 電子發燒友App
電子發燒友App


CPU、GPU、DPU、TPU、NPU……各種不同的XPU還分不同等級的系列,價格也大不相同。
常見的XPU的英文全稱:
CPU全稱:Central Processing Unit, 中央處理器;
GPU全稱:Graphics Processing Unit, 圖像處理器;
TPU全稱:Tensor Processing Unit, 張量處理器;
DPU全稱:Deep learning Processing Unit, 深度學習處理器;
NPU全稱:Neural network Processing Unit, 神經網絡處理器;
BPU全稱:Brain Processing Unit, 大腦處理器。
下面簡單總結一下這些“XPU”。
1、CPU:中央處理器
CPU( Central Processing Unit, 中央處理器)一般是指的設備的“大腦”,是整體布局、發布執行命令、控制行動的總指揮。
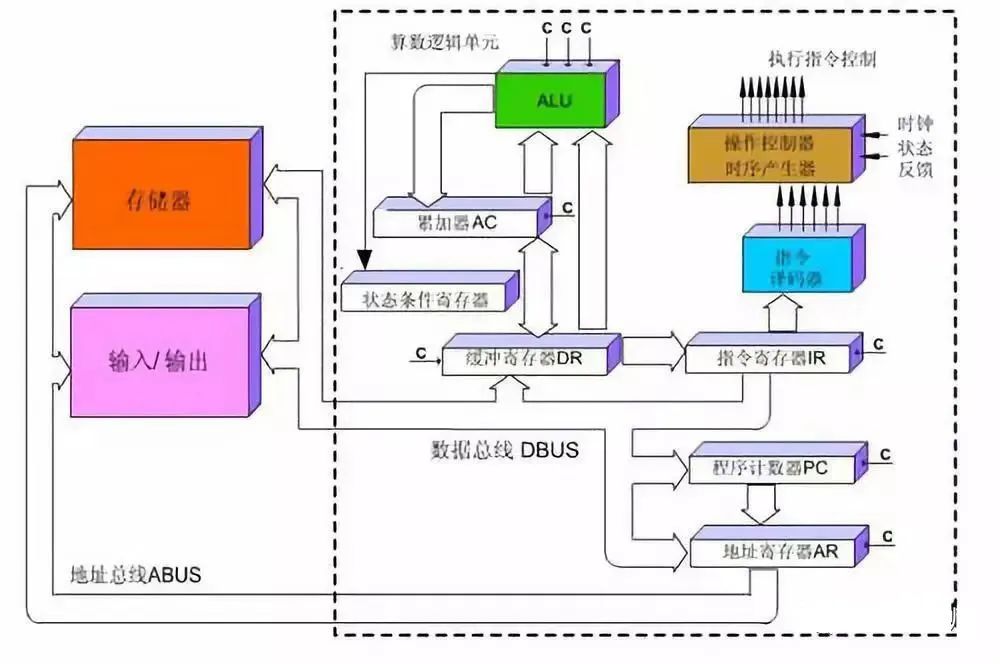
CPU主要包括運算器(ALU, Arithmetic and Logic Unit)和控制單元(CU, Control Unit),除此之外還包括若干寄存器、高速緩存器和它們之間通訊的數據、控制及狀態的總線。CPU遵循的是馮諾依曼架構,即存儲程序、順序執行。一條指令在CPU中執行的過程是:讀取到指令后,通過指令總線送到控制器中進行譯碼,并發出相應的操作控制信號。然后運算器按照操作指令對數據進行計算,并通過數據總線將得到的數據存入數據緩存器。因此,CPU需要大量的空間去放置存儲單元和控制邏輯,相比之下計算能力只占據了很小的一部分,在大規模并行計算能力上極受限制,而更擅長于邏輯控制。
簡單一點來說CPU主要就是三部分:計算單元、控制單元和存儲單元。
2、GPU:圖像處理器
在正式了解GPU之前,先了解一個概念——并行計算。
并行計算(Parallel Computing)是指同時使用多種計算資源解決計算問題的過程,是提高計算機系統計算速度和數據處理能力的一種有效手段。它的基本思想是用多個處理器來共同求解同一個問題,即將被求解的問題分解成若干個部分,各部分均由一個獨立的處理機來并行計算完成。
并行計算可分為時間上的并行和空間上的并行。
時間上的并行是指流水線技術,比如說工廠生產食品的時候分為四步:清洗-消毒-切割-包裝。
如果不采用流水線,一個食品完成上述四個步驟后,下一個食品才進行處理,耗時且影響效率。但是采用流水線技術,就可以同時處理四個食品。這就是并行算法中的時間并行,在同一時間啟動兩個或兩個以上的操作,大大提高計算性能。
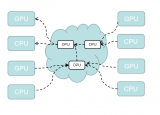
空間上的并行是指多個處理機并發的執行計算,即通過網絡將兩個以上的處理機連接起來,達到同時計算同一個任務的不同部分,或者單個處理機無法解決的大型問題。
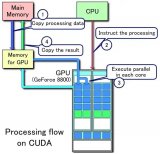
