 電子發(fā)燒友App
電子發(fā)燒友App


去年的時候,拋磚引玉的寫了一篇“硬件定義軟件?還是軟件定義硬件?”的文章,現(xiàn)在再看,發(fā)現(xiàn)很多考慮不全面不深刻的地方。繼續(xù)拋磚,與大家深入探討此話題。
今天這篇文章,我們主要關(guān)注如下話題:
超異構(gòu)計算,為什么需要開放生態(tài)?
開放生態(tài)應(yīng)該由硬件定義還是軟件定義?
什么樣的生態(tài)才算開放?
1.1 CPU指令集架構(gòu)ISA
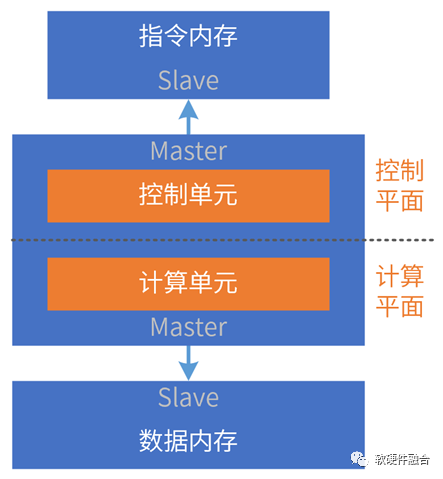
ISA(Instruction Set Architecture,指令集架構(gòu)),是計算機(jī)體系結(jié)構(gòu)與編程相關(guān)的部分(不包含組成和實(shí)現(xiàn))。ISA定義了:指令集、數(shù)據(jù)類型、寄存器、尋址模式、內(nèi)存管理、I/O模型等。
CPU圖靈完備,是可自運(yùn)行的處理器:CPU主動從指令內(nèi)存讀取指令流,然后譯碼后執(zhí)行;指令執(zhí)行會涉及到數(shù)據(jù)的載入(Load)、計算和存儲(Store)。
我們可以把處理器簡單地分為控制平面和計算平面兩部分。
CPU是指令流驅(qū)動計算的處理引擎。
1.2 (CPU視角的)GPU架構(gòu)
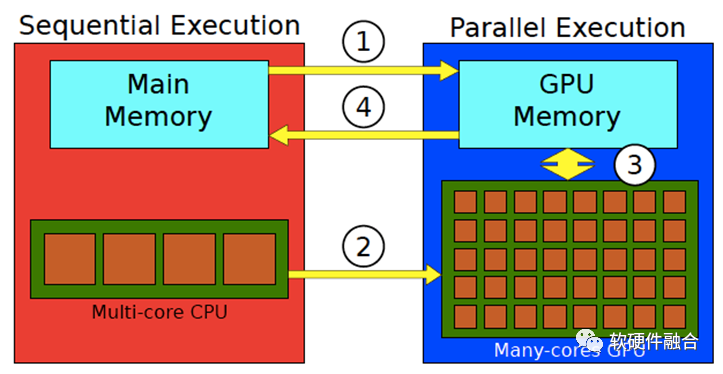
架構(gòu)側(cè)重軟硬件之間的交互“接口”,而微架構(gòu)側(cè)重具體實(shí)現(xiàn)。因此,GPU架構(gòu)通常指的是CPU視角看到的GPU“接口”。從CPU視角看GPU的處理流程:
CPU把數(shù)據(jù)準(zhǔn)備好,并保存在CPU內(nèi)存中;
將待處理的數(shù)據(jù)從CPU內(nèi)存復(fù)制到GPU內(nèi)存(處理①);
CPU指示GPU工作,配置并啟動GPU內(nèi)核(處理②);
多個GPU內(nèi)核并行執(zhí)行,處理準(zhǔn)備好的數(shù)據(jù)(圖中的③處理);
處理完成后,將處理結(jié)果復(fù)制回CPU內(nèi)存(處理④);
CPU把GPU的結(jié)果進(jìn)行后續(xù)處理。
1.3 ASIC專用處理引擎
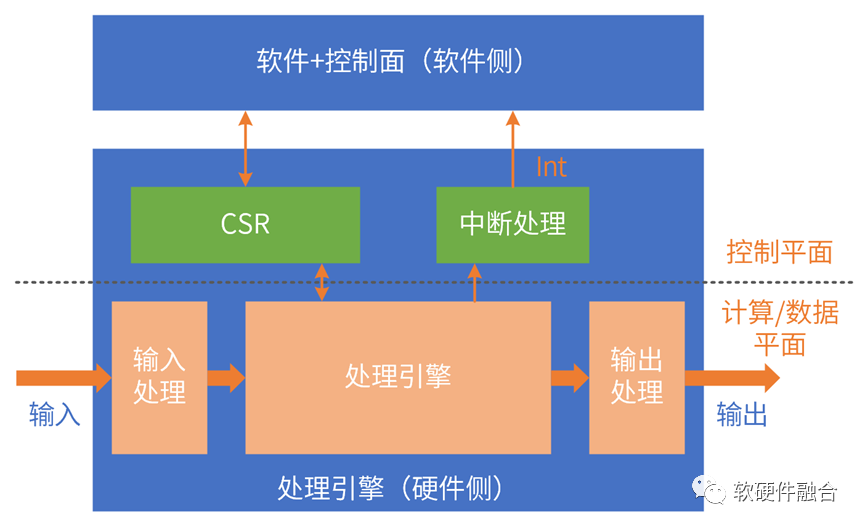
ASIC功能邏輯完全確定:通過驅(qū)動程序和CSR和可配置表項交互,以此來控制硬件運(yùn)行。
ASIC覆蓋的場景較小,并且類型多種多樣;即使同一場景,不同廠家實(shí)現(xiàn)依然存在差別;ASIC場景碎片化,毫無生態(tài)可言。
和GPU類似,ASIC的運(yùn)行依然需要CPU的參與:
數(shù)據(jù)的輸入:數(shù)據(jù)在內(nèi)存準(zhǔn)備好,CPU控制ASIC引擎的輸入邏輯,把數(shù)據(jù)從內(nèi)存搬到處理引擎;
ASIC的運(yùn)行控制:控制CSR、可配置表項、中斷等;
數(shù)據(jù)的輸出:CPU控制ASIC引擎的輸出邏輯,把數(shù)據(jù)從引擎搬到內(nèi)存,等待后續(xù)處理。
ASIC是數(shù)據(jù)流驅(qū)動計算的處理引擎。
1.4 DSA領(lǐng)域?qū)S眉軜?gòu)
DSA是在ASIC基礎(chǔ)上的回調(diào),具有一定的可編程能力,覆蓋場景更多,性能和ASIC同量級。
DSA經(jīng)典案例:
AI-DSA,如谷歌TPU;
網(wǎng)絡(luò)DSA,如Intel Barefoot P4-DSA網(wǎng)絡(luò)交換芯片。
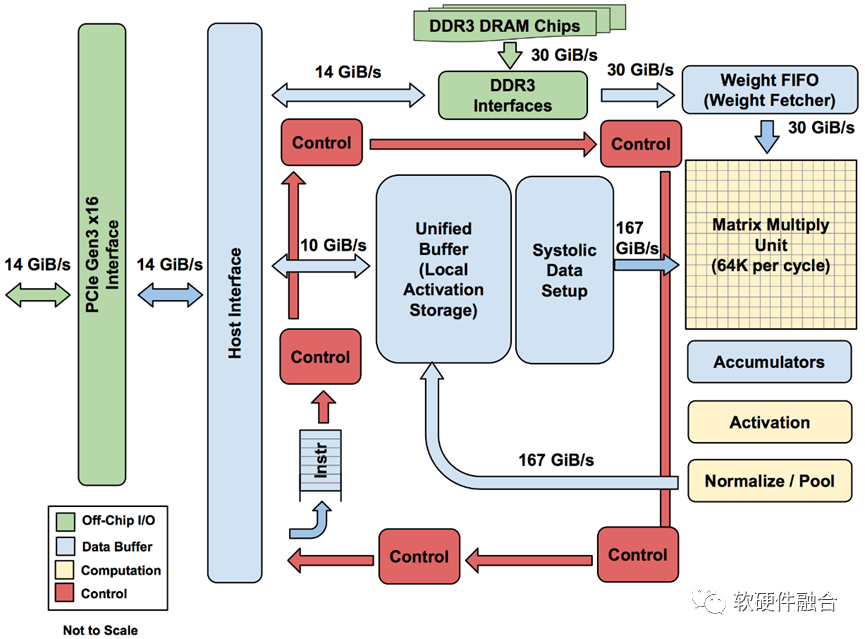
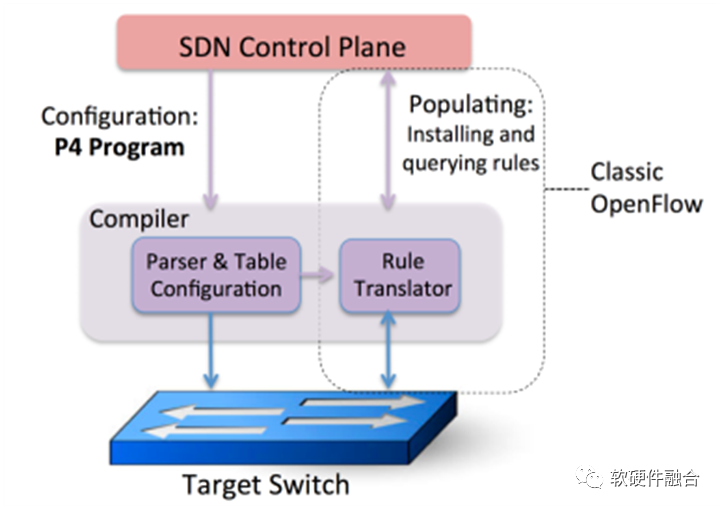
1.5 小結(jié):從CPU到ASIC,架構(gòu)越來越碎片化
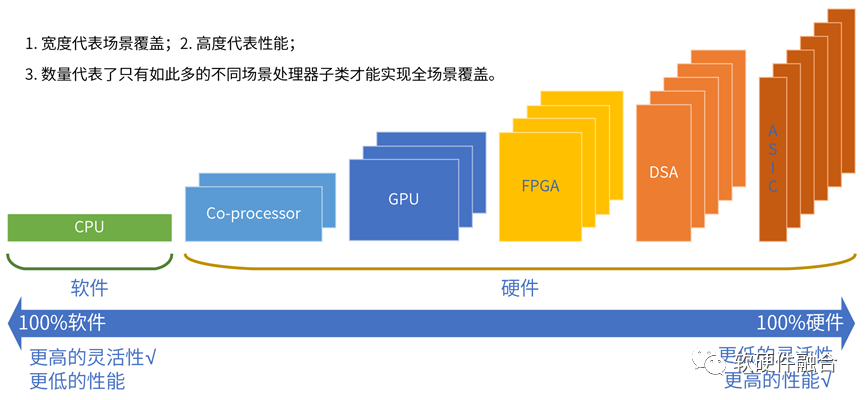
指令是軟件和硬件的媒介,指令的復(fù)雜度(單位計算密度)決定了系統(tǒng)的軟硬件解耦程度。
按照指令的復(fù)雜度,典型的處理器平臺大致分為CPU、協(xié)處理器、GPU、FPGA、DSA、ASIC。
世間萬物由基本粒子組成,復(fù)雜處理由基本計算組成。
指令復(fù)雜度越高,單個處理器引擎覆蓋的場景就會越小,處理器引擎的形態(tài)就會越多。
從CPU到ASIC,處理器引擎越來越碎片化,構(gòu)建生態(tài)越來越困難。
2 計算架構(gòu):從異構(gòu)到超異構(gòu)
2.1 CPU性能瓶頸,引發(fā)連鎖反應(yīng)
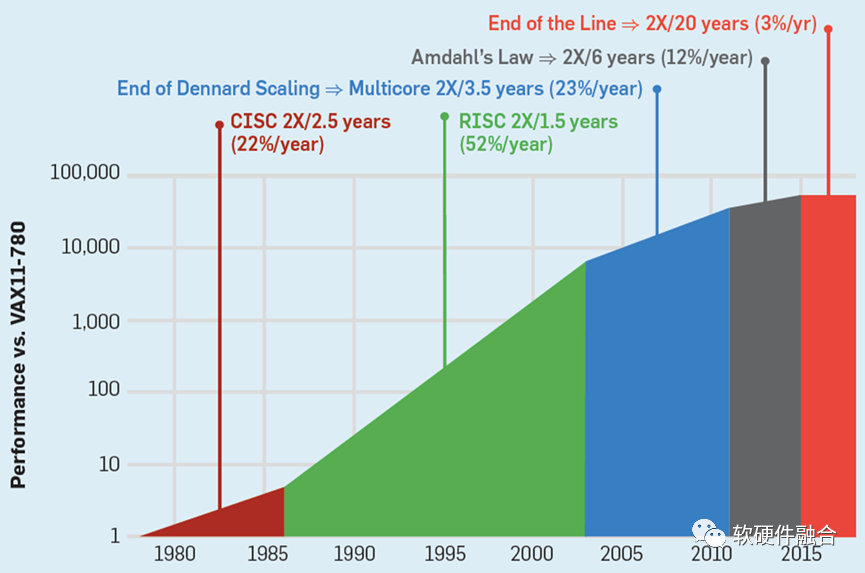
在云計算、邊緣計算以及一些超級終端的復(fù)雜計算場景,對靈活性的要求遠(yuǎn)高于對性能的要求。
CPU通用靈活性好,在符合性能要求的情況下,各類復(fù)雜計算場景,CPU依然是最優(yōu)選擇。
對算力的需求不斷增加,不得不通過各種異構(gòu)加速方式進(jìn)行性能優(yōu)化。
實(shí)踐證明,在復(fù)雜計算場景,提升性能的同時,不能損失通用靈活性(言外之意,目前很多技術(shù)方案損害了靈活性)。
2.2 異構(gòu)計算存在的問題
復(fù)雜計算的挑戰(zhàn):系統(tǒng)越復(fù)雜,需要選擇越靈活的處理器;性能挑戰(zhàn)越大,需要選擇越偏向定制的加速處理器。本質(zhì)矛盾是:單一處理器無法兼顧性能和靈活性;即使我們拼盡全力平衡,也只“治標(biāo)不治本”。
