 電子發(fā)燒友App
電子發(fā)燒友App


導(dǎo)讀
AI大模型的熱潮不斷,預(yù)計(jì)未來十年,AGI時(shí)代即將到來。但目前支撐AI發(fā)展的GPU和AI專用芯片,都存在各種各樣的問題。 那么,在分析這些問題的基礎(chǔ)上,我們能不能針對(duì)這些問題進(jìn)行優(yōu)化,重新定義一款能夠支持未來十年AGI大模型的、足夠靈活通用的、效率極高性能數(shù)量級(jí)提升的、單位算力成本非常低廉的、新的AI處理器類型?
01.?首先分析場(chǎng)景特點(diǎn),做好軟硬件劃分
1.1 一方面,AI處理器存在問題
差不多是從2015年前后,開始興起了專用AI芯片的浪潮。以谷歌TPU為典型代表的各種架構(gòu)的AI專用芯片,如雨后春筍般涌現(xiàn)。 但從AI落地情況來看,效果并不是很理想。這里的主要問題在于:
AI芯片專用設(shè)計(jì),把許多業(yè)務(wù)邏輯沉到硬件里,跟業(yè)務(wù)緊密耦合;但業(yè)務(wù)變化太快,算法不斷更新,芯片和業(yè)務(wù)的匹配度很低。
AI算法是專用的,面向具體場(chǎng)景,比如人臉識(shí)別、車牌識(shí)別,各種物品識(shí)別等。綜合來看,算法有上千種,加上算法自身仍在快速演進(jìn),加上各種變種的算法甚至超過數(shù)萬種。
用戶的業(yè)務(wù)場(chǎng)景是綜合性的,把業(yè)務(wù)場(chǎng)景比做一桌宴席,AI芯片就是主打的那道主菜。對(duì)AI芯片公司來說,自己只擅長(zhǎng)做這一道菜,并不擅長(zhǎng)做其他的菜品,更不擅長(zhǎng)幫助用戶搭配一桌美味可口、葷素均衡、營(yíng)養(yǎng)均衡的宴席。? ?
1.2 另一方面,GPU也存在問題
NVIDIA的GPU是通用并行處理器:
性能效率相對(duì)不高,性能逐漸見頂。要想算力提升,只能通過提升集群規(guī)模(Scale Out,增加GPU數(shù)量)的方式。
增加集群規(guī)模,受限于I/O的帶寬和延遲。一方面,集群的網(wǎng)絡(luò)連接數(shù)量為O(n^2),連接數(shù)量隨著集群規(guī)模的指數(shù)級(jí)增加;另一方面,AI類的計(jì)算任務(wù),不同節(jié)點(diǎn)間的數(shù)據(jù)交互本身就非常巨大。因此,受阿姆達(dá)爾定律影響,I/O的帶寬和延遲,會(huì)約束集群規(guī)模的大小。(在保證集群交互效率的情況下,)目前能支持的集群規(guī)模大約在1500臺(tái)左右。
還有另外一個(gè)強(qiáng)約束,就是成本。據(jù)稱GPT5需要5萬張GPU卡,單卡的成本在5W美金左右,再加上其他硬件和基礎(chǔ)設(shè)施已經(jīng)運(yùn)營(yíng)的成本。僅硬件開銷接近50億美金,即350億RMB。這對(duì)很多廠家來說,是天文數(shù)字。
1.3 問題的核心:芯片的靈活性要匹配場(chǎng)景的靈活性
首先,仍然是從我們之前很多文章中提到的這個(gè)“從軟件到硬件的典型處理器劃分圖”開始分析。? ?
