 電子發(fā)燒友App
電子發(fā)燒友App


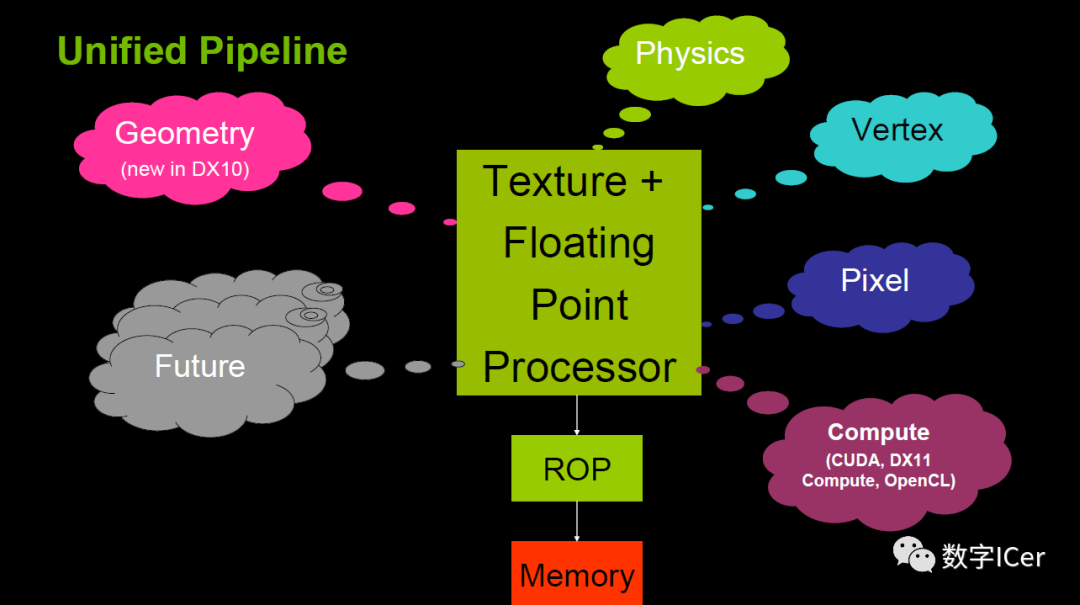
四、GPU運(yùn)行機(jī)制
4.1 GPU渲染總覽
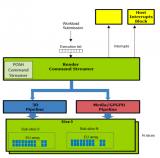
由上一章可得知,現(xiàn)代GPU有著相似的結(jié)構(gòu),有很多相同的部件,在運(yùn)行機(jī)制上,也有很多共同點(diǎn)。下面是Fermi架構(gòu)的運(yùn)行機(jī)制總覽圖:

從Fermi開始NVIDIA使用類似的原理架構(gòu),使用一個Giga Thread Engine來管理所有正在進(jìn)行的工作,GPU被劃分成多個GPCs(Graphics Processing Cluster),每個GPC擁有多個SM(SMX、SMM)和一個光柵化引擎(Raster Engine),它們其中有很多的連接,最顯著的是Crossbar,它可以連接GPCs和其它功能性模塊(例如ROP或其他子系統(tǒng))。 程序員編寫的shader是在SM上完成的。每個SM包含許多為線程執(zhí)行數(shù)學(xué)運(yùn)算的Core(核心)。例如,一個線程可以是頂點(diǎn)或像素著色器調(diào)用。這些Core和其它單元由Warp Scheduler驅(qū)動,Warp Scheduler管理一組32個線程作為Warp(線程束)并將要執(zhí)行的指令移交給Dispatch Units。 GPU中實(shí)際有多少這些單元(每個GPC有多少個SM,多少個GPC ......)取決于芯片配置本身。例如,GM204有4個GPC,每個GPC有4個SM,但Tegra X1有1個GPC和2個SM,它們均采用Maxwell設(shè)計。SM設(shè)計本身(內(nèi)核數(shù)量,指令單位,調(diào)度程序......)也隨著時間的推移而發(fā)生變化,并幫助使芯片變得如此高效,可以從高端臺式機(jī)擴(kuò)展到筆記本電腦移動。
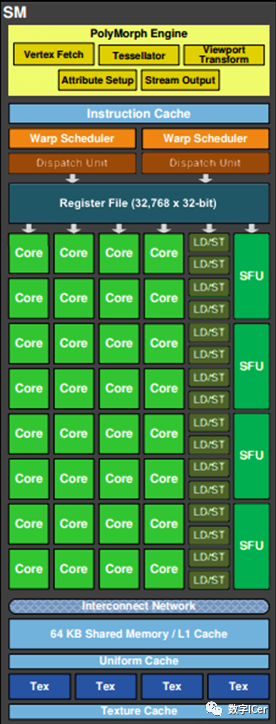
如上圖,對于某些GPU(如Fermi部分型號)的單個SM,包含:
32個運(yùn)算核心 (Core,也叫流處理器Stream Processor)
16個LD/ST(load/store)模塊來加載和存儲數(shù)據(jù)
4個SFU(Special function units)執(zhí)行特殊數(shù)學(xué)運(yùn)算(sin、cos、log等)
128KB寄存器(Register File)
64KB L1緩存
全局內(nèi)存緩存(Uniform Cache)
紋理讀取單元
紋理緩存(Texture Cache)