CPU+xPU異構(gòu)計算中的xPU,決定了整個系統(tǒng)的性能/靈活性特征:
GPU靈活性較好,但性能效率不夠極致;
DSA性能好,但靈活性差,難以適應(yīng)復(fù)雜計算場景對靈活性的要求。案例:AI落地困難。
FPGA功耗和成本高,需要一些定制開發(fā),落地案例不多。
ASIC功能完全固定,難以適應(yīng)靈活多變的復(fù)雜計算場景。
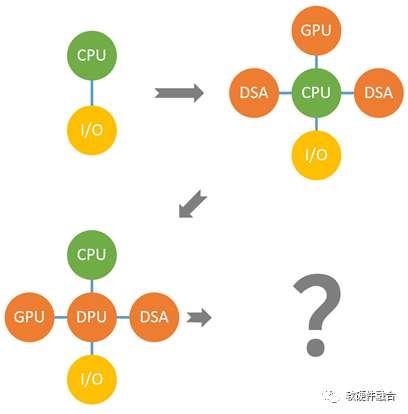
異構(gòu)計算還存在計算孤島的問題:
異構(gòu)計算面向某個領(lǐng)域或場景,領(lǐng)域之間的交互困難。
服務(wù)器物理空間有限,無法多個物理加速卡,需要把這些加速方案整合;
需要強(qiáng)調(diào)的是:整合,不是簡單的拼湊,而是要架構(gòu)重構(gòu)。
2.3 超異構(gòu)存在的前提條件:復(fù)雜系統(tǒng)和超大規(guī)模
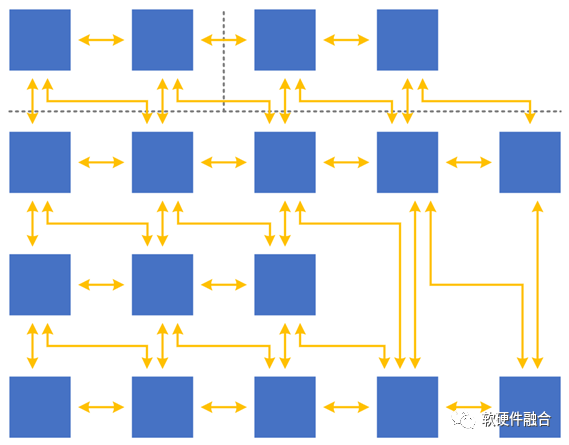
基礎(chǔ)特征:①超大規(guī)模的計算集群;②復(fù)雜宏系統(tǒng),是由分層分塊的組件(系統(tǒng))組成。
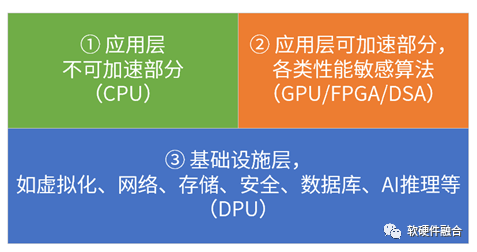
單服務(wù)器的宏系統(tǒng)復(fù)雜度,以及超大規(guī)模的云和邊緣計算,使得“二八定律”在系統(tǒng)中普遍存在,因此,可以把:相對確定的任務(wù)沉淀到基礎(chǔ)設(shè)施層,相對彈性的沉淀到彈性加速部分,其他繼續(xù)放在CPU(CPU兜底)。
2.4 從異構(gòu)并行到超異構(gòu)并行
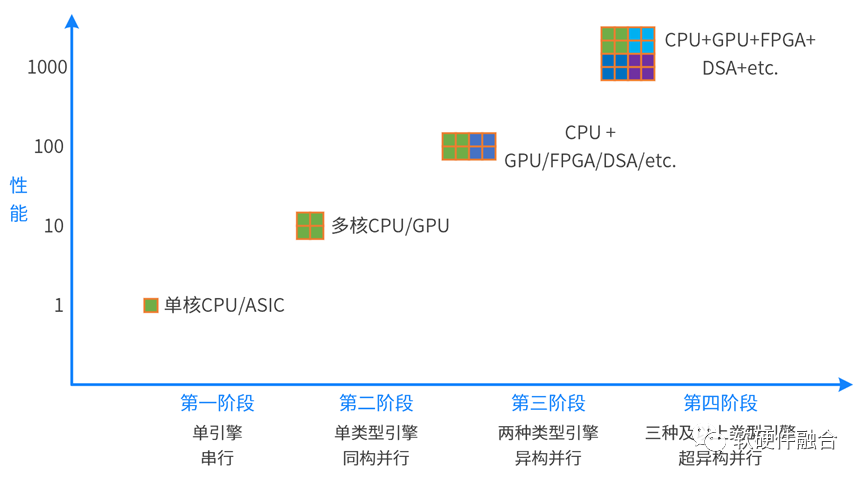
計算從單核的串行走向多核的并行;又進(jìn)一步從同構(gòu)并行走向異構(gòu)并行。未來,計算需要進(jìn)一步從異構(gòu)并行走向超異構(gòu)并行。
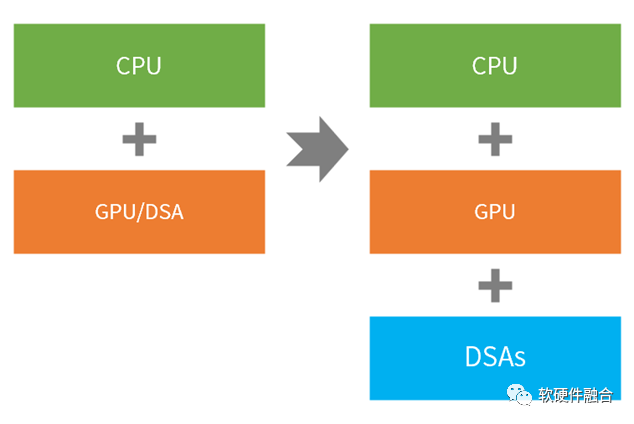
異構(gòu)計算是CPU+xPU的兩個層次的處理引擎類型,而超異構(gòu)計算則是CPU+GPU+DSA的三個層次的處理引擎類型。
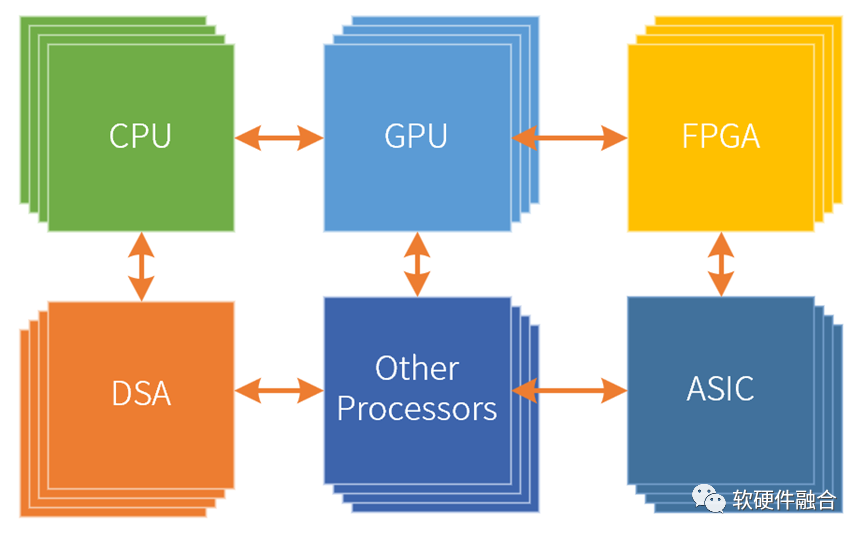
超異構(gòu)計算,不是簡單的集成,而是把更多的異構(gòu)計算整合重構(gòu),各類型處理器間充分的、靈活的數(shù)據(jù)交互,形成統(tǒng)一的超異構(gòu)計算宏系統(tǒng)。
2.5 Intel:超異構(gòu)、XPU和oneAPI
2019年,Intel提出超異構(gòu)計算相關(guān)概念;目前為止,Intel沒有完全符合超異構(gòu)概念的產(chǎn)品。
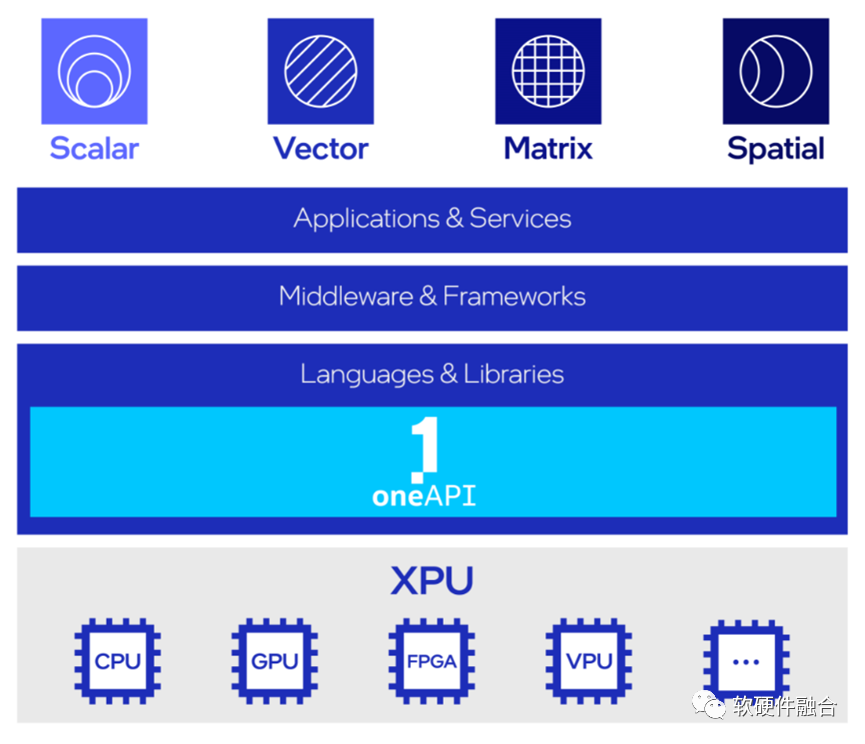
