 電子發燒友App
電子發燒友App


RDNA 3 代表了 AMD RDNA 架構的第三次迭代,它在其消費類圖形產品線中取代了 GCN。在較高層面上,與 RDNA 2 相比,RDNA 3 的目標是大規模擴展。緩存設置在各個層面進行了調整,以提供更高的帶寬。為了擴展計算吞吐量而不僅僅是添加更多 WGP,AMD 為通用指令的子集實現了雙重發布功能。
在本文中,我們將對 7900XTX 進行一些微基準測試,看看與 AMD 的 RDNA 2 架構相比的差異。我們還將結合Nemes 的 GPU 微基準測試套件的結果。雖然我對 CPU 微基準測試有相當多的了解,但我無法將幾乎那么多的時間投入到我的 OpenCL bsaed 測試中。Nemes 在她基于 Vulkan 的 GPU 測試套件上取得了很好的進展,她的測試在某些領域提供了更好的覆蓋。
內存延遲
測試緩存和內存延遲讓我們可以很好地了解 RDNA 3 的緩存和內存設置。延遲測試在后 GCN AMD 圖形架構上也很復雜,因為全局內存層次結構可以通過標量或矢量數據路徑訪問,它們具有不同的一級緩存。如果編譯器確定加載的值在整個波前(wavefront)是恒定的,它可以告訴 GPU 使用標量數據路徑。因為標量路徑用于延遲敏感的東西,比如計算波前負載的內存地址,延遲是相當不錯的(對于 GPU)。在訪問全局內存時,AMD 大量使用矢量和標量端。確切的比例會因工作量而異,但通常兩者都很重要。
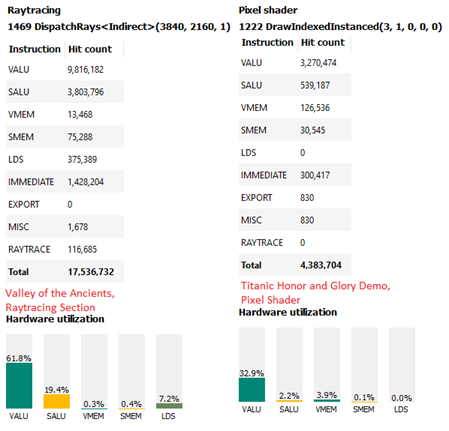
Radeon GPU Profiler 的統計數據顯示了在 RDNA 2 上運行的幾個工作負載上執行的指令混合。SMEM(標量路徑)和 VMEM(矢量路徑)都用于命中全局內存。
讓我們從標量方面開始。與 RDNA 2 一樣,RDNA 3 具有 16 KB、4 路組關聯標量緩存。此緩存的加載到使用延遲非常好,RDNA 3 為 15.4 ns,RDNA 2 為 17.4 ns。RDNA 3 的延遲優勢至少部分歸功于更高的時鐘速度。Nvidia 的 Ada Lovelace 在到達 SM 的 L1 時的延遲稍好一些,考慮到 Nvidia 緩存的大小,這令人印象深刻。我們在這里看到 64 KB 的 L1 緩存容量,但 Ada Lovelace 實際上有一個 128 KB 的 SRAM 塊,可以在 L1 和共享內存 (LDS) 使用之間靈活分區。
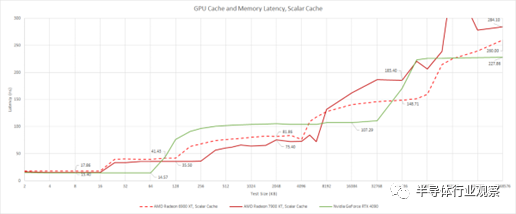
AMD 還增加了 L1 和 L2 中級緩存的容量,以便更好地處理更大 GPU 的帶寬需求。RDNA 2 有一個 128 KB、16 路集關聯 L1,在著色器陣列中共享。RDNA 3 將容量翻倍至 256 KB,同時保持 16 向結合性。L2 緩存容量增加到 6 MB,而 RDNA 2 上為 4 MB,同時還保持 16 路關聯性。盡管容量有所增加,但 RDNA 3 在 L1 和 L2 上都提供了可測量的延遲改進。