為了解決CPU在大規模并行運算中遇到的困難, GPU應運而生,GPU全稱為Graphics Processing Unit,中文為圖形處理器,就如它的名字一樣,圖形處理器,GPU最初是用在個人電腦、工作站、游戲機和一些移動設備(如平板電腦、智能手機等)上運行繪圖運算工作的微處理器。
GPU采用數量眾多的計算單元和超長的流水線,善于處理圖像領域的運算加速。但GPU無法單獨工作,必須由CPU進行控制調用才能工作。CPU可單獨作用,處理復雜的邏輯運算和不同的數據類型,但當需要大量的處理類型統一的數據時,則可調用GPU進行并行計算。近年來,人工智能的興起主要依賴于大數據的發展、算法模型的完善和硬件計算能力的提升。其中硬件的發展則歸功于GPU的出現。
為什么GPU特別擅長處理圖像數據呢?這是因為圖像上的每一個像素點都有被處理的需要,而且每個像素點處理的過程和方式都十分相似,也就成了GPU的天然溫床。
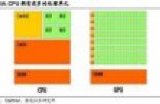
從架構圖我們就能很明顯的看出,GPU的構成相對簡單,有數量眾多的計算單元和超長的流水線,特別適合處理大量的類型統一的數據。
但GPU無法單獨工作,必須由CPU進行控制調用才能工作。CPU可單獨作用,處理復雜的邏輯運算和不同的數據類型,但當需要大量的處理類型統一的數據時,則可調用GPU進行并行計算。
注:GPU中有很多的運算器ALU和很少的緩存cache,緩存的目的不是保存后面需要訪問的數據的,這點和CPU不同,而是為線程thread提高服務的。如果有很多線程需要訪問同一個相同的數據,緩存會合并這些訪問,然后再去訪問dram。
再把CPU和GPU兩者放在一張圖上看下對比,就非常一目了然了。
有一點需要強調,雖然GPU是為了圖像處理而生的,但是我們通過前面的介紹可以發現,它在結構上并沒有專門為圖像服務的部件,只是對CPU的結構進行了優化與調整,所以現在GPU不僅可以在圖像處理領域大顯身手,它還被用來科學計算、密碼破解、數值分析,海量數據處理(排序,Map-Reduce等),金融分析等需要大規模并行計算的領域。
所以GPU也可以認為是一種較通用的芯片。
3、TPU:張量處理器
按照上文所述,CPU和GPU都是較為通用的芯片,但是有句老話說得好:萬能工具的效率永遠比不上專用工具。
隨著人們的計算需求越來越專業化,人們希望有芯片可以更加符合自己的專業需求,這時,便產生了ASIC(專用集成電路)的概念。
ASIC是指依產品需求不同而定制化的特殊規格集成電路,由特定使用者要求和特定電子系統的需要而設計、制造。當然這概念不用記,簡單來說就是定制化芯片。
因為ASIC很“專一”,只做一件事,所以它就會比CPU、GPU等能做很多件事的芯片在某件事上做的更好,實現更高的處理速度和更低的能耗。但相應的,ASIC的生產成本也非常高。
而TPU(Tensor Processing Unit, 張量處理器)就是谷歌專門為加速深層神經網絡運算能力而研發的一款芯片,其實也是一款ASIC。
