試圖做碼本,但這使得數(shù)學(xué)上的縮放很昂貴。
最后,在加速器里試驗(yàn)成功的技術(shù)最終會被運(yùn)用到GPU中。這是一種很好的測試方式,我們認(rèn)為,GPU是一個(gè)針對特定領(lǐng)域硬件的平臺,它的內(nèi)存系統(tǒng)非常好,網(wǎng)絡(luò)流暢,能夠讓深度學(xué)習(xí)應(yīng)用運(yùn)行得非常快。
05?深度學(xué)習(xí)硬件的未來
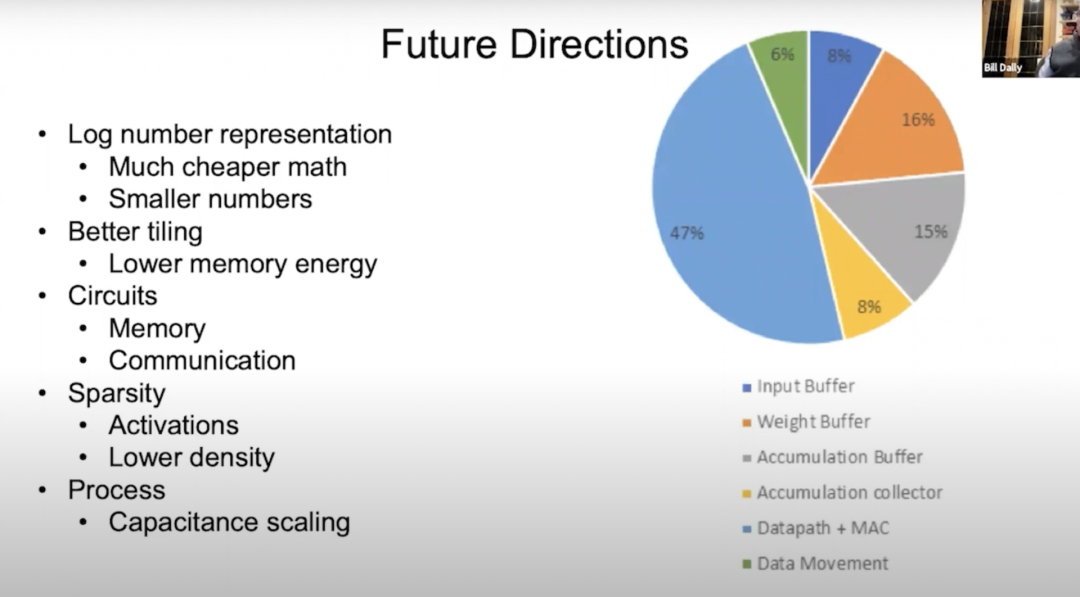
Future Directions
接下來談?wù)勆疃葘W(xué)習(xí)硬件的未來。上圖是一個(gè)能量流向餅狀圖,從中可以看到大部分都流向于數(shù)據(jù)路徑,其背后有大約50%是關(guān)于數(shù)學(xué)運(yùn)算,所以我們想讓數(shù)學(xué)運(yùn)算的能量消耗更少;剩下很多流向內(nèi)存和數(shù)據(jù)搬運(yùn)。其中綠色的是數(shù)據(jù)搬運(yùn),其余部分是輸入緩沖區(qū)、權(quán)重緩沖區(qū)、累加緩沖區(qū)和累加收集器,占比都有不同。
我們正在研究降低數(shù)學(xué)運(yùn)算的能量消耗,最好的一個(gè)辦法就是將其轉(zhuǎn)移到對數(shù)系統(tǒng)。因?yàn)樵趯?shù)系統(tǒng)中,乘法變成了加法,而加法的耗能通常要低得多。另一個(gè)辦法是轉(zhuǎn)為更小的數(shù)值,這一點(diǎn)可以通過VS-Quant實(shí)現(xiàn)。通過更精確地量化,我們可以用較低的精度數(shù)從神經(jīng)網(wǎng)絡(luò)中獲得同等的精度。
我們希望能將平鋪?zhàn)龅酶茫热缭谀承┣闆r下,可能會在內(nèi)存層次結(jié)構(gòu)中添加更多層,這樣就可以降低內(nèi)存能量,也可以使內(nèi)存電路和通信電路的效果更好。
在Ampere架構(gòu)上,我們已經(jīng)在結(jié)構(gòu)化稀疏的工作是一個(gè)很好的開始,但我認(rèn)為我們可以通過降低密度或選擇多個(gè)密度來調(diào)整激活和權(quán)重,以此做得更好。
隨著研究的深入,工藝技術(shù)也會帶來一些電容縮放的進(jìn)展。
06?總結(jié)
2012年發(fā)布Kepler架構(gòu)以來,GPU的推理性能(inference performance)每年都在翻倍增長。發(fā)展到現(xiàn)在,很大程度上要?dú)w功于不斷更好的數(shù)字表示。本次我們談了很多內(nèi)容,比如從Kepler架構(gòu)的FP32到FP16到Int8再到Int4;談到了通過分配指令開銷,使用更復(fù)雜的點(diǎn)積;談到了Pascal架構(gòu),Volta架構(gòu)中的半精密矩陣乘累加,Turing架構(gòu)中的整數(shù)矩陣乘累加,還有Ampere架構(gòu)和結(jié)構(gòu)稀疏。