超異構(gòu)計算的基礎(chǔ)引擎是XPU,XPU是多種架構(gòu)的組合,包括CPU、GPU、FPGA 和其他加速器;
oneAPI是開源的跨平臺編程框架,底層是不同的XPU處理器,通過OneAPI提供一致性編程接口,使得應(yīng)用跨平臺復(fù)用。
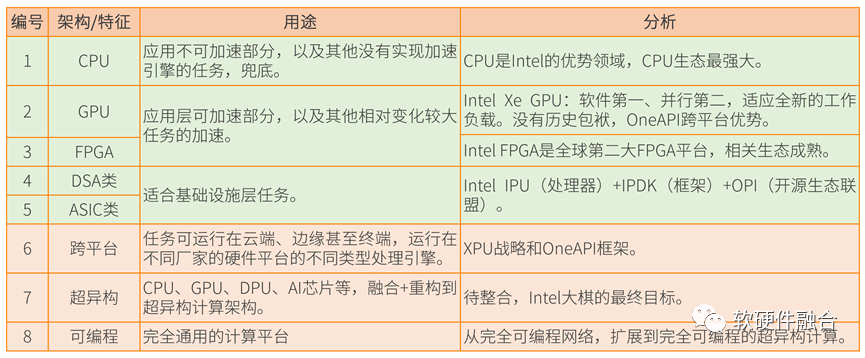
2.6 Intel超異構(gòu)分析
2.7 NVIDIA自動駕駛Thor
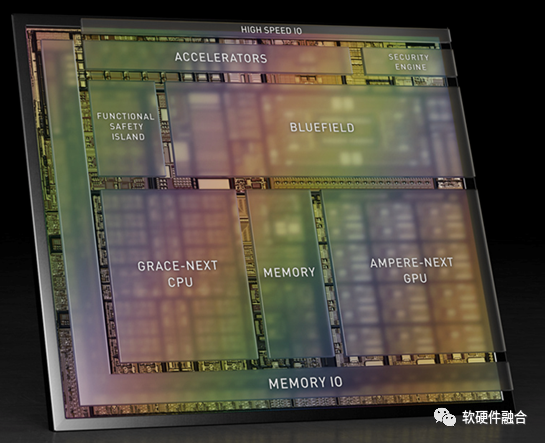
(上圖為Atlan架構(gòu)示意圖,Atlan和Thor架構(gòu)相同,性能上有差異)
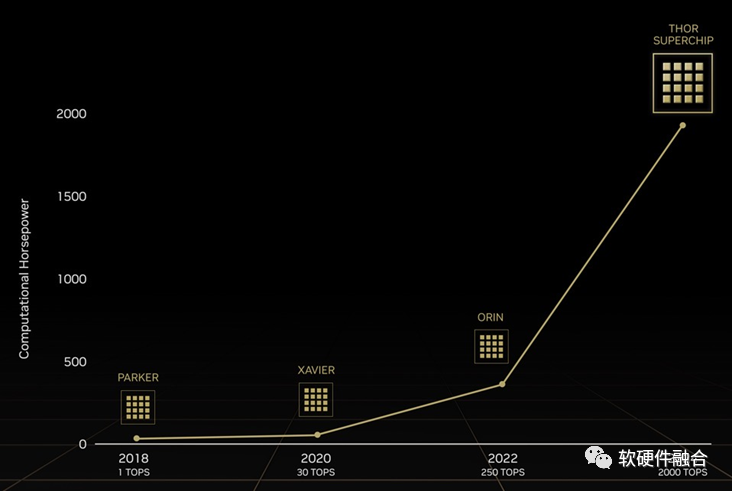
NVIDIA自動駕駛Thor芯片,由數(shù)據(jù)中心架構(gòu)的CPU+GPU+DPU三部分組成,算力高達(dá)2000TFLOPS的超異構(gòu)計算芯片。
Thor是把傳統(tǒng)多個DCU(SOC)的功能融合成單個超異構(gòu)處理芯片。
2.8 為什么是現(xiàn)在?
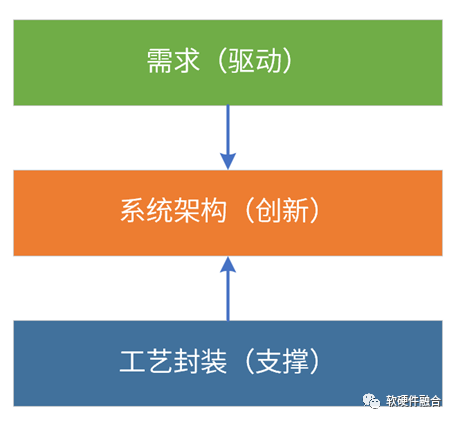
首先,是需求驅(qū)動。軟件新應(yīng)用層出不窮,兩年一個新熱點(diǎn);并且,已有的熱點(diǎn)技術(shù)仍在快速演進(jìn)。元宇宙是繼互聯(lián)網(wǎng)和移動互聯(lián)網(wǎng)之后的下一個互聯(lián)網(wǎng)形態(tài),要想實(shí)現(xiàn)元宇宙級別的體驗,需將算力提升1000倍。
其次,工藝和封裝支撐。工藝封裝持續(xù)進(jìn)步,工藝10nm以下,芯片從2D->3D->4D。Chiplet使得在單芯片層次,可以構(gòu)建規(guī)模數(shù)量級提升的超大系統(tǒng)。系統(tǒng)規(guī)模越大,超異構(gòu)的優(yōu)勢越明顯。
最后,系統(tǒng)架構(gòu)需要持續(xù)創(chuàng)新。通過架構(gòu)創(chuàng)新,在單芯片層次,實(shí)現(xiàn)多個數(shù)量級的性能提升。挑戰(zhàn):異構(gòu)編程很難,超異構(gòu)編程更是難上加難;如何更好地駕馭超異構(gòu),是成敗的關(guān)鍵。
2.9 小結(jié):超異構(gòu)設(shè)計和開發(fā)難度呈指數(shù)上升
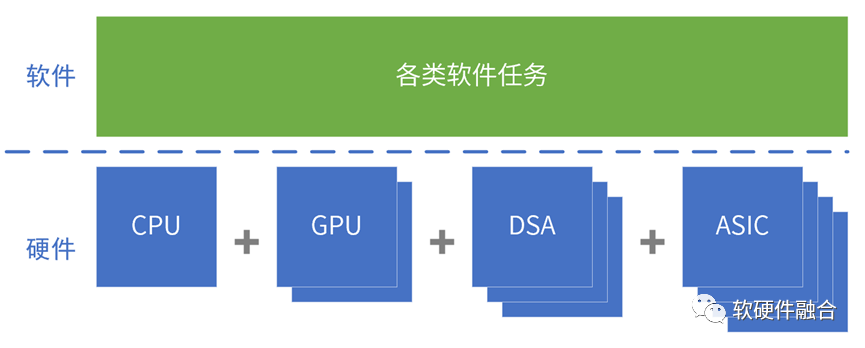
軟件需要跨平臺復(fù)用,跨①不同架構(gòu)、②不同處理器類型、③不同廠家平臺、④不同位置、⑤不同設(shè)備類型。
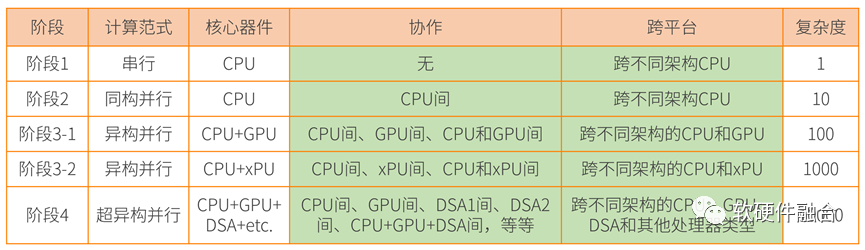
如此復(fù)雜的超異構(gòu)該如何駕馭?