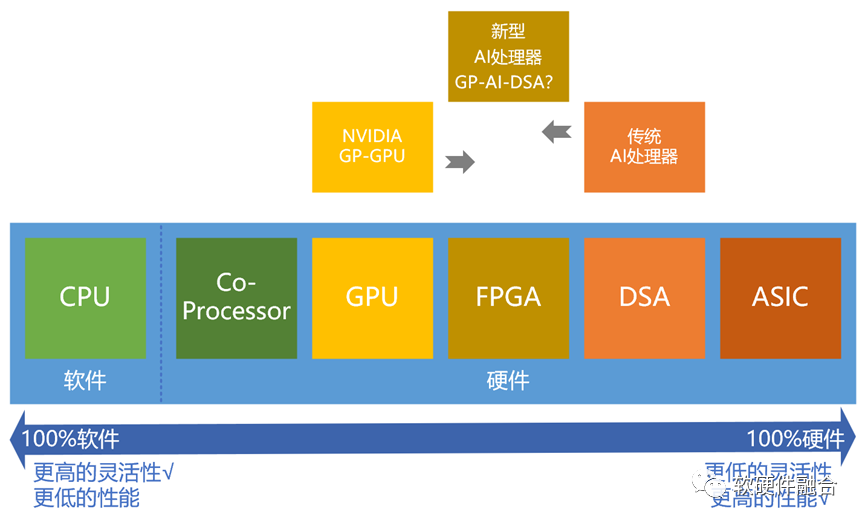
指令是處理器軟件和硬件的媒介:有的指令非常簡(jiǎn)單,就是基本的加減乘除等標(biāo)量計(jì)算;有的指令非常復(fù)雜,不是純粹的向量、矩陣或多維張量計(jì)算,而是各種維度計(jì)算再組合的一個(gè)混合的宏指令,或者說是一個(gè)算子甚至算法,就對(duì)應(yīng)到一條(單位計(jì)算)指令。 AI專用處理器是一種DSA,是在ASIC基礎(chǔ)上具有一定的可編程能力。性能效率足夠好,但不夠靈活,不太適合業(yè)務(wù)邏輯和算法快速變化的AI場(chǎng)景。而GPU足夠靈活,但性能效率不夠,并且性能逐漸達(dá)到上限。 從目前大模型宏觀發(fā)展趨勢(shì)來看:
Transformer會(huì)是核心算法,在大模型上已經(jīng)顯露威力。未來模型的底層算法/算子會(huì)逐漸統(tǒng)一于Transformer或某個(gè)類Transformer的算法。從此趨勢(shì)分析可得:AI場(chǎng)景的業(yè)務(wù)邏輯和算法在逐漸收斂,其靈活性在逐漸降低。
此外,AI計(jì)算框架也走過了百家爭(zhēng)鳴的階段,目前可以看到的趨勢(shì)是,PyTorch占據(jù)了絕大部分份額。這說明整個(gè)生態(tài)也在逐漸收斂,整個(gè)系統(tǒng)的迭代也在放慢。? ?
這兩個(gè)趨勢(shì)都說明了,未來,“專用”的AI芯片會(huì)逐漸地綻放光芒。當(dāng)然了,作為AI芯片的公司,不能等,而是需要相向而行:
需要定義一款,其性能/靈活性特征介于GPU和目前傳統(tǒng)AI-DSA處理器之間的,新型的通用AI處理器。“比GPU更高效,比AI芯片更通用”。
通用性體現(xiàn)在兩個(gè)方面:
一方面,處理器的通用性。能夠適配更多的算法差異性和算法迭代,覆蓋更多場(chǎng)景和更長(zhǎng)的生命周期。
另一方面,面向AGI通用人工智能。不再是專用AI的“場(chǎng)景千千萬,處理器千千萬”,架構(gòu)和生態(tài)完全碎片;而是一個(gè)通用的強(qiáng)人工智能算法,一個(gè)通用的強(qiáng)處理器平臺(tái),去強(qiáng)智能化的適配各種場(chǎng)景。
02.?大核少核 or 小核眾核?