PolyMorph Engine:多邊形引擎負(fù)責(zé)屬性裝配(attribute Setup)、頂點(diǎn)拉取(VertexFetch)、曲面細(xì)分、柵格化(這個模塊可以理解專門處理頂點(diǎn)相關(guān)的東西)。
2個Warp Schedulers:這個模塊負(fù)責(zé)warp調(diào)度,一個warp由32個線程組成,warp調(diào)度器的指令通過Dispatch Units送到Core執(zhí)行。
指令緩存(Instruction Cache)
內(nèi)部鏈接網(wǎng)絡(luò)(Interconnect Network)
4.2 GPU邏輯管線
了解上一節(jié)的部件和概念之后,可以深入闡述GPU的渲染過程和步驟。下面將以Fermi家族的SM為例,進(jìn)行邏輯管線的詳細(xì)說明。
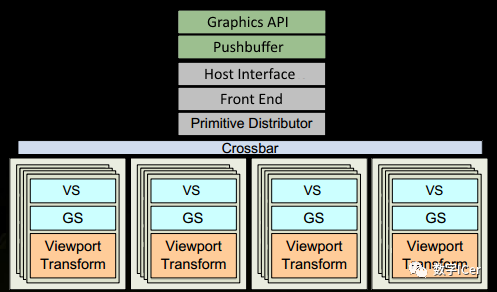
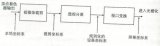
1、程序通過圖形API(DX、GL、WEBGL)發(fā)出drawcall指令,指令會被推送到驅(qū)動程序,驅(qū)動會檢查指令的合法性,然后會把指令放到GPU可以讀取的Pushbuffer中。 2、經(jīng)過一段時間或者顯式調(diào)用flush指令后,驅(qū)動程序把Pushbuffer的內(nèi)容發(fā)送給GPU,GPU通過主機(jī)接口(Host Interface)接受這些命令,并通過前端(Front End)處理這些命令。 3、在圖元分配器(Primitive Distributor)中開始工作分配,處理indexbuffer中的頂點(diǎn)產(chǎn)生三角形分成批次(batches),然后發(fā)送給多個PGCs。這一步的理解就是提交上來n個三角形,分配給這幾個PGC同時處理。
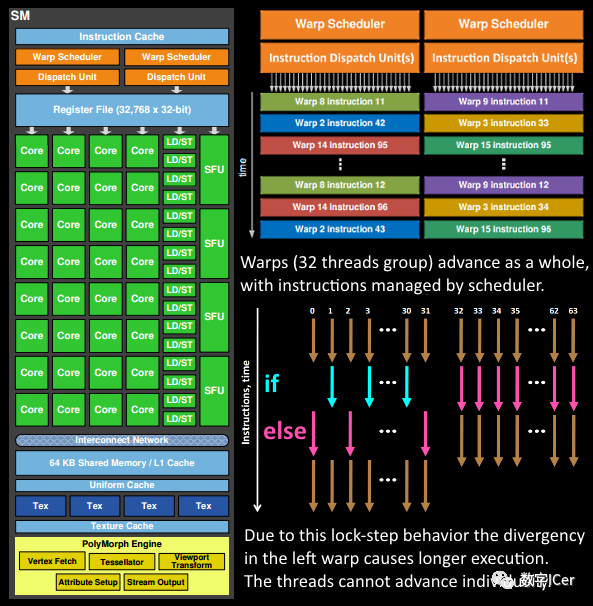
4、在GPC中,每個SM中的Poly Morph Engine負(fù)責(zé)通過三角形索引(triangle indices)取出三角形的數(shù)據(jù)(vertex data),即圖中的Vertex Fetch模塊。
5、在獲取數(shù)據(jù)之后,在SM中以32個線程為一組的線程束(Warp)來調(diào)度,來開始處理頂點(diǎn)數(shù)據(jù)。Warp是典型的單指令多線程(SIMT,SIMD單指令多數(shù)據(jù)的升級)的實(shí)現(xiàn),也就是32個線程同時執(zhí)行的指令是一模一樣的,只是線程數(shù)據(jù)不一樣,這樣的好處就是一個warp只需要一個套邏輯對指令進(jìn)行解碼和執(zhí)行就可以了,芯片可以做的更小更快,之所以可以這么做是由于GPU需要處理的任務(wù)是天然并行的。