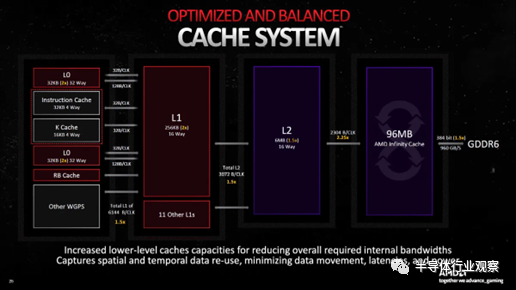
AMD 的幻燈片描述了 RDNA 3 的緩存系統
然而,RDNA 3 的 Infinity Cache 有所退步。容量從 128 MB 減少到 96 MB,同時延遲增加。這并不奇怪,因為 RDNA 3 的 Infinity Cache 是在單獨的內存控制器芯片上實現的。但這也不應該是一個大問題。RDNA 3 可能能夠通過其片上 L2 為更多內存訪問提供服務,而不必經常訪問 Infinity Cache。
為了減少內存帶寬需求,Nvidia 選擇大規模擴展 L2 而不是添加另一級緩存。與 AMD 最近的 GPU 相比,這稍微提高了 L2 延遲,但確實提供了比 Ada Lovelace 更優越的延遲特性,以應對數十兆字節范圍內的內存占用。RTX 4090 的 L2 容量為 72 MB,比芯片上實際存在的 96 MB SRAM 有所縮減。
與 RDNA 2 相比,RDNA 3 上的 VRAM 延遲略有上升。Nvidia 在該領域具有優勢,部分原因是 AMD 在前往 DRAM 的途中檢查額外級別的緩存時會產生額外的延遲。
矢量延遲
當然,矢量路徑的延遲也很重要,因此我修改了測試以防止編譯器確定加載的值在整個波前保持不變。從矢量方面來看,AMD 發現延遲增加了,但矢量訪問對延遲的敏感度應該較低。向量緩存的設計也發揮了作用——與 4 路標量緩存相比,它在 RDNA 2 和 RDNA 3 上都是 32 路組關聯。在一次查找中檢查 32 個標簽可能會比檢查四個標簽產生更高的延遲。
盡管如此,與 RDNA 2 相比,RDNA 3 設法減少了 L0 向量緩存延遲,同時將容量翻了一番,達到每個 CU 32 KB。
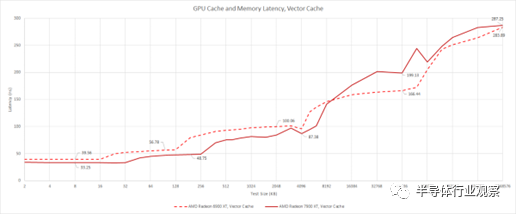
在緩存層次結構的下方,延遲特性主要反映標量端的特性,盡管絕對延遲當然更高。當我們從矢量端進行測試時,RDNA 2 的 VRAM 延遲優勢也會降低。這兩種架構在 1 GB 的測試大小下結束了幾納秒,這基本上沒有。
內存帶寬
Radeon 7900 XTX 比 6900 XT 擁有更多的 WGP。同時,每個 WGP 都有更多的計算吞吐量,因此必須加強內存子系統來滿足它們的需求。因此,RDNA 3 在內存子系統的每個級別都看到了巨大的帶寬增加。L1 和 L2 緩存的增益尤其顯著,與 RDNA 2 相比,帶寬大約翻了一番,盡管它們的容量也有所增加。
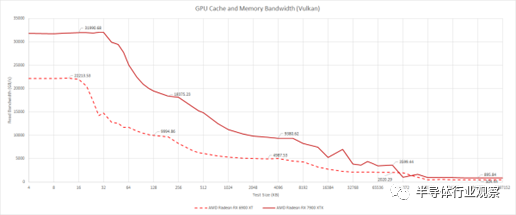
使用 Nemes 的帶寬測試,因為它比我的更干凈地溢出緩存級別
Infinity Cache 帶寬也有大幅增加。使用純讀取訪問模式,我們無法獲得理論上可能實現的 2.7 倍帶寬增長。盡管如此,1.8 倍的帶寬提升并不是開玩笑的。考慮到 Infinity Cache 在不同的小芯片上物理實現,帶寬優勢令人印象深刻,而 RDNA 2 將 Infinity Cache 保留在芯片上。