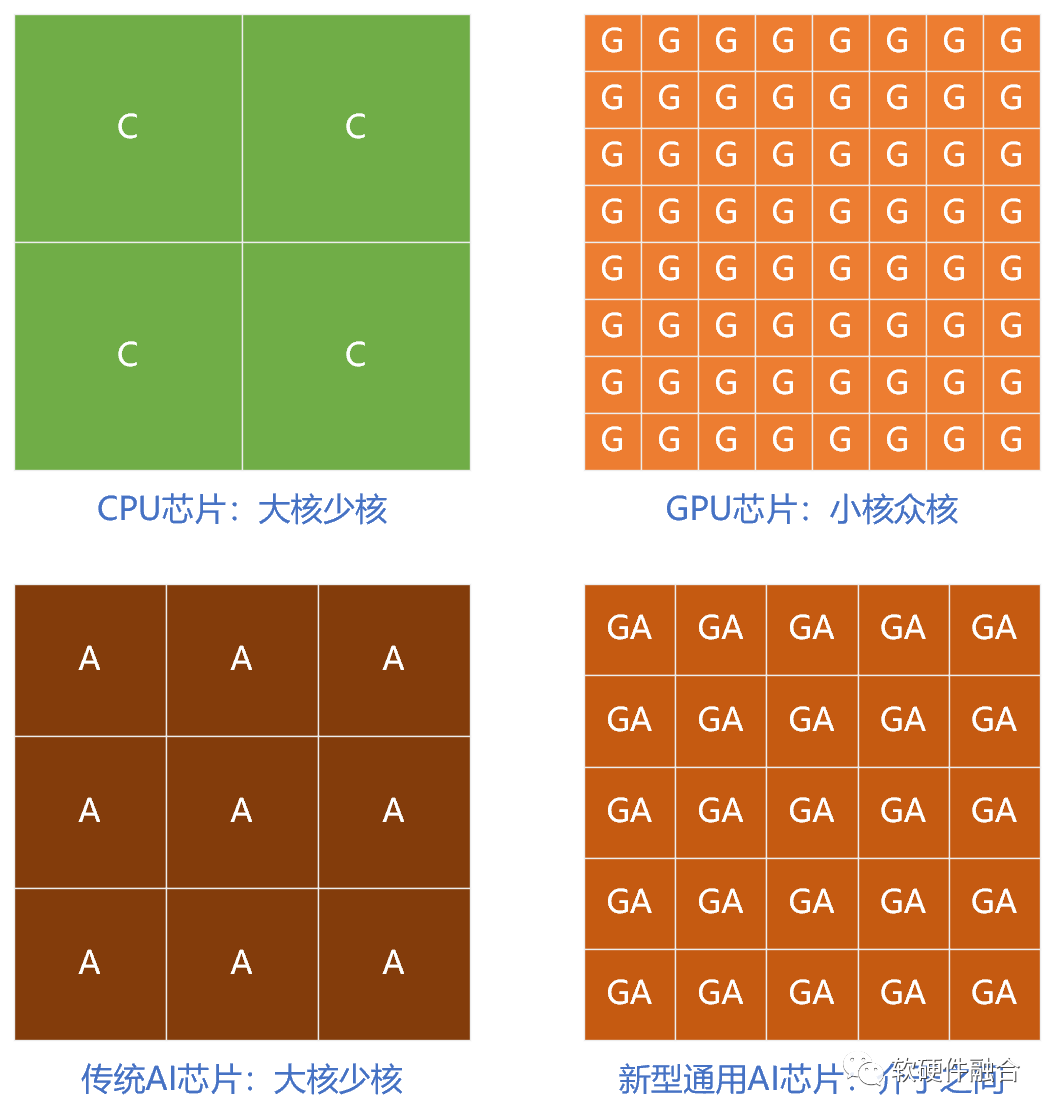
CPU是大核,但通常一個(gè)芯片里只有不到100個(gè)物理核心;而GPU是小核眾核的實(shí)現(xiàn),目前通常在上萬個(gè)核左右;而傳統(tǒng)AI芯片,通常是大的定制核+相對(duì)少量核(100核以內(nèi))的并行。? ?