6、SM的warp調(diào)度器會按照順序分發(fā)指令給整個warp,單個warp中的線程會鎖步(lock-step)執(zhí)行各自的指令,如果線程碰到不激活執(zhí)行的情況也會被遮掩(be masked out)。被遮掩的原因有很多,例如當(dāng)前的指令是if(true)的分支,但是當(dāng)前線程的數(shù)據(jù)的條件是false,或者循環(huán)的次數(shù)不一樣(比如for循環(huán)次數(shù)n不是常量,或被break提前終止了但是別的還在走),因此在shader中的分支會顯著增加時間消耗,在一個warp中的分支除非32個線程都走到if或者else里面,否則相當(dāng)于所有的分支都走了一遍,線程不能獨(dú)立執(zhí)行指令而是以warp為單位,而這些warp之間才是獨(dú)立的。
7、warp中的指令可以被一次完成,也可能經(jīng)過多次調(diào)度,例如通常SM中的LD/ST(加載存取)單元數(shù)量明顯少于基礎(chǔ)數(shù)學(xué)操作單元。
8、由于某些指令比其他指令需要更長的時間才能完成,特別是內(nèi)存加載,warp調(diào)度器可能會簡單地切換到另一個沒有內(nèi)存等待的warp,這是GPU如何克服內(nèi)存讀取延遲的關(guān)鍵,只是簡單地切換活動線程組。為了使這種切換非常快,調(diào)度器管理的所有warp在寄存器文件中都有自己的寄存器。這里就會有個矛盾產(chǎn)生,shader需要越多的寄存器,就會給warp留下越少的空間,就會產(chǎn)生越少的warp,這時候在碰到內(nèi)存延遲的時候就會只是等待,而沒有可以運(yùn)行的warp可以切換。
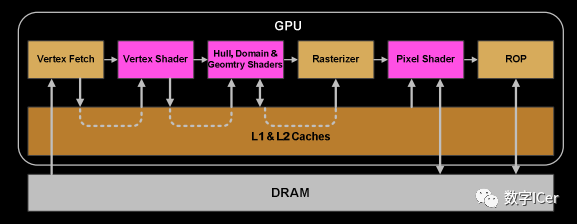
9、一旦warp完成了vertex-shader的所有指令,運(yùn)算結(jié)果會被Viewport Transform模塊處理,三角形會被裁剪然后準(zhǔn)備柵格化,GPU會使用L1和L2緩存來進(jìn)行vertex-shader和pixel-shader的數(shù)據(jù)通信。
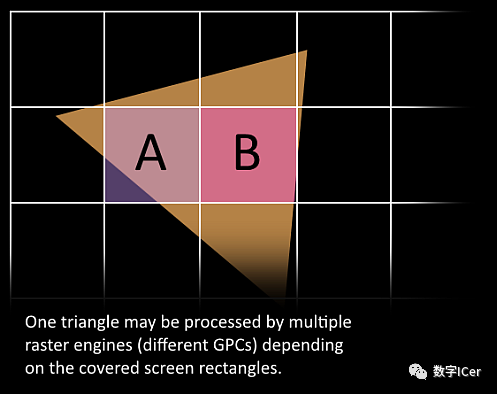
10、接下來這些三角形將被分割,再分配給多個GPC,三角形的范圍決定著它將被分配到哪個光柵引擎(raster engines),每個raster engines覆蓋了多個屏幕上的tile,這等于把三角形的渲染分配到多個tile上面。也就是像素階段就把按三角形劃分變成了按顯示的像素劃分了。
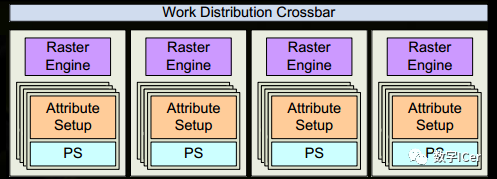