AMD 還為 7900XTX 配備了更大的 GDDR6 設置,使其帶寬比 6900XT 高得多。事實上,它的 VRAM 帶寬更接近 GA102 的帶寬。這可能使 AMD 能夠保持高性能,同時減少末級緩存的數量,從而允許使用更小的內存控制器芯片。
占用率較低時的帶寬
現代 GPU 旨在利用大量顯式并行性。但是一些工作負載沒有足夠的并行性來填充所有可用的計算單元。頂點著色器,我在看著你。Nemes 的測試套件目前沒有為較低的工作組數量提供結果,所以我在這里使用 OpenCL 結果。
讓我們從單個工作組的帶寬開始。運行單個工作組將我們限制在 AMD 上的單個 WGP,或 Nvidia 架構上的 SM。這是我們可以在 CPU 上獲得的最接近單核帶寬的值。與 CPU 上的單核帶寬一樣,此類測試并不特別代表任何現實世界的工作負載。但它確實讓我們從單個計算單元的角度了解了內存層次結構。
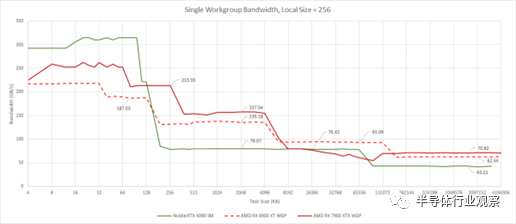
同樣,我們可以看到 RDNA 3 更大的片上緩存。從單個 WGP 的角度來看,所有這三個緩存級別都提供了更高的帶寬。Nvidia 有一個非常大和快速的一級緩存,但在那之后,只要它可以服務于 L1 或 L2 的訪問,AMD 就有優勢。
從 Infinity Cache 來看,RDNA 3 的日子更難過,這可能是因為單個 WGP 沒有獲得足夠的內存級并行能力增加來吸收 Infinity Cache 延遲的增加。事實上,一個 WGP 的 Infinity Cache 帶寬與 RDNA 2 中的帶寬相比有所下降。當我們使用 VRAM 時,情況再次翻轉,RDNA 3 領先。
帶寬縮放
共享緩存很好,因為可以更有效地使用它們的容量。共享緩存可以存儲數據一次并為來自多個計算單元的請求提供服務,而不是在多個私有緩存之間復制共享數據。然而,共享緩存很難實現,因為它必須能夠處理所有客戶端的帶寬需求。
我們將從 L2 帶寬開始,因為 L0 和 L1 帶寬幾乎呈線性擴展。L2 縮放更難實現,因為單個 6 MB L2 緩存必須為 GPU 上的所有 48 個 WGP 提供服務。考慮到這一點,RDNA 3 的 L2 在擴展方面做得非常好,可以滿足所有這些 WGP 的帶寬需求。隨著 WGP 數量的增加,RDNA 3 的 L2 帶寬開始遠離 RDNA 2。
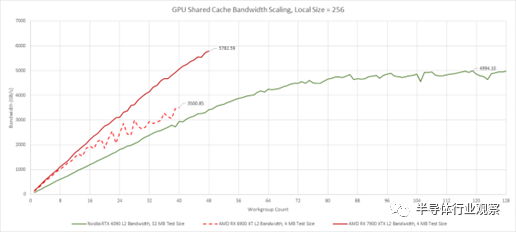