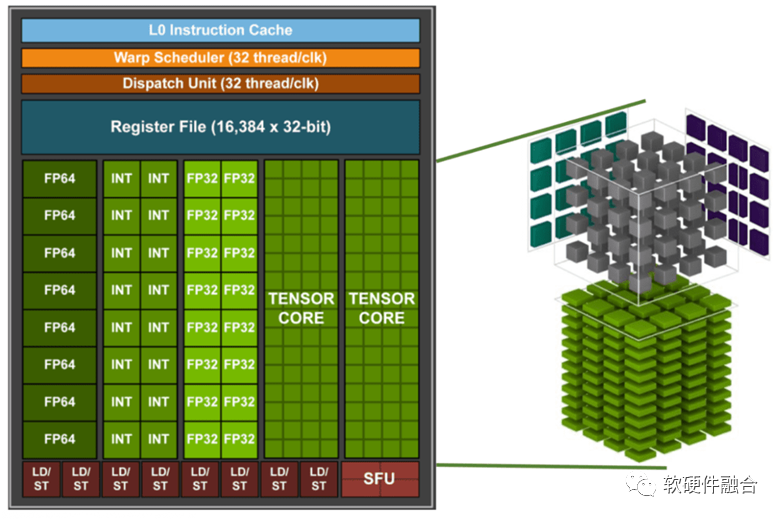
此外,一個(gè)很重要的現(xiàn)象是,GPU核,不再是之前只有CUDA核的標(biāo)量處理器,而是增加了很多Tensor核的類協(xié)處理器的部分。新的GPU處理器不再在處理器核的數(shù)量上增加,反而把寶貴的晶體管資源用在單個(gè)核的協(xié)處理器上,把單核的能力做更多的強(qiáng)化。 因此,新型通用AI芯片需要:
在目前工藝情況下,并行的單芯片處理器核心(GA,通用AI處理器核心)數(shù)量在500-1000之間比較合適;
單個(gè)GA采用通用高效能CPU核(例如定制的RISC-v CPU)+強(qiáng)大的Tensor協(xié)處理器的方式。? ?
03.?極致擴(kuò)展性,多層次強(qiáng)化內(nèi)聯(lián)交互
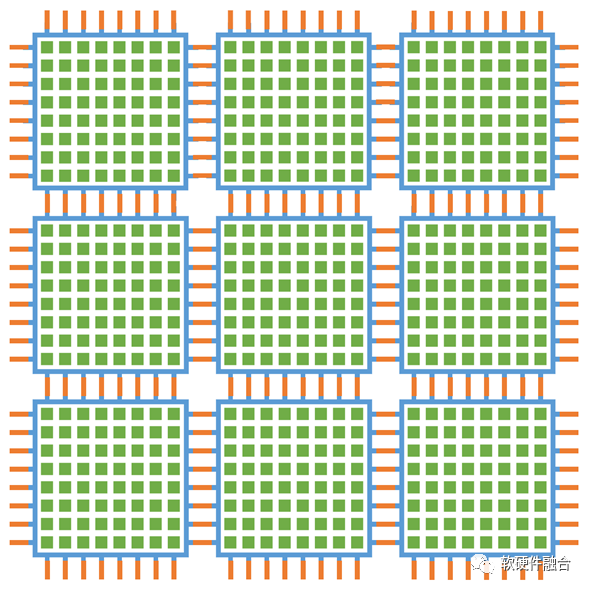
要想實(shí)現(xiàn)極致擴(kuò)展性,通常需要多個(gè)層次的資源切分和整合:
首先,單核心內(nèi)部。可以支持資源的虛擬切分和整合(類似CPU的分時(shí)共享和虛擬化vCPU)實(shí)現(xiàn)從1-m個(gè)vGA核的自由擴(kuò)展。
其次,單芯片內(nèi)部。可以從1-n個(gè)核的擴(kuò)展資源切分和整合,也就是說vGA可以實(shí)現(xiàn)1-m*n個(gè)資源的擴(kuò)展。
最后,眾多芯片構(gòu)成的計(jì)算集群。多個(gè)芯片可以組成一臺(tái)服務(wù)器、多個(gè)服務(wù)器組成一個(gè)機(jī)柜、多個(gè)機(jī)柜組成一個(gè)POD集群。可以通過集群互聯(lián)實(shí)現(xiàn)1-k個(gè)芯片的擴(kuò)展,也就是說,vGA實(shí)現(xiàn)1-m*n*k個(gè)資源的極致擴(kuò)展。
此外,每個(gè)層次的數(shù)據(jù)交互都要求極高,內(nèi)部需要非常強(qiáng)勁的NOC總線,外部需要帶寬數(shù)量級(jí)提升的高性能網(wǎng)絡(luò)的支持。? ?