11、SM上的Attribute Setup保證了從vertex-shader來的數(shù)據(jù)經(jīng)過插值后是pixel-shade是可讀的。
12、GPC上的光柵引擎(raster engines)在它接收到的三角形上工作,來負(fù)責(zé)這些這些三角形的像素信息的生成(同時會處理裁剪Clipping、背面剔除和Early-Z剔除)。
13、32個像素線程將被分成一組,或者說8個2x2的像素塊,這是在像素著色器上面的最小工作單元,在這個像素線程內(nèi),如果沒有被三角形覆蓋就會被遮掩,SM中的warp調(diào)度器會管理像素著色器的任務(wù)。
14、接下來的階段就和vertex-shader中的邏輯步驟完全一樣,但是變成了在像素著色器線程中執(zhí)行。由于不耗費(fèi)任何性能可以獲取一個像素內(nèi)的值,導(dǎo)致鎖步執(zhí)行非常便利,所有的線程可以保證所有的指令可以在同一點(diǎn)。

15、最后一步,現(xiàn)在像素著色器已經(jīng)完成了顏色的計算還有深度值的計算,在這個點(diǎn)上,我們必須考慮三角形的原始api順序,然后才將數(shù)據(jù)移交給ROP(render output unit,渲染輸入單元),一個ROP內(nèi)部有很多ROP單元,在ROP單元中處理深度測試,和framebuffer的混合,深度和顏色的設(shè)置必須是原子操作,否則兩個不同的三角形在同一個像素點(diǎn)就會有沖突和錯誤。
4.3 GPU技術(shù)要點(diǎn)
由于上一節(jié)主要闡述GPU內(nèi)部的工作流程和機(jī)制,為了簡潔性,省略了很多知識點(diǎn)和過程,本節(jié)將對它們做進(jìn)一步補(bǔ)充說明。
4.3.1 SIMD和SIMT
SIMD(Single Instruction Multiple Data)是單指令多數(shù)據(jù),在GPU的ALU單元內(nèi),一條指令可以處理多維向量(一般是4D)的數(shù)據(jù)。比如,有以下shader指令:
float4 c = a + b; // a, b都是float4類型 對于沒有SIMD的處理單元,需要4條指令將4個float數(shù)值相加,匯編偽代碼如下:
ADD c.x, a.x, b.x ADD c.y, a.y, b.y ADD c.z, a.z, b.z ADD c.w, a.w, b.w 但有了SIMD技術(shù),只需一條指令即可處理完:
SIMD_ADD c, a, b
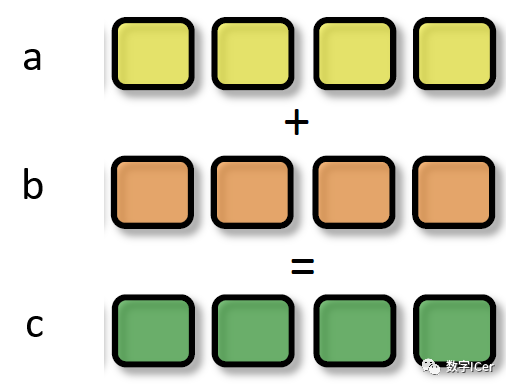
SIMT_ADD c, a, b 上述指令會被同時送入在單個SM中被編組的所有Core中,同時執(zhí)行運(yùn)算,但a、b?、c的值可以不一樣:
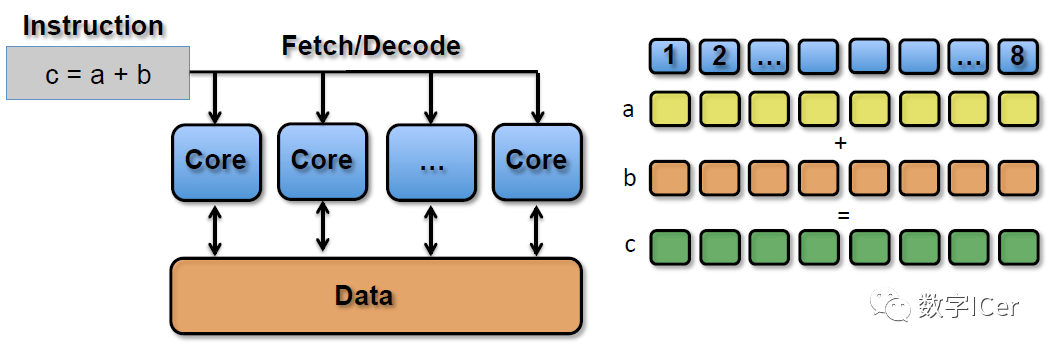
?
?