與 Nvidia 的 Ada Lovelace 相比,這兩種 AMD 架構都能夠為匹配的工作組數量提供更多的 L2 帶寬。但是,RTX 4090 具有更大的一級緩存,應該可以減少 L2 流量。Ada Lovelace 的 L2 也起著稍微不同的作用,兼作某種 Infinity Cache。考慮到其非常大的容量,Nvidia 的 L2 表現非常出色。如果我們與具有相似容量的 RDNA 3 的 Infinity Cache 進行比較,Ada 的 L2 在低占用率下保持相似的帶寬。當 Ada 的所有 SM 都發揮作用時,Nvidia 將享有巨大的帶寬優勢。當然,AMD 的 Infinity Cache 不需要提供那么多的帶寬,因為 L2 緩存通常會吸收相當比例的 L1 未命中流量。
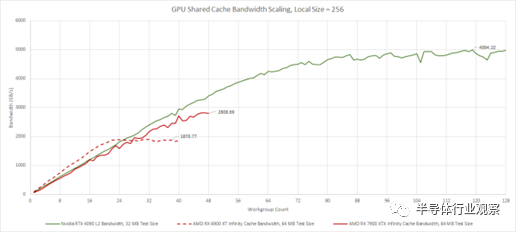
與 RDNA 2 相比,RDNA 3 的 Infinity Cache 的提升速度稍慢,并且加載不到其 WGP 的一半處于劣勢。但是,當工作負載擴展到填滿所有 WGP 時,RDNA 3 的 Infinity Cache 顯示出比 RDNA 2 更大的帶寬優勢。
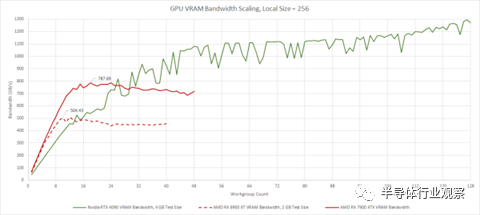
4090 夸大了其最大內存帶寬,因為我們的測試無法完全擊敗 4090 上的讀取組合
從 VRAM 來看,兩種 AMD 架構都以低占用率享有非常好的帶寬。
RDNA 3 從一個小優勢開始,隨著更多 WGP 發揮作用而變得更大。從另一個角度來看,RDNA 2 的 256 位 GDDR6 設置可能僅用 10 個 WGP 就可以飽和。RDNA 3 更大的 VRAM 子系統可以滿足更多需要全帶寬的 WGP。如果僅加載少量 SM,Nvidia 在 VRAM 帶寬方面會遇到更多麻煩,但在占用率較高時處于領先地位。
本地內存延遲
除了常規的全局內存層次結構之外,GPU 還具有快速暫存器內存。OpenCL 調用這個本地內存。在 AMD GPU 上,相應的結構稱為本地數據共享 (LDS)。Nvidia GPU 稱之為共享內存。與緩存不同,軟件必須明確分配和管理本地內存容量。一旦數據在 LDS 中,軟件就可以期望有保證的高帶寬和低延遲訪問該數據。
與前幾代 RDNA 一樣,每個 RDNA 3 WGP 都有一個 128 KB 的 LDS。LDS 內部構建有兩個 64 KB 塊,每個塊都隸屬于 WGP 中的一個 CU。每個 64 KB 塊包含 32 個存儲區,每個存儲區可以處理 32 位寬的訪問。這使得 LDS 可以在每個周期為波前范圍的負載提供服務。我們目前沒有針對 LDS 帶寬的測試,但 RDNA 3 似乎具有非常低的延遲 LDS。
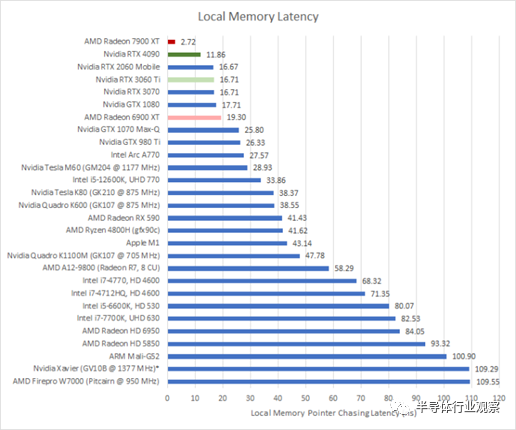
*Xavier 結果可能不準確,因為該 GPU 上的時鐘斜坡非常慢
由于架構改進和更高的時鐘速度相結合,RDNA 3 大大改善了 LDS 延遲。Nvidia 的本地內存延遲略高于 AMD 的架構,但 RDNA 3 改變了這一點。當 RDNA 3 處理光線追蹤時,低 LDS 延遲可能非常有用,因為 LDS 用于存儲 BVH 遍歷堆棧。