3 開放架構(gòu)和生態(tài)的現(xiàn)狀
3.1 開放架構(gòu)和生態(tài)綜述
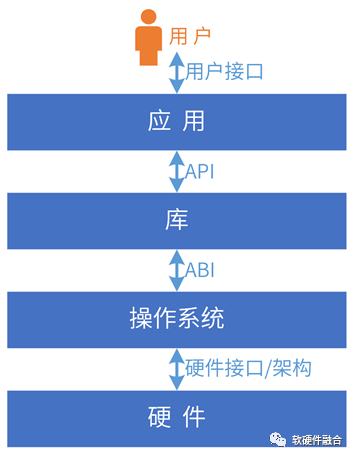
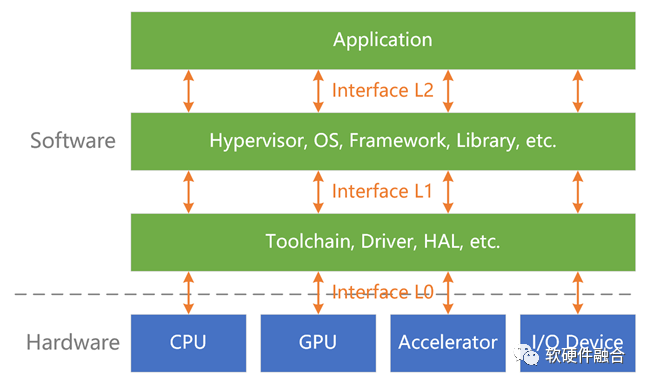
系統(tǒng)必然是在某個層次開放:
用戶接口:應(yīng)用程序必須提供UI供用戶使用。
開發(fā)庫:指提供函數(shù)的代碼,開發(fā)者可以從自己的代碼中調(diào)用這些函數(shù)來處理常見任務(wù),如CUDA庫等。
操作系統(tǒng):提供系統(tǒng)調(diào)用接口。
硬件需要提供硬件接口/架構(gòu),給系統(tǒng)軟件調(diào)用,如I/O接口、CPU架構(gòu)、GPU架構(gòu)等。
互操作性:不同的系統(tǒng)、模塊一起協(xié)同工作并共享信息的能力。系統(tǒng)堆棧的相鄰兩層,遵循配對的接口協(xié)議進(jìn)行交互;如果接口不匹配,就需要有接口轉(zhuǎn)換層。
開放接口/架構(gòu)及生態(tài):基于互操作性,形成標(biāo)準(zhǔn)的開放的接口/架構(gòu);大家遵循此接口/架構(gòu)開發(fā)產(chǎn)品和服務(wù),從而形成開放生態(tài)。
3.2 RISC-V:開放CPU架構(gòu)
x86架構(gòu)主要應(yīng)用在PC和數(shù)據(jù)中心領(lǐng)域,ARM架構(gòu)主要應(yīng)用在移動領(lǐng)域,目前也在向PC和服務(wù)器領(lǐng)域拓展。
為了給芯片提供低成本CPU,加州大學(xué)伯克利分校開發(fā)了RISC-V, RISC-V已成為行業(yè)標(biāo)準(zhǔn)的開放ISA。
理論上可通過靜態(tài)編譯、動態(tài)翻譯等方式,實(shí)現(xiàn)跨不同CPU架構(gòu)運(yùn)行。但都存在損耗及穩(wěn)定性等問題,需要很多移植方面的工作。
一個平臺上的程序難以在其他平臺上運(yùn)行(靜態(tài)),運(yùn)行時跨平臺(動態(tài))更是難上加難。
理想情況,如果形成RISC-V的開放生態(tài),沒有了跨平臺的損耗和風(fēng)險,大家可以把精力專注于CPU微架構(gòu)及上層軟件的創(chuàng)新。
RISC-V的優(yōu)勢:
免費(fèi)。指令集架構(gòu)免費(fèi)獲取,不需要授權(quán),沒有商業(yè)上掣肘。
開放性。任何廠家就可以設(shè)計自己的RISC-v CPU,大家共建一套開放的生態(tài),共榮共生。
簡潔高效。沒有歷史包袱,ISA更高效。
標(biāo)準(zhǔn)化。最關(guān)鍵的價值。如果RISC-v變成主流架構(gòu),就沒有了跨平臺等成本或代價。
3.3 GPU架構(gòu)生態(tài)
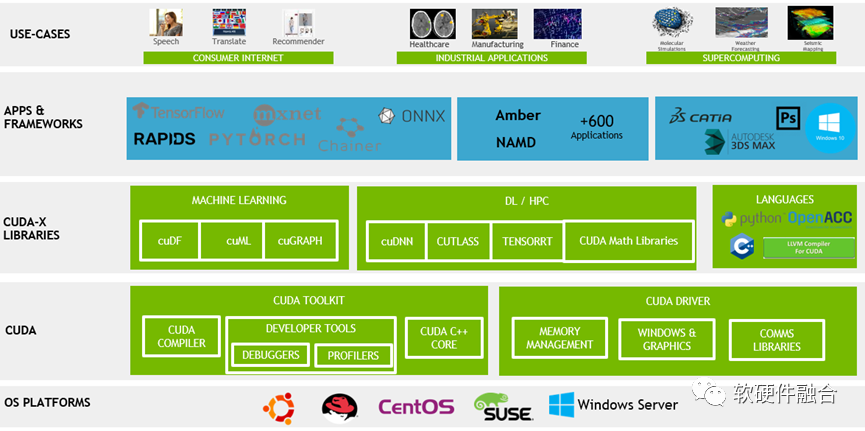
目前,GPU還沒有像CPU RISC-V一樣,有標(biāo)準(zhǔn)化的、開源的ISA架構(gòu)。
CUDA是NVIDIA GPU的開發(fā)框架,向前兼容。
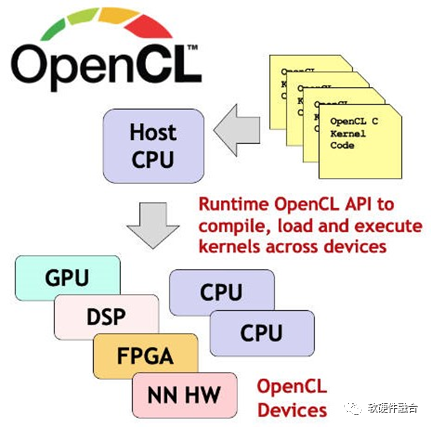
OpenCL是完全開放的異構(gòu)開發(fā)框架,可以跨CPU、GPU、FPGA等處理引擎。
3.4 DSA,混戰(zhàn)
①DSA領(lǐng)域多種多樣,即使同一領(lǐng)域,②不同廠家的DSA架構(gòu)仍不相同,甚至③同一廠家不同代產(chǎn)品的架構(gòu)也不相同。
最典型的AI-DSA場景,目前就處在各種DSA架構(gòu)混戰(zhàn)的階段。
要想構(gòu)建DSA的生態(tài):
軟件定義,不需要開發(fā)應(yīng)用,兼容已有軟件生態(tài);
少量編程(許多DSA編程,類似靜態(tài)配置腳本),門檻較低的標(biāo)準(zhǔn)的領(lǐng)域編程語言;