04.?AI芯片案例
4.1 Tenstorrent的案例
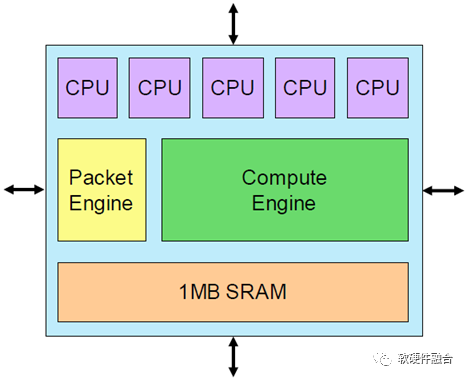
Tenstorrent的AI核稱為Tensix,第一代Tensix每個(gè)核有五個(gè)標(biāo)量RISC CPU,單個(gè)計(jì)算引擎的性能為3 TOPS。
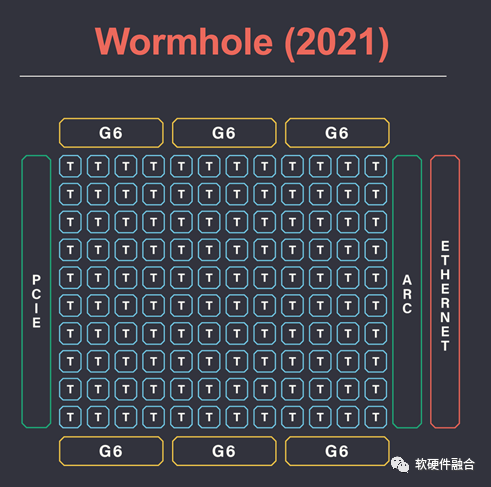
整個(gè)芯片代號(hào)為Wormhole,有80個(gè)Tensix核心,并且集成了ARC架構(gòu)的Host CPU。此外,Wormhole支持16個(gè)100Gbps的Ethernet網(wǎng)絡(luò)接口。? ?
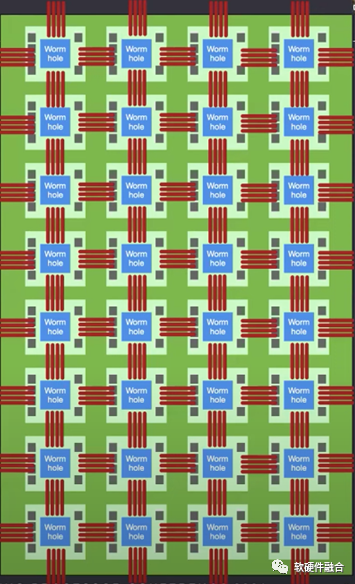
采用Wormhole芯片,Tenstorrent設(shè)計(jì)了nebula(星云)服務(wù)器,一個(gè)4U服務(wù)器包含32個(gè)Wormhole芯片。
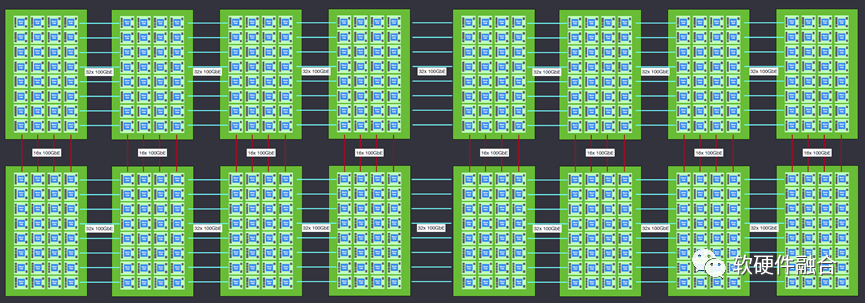
一個(gè)機(jī)柜包含8臺(tái)nebula服務(wù)器,上圖為兩個(gè)機(jī)柜互聯(lián)的架構(gòu)示意圖。 當(dāng)然,Scale out橫向擴(kuò)展功能并不止于此,Wormhole在機(jī)架級(jí)連接方面是非常靈活的。理論上可以達(dá)到幾乎無限的擴(kuò)展連接能力。
4.2 Tenstorrent Roadmap
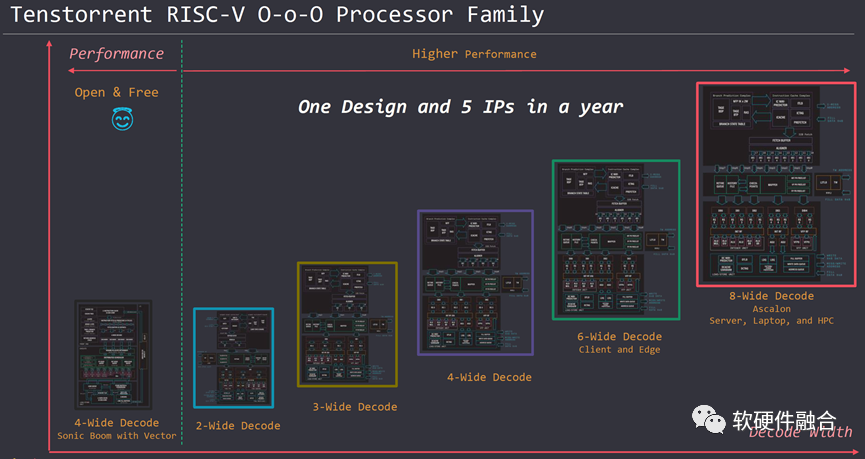
Tenstorrent推出了自研的RISCv處理器 IP,從用于AI-DSA的小CPU核,用于IoT的MCU級(jí)別的CPU核心,到筆記本電腦、邊緣和服務(wù)器以及HPC場(chǎng)景的高性能CPU核。

目前,Tenstorrent的AI芯片,已經(jīng)量產(chǎn)的有Grayskull和Wormhole,BlackHole在公司內(nèi)部調(diào)試中。
