 電子發(fā)燒友App
電子發(fā)燒友App


隨著越來越多不同類型的處理元件包含在同一架構(gòu)中,對處理器進行編程變得越來越復雜。
雖然系統(tǒng)架構(gòu)師可能會陶醉于可用于提高功率、性能和面積的選項數(shù)量,但編程功能并使其協(xié)同工作的挑戰(zhàn)將成為一項重大挑戰(zhàn)。它涉及來自不同IP提供商的多種編程工具、模型和方法。
“在任何一種邊緣推理產(chǎn)品中,無論是Nest相機、汽車應用中的相機,還是筆記本電腦,基本上都有三種類型的功能軟件,主要來自三種不同類型的開發(fā)人員——數(shù)據(jù)科學家、嵌入式CPU開發(fā)人員和DSP開發(fā)人員,”的首席營銷官史蒂夫·羅迪說二次曲面。
根據(jù)他們在開發(fā)過程中所處的位置,他們的方法可能看起來非常不同。“數(shù)據(jù)科學家花時間在Python、框架培訓和數(shù)學抽象層面上做事情,”羅迪說。“PyTorch是非常高級的、抽象的、解釋的,不太關(guān)心實現(xiàn)的效率,因為他們關(guān)心的只是數(shù)學中的增益函數(shù)和模型的準確性等。從那里出來的是PyTorch模型,ONNX代碼,以及嵌入PyTorch模型的Python代碼。嵌入式開發(fā)者是完全不同的性格類型。他們使用更傳統(tǒng)的工具集,這些工具集可能是CPU供應商的工具,或者Arm工具包,或者像Microsoft Visual Studio for C/C++開發(fā)這樣的通用工具。無論是哪種CPU,您都將獲得該特定芯片的供應商版本的開發(fā)工作室,它將帶有預構(gòu)建的東西,如RTOS代碼和驅(qū)動程序代碼。如果你從某個特定的供應商那里購買芯片級的解決方案,它會有DDR和PCI接口的驅(qū)動程序,等等。“
例如,考慮iPhone的應用程序編程,它是高度抽象的。“iPhone開發(fā)者有一個開發(fā)工具包,上面有很多其他軟件,”他說。“但在很大程度上,這是一個嵌入式的東西。有人在編寫C代碼,有人在開發(fā)操作系統(tǒng),不管是澤法還是微軟的操作系統(tǒng),或者類似的東西。他們生產(chǎn)什么?他們產(chǎn)生C代碼,有時是匯編代碼,這取決于編譯器的質(zhì)量。DSP開發(fā)人員也是算法開發(fā)人員,通常面向數(shù)學家,使用MATLAB或Visual Studio等工具。這里創(chuàng)建了三個級別的代碼。類似Python的數(shù)據(jù)科學代碼,DSP,C++,還有嵌入式代碼。”
從一個Android開發(fā)者的角度來看,Ronan Naughton是手臂說:“一個典型的軟件工程師可能正在開發(fā)一個移動應用程序,用于部署到多個平臺。在這種情況下,他們將尋求最低的維護開銷、無縫的可移植性和高性能,這些都可以通過無處不在的Arm CPU和支持工具鏈來提供。”
在Android環(huán)境中,針對CPU的編程提供了盡可能多的工具選擇。
“例如,”諾頓指出,“一個好的矢量化編譯器,如LLVM或GCC,可以針對多個CPU和操作系統(tǒng)目標。有一個豐富的面向特定功能任務的函數(shù)庫生態(tài)系統(tǒng),例如面向ML的Arm計算庫。或者,開發(fā)人員可以使用Arm C語言擴展等內(nèi)部函數(shù)來針對指令集架構(gòu)本身。”
在所有這些之下是一個傳統(tǒng)的架構(gòu),由一個NPU、DSP和CPU組成,需要所有的步驟才能到達目標主機CPU。所有或大部分都使用某種形式的運行時應用程序。
“如果你正在運行你的機器學習代碼,CPU會積極參與每一次推理,每一次迭代,每一次通過機器學習圖編排整個事情,”羅迪指出。