關(guān)于Plumbing我談得很少,但Plumbing卻非常重要。通過Plumbing來布置片上內(nèi)存系統(tǒng)和網(wǎng)絡(luò),由此可以充分利用強(qiáng)大的Tensor Cores(張量核心)。對于Tensor Cores來說,使其在Turing架構(gòu)中每秒執(zhí)行一千兆的操作,并將數(shù)據(jù)輸入到執(zhí)行通用基準(zhǔn)測試中,以此來安排分支存儲器、片上存儲器和它們之間的互連互通以及正常運(yùn)行,都非常重要。
展望未來,我們準(zhǔn)備嘗試將各種新技術(shù)應(yīng)用到加速器中。前面提到,我們已經(jīng)就稀疏性和平鋪技術(shù)進(jìn)行了多次實(shí)驗(yàn),并在MAGNet項(xiàng)目中試驗(yàn)了不同的平鋪技術(shù)和數(shù)值表示等等。但我們?nèi)匀槐陡袎毫Γ驗(yàn)樯疃葘W(xué)習(xí)的進(jìn)步其實(shí)取決于硬件性能的持續(xù)提升,讓GPU的推理性能每年都翻一番是一項(xiàng)巨大的挑戰(zhàn)。
其實(shí)我們手里的牌打得差不多了,這意味著我們必須開始研發(fā)新的技術(shù),以下是我認(rèn)為值得關(guān)注的四個(gè)方向:首先,研究新的數(shù)字表示,比如對數(shù)(Log number),以及比EasyQuant更加巧妙的量化方案;其次,繼續(xù)深入研究稀疏性;然后,研究存儲電路和通信電路;最后,改良現(xiàn)有的工藝技術(shù)。
07?答聽眾問
Dejan Milojicic:需要多大的矩陣卷積才能將Winograd算法轉(zhuǎn)換成更高效的卷積實(shí)現(xiàn)?
Bill Dally:我認(rèn)為,3×3的矩陣卷積就很高效。當(dāng)然,卷積越大,效率越高。
Dejan Milojicic:高帶寬存儲器(High Bandwidth Memory, HBM)的內(nèi)存帶寬是如何計(jì)算的?是通過所有的GPU核同時(shí)訪問內(nèi)存嗎?
Bill Dally:每個(gè)HBM堆棧都有一個(gè)單獨(dú)的幀緩沖區(qū),像Ampere架構(gòu)有六個(gè)堆棧。我們的內(nèi)存帶寬是通過每個(gè)內(nèi)存控制器以全帶寬運(yùn)行來計(jì)算的。各個(gè)GPU核之間都有一個(gè)緩存層,然后我們的片上網(wǎng)絡(luò)的帶寬是HBM帶寬好幾倍,所以基本上只需運(yùn)行一小部分的流式多處理器就能使HBM達(dá)到飽和。
Dejan Milojicic:帶有NVLink的分布式計(jì)算如何工作?誰來決定具體執(zhí)行哪一個(gè)計(jì)算?在多個(gè)GPU上做scatter-gather時(shí),哪些地方會產(chǎn)生開銷以及會產(chǎn)生哪些開銷?