人工智能旨在為機器賦予人的智能,機器學習是實現人工智能的強有力方法。所謂機器學習,即研究如何讓計算機自動學習的學科。TPU就是這樣一款專用于機器學習的芯片,它是Google于2016年5月提出的一個針對Tensorflow平臺的可編程AI加速器,其內部的指令集在Tensorflow程序變化或者更新算法時也可以運行。TPU可以提供高吞吐量的低精度計算,用于模型的前向運算而不是模型訓練,且能效(TOPS/w)更高。在Google內部,CPU,GPU,TPU均獲得了一定的應用,相比GPU,TPU更加類似于DSP,盡管計算能力略有遜色,但是其功耗大大降低,而且計算速度非常的快。然而,TPU,GPU的應用都要受到CPU的控制。
原來很多的機器學習以及圖像處理算法大部分都跑在GPU與FPGA(半定制化芯片)上面,但這兩種芯片都還是一種通用性芯片,所以在效能與功耗上還是不能更緊密的適配機器學習算法,而且Google一直堅信偉大的軟件將在偉大的硬件的幫助下更加大放異彩,所以Google便想,我們可不可以做出一款專用機機器學習算法的專用芯片,TPU便誕生了。
據稱,TPU與同期的CPU和GPU相比,可以提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升。初代的TPU只能做推理,要依靠Google云來實時收集數據并產生結果,而訓練過程還需要額外的資源;而第二代TPU既可以用于訓練神經網絡,又可以用于推理。
為什么TPU會在性能上這么牛呢?TPU是怎么做到如此之快呢?
(1)深度學習的定制化研發:TPU 是谷歌專門為加速深層神經網絡運算能力而研發的一款芯片,其實也是一款 ASIC(專用集成電路)。
(2)大規模片上內存:TPU 在芯片上使用了高達 24MB 的局部內存,6MB 的累加器內存以及用于與主控處理器進行對接的內存。
(3)低精度 (8-bit) 計算:TPU 的高性能還來源于對于低運算精度的容忍,TPU 采用了 8-bit 的低精度運算,也就是說每一步操作 TPU 將會需要更少的晶體管。
4、NPU:神經網絡處理器
所謂NPU(Neural network Processing Unit), 即神經網絡處理器。神經網絡處理器(NPU)采用“數據驅動并行計算”的架構,特別擅長處理視頻、圖像類的海量多媒體數據。NPU處理器專門為物聯網人工智能而設計,用于加速神經網絡的運算,解決傳統芯片在神經網絡運算時效率低下的問題。
在GX8010中,CPU和MCU各有一個NPU,MCU中的NPU相對較小,習慣上稱為SNPU。NPU處理器包括了乘加、激活函數、二維數據運算、解壓縮等模塊。乘加模塊用于計算矩陣乘加、卷積、點乘等功能,NPU內部有64個MAC,SNPU有32個。
激活函數模塊采用最高12階參數擬合的方式實現神經網絡中的激活函數,NPU內部有6個MAC,SNPU有3個。二維數據運算模塊用于實現對一個平面的運算,如降采樣、平面數據拷貝等,NPU內部有1個MAC,SNPU有1個。解壓縮模塊用于對權重數據的解壓。為了解決物聯網設備中內存帶寬小的特點,在NPU編譯器中會對神經網絡中的權重進行壓縮,在幾乎不影響精度的情況下,可以實現6-10倍的壓縮效果。
既然叫神經網絡處理器,顧名思義,就是想用電路模擬人類的神經元和突觸結構!