作為比較,RDNA 2 的 LDS 具有與其標量緩存大致相同的加載到使用延遲。它仍然非常有用,因為它可以比從 L0 向量緩存中更快地將數據放入向量寄存器。我檢查了這個測試的編譯代碼,它正在使用向量寄存器,即使工作組中除了一個線程之外的所有線程都被屏蔽了。
WGP 計算特性
相比RDNA 2,RDNA 3在計算吞吐量上明顯有很大優勢。畢竟,它具有更高的 WGP 計數。但計算吞吐量的潛在增長不止于此,因為 RDNA 3 的 SIMD 獲得了有限的雙重發布能力。在 wave32 模式下,某些常用操作可以打包到單個 VOPD(向量操作,對偶)指令中。在 wave64 模式下,SIMD 自然會嘗試在單個周期內開始執行 64 寬波前,前提是指令可以雙重發出。
RDNA 3 VOPD 指令以八個字節編碼,并支持兩個操作中的每一個的兩個源和一個目標。這不包括需要三個輸入的操作,例如通用的融合乘加操作。雙重發行機會進一步受到可用執行單元、數據依賴性和寄存器文件帶寬的限制。
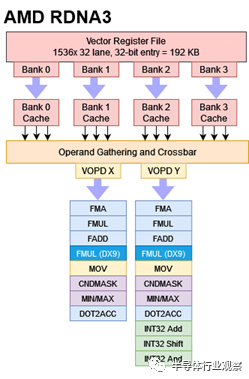
同一位置的操作數不能從同一寄存器組(register bank)讀取。早些時候我們推測這是handling bank 沖突的局限性。然而,AMD 的 ISA 手冊明確指出,每個存儲體實際上都有一個寄存器緩存,其中包含三個讀取端口,每個端口都與一個操作數位置相關聯。來自相同源位置的相同存儲體的兩次讀取將超額訂閱寄存器高速緩存端口。另一個限制適用于目標寄存器,它不能同時是偶數或奇數。
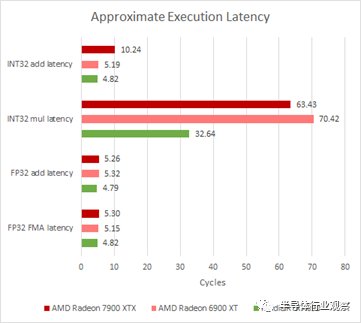
在此測試中,我們運行單個工作組以將測試保持在 WGP 的本地。由于最近 GPU 上的提升行為變化很大,我們將時鐘鎖定到 1 GHz 以深入了解每個時鐘的行為。
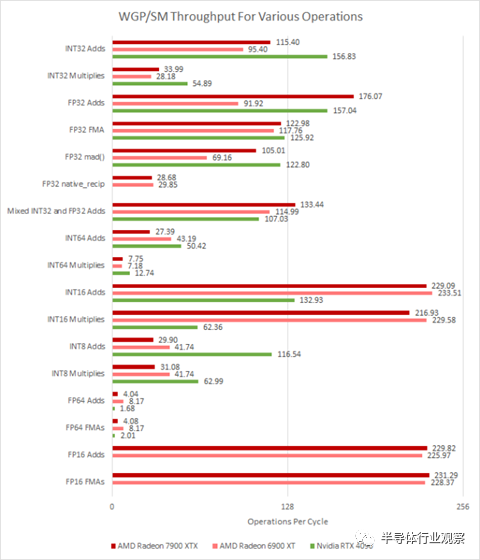
我的測試肯定高估了 Ada 的 FP32 和 INT32 添加,或者 2.7 GHz 時鐘速度的假設已關閉
不幸的是,通過 OpenCL 進行測試很困難,因為我們依賴編譯器來尋找雙重問題機會。我們只看到 FP32 添加令人信服的雙重問題行為,其中編譯器發出 v_dual_add_f32 指令。混合 INT32 和 FP32 加法測試看到了一些好處,因為 FP32 加法是雙重發出的,但由于缺少用于 INT32 操作的 VOPD 指令,因此無法為 INT32 生成 VOPD 指令。用于計算 GPU 的標題 TFLOPs 數的融合乘加看到很少發出雙重問題指令。兩種架構都可以雙倍速率執行 16 位操作,盡管這與 RDNA 3 的新雙發射功能無關。相反,16 位指令受益于以壓縮數學模式發出的單個操作。在其他主要類別中,吞吐量與 RDNA 2 基本相似。
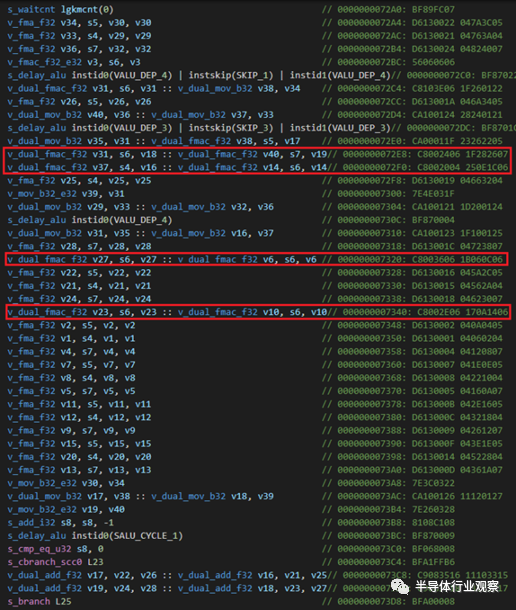
為融合乘加測試生成的 RDNA 3 代碼,雙問題對標記為紅色