開放架構(gòu),防止架構(gòu)過多導(dǎo)致的市場碎片化。
DSA架構(gòu)一般來說分為靜態(tài)和動態(tài)兩部分:
靜態(tài)部分。類配置腳本,通過編譯器映射到具體的DSA引擎,編程實(shí)現(xiàn)DSA引擎的具體功能。
動態(tài)部分。DSA的動態(tài)部分通常不是編程實(shí)現(xiàn),而是跟已有軟件進(jìn)行適配;相當(dāng)于是把軟件的數(shù)據(jù)平面/計算平面卸載到硬件,控制平面依然在軟件;符合軟件定義的思路。
3.5 DSA/ASIC集成平臺:NVIDIA DPU
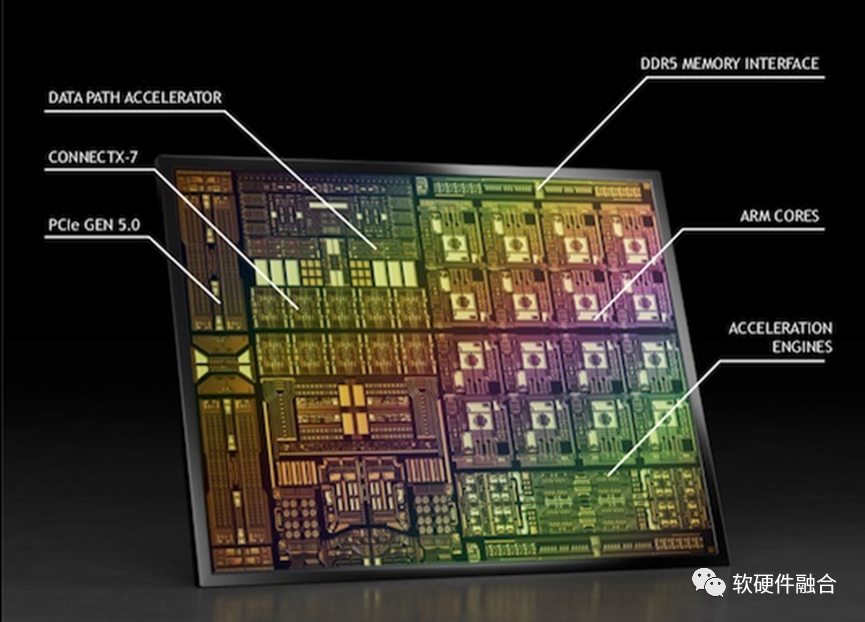
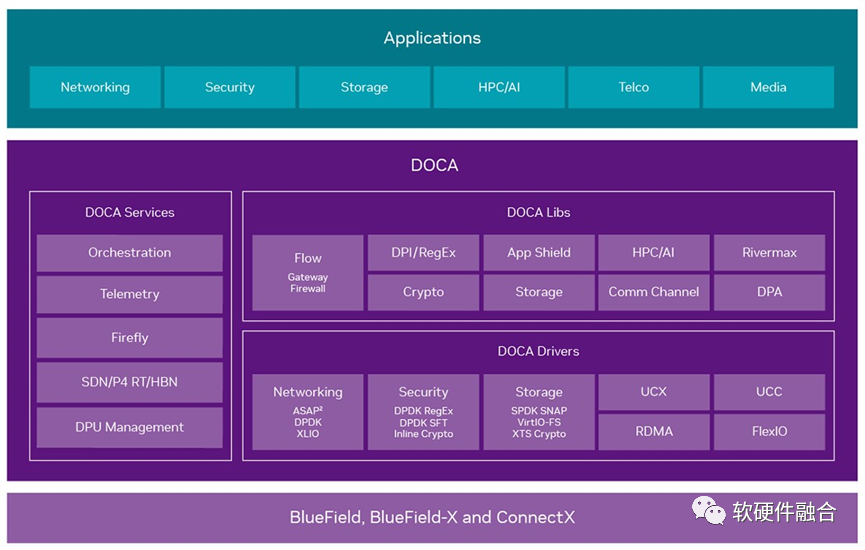
DPU集成虛擬化、網(wǎng)絡(luò)、存儲、安全等DSA/ASIC引擎,DOCA框架:庫文件、運(yùn)行時和服務(wù)、驅(qū)動程序組成。
DPU/DOCA是非開源/開放的封閉架構(gòu)、平臺和生態(tài)。
3.6 DSA/ASIC集成平臺:Intel IPU
和NVIDIA DPU類似,Intel IPU集成虛擬化、網(wǎng)絡(luò)、存儲、安全等DSA/ASIC引擎。
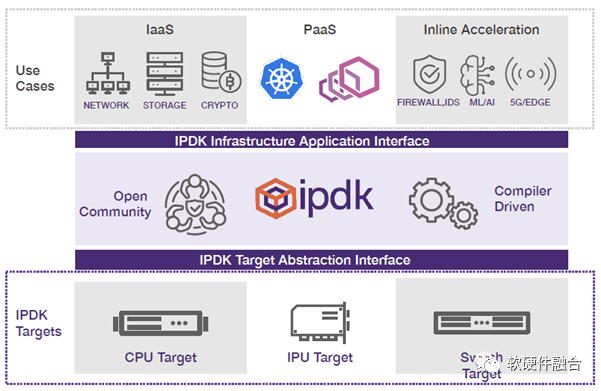
IPDK是開源的基礎(chǔ)設(shè)施編程框架,可運(yùn)行在CPU、IPU、DPU或交換機(jī)。

Intel和Linux基金會的OPI項目:為基于 DPU/IPU 類技術(shù)的下一代架構(gòu)和框架,培育一個標(biāo)準(zhǔn)的開放生態(tài)系統(tǒng)。
Intel IPU/IPDK/OPI是開源/開放的架構(gòu)、平臺和生態(tài)。
3.7 硬件使能:Hardware Enablement
隨著數(shù)據(jù)中心演變成虛擬機(jī)、裸金屬機(jī)和容器的組合,OpenStack社區(qū)擴(kuò)大成新的OpenInfra社區(qū)。
旨在推進(jìn)開放基礎(chǔ)設(shè)施領(lǐng)域技術(shù)發(fā)展,包括:公共云、私有云、混合云,以及AI/ML、CI/CD、容器、邊緣計算等。
Ubuntu硬件使能版本:為了更好地支持最新的硬件,會經(jīng)常更新內(nèi)核版本,不太適合企業(yè)用戶。
OpenInfra硬件使能:軟件組件需要在云和邊緣環(huán)境使能硬件,包括GPU、DPU、FPGA等。
在硬件加速/軟件卸載的語境下,硬件使能可以理解成:
軟件要支持硬件加速,“硬件加速原生”;
如果存在硬件加速的資源,則采用硬件加速模式;
如果不存在硬件加速的資源,則繼續(xù)采用傳統(tǒng)的軟件運(yùn)行模式。
4 硬件定義軟件,還是軟件定義硬件?
4.1 系統(tǒng)的控制平面和計算平面
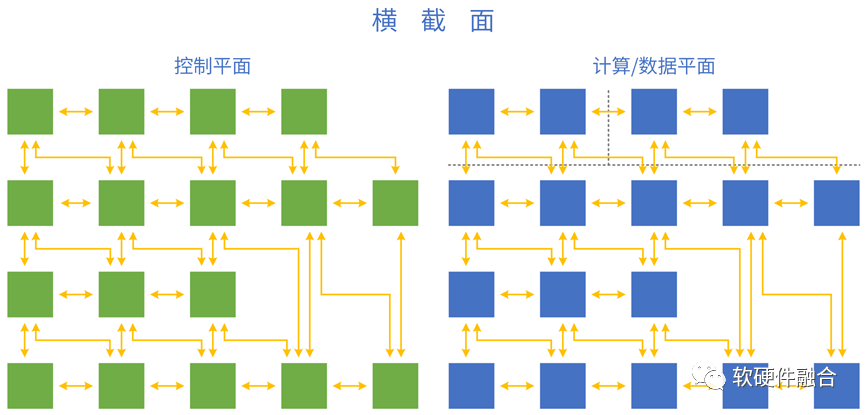
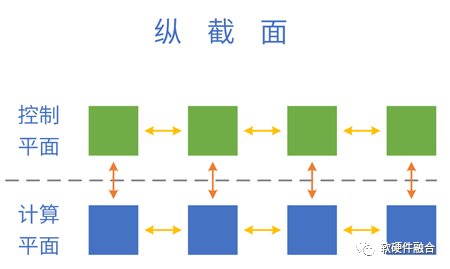
把分層分塊的系統(tǒng),映射到軟硬件具體實(shí)現(xiàn):控制平面運(yùn)行在CPU,計算/數(shù)據(jù)平面運(yùn)行在CPU、GPU、DSA等處理引擎。
4.2 泛義的軟硬件接口
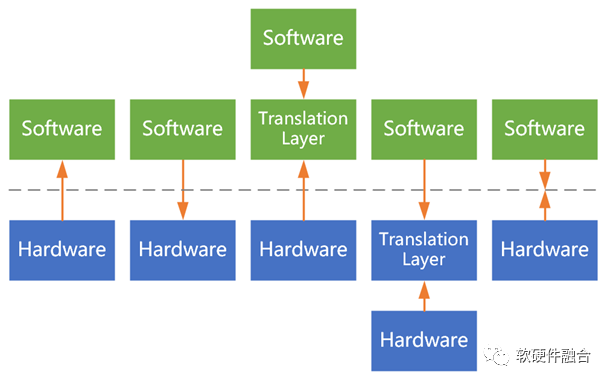
泛義的接口:
塊和塊之間、層和層之間的接口;
軟件和軟件之間、硬件和硬件之間、軟硬件之間的接口。
軟件和硬件之間的接口:
硬件定義接口,軟件適配;
軟件定義接口,硬件適配;
硬件/軟件定義接口,軟件接口適配層;
硬件/軟件定義接口,接口適配層卸載;
軟件硬件設(shè)計遵循標(biāo)準(zhǔn)接口(要求:標(biāo)準(zhǔn)、高效、開源、迭代)。
4.3 什么是硬件/軟件定義?