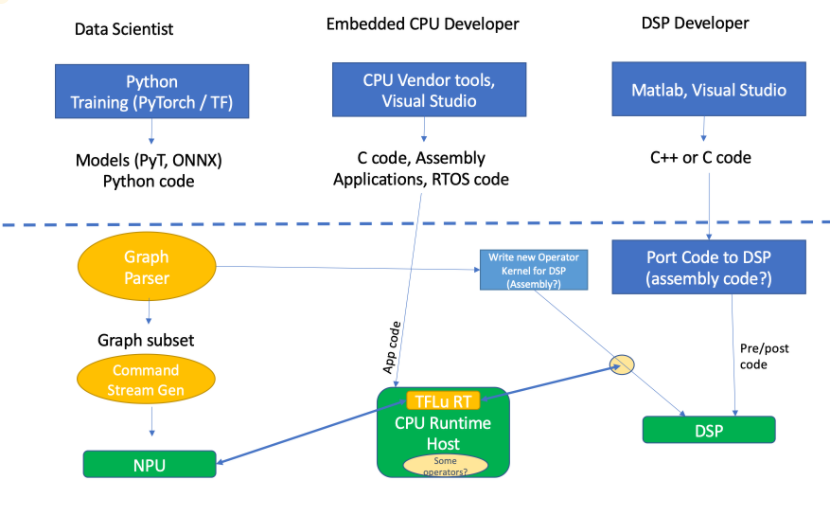
圖1:傳統(tǒng)NPU+DSP+CPU的工具/代碼流程。來源:Quadric.io
DSP、CPU和npu的編程方式因應用、用例、系統(tǒng)架構(gòu)和環(huán)境而異。這將決定如何優(yōu)化代碼,以實現(xiàn)特定應用程序或使用模型的最佳性能。
“在CPU上,大多數(shù)編譯器可以非常好地優(yōu)化代碼,但當編程DSP或npu時,特別是并行化代碼時,大量工作必須由軟件工程師完成,因為所有編譯器都失敗了,”Andy Heinig說,他是弗勞恩霍夫協(xié)會適應性系統(tǒng)工程分部。這意味著硬件上的并行工作越多,軟件工程師手動完成的工作就越多。而且大部分工作都是低級編程需要的。”
雖然有一些重疊,但這些不同的處理元素之間也有一些基本差異。“CPU是一種通用架構(gòu),因此支持廣泛的用途、操作系統(tǒng)、開發(fā)工具、庫和許多編程語言,從傳統(tǒng)的低級C到高級C++、Python、Web應用程序和Java,”的產(chǎn)品經(jīng)理蓋伊·本哈姆說新思科技。“DSP應用通常運行在優(yōu)化的實時系統(tǒng)上,因此對DSP處理器進行編程需要使用低級語言(如匯編語言、C語言)、DSP庫和特定的編譯器/分析器,以實現(xiàn)數(shù)據(jù)并行、性能調(diào)整和代碼大小優(yōu)化。與通用CPU不同,但與DSP類似,NPU架構(gòu)也致力于加速特定任務,在這種情況下是為了加速AI/ML應用。”
DSP架構(gòu)可以并行處理來自多個傳感器的數(shù)據(jù)。傳統(tǒng)的CPU或DSP編程依賴于一個程序或一套規(guī)則的算法來處理數(shù)據(jù),而人工智能則從數(shù)據(jù)中學習,并隨著時間的推移提高其性能。
“人工智能使用PyTorch和TensorFlow等高級框架來創(chuàng)建、訓練和部署模型,”本哈姆解釋道。“神經(jīng)網(wǎng)絡模型的靈感來自人腦中神經(jīng)元的結(jié)構(gòu),由一個系統(tǒng)的數(shù)學表示組成,該系統(tǒng)可以根據(jù)輸入數(shù)據(jù)進行預測或決策。”
還有其他不同之處。Tensilica Vision和AI DSPs的產(chǎn)品營銷和管理小組主任Pulin Desai說,除了用C和C++等高級語言編程之外節(jié)奏,“DSP和CPU還利用各種庫,如math lib、fp lib。DSP也有一個特定的庫,用于特定的垂直領域,以執(zhí)行特殊用途的應用。DSP和CPU還可以與OpenCL和Halide等高級語言一起工作,客戶可以使用這些語言來開發(fā)他們的應用。”
NPU編程是在完全不同的環(huán)境中使用AI訓練框架完成的。反過來,它們在TensorFlow和PyTorch中生成神經(jīng)網(wǎng)絡代碼,并使用神經(jīng)網(wǎng)絡編譯器為特定硬件進一步編譯網(wǎng)絡。”
“神經(jīng)網(wǎng)絡不是‘程序化的’“他們受過訓練,”新思科技的產(chǎn)品經(jīng)理戈爾登·庫勃說DSP和CPU以更傳統(tǒng)的方式編程。代碼是用C/C++寫的。然后,您需要一個IDE和調(diào)試器來測試和編輯代碼。“
編程模型如何工作
所以對于CPU和DSP,設計師會用C或C++編程,但可能會調(diào)用特定的lib api。“例如,對于vision,代碼可能會調(diào)用OpenCV API調(diào)用,”Desai說。
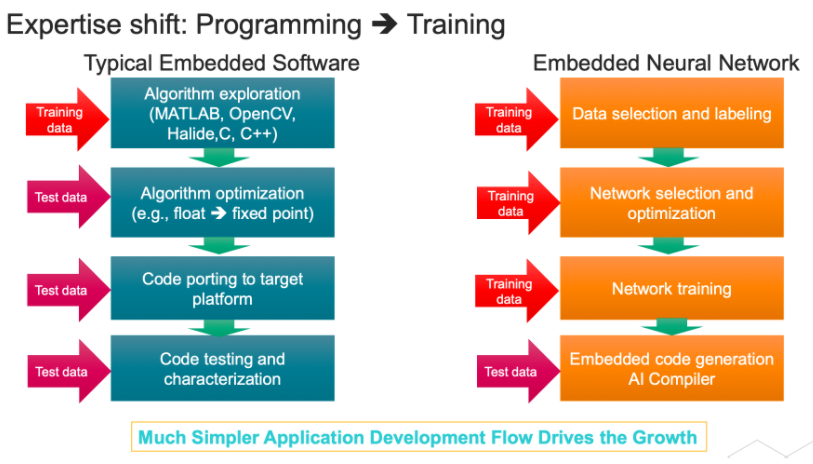
圖2:DSP/CPU