4.3.2 co-issue
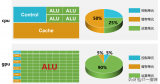
co-issue是為了解決SIMD運(yùn)算單元無法充分利用的問題。例如下圖,由于float數(shù)量的不同,ALU利用率從100%依次下降為75%、50%、25%。
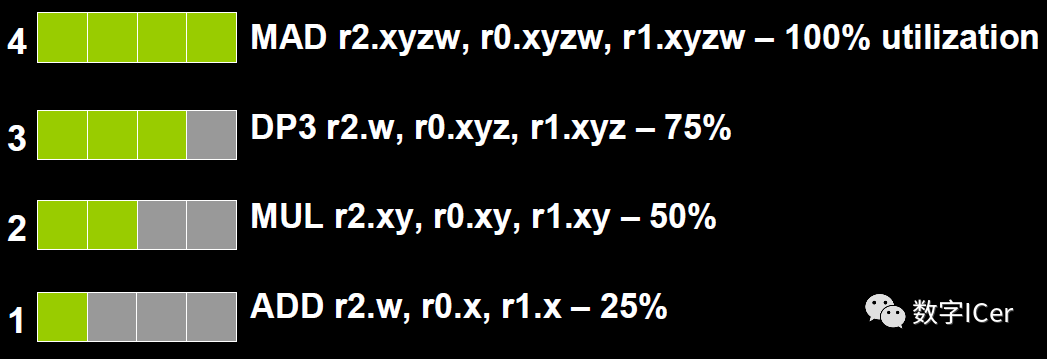
為了解決著色器在低維向量的利用率低的問題,可以通過合并1D與3D或2D與2D的指令。例如下圖,DP3指令用了3D數(shù)據(jù),ADD指令只有1D數(shù)據(jù),co-issue會自動將它們合并,在同一個ALU只需一個指令周期即可執(zhí)行完。
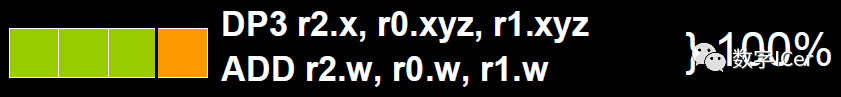
但是,對于向量運(yùn)算單元(Vector ALU),如果其中一個變量既是操作數(shù)又是存儲數(shù)的情況,無法啟用co-issue技術(shù):

于是標(biāo)量指令著色器(Scalar Instruction Shader)應(yīng)運(yùn)而生,它可以有效地組合任何向量,開啟co-issue技術(shù),充分發(fā)揮SIMD的優(yōu)勢。
4.3.3 if - else語句
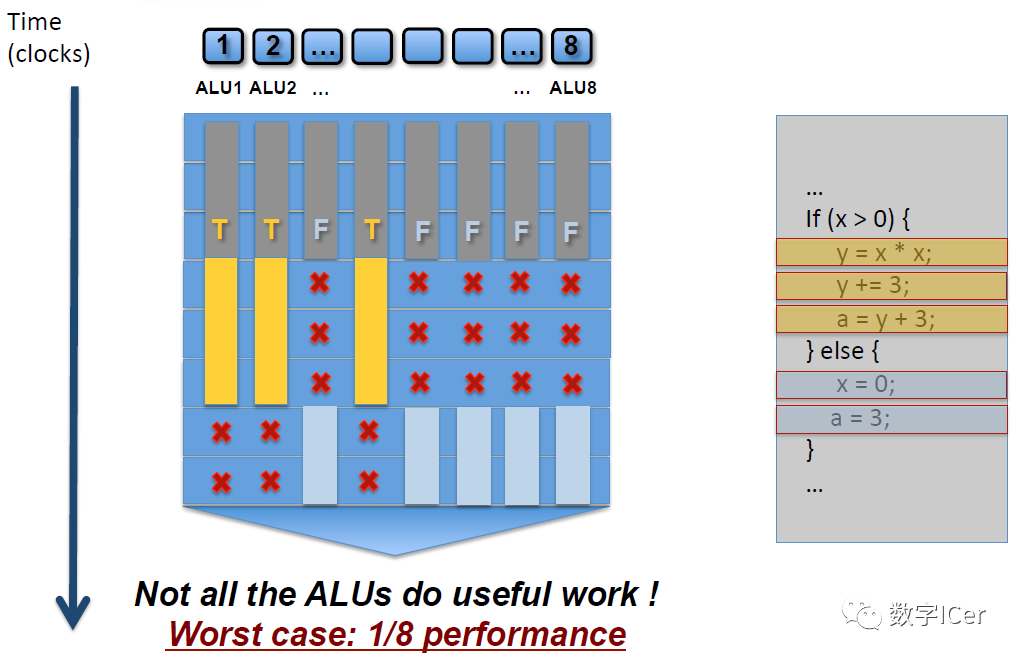
如上圖,SM中有8個ALU(Core),由于SIMD的特性,每個ALU的數(shù)據(jù)不一樣,導(dǎo)致if-else語句在某些ALU中執(zhí)行的是true分支(黃色),有些ALU執(zhí)行的是false分支(灰藍(lán)色),這樣導(dǎo)致很多ALU的執(zhí)行周期被浪費(fèi)掉了(即masked out),拉長了整個執(zhí)行周期。最壞的情況,同一個SM中只有1/8(8是同一個SM的線程數(shù),不同架構(gòu)的GPU有所不同)的利用率。 同樣,for循環(huán)也會導(dǎo)致類似的情形,例如以下shader代碼:
void func(int count, int breakNum) { for(int i=0; i
4.3.4 Early-Z
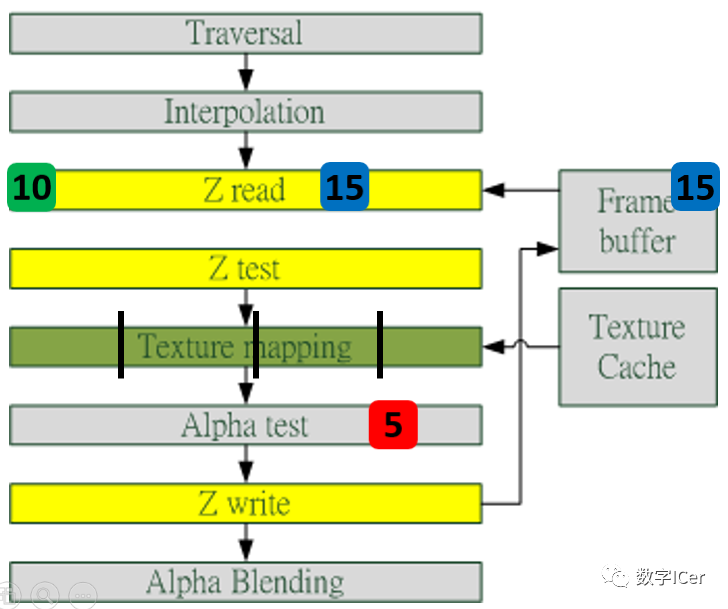
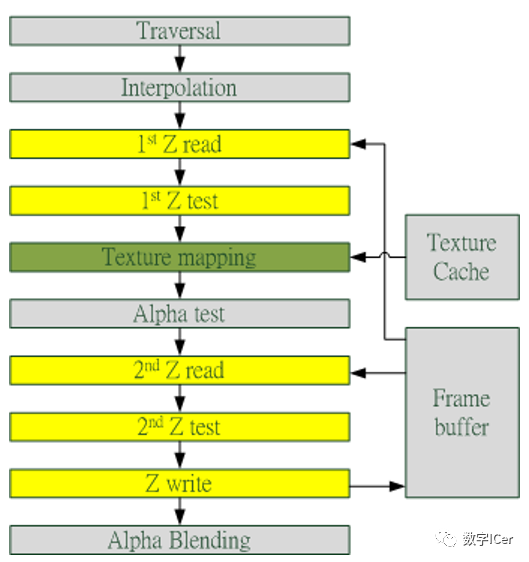
早期GPU的渲染管線的深度測試是在像素著色器之后才執(zhí)行(下圖),這樣會造成很多本不可見的像素執(zhí)行了耗性能的像素著色器計算。
后來,為了減少像素著色器的額外消耗,將深度測試提至像素著色器之前(下圖),這就是Early-Z技術(shù)的由來。
Early-Z技術(shù)可以將很多無效的像素提前剔除,避免它們進(jìn)入耗時嚴(yán)重的像素著色器。Early-Z剔除的最小單位不是1像素,而是像素塊(pixel quad,2x2個像素,詳見[4.3.6 ](#4.3.6 像素塊(pixel quad)))。 但是,以下情況會導(dǎo)致Early-Z失效:
開啟Alpha Test:由于Alpha Test需要在像素著色器后面的Alpha Test階段比較,所以無法在像素著色器之前就決定該像素是否被剔除。
開啟Alpha Blend:啟用了Alpha混合的像素很多需要與frame buffer做混合,無法執(zhí)行深度測試,也就無法利用Early-Z技術(shù)。
開啟Tex Kill:即在shader代碼中有像素摒棄指令(DX的discard,OpenGL的clip)。
關(guān)閉深度測試。Early-Z是建立在深度測試看開啟的條件下,如果關(guān)閉了深度測試,也就無法啟用Early-Z技術(shù)。
開啟Multi-Sampling:多采樣會影響周邊像素,而Early-Z階段無法得知周邊像素是否被裁剪,故無法提前剔除。