2024年將推出基于Chiplet的AI芯片,集成了自研的RISC-v CPU和AI處理器。
4.3?Tenstorrent Wormhole的不足
從軟硬件融合的理念和理論出發(fā),對(duì)Tenstorrent Wormhole進(jìn)行分析,仍有不少待優(yōu)化的地方:
單個(gè)Tensix核心的能力仍有待優(yōu)化。單核心內(nèi)部小的用于控制的CPU核,其工作仍需要進(jìn)一步優(yōu)化,哪些可以硬件卸載加速,哪些還需要在協(xié)處理器增強(qiáng)。此外,內(nèi)部的各種緩存設(shè)計(jì)仍需要進(jìn)一步優(yōu)化。
核數(shù)太少。通過優(yōu)化單核的資源消耗,以及通過更先進(jìn)工藝和Chiplet封裝等方式把核數(shù)再增加4/8倍,比較符合未來2-3年大模型現(xiàn)狀(從最新的Roadmap看,已經(jīng)在規(guī)劃中了)。
核間通信需要進(jìn)一步優(yōu)化。很多核間通信需要CPU參與,一方面集成CPU更高效(已經(jīng)在規(guī)劃中了),另一方面,進(jìn)一步把相關(guān)任務(wù)從CPU卸載到硬件加速。
片間通信優(yōu)化。支撐極致擴(kuò)展性的網(wǎng)絡(luò)端口,對(duì)高性能網(wǎng)絡(luò)技術(shù)的要求非常之高,需要進(jìn)一步加強(qiáng)。
軟硬件耦合設(shè)計(jì)。軟件和硬件必須解耦,而不是緊耦合。只有充分的解耦,才能各自“放飛自我”,實(shí)現(xiàn)更多的創(chuàng)新能力增強(qiáng)。
軟件定義。做AI大模型的客戶,通常都是大客戶。大客戶的業(yè)務(wù)系統(tǒng)是已經(jīng)存在的,客戶需要的僅僅是性能提升和成本下降。客戶并不想大范圍修改業(yè)務(wù)邏輯,更不想有平臺(tái)依賴。需要解決這個(gè)問題。
編輯:黃飛
?









 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論