我猜 RDNA 3 的雙發模式影響有限。它在很大程度上依賴于編譯器來尋找 VOPD 的可能性,而編譯器在看到非常簡單的優化時愚蠢得令人沮喪。例如,上面的 FMA 測試對兩個輸入使用一個變量,這應該使編譯器能夠滿足雙重問題約束。但顯然,編譯器并沒有讓它發生。我們還使用 clpeak 進行了測試,并在那里看到了類似的行為。即使編譯器能夠發出 VOPD 指令,只有在計算吞吐量成為瓶頸而不是內存性能時,性能才會提高。

從 AMD 的新聞稿中幻燈片,注意到新的雙重發行能力
另一方面,VOPD 確實留下了改進的潛力。AMD 可以通過用手動優化的程序集替換已知的著色器來優化游戲,而不是依賴于編譯器代碼生成。與編譯器所希望的相比,人類更善于發現雙重問題機會。Wave64 模式是另一個機會。在 RDNA 2 上,AMD 似乎將許多像素著色器編譯為 wave64 模式,在這種模式下,雙重問題可能會在編譯器沒有任何調度或寄存器分配智能的情況下發生。
一旦 AMD 有更多時間優化架構,看看 RDNA 3 的性能將會很有趣,但他們絕對有理由不將 VOPD 雙問題功能作為額外的著色器來宣傳。通常,GPU 制造商使用著色器計數來描述他們的 GPU 每個周期可以完成多少 FP32 操作。理論上,VOPD 將使每個 WGP 的 FP32 吞吐量翻倍,除了額外的執行單元外,硬件開銷非常小。但它是通過將繁重的調度責任推給編譯器來實現的。AMD 可能意識到編譯器技術無法勝任這項任務,而且不會很快達到目標。
在指令延遲方面,RDNA 3 與之前的 RDNA 架構相似。常見的 FP 操作以 5 個周期的延遲執行。Nvidia 在這方面略有優勢,能夠以 4 個周期的延遲執行常見操作。
GPU 不進行分支預測,也不像 CPU 那樣具有強大的標量執行能力,因此循環開銷通常會導致延遲被高估,即使在展開時也是如此
從圖靈開始,Nvidia 也實現了非常好的整數乘法性能。整數乘法在著色器代碼中似乎極為罕見,而且 AMD 似乎也沒有針對它進行優化。32 位整數乘法的執行速度約為 FP32 的四分之一,而且延遲也相當高。
全 GPU 吞吐量——Vulkan
在這里,我們使用 Nemes 的 GPU 基準測試套件來測試完整的 GPU 吞吐量,其中考慮了所有 WGP 處于活動狀態時的加速時鐘。RDNA 3 通過 VOPD 指令、更高的 WGP 計數和更高的時鐘速度實現更高的吞吐量。奇怪的是,AMD的編譯器非常愿意將Nemes的測試代碼序列轉化為VOPD指令。
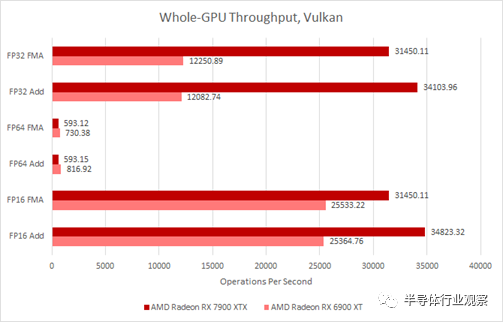
為了從每秒操作中獲得 FLOP 數,將 FMA 數乘以 2,這為 FP32 和 FP16 FMA 計算提供了 62.9 TFLOP。