由于深度學習的基本操作是神經元和突觸的處理,而傳統的處理器指令集(包括x86和ARM等)是為了進行通用計算發展起來的,其基本操作為算術操作(加減乘除)和邏輯操作(與或非),往往需要數百甚至上千條指令才能完成一個神經元的處理,深度學習的處理效率不高。
神經網絡中存儲和處理是一體化的,都是通過突觸權重來體現。而馮·諾伊曼結構中,存儲和處理是分離的,分別由存儲器和運算器來實現,二者之間存在巨大的差異。當用現有的基于馮·諾伊曼結構的經典計算機(如X86處理器和英偉達GPU)來跑神經網絡應用時,就不可避免地受到存儲和處理分離式結構的制約,因而影響效率。這也就是專門針對人工智能的專業芯片能夠對傳統芯片有一定先天優勢的原因之一。
5、BPU:大腦處理器
Brain Processing Unit (大腦處理器)。地平線機器人(Horizon Robotics)以 BPU 來命名自家的 AI 芯片。地平線是一家成立于 2015 年的 start-up,總部在北京,目標是“嵌入式人工智能全球領導者”。地平線的芯片未來會直接應用于自己的主要產品中,包括:智能駕駛、智能生活和智能城市。地平線機器人的公司名容易讓人誤解,以為是做“機器人”的,其實不然。地平線做的不是“機器”的部分,是在做“人”的部分,是在做人工智能的“大腦”,所以,其處理器命名為 BPU。相比于國內外其他 AI 芯片 start-up 公司,第一代是高斯架構,第二代是伯努利架構,第三代是貝葉斯架構。目前地平線已經設計出了第一代高斯架構,并與英特爾在2017年CES展會上聯合推出了ADAS系統(高級駕駛輔助系統)。BPU主要是用來支撐深度神經網絡,比在CPU上用軟件實現更為高效。然而,BPU一旦生產,不可再編程,且必須在CPU控制下使用。BPU 已經被地平線申請了注冊商標,其他公司就別打 BPU 的主意了。
Biological Processing Unit。一個口號“21 世紀是生物學的世紀”忽悠了無數的有志青年跳入了生物領域的大坑。其實,這句話需要這么理解,生物學的進展會推動 21 世紀其他學科的發展。比如,對人腦神經系統的研究成果就會推動 AI 領域的發展,SNN 結構就是對人腦神經元的模擬。不管怎么說,隨著時間的推移,坑總會被填平的。不知道生物處理器在什么時間會有質的發展。
Bio-Recognition Processing Unit。生物特征識別現在已經不是紙上談兵的事情了。指紋識別已經是近來智能手機的標配,電影里的黑科技虹膜識別也上了手機,聲紋識別可以支付了 ... 不過,除了指紋識別有專門的 ASIC 芯片外,其他生物識別還基本都是 sensor 加通用 cpu/dsp 的方案。不管怎樣,這些芯片都沒占用 BPU 或 BRPU 這個寶貴位置。
D 是 Deep Learning 的首字母,以 Deep Learning 開頭來命名 AI 芯片是一種很自然的思路。
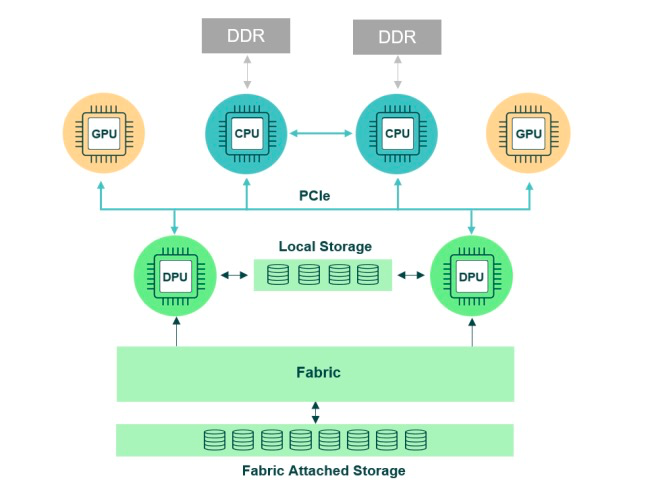
6、DPU:深度學習處理器
Deep-Learning Processing Unit(深度學習處理器)。DPU 并不是哪家公司的專屬術語。在學術圈,Deep Learning Processing Unit(或 processor)被經常提及。例如 ISSCC 2017 新增的一個 session 的主題就是 Deep Learning Processor。以 DPU 為目標的公司如下。