以及其它任何導(dǎo)致需要混合后面顏色的操作。
此外,Early-Z技術(shù)會導(dǎo)致一個問題:深度數(shù)據(jù)沖突(depth data hazard)。
例子要結(jié)合上圖,假設(shè)數(shù)值深度值5已經(jīng)經(jīng)過Early-Z即將寫入Frame Buffer,而深度值10剛好處于Early-Z階段,讀取并對比當(dāng)前緩存的深度值15,結(jié)果就是10通過了Early-Z測試,會覆蓋掉比自己小的深度值5,最終frame buffer的深度值是錯誤的結(jié)果。 避免深度數(shù)據(jù)沖突的方法之一是在寫入深度值之前,再次與frame buffer的值進(jìn)行對比:
4.3.5 統(tǒng)一著色器架構(gòu)(Unified shader Architecture)
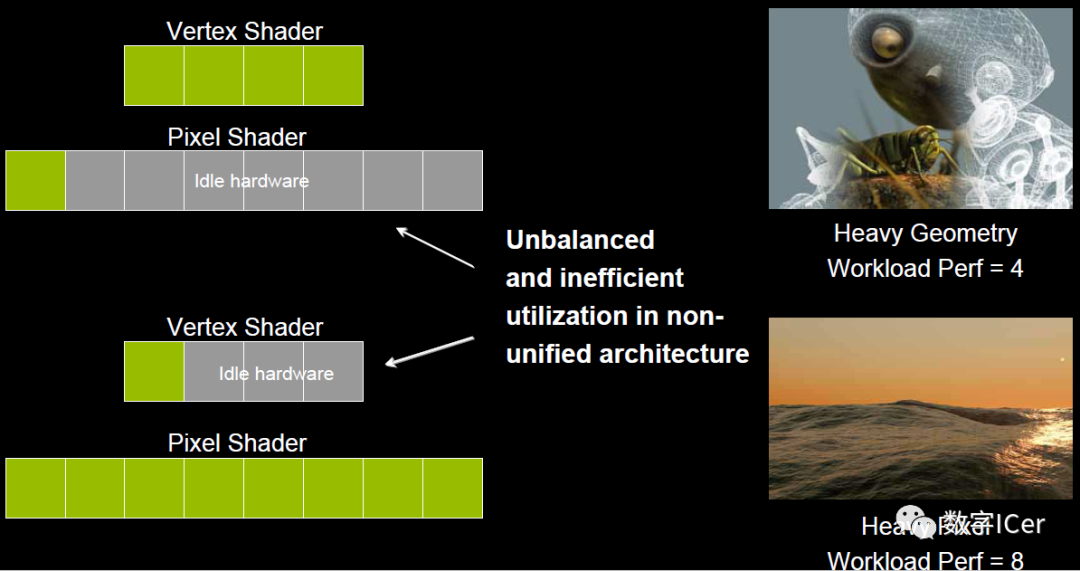
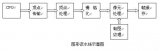
在早期的GPU,頂點(diǎn)著色器和像素著色器的硬件結(jié)構(gòu)是獨(dú)立的,它們各有各的寄存器、運(yùn)算單元等部件。這樣很多時候,會造成頂點(diǎn)著色器與像素著色器之間任務(wù)的不平衡。對于頂點(diǎn)數(shù)量多的任務(wù),像素著色器空閑狀態(tài)多;對于像素多的任務(wù),頂點(diǎn)著色器的空閑狀態(tài)多(下圖)。
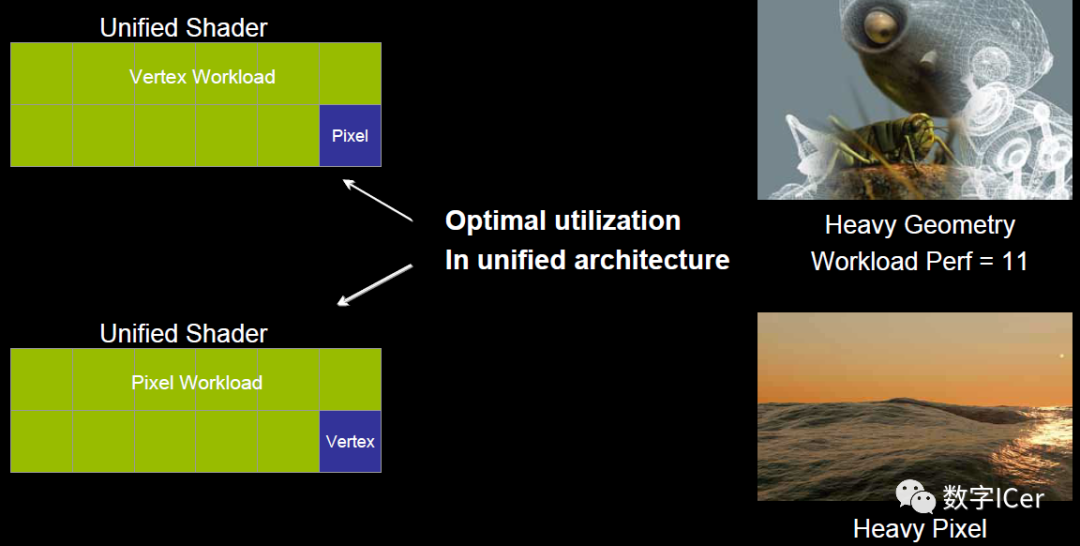
于是,為了解決VS和PS之間的不平衡,引入了統(tǒng)一著色器架構(gòu)(Unified shader Architecture)。用了此架構(gòu)的GPU,VS和PS用的都是相同的Core。也就是,同一個Core既可以是VS又可以是PS。