結果是 FP32 吞吐量大幅增加。FP16 的吞吐量增加較小,因為 RDNA 2 能夠使用打包的 FP16 執行,以及 v_pk_add_f16 等指令。這些指令將每個 32 位寄存器解釋為兩個 16 位元素,從而使吞吐量翻倍。RDNA 3 做同樣的事情,但不能雙重發出這樣的打包指令。奇怪的是,RDNA 3 實際上在 FP64 吞吐量上倒退了。我們之前已經在 OpenCL 中看到了這一點,其中一個 RDNA 2 WGP 每個周期可以執行八個 FP64 操作。RDNA 3 將吞吐量減半,這意味著 WGP 可以執行四次 FP64 操作——可能每個周期每個 SIMD 一個。
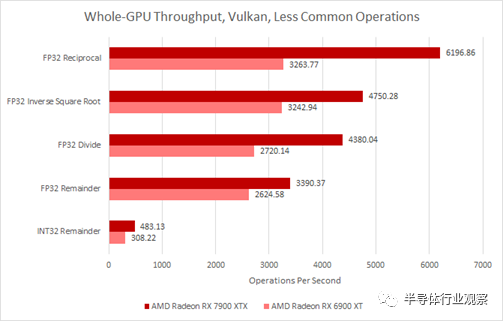
兩個 GPU 上特殊操作的吞吐量都較低。倒數通常用作避免昂貴的除法運算的一種方式,并且在兩種體系結構上都以四分之一的速率運行。除法甚至更慢,對整數運算進行模塊化運算與進行 FP64 一樣慢。
現在,讓我們談談 AMD 聲稱的 123TFLOP FP16 數字。雖然這在技術上是正確的,但這個數字有很大的局限性。查看 RDNA3 ISA 文檔,只有一個 VOPD 指令可以同時發出打包的 FP16 指令和另一個可以使用打包的 BF16 數字的指令。

這些是可以使用壓縮數學的 2 條 VOPD 指令。
這意味著標題 123TF FP16 數字只會在非常有限的場景中看到,主要是在 AI 和 ML 工作負載中,盡管游戲已經開始更頻繁地使用 FP16。
PCIe鏈路
Radeon 7900 XTX 通過 PCIe 4.0 x16 鏈接連接到主機。與 RDNA 2 一樣,AMD 的新圖形架構在將數據移動到 GPU 時表現非常出色,尤其是在中等大小的塊中。從 GPU 獲取數據時傳輸速率較低。
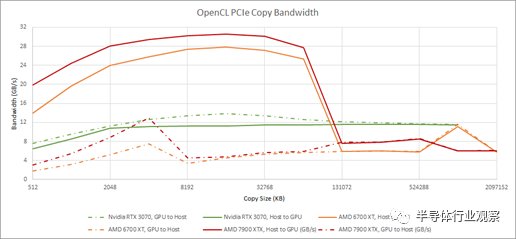
使用 Smcelrea 的 6700 XT 結果是因為我的 6900 XT 沒有設置可調整大小的 BAR,這似乎會影響 OpenCL 帶寬結果。
Nvidia 處于中間位置,在所有副本大小和方向上都具有不錯的傳輸速度。在大拷貝尺寸下,Nvidia 似乎比 AMD 在 PCIe 傳輸帶寬方面具有優勢。
內核啟動延遲
在這里,我們使用clpeak來估計 GPU 啟動內核并報告其完成所需的時間。Clpeak 通過向 GPU 提交極少量的工作并測試完成所需的時間來做到這一點。
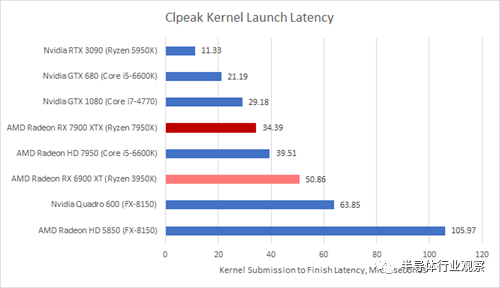
Terascale 2 在這里做什么?5850怎么還活著?不要質疑它......
結果似乎相差很大,我們無法將平臺與我們的測試模型相匹配。然而,我們可以看出 RDNA 3 沒有任何異常。Nvidia 的 GPU 內核啟動速度可能稍快一些,但由于我們無法匹配平臺,因此很難得出任何結論。
最后的話
AMD 的 RDNA 2 架構使該公司的 GPU 與 Nvidia 的最佳性能相差無幾,這標志著 AMD 與 Nvidia 最高端卡的距離達到了另一個例子。
RDNA 3 希望通過擴大 RDNA 2 來推進這一點,同時引入旨在提高性能的架構改進,而不僅僅是添加 WGP。AMD 采用多管齊下的策略來實現這一目標。