Bill Dally:程序員會決定把數(shù)據(jù)和線程放在什么位置,而你只需在GPU上啟動線程和數(shù)據(jù)以及確定它們的運(yùn)行位置。采用NVLink進(jìn)行連接的系統(tǒng)具備一大優(yōu)勢,那就是它是一個(gè)共享的地址空間,傳輸相對較小數(shù)據(jù)時(shí)的開銷也相當(dāng)小,所以我們在網(wǎng)絡(luò)中采取集群通信。
通常情況下,如果你在深度學(xué)習(xí)中做數(shù)據(jù)并行,那么每個(gè)GPU都會運(yùn)行相同的網(wǎng)絡(luò),但處理的是同一數(shù)據(jù)集的不同部分,它們會各自累積權(quán)重梯度,之后你再共享各個(gè)GPU上的梯度并累積所有梯度,然后添加到權(quán)重中。集群通信就非常擅長處理這樣的工作。
Dejan Milojicic:我們到底是應(yīng)該為所有應(yīng)用創(chuàng)建通用的深度學(xué)習(xí)加速器,還是分別創(chuàng)建專用的加速器,比如視覺加速器或自然語言處理加速器?
Bill Dally:在不影響效率的情況下,我認(rèn)為加速器當(dāng)然越通用越好,英偉達(dá)的GPU在加速深度學(xué)習(xí)效率方面堪比專用加速器。真正重要的是,機(jī)器學(xué)習(xí)領(lǐng)域正在以驚人的速度向前發(fā)展。
幾年前,大家還在使用循環(huán)神經(jīng)網(wǎng)絡(luò)處理語言,然后Transformer出現(xiàn)并以迅雷不及掩耳之速取代了RNN,轉(zhuǎn)眼間所有人都開始使用Transformer進(jìn)行自然語言處理。同樣,就在幾年前,每個(gè)人都在使用CNN來處理圖像,雖然現(xiàn)在仍有不少人在使用卷積神經(jīng)網(wǎng)絡(luò),但越來越多人開始使用Transformer來處理圖像。
因此,我并不支持產(chǎn)品過度專用化或者為某一網(wǎng)絡(luò)創(chuàng)建專用加速器,因?yàn)楫a(chǎn)品的設(shè)計(jì)周期通常需要持續(xù)好幾年時(shí)間,而在此期間,人們很可能已經(jīng)不再使用這種網(wǎng)絡(luò)了。我們必須具備敏銳的眼光,及時(shí)洞察行業(yè)變化,因?yàn)樗鼤r(shí)刻都在以驚人的速度發(fā)展。
Dejan Milojicic:摩爾定律對GPU性能和內(nèi)存占用有何影響?
Bill Dally:摩爾定律認(rèn)為,晶體管成本會隨時(shí)間逐年降低。今天,集成電路上可容納的晶體管數(shù)量確實(shí)越來越多,芯片制程也實(shí)現(xiàn)了從16納米到7納米的飛躍,集成電路上的晶體管密度越來越大,但單個(gè)晶體管的價(jià)格卻并未降低。因此,我認(rèn)為摩爾定律有些過時(shí)了。
盡管如此,集成電路上能容納更多的晶體管仍是一件好事,這樣我們就能夠建造更大規(guī)模的GPU。雖然大型GPU的能耗也會更高,價(jià)格也更加昂貴,但這總歸是一件好事,因?yàn)槲覀兡軌驑?gòu)建一些從前無法構(gòu)建的產(chǎn)品。
Dejan Milojicic:如果開發(fā)者比較重視PyTorch這樣的框架,那么他們應(yīng)該從硬件的進(jìn)步中學(xué)習(xí)什么來讓自己的深度學(xué)習(xí)模型運(yùn)行更高效?
Bill Dally:這個(gè)問題很難回答。框架在抽象硬件方面做得很好,但仍然有一些影響模型運(yùn)行速度的因素值得研究。我們可以嘗試去做的是,當(dāng)想出一項(xiàng)更好的技術(shù)時(shí),比如更好的數(shù)值表示方法,可以嘗試將各種不同的技術(shù)與框架相結(jié)合,看看哪種方法更加有效,這是研發(fā)工作不可或缺的環(huán)節(jié)。
Dejan Milojicic:英偉達(dá)是否正在實(shí)驗(yàn)新的封裝方法?
Bill Dally:我們一直在對各種封裝技術(shù)進(jìn)行各種實(shí)驗(yàn),弄清楚它們能做什么和不能做什么,以便在合適的時(shí)機(jī)將它們部署到產(chǎn)品。比如其中一些項(xiàng)目在研究多芯片模塊,用焊接凸點(diǎn)、混合鍵合做芯片堆疊,其實(shí)有很多簡潔的封裝技術(shù)。
Dejan Milojicic:英偉達(dá)的Tensor Core和谷歌的TPU相比,誰更勝一籌?