這樣就解決了不同類型著色器之間的不平衡問題,還可以減少GPU的硬件單元,壓縮物理尺寸和耗電量。此外,VS、PS可還可以和其它著色器(幾何、曲面、計算)統(tǒng)一為一體。
4.3.6 像素塊(Pixel Quad)
上一節(jié)步驟13提到:
32個像素線程將被分成一組,或者說8個2x2的像素塊,這是在像素著色器上面的最小工作單元,在這個像素線程內(nèi),如果沒有被三角形覆蓋就會被遮掩,SM中的warp調(diào)度器會管理像素著色器的任務(wù)。
也就是說,在像素著色器中,會將相鄰的四個像素作為不可分隔的一組,送入同一個SM內(nèi)4個不同的Core。
為什么像素著色器處理的最小單元是2x2的像素塊? 筆者推測有以下原因: 1、簡化和加速像素分派的工作。 2、精簡SM的架構(gòu),減少硬件單元數(shù)量和尺寸。 3、降低功耗,提高效能比。 4、無效像素雖然不會被存儲結(jié)果,但可輔助有效像素求導(dǎo)函數(shù)。詳見4.6 利用擴(kuò)展例證。
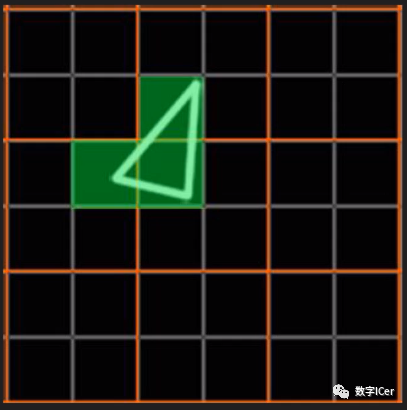
這種設(shè)計雖然有其優(yōu)勢,但同時,也會激化過繪制(Over Draw)的情況,損耗額外的性能。比如下圖中,白色的三角形只占用了3個像素(綠色),按我們普通的思維,只需要3個Core繪制3次就可以了。
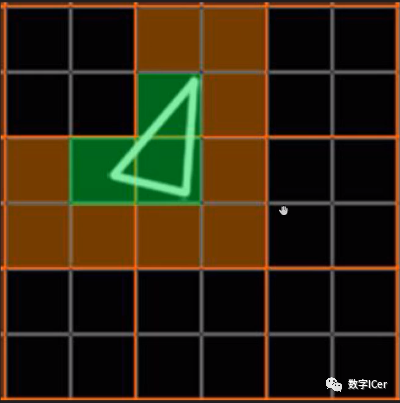
但是,由于上面的3個像素分別占據(jù)了不同的像素塊(橙色分隔),實(shí)際上需要占用12個Core繪制12次(下圖)。
這就會額外消耗300%的硬件性能,導(dǎo)致了更加嚴(yán)重的過繪制情況。
參考文獻(xiàn)
編輯:黃飛
?


















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論