Deephi Tech(深鑒) 深鑒是一家位于北京的 start-up,初創團隊有很深的清華背景。深鑒將其開發的基于 FPGA 的神經網絡處理器稱為 DPU。到目前為止,深鑒公開發布了兩款 DPU:亞里士多德架構和笛卡爾架構,分別針對 CNN 以及 DNN/RNN。雖然深鑒號稱是做基于 FPGA 的處理器開發,但是從公開渠道可以看到的招聘信息以及非公開的業內交流來看,其做芯片已成事實。
TensTorrent 一家位于 Toronto 的 start-up,研發專為深度學習和智能硬件而設計的高性能處理器,技術人員來自 NVDIA 和 AMD。
Deep Learning Unit。深度學習單元。Fujitsu(富士通)最近高調宣布了自家的 AI 芯片,命名為 DLU。名字雖然沒什么創意,但是可以看到 DLU 已經被富士通標了“TM”,雖然 TM 也沒啥用。在其公布的信息里可以看到,DLU 的 ISA 是重新設計的,DLU 的架構中包含眾多小的 DPU(Deep Learning Processing Unit)和幾個大的 master core(控制多個 DPU 和 memory 訪問)。每個 DPU 中又包含了 16 個 DPE(Deep-Learning Processing Element),共 128 個執行單元來執行 SIMD 指令。富士通預計 2018 財年內推出 DLU。
Deep Learning Accelerator。深度學習加速器。NVIDA 宣布將這個 DLA 開源,給業界帶來了不小的波瀾。大家都在猜測開源 DLA 會給其他 AI 公司帶來什么。參考這篇吧"從 Nvidia 開源深度學習加速器說起"
Dataflow Processing Unit。數據流處理器。創立于 2010 年的 wave computing 公司將其開發的深度學習加速處理器稱為 Dataflow Processing Unit(DPU),應用于數據中心。Wave 的 DPU 內集成 1024 個 cluster。每個 Cluster 對應一個獨立的全定制版圖,每個 Cluster 內包含 8 個算術單元和 16 個 PE。其中,PE 用異步邏輯設計實現,沒有時鐘信號,由數據流驅動,這就是其稱為 Dataflow Processor 的緣由。使用 TSMC 16nm FinFET 工藝,DPU die 面積大概 400mm^2,內部單口 sram 至少 24MB,功耗約為 200W,等效頻率可達 10GHz,性能可達 181TOPS。前面寫過一篇他家 DPU 的分析,見傳輸門 AI 芯片|淺析 Yann LeCun 提到的兩款 Dataflow Chip。
Digital Signal Processor。數字信號處理器。芯片行業的人對 DSP 都不陌生,設計 DSP 的公司也很多,TI,Qualcomm,CEVA,Tensilica,ADI,Freescale 等等,都是大公司,此處不多做介紹。相比于 CPU,DSP 通過增加指令并行度來提高數字計算的性能,如 SIMD、VLIW、SuperScalar 等技術。面對 AI 領域新的計算方式(例如 CNN、DNN 等)的挑戰,DSP 公司也在馬不停蹄地改造自己的 DSP,推出支持神經網絡計算的芯片系列。在后面 VPU 的部分,會介紹一下針對 Vision 應用的 DSP。和 CPU 一樣,DSP 的技術很長時間以來都掌握在外國公司手里,國內也不乏兢兢業業在這方向努力的科研院所,如清華大學微電子所的 Lily DSP(VLIW 架構,有獨立的編譯器),以及國防科大的 YHFT-QDSP 和矩陣 2000。但是,也有臭名昭著的“漢芯”。?