Bill Dally:我們對谷歌最新的TPU并不了解,但他們之前推出的TPU都是專用引擎,基本上都內(nèi)置了大型的乘加器陣列。
TPU獨(dú)立的單元來處理非線性函數(shù)和批量歸一化(batch norm)之類的事情,但我們的方法是建立一個(gè)非常通用的計(jì)算單元流式多處理器(SM),只需非常通用的指令就可以讓它做任何事情,然后再用Tensor Core來加速矩陣乘法部分。因此,Tensor Core和谷歌的TPU都有類似的乘加器陣列,只是我們使用的陣列相對較小。
Dejan Milojicic:英偉達(dá)最大的對手是誰?
Bill Dally:英偉達(dá)從來不跟其他公司比較,最大的對手就是我們自己,我們也在不斷地挑戰(zhàn)自己,我認(rèn)為這才是正確的態(tài)度。如果我們一味地把其他人視作競爭對手,反而放緩我們前進(jìn)的腳步。不必過多關(guān)注其他人在做什么,我們真正應(yīng)該關(guān)注的是哪些事情是可能實(shí)現(xiàn)的。我們所做的事就像在追求光速,我們更關(guān)注怎樣才能做到最好,以及距離光速還有多遠(yuǎn),這才是真正的挑戰(zhàn)。
Dejan Milojicic:你對量子計(jì)算有何看法?量子模擬是深度學(xué)習(xí)挑戰(zhàn)的自然延伸嗎?
Bill Dally:2021年3月,我們發(fā)布了一款名為“cuQuantum”的軟件開發(fā)工具包。Google之前也研制出了具有53個(gè)量子比特的計(jì)算機(jī),并稱自己實(shí)現(xiàn)了“量子優(yōu)越性”。一些傳統(tǒng)計(jì)算機(jī)無法完成的計(jì)算,用cuQuantum在五分鐘內(nèi)就能完成了。所以,如果想真正做到精準(zhǔn)的量子算法,而不是今天的嘈雜中型量子(Noisy Intermediate-Scale Quantum,NIST)計(jì)算,GPU應(yīng)該是最佳選擇。
英偉達(dá)的傳統(tǒng)GPU計(jì)算機(jī)是目前最快的量子計(jì)算機(jī)之一,阿里巴巴也在類似的經(jīng)典計(jì)算中取得了不錯(cuò)的成績,這恰好印證了我們的結(jié)論。我們對量子計(jì)算的看法是:英偉達(dá)不會因?yàn)檫@一技術(shù)領(lǐng)域的任何動態(tài)而感到驚訝。
實(shí)際上,我們還成立了一個(gè)研究小組來追蹤量子計(jì)算領(lǐng)域的前沿動態(tài),比如IBM宣布研制出了具有127個(gè)量子比特的芯片。我們也一直在跟蹤量子比特?cái)?shù)量和相干時(shí)間(coherence time)等方面的進(jìn)展。
考慮到所需的量子比特?cái)?shù)量、量子比特的準(zhǔn)確性、噪音對量子的干擾以及量子糾錯(cuò)所需的開銷,我認(rèn)為未來五到十年內(nèi),量子計(jì)算都無法實(shí)現(xiàn)商用。
我最樂觀的看法是,大概五年后,人們將開始進(jìn)行量子化學(xué)模擬,這應(yīng)該最有可能做到的。但在那之前,還有很多物理上的難題需要解決。很多人還沒有意識到,量子計(jì)算機(jī)就是模擬計(jì)算機(jī),而模擬計(jì)算機(jī)需要非常精確且易于隔離,否則任何與環(huán)境的耦合都會導(dǎo)致結(jié)果不一致。
Dejan Milojicic:在你看來,機(jī)器何時(shí)才能達(dá)到通用人工智能(AGI)的水平?
Bill Dally:我對這個(gè)問題的看法比較消極。試看一些比較成功的人工智能用例,例如神經(jīng)網(wǎng)絡(luò),其實(shí)它本質(zhì)上就是通用函數(shù)擬合器。神經(jīng)網(wǎng)絡(luò)可以通過觀察來學(xué)習(xí)一個(gè)函數(shù),所以它的價(jià)值還是體現(xiàn)在人工感知而不是人工智能。
雖然我們目前已經(jīng)取得了不錯(cuò)的成果,但還是可以繼續(xù)研究如何使用人工智能和深度學(xué)習(xí)來提高生產(chǎn)力,從而改善醫(yī)療、教育,給人們帶來更加美好的生活。其實(shí),我們不需要AGI來做到這些,而應(yīng)該重視如何最大程度地利用現(xiàn)有技術(shù)。距離AGI還有很長的路要走,我們也必須弄清到底什么是AGI。
編輯:黃飛
?




















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論