系統(tǒng)是由軟件和硬件組成,也必然是軟硬件協(xié)同的。從軟硬件的相互關(guān)系和影響,闡述軟件定義和硬件定義。
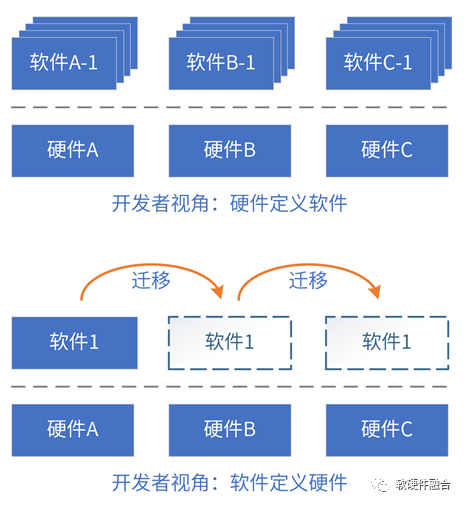
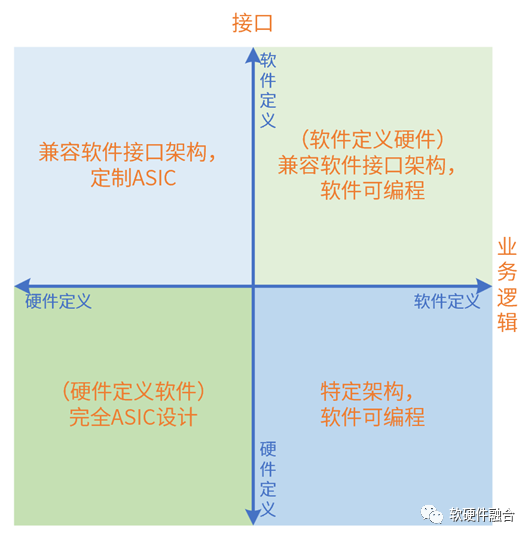
評價標(biāo)準(zhǔn):系統(tǒng)的業(yè)務(wù)邏輯由誰決定;軟件和硬件的交互接口(架構(gòu))由誰決定。
“硬件定義軟件”定義為:系統(tǒng)的業(yè)務(wù)邏輯以硬件實(shí)現(xiàn)為主,軟件實(shí)現(xiàn)為輔;軟件依賴于硬件提供的接口構(gòu)建。
“軟件定義硬件”定義為:當(dāng)一個系統(tǒng)的業(yè)務(wù)邏輯以軟件實(shí)現(xiàn)為主,硬件實(shí)現(xiàn)為輔;或者硬件引擎是軟件可編程的,硬件引擎按照軟件編程的邏輯執(zhí)行操作;硬件依賴于軟件提供的接口構(gòu)建。
4.4 硬件/軟件定義的依據(jù):系統(tǒng)復(fù)雜度
硬件定義軟件,還是軟件定義硬件,跟系統(tǒng)復(fù)雜度是休戚相關(guān)的。
系統(tǒng)復(fù)雜度較小,迭代較慢。可以快速設(shè)計優(yōu)化的系統(tǒng)軟硬件劃分,先硬件開發(fā),然后開始系統(tǒng)層和應(yīng)用層的軟件開發(fā)。
量變引起質(zhì)變,隨著系統(tǒng)復(fù)雜度上升,系統(tǒng)迭代快,直接實(shí)現(xiàn)一個完全優(yōu)化的設(shè)計難度很大。系統(tǒng)實(shí)現(xiàn)變成了演進(jìn)式:
前期系統(tǒng)不夠穩(wěn)定,算法和業(yè)務(wù)邏輯在快速迭代,需要快速實(shí)現(xiàn)想法。這樣,基于CPU的軟件實(shí)現(xiàn)就比較合適;
隨著系統(tǒng)發(fā)展,算法和業(yè)務(wù)邏輯逐漸穩(wěn)定,后續(xù)逐步優(yōu)化到GPU、DSA等硬件加速來持續(xù)優(yōu)化性能。
硬件定義還是軟件定義?本質(zhì)上是系統(tǒng)定義。系統(tǒng)的復(fù)雜度過高,實(shí)現(xiàn)難以一次到位,于是系統(tǒng)的實(shí)現(xiàn),變成了持續(xù)優(yōu)化和迭代的過程。
4.5 硬件/軟件定義的本質(zhì):歸納和演繹
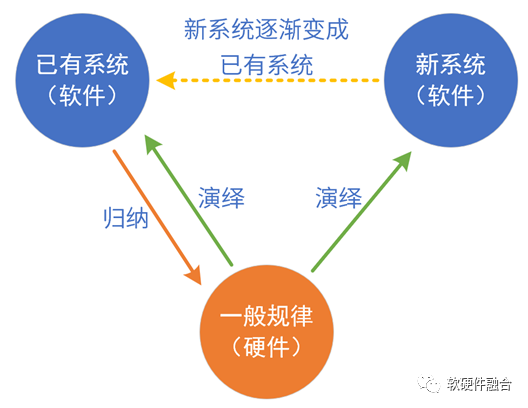
硬件/軟件定義的本質(zhì),是通過歸納和演繹實(shí)現(xiàn)系統(tǒng)及系統(tǒng)的發(fā)展。從長期和發(fā)展的視角看,系統(tǒng)是由軟硬件共同定義的。我們以典型的處理引擎實(shí)現(xiàn)進(jìn)行分析:
CPU:把所有領(lǐng)域歸納出共性(最基本的指令),這個共性“放之四海皆準(zhǔn)”。也即是說,相對其他平臺,“CPU不需要再歸納”,只需要持續(xù)演繹新的領(lǐng)域和場景。軟件定義:CPU已經(jīng)是成熟的軟件平臺,可以基于CPU快速實(shí)現(xiàn)系統(tǒng)原型,當(dāng)系統(tǒng)的算法和業(yè)務(wù)邏輯穩(wěn)定后,可通過硬件加速進(jìn)行性能優(yōu)化。
GPU:把很多個領(lǐng)域歸納出共性,然后硬件實(shí)現(xiàn)共性,軟件實(shí)現(xiàn)個性。GPU平臺實(shí)現(xiàn)后,可以持續(xù)演繹新的領(lǐng)域新的場景。GPU是足夠通用、成熟的并行計算開發(fā)平臺。
DSA:把某個領(lǐng)域多個場景的業(yè)務(wù)邏輯進(jìn)行歸納:硬件實(shí)現(xiàn)共性部分,軟件實(shí)現(xiàn)個性部分。DSA平臺實(shí)現(xiàn)后,可以在此領(lǐng)域演繹新的場景。
ASIC:具體場景的算法和業(yè)務(wù)邏輯直接變成硬件,軟件只是基本的控制作用。直接映射,談不上歸納和演繹。
5 總結(jié):軟硬件共同定義,超異構(gòu)開放生態(tài)
5.1 軟件原生支持硬件加速
軟件原生支持硬件加速:
軟件架構(gòu)調(diào)整,控制面和計算/數(shù)據(jù)面分開;
控制面和計算/數(shù)據(jù)面接口標(biāo)準(zhǔn)化;
硬件加速資源的發(fā)現(xiàn)能力,自適應(yīng)選擇軟件計算/數(shù)據(jù)面或硬件計算/數(shù)據(jù)面。
數(shù)據(jù)的輸入,可以來源于軟件,也可以來源于硬件;