國際上,Wave Computing最早提出DPU。在國內,DPU最早是由深鑒科技提出,是基于Xilinx可重構特性的FPGA芯片,設計專用深度學習處理單元,且可以抽象出定制化的指令集和編譯器,從而實現快速的開發與產品迭代。
7、被占用的XPU
據說每過18天,集成電路領域就會多出一個XPU,直到26個字母被用完。這被戲稱為AI時代的XPU版摩爾定律。
據不完全統計,已經被用掉的有:
7.1、APU
Accelerated Processing Unit, 加速處理器,AMD公司推出加速圖像處理芯片產品。
7.2、BPU
Brain Processing Unit,大腦處理器, 地平線公司主導的嵌入式處理器架構。
7.3、CPU
Central Processing Unit 中央處理器, 目前PC core的主流產品。
7.4、DPU
Deep learning Processing Unit, 深度學習處理器,最早由國內深鑒科技提出;另說有Dataflow Processing Unit 數據流處理器, Wave Computing 公司提出的AI架構;Data storage Processing Unit,深圳大普微的智能固態硬盤處理器。
7.5、EPU
Emotion Processing Unit 情感處理器,Emoshape 并不是這兩年才推出 EPU 的,號稱是全球首款情緒合成(emotion synthesis)引擎,可以讓機器人具有情緒。但是,從官方渠道消息看,EPU 本身并不復雜,也不需要做任務量巨大的神經網絡計算,是基于 MCU 的芯片。結合應用 API 以及云端的增強學習算法,EPU 可以讓機器能夠在情緒上了解它們所讀或所看的內容。結合自然語言生成(NLG)及 WaveNet 技術,可以讓機器個性化的表達各種情緒。例如,一部能夠朗讀的 Kindle,其語音將根據所讀的內容充滿不同的情緒狀態。
7.6、FPU
Floating Processing Unit 浮點計算器,浮點單元,不多做解釋了。現在高性能的 CPU、DSP、GPU 內都集成了 FPU 做浮點運算。 Force Processing Unit。原力處理。
7.7、GPU
Graphics Processing Unit, 圖形處理器,采用多線程SIMD架構,為圖形處理而生。
7.8、HPU
Holographics Processing Unit 全息圖像處理器。Microsoft 專為自家 Hololens 應用開發的。第一代 HPU 采用 28nm HPC 工藝,使用了 24 個 Tensilica DSP 并進行了定制化擴展。HPU 支持 5 路 cameras、1 路深度傳感器(Depth sensor)和 1 路動作傳感器(Motion Sensor)。Microsoft 在最近的 CVPR 2017 上宣布了 HPU2 的一些信息。HPU2 將搭載一顆支持 DNN 的協處理器,專門用于在本地運行各種深度學習。指的一提的是,HPU 是一款為特定應用所打造的芯片,這個做產品的思路可以學習。據說 Microsoft 評測過 Movidius(見 VPU 部分)的芯片,但是覺得無法滿足算法對性能、功耗和延遲的要求,所有才有了 HPU。
7.9、IPU
Intelligence Processing Unit,智能處理器, Deep Mind投資的Graphcore公司出品的AI處理器產品。
7.10、JPU
一種新型聯合上采樣模塊(joint upsampling module)來替代耗時又耗內存的擴張卷積,即 Joint Pyramid Upsampling(JPU)。
7.11、KPU
Knowledge Processing Unit,知識處理器。嘉楠耘智(canaan)號稱 2017 年將發布自己的 AI 芯片 KPU。嘉楠耘智要在 KPU 單一芯片中集成人工神經網絡和高性能處理器,主要提供異構、實時、離線的人工智能應用服務。這又是一家向 AI 領域擴張的不差錢的礦機公司。作為一家做礦機芯片(自稱是區塊鏈專用芯片)和礦機的公司,嘉楠耘智累計獲得近 3 億元融資,估值近 33 億人民幣。據說嘉楠耘智近期將啟動股改并推進 IPO。
另:Knowledge Processing Unit 這個詞并不是嘉楠耘智第一個提出來的,早在 10 年前就已經有論文和書籍講到這個詞匯了。只是,現在嘉楠耘智將 KPU 申請了注冊商標。
7.12、LPU
Line Protocol Unit -- 線路協議部件 Line Processing Unit -- 線路處理單元
7.13、MPU/MCU
Microprocessor/Micro controller Unit, 微處理器/微控制器,一般用于低計算應用的RISC計算機體系架構產品,如ARM-M系列處理器。
7.14、NPU
Neural Network Processing Unit,神經網絡處理器,是基于神經網絡算法與加速的新型處理器總稱,如中科院計算所/寒武紀公司出品的diannao系列。