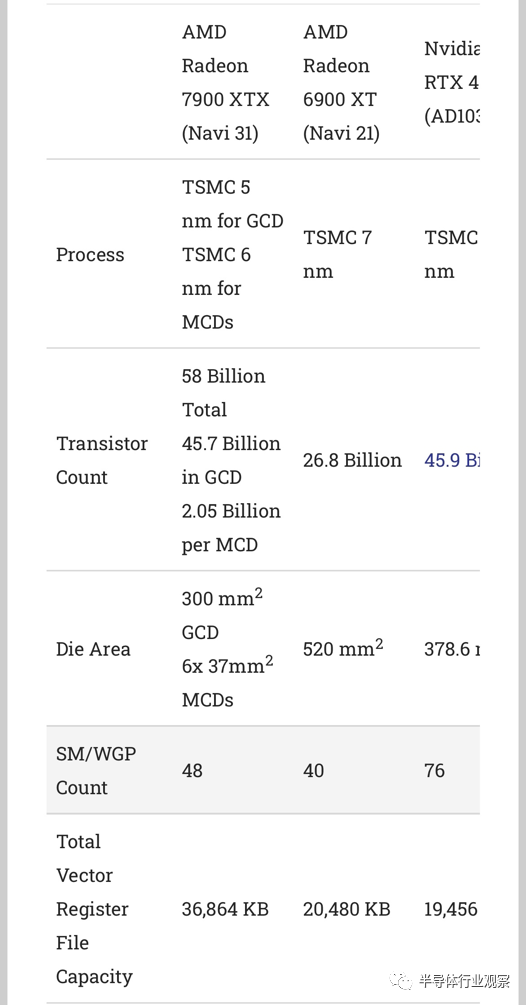
在物理實現方面,AMD 轉向了臺積電更先進的 5 納米工藝節點。5 nm 允許更高的晶體管密度,并在沒有膨脹區域的情況下改進 WGP。因此,WGP 獲得了增加的寄存器文件大小和雙重發布能力。Chiplet 技術通過將 Infinity Cache 和內存控制器移動到單獨的芯片上,可以實現更小的 5 納米主芯片。這有助于通過在圖形芯片上使用更少的區域來實現 VRAM 連接,從而實現更高帶寬的 VRAM 設置。
更高的帶寬是支持更大 GPU 的關鍵,而 AMD 超越了 VRAM 帶寬。緩存帶寬在每個級別都會增加。AMD 還增加了片上緩存的容量,因為即使在片之間有中介層,片外訪問也更耗電。即使采用小芯片設置,AMD 也需要最大限度地提高面積效率,dual issue 就是一個很好的例子。VOPD 指令允許 AMD 為最常見的操作添加額外的執行單元,但在其他地方的額外開銷很少。AMD 還增加了矢量寄存器文件容量,這應該有助于提高占用率。而且,它們極大地減少了 LDS 延遲。光線追蹤似乎是這一變化的明顯受益者。
結果是 GPU 的性能非常接近 Nvidia 的 RTX 4080。根據Hardware?Unboxed,7900 XTX 在 1440p 時慢 1%,在 4K 時快 1%。AMD 沒有使用非常大的 WGP/SM 數量,而是通過提高每個 WGP 的吞吐量來實現其性能。他們還專注于為 WGP 提供更復雜的內存層次結構。與上一代相比,最后一級緩存的總容量有所下降,因為 384 位內存總線意味著 RDNA 3 不需要那么高的緩存命中率來避免帶寬瓶頸。
?
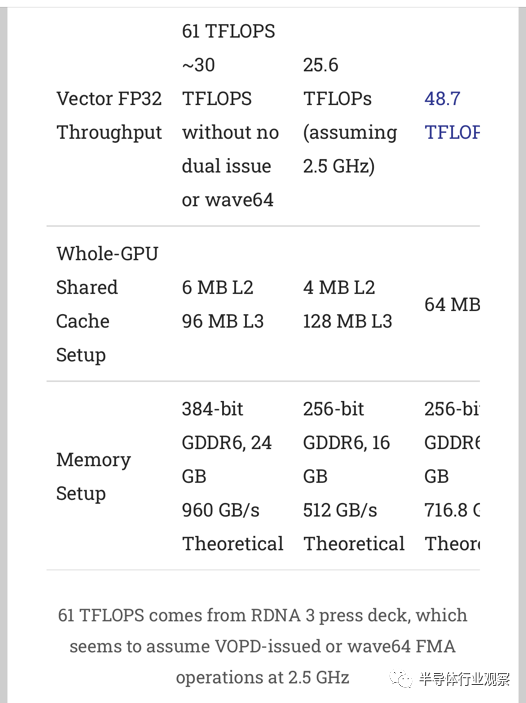
AMD 和 Nvidia 因此做出不同的權衡以達到相同的性能水平。通過將緩存和內存控制器放在單獨的 6 納米芯片上,小芯片設置幫助 AMD 在領先的工藝節點中使用比 Nvidia 更少的芯片面積。作為交換,AMD 必須支付更昂貴的封裝解決方案費用,因為簡單的封裝走線在處理 GPU 的高帶寬要求方面表現不佳。
Nvidia 將所有東西都放在一個更大的芯片上,采用尖端的 4 納米節點。這使得 4080 的 VRAM 帶寬和緩存比 7900 XTX 更少。它們的晶體管密度在技術上低于 AMD,但這是因為 Nvidia 更高的 SM 數量意味著與寄存器文件和 FMA 單元相比它們具有更多的控制邏輯。每個 SM 更少的執行單元意味著 Ada Lovelace 將更容易讓這些執行單元得到滿足。
Nvidia 還具有更簡單的緩存層次結構的優勢,它仍然提供相當大的緩存容量。
無論如何,很高興看到 AMD 和 Nvidia 在 Nvidia 多年無可置疑的領先優勢之后繼續正面交鋒。希望這會導致未來 GPU 價格下降,以及雙方更多的創新。
編輯:黃飛
?















 工商網監
工商網監
評論