數(shù)據(jù)的輸出,可以去向軟件,也可以去向硬件。
5.2 完全可編程
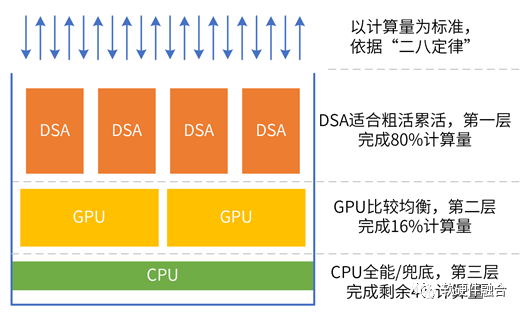
完全可編程,不是CPU可編程,而是在極致優(yōu)化性能基礎(chǔ)之上的可編程。完全可編程是分層的可編程體系:
基礎(chǔ)設(shè)施層可編程。基礎(chǔ)設(shè)施層Workload不經(jīng)常變化,可以采用DSA架構(gòu)。
彈性應(yīng)用可編程。支持主流GPU編程方式,可以把常見應(yīng)用通過DSA,實(shí)現(xiàn)更高效率的加速。
應(yīng)用可編程。應(yīng)用不確定性最大,仍然運(yùn)行在CPU。同時,CPU負(fù)責(zé)兜底,所有其他不適合加速或沒有加速引擎的任務(wù)都在CPU運(yùn)行。
實(shí)現(xiàn)完全可編程的同時,性能數(shù)量級的提升:
從整個系統(tǒng)看,絕大部分是DSA加速的,因此系統(tǒng)的性能效率接近于DSA;
Chiplet+超異構(gòu),系統(tǒng)規(guī)模數(shù)量級提升,系統(tǒng)性能數(shù)量級提升;
從用戶角度,應(yīng)用運(yùn)行在CPU,用戶體驗到的是100%的CPU可編程。
5.3 開放接口和架構(gòu)
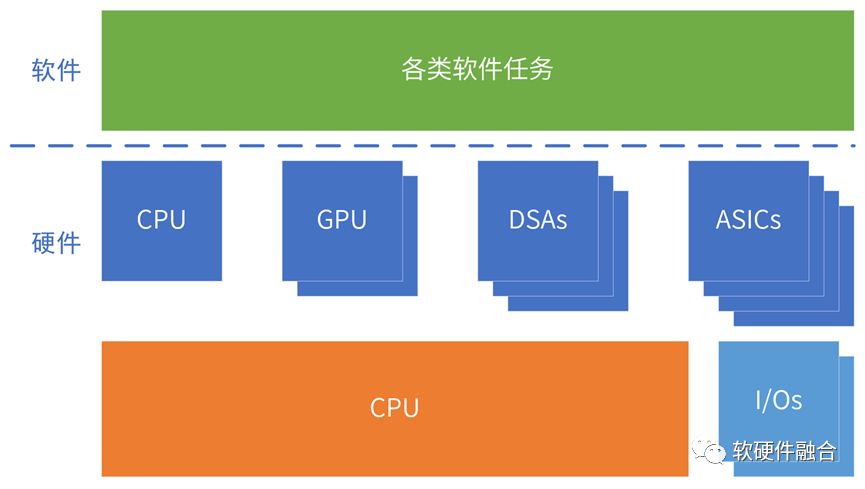
ASIC/DSA覆蓋的領(lǐng)域/場景較小,芯片對場景的覆蓋(相比CPU、GPU)越來越碎片化。
構(gòu)建生態(tài)越來越困難。需要從硬件定義,逐步轉(zhuǎn)向軟件定義。
超異構(gòu)計算,包括CPU、GPU,也包括多種DSA、ASIC類型的處理器。
異構(gòu)的引擎架構(gòu)越來越多,必須構(gòu)建高效的、標(biāo)準(zhǔn)的、開放的接口和架構(gòu)體系,才能構(gòu)建一致性的宏架構(gòu)(多種架構(gòu)組合)平臺,才能避免場景覆蓋的碎片化。
5.4 計算需要跨不同類型處理器
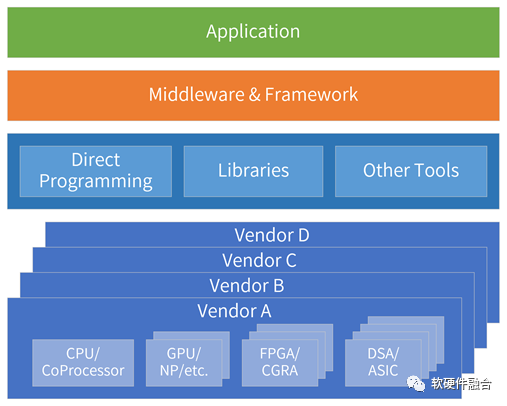
超異構(gòu)包含CPU、GPU、FPGA、DSA等不同類型的處理器,計算任務(wù)需要跨不同類型的處理器運(yùn)行。
oneAPI是Intel開源的跨平臺編程框架,通過oneAPI提供一致性編程接口,使得應(yīng)用可以跨不同類型處理器運(yùn)行。
更廣泛的,不僅僅是跨不同類型的處理器,還要能跨不同廠家的芯片平臺。
5.5 超異構(gòu)開放生態(tài)
要想提升算力利用率,就需要把一個個孤島的計算資源,整合成統(tǒng)一的資源池。
需要通過跨平臺融合,實(shí)現(xiàn)計算資源池化:
維度一:跨同類型處理器架構(gòu)。如軟件可以跨x86、ARM和RISC-v CPU運(yùn)行。
維度二:跨不同類型處理器架構(gòu)。軟件需要跨CPU、GPU、FPGA和DSA等處理器運(yùn)行。
維度三:跨不同的芯片平臺。如軟件可以在Intel、NVIDIA等不同公司的芯片上運(yùn)行。
維度四:跨云網(wǎng)邊端不同的位置。計算可以根據(jù)各種因素的變化,自適應(yīng)的運(yùn)行在云網(wǎng)邊端最合適的位置。
維度五:跨不同的云網(wǎng)邊服務(wù)供應(yīng)商、不同的終端用戶、不同的終端設(shè)備類型。
超異構(gòu)時代,必須要形成開放的生態(tài),才能讓計算資源形成一個整體,才能滿足元宇宙等應(yīng)用場景對算力數(shù)量級提升的要求。
5.6 軟硬件共同定義:超異構(gòu)開放生態(tài)
首先,是超異構(gòu)計算架構(gòu)。CPU+GPU+FPGA+DSA等多種架構(gòu)處理引擎組成的超異構(gòu)計算;實(shí)現(xiàn)既要又要:接近CPU的靈活性,接近ASIC的性能效率,以及多個數(shù)量級提升的性能。
其次,要平臺化&可編程。兩個一切:軟件定義一切,硬件加速一切;兩個完全:完全可軟件編程的硬件加速平臺,完全由軟件編程決定業(yè)務(wù)邏輯;一個通用:足夠的通用性,滿足多場景、多用戶的需求,滿足業(yè)務(wù)的長期演進(jìn)。
最后,要標(biāo)準(zhǔn)&開放。架構(gòu)/接口標(biāo)準(zhǔn)、開放,持續(xù)演進(jìn);擁抱開源開放的生態(tài);支持云原生、云網(wǎng)邊端融合;用戶無(硬件、框架等)平臺依賴。
編輯:黃飛
?








 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論