7.15、OPU
Optical-Flow Processing Unit。光流處理器。
7.16、PPU
Physical Processing Unit。物理處理器。物理計算,就是模擬一個物體在真實世界中應該符合的物理定律。具體的說,可以使虛擬世界中的物體運動符合真實世界的物理定律,可以使游戲中的物體行為更加真實,例如布料模擬、毛發模擬、碰撞偵測、流體力學模擬等。開發物理計算引擎的公司有那么幾家,使用 CPU 來完成物理計算,支持多種平臺。但是,Ageia 應該是唯一一個使用專用芯片來加速物理計算的公司。Ageia 于 2006 年發布了 PPU 芯片 PhysX,還發布了基于 PPU 的物理加速卡,同時提供 SDK 給游戲開發者。2008 年被 NVIDIA 收購后,PhysX 加速卡產品被逐漸取消,現在物理計算的加速功能由 NVIDIA 的 GPU 實現,PhysX SDK 被 NVIDIA 重新打造。
7.17、QPU
Quantum Processing Unit。量子處理器。量子計算機也是近幾年比較火的研究方向。作者承認在這方面所知甚少。可以關注這家成立于 1999 年的公司 D-Wave System。DWave 大概每兩年可以將其 QPU 上的量子位個數翻倍一次。
7.18、RPU
Resistive Processing Unit。阻抗處理單元 RPU。這是 IBM Watson Research Center 的研究人員提出的概念,真的是個處理單元,而不是處理器。RPU 可以同時實現存儲和計算。利用 RPU 陣列,IBM 研究人員可以實現 80TOPS/s/W 的性能。 Ray-tracing Processing Unit。光線追蹤處理器。Ray tracing 是計算機圖形學中的一種渲染算法,RPU 是為加速其中的數據計算而開發的加速器。現在這些計算都是 GPU 的事情了。 Radio Processing Unit, 無線電處理器, Imagination Technologies 公司推出的集合集Wifi/藍牙/FM/處理器為單片的處理器。
7.19、SPU
Streaming Processing Unit。流處理器。流處理器的概念比較早了,是用于處理視頻數據流的單元,一開始出現在顯卡芯片的結構里。可以說,GPU 就是一種流處理器。甚至,還曾經存在過一家名字為“Streaming Processor Inc”的公司,2004 年創立,2009 年,隨著創始人兼董事長被挖去 NVIDIA 當首席科學家,SPI 關閉。
Speech-Recognition Processing Unit。語音識別處理器,SPU 或 SRPU。這個縮寫還沒有公司拿來使用。和語音識別相關的芯片如下。 Smart Processing Unit。敏捷處理器??這個不確定。 Space Processing Unit。空間處理器。
7.20、TPU
Tensor Processing Unit 張量處理器, Google 公司推出的加速人工智能算法的專用處理器。目前一代TPU面向Inference,二代面向訓練。
7.21、UPU
Universe Processing Unit。宇宙處理器。和 Space Processing Unit 相比,你更喜歡哪個?
7.22、VPU
Vector Processing Unit 矢量處理器,Intel收購的Movidius公司推出的圖像處理與人工智能的專用芯片的加速計算核心。
Vision Processing Unit。視覺處理器 VPU 也有希望成為通用名詞。
7.23、WPU
Wearable Processing Unit, 可穿戴處理器,一家印度公司Ineda Systems公司推出的可穿戴片上系統產品,包含GPU/MIPS CPU等IP。
Wisdom Processing Unit。智慧處理器。這個 WPU 聽起來比較高大上,拿去用,不謝。不過,有點“腦白金”的味道。
7.24、XPU
百度與Xilinx公司在2017年Hotchips大會上發布的FPGA智能云加速,含256核。
百度公開了其 FPGA Accelerator 的名字,就叫 XPU。
7.25、YPU
unsign 。
7.26、ZPU
Zylin Processing Unit, 由挪威Zylin 公司推出的一款32位開源處理器。
挪威公司 Zylin 的 CPU 的名字。為了在資源有限的 FPGA 上能擁有一個靈活的微處理器,Zylin 開發了 ZPU。ZPU 是一種 stack machine(堆棧結構機器),指令沒有操作數,代碼量很小,并有 GCC 工具鏈支持,被稱為“The worlds smallest 32 bit CPU with GCC toolchain”。Zylin 在 2008 年將 ZPU 在 opencores 上開源。有組織還將 Arduino 的開發環境進行了修改給 ZPU 用。
編輯:黃飛
?






















 工商網監
工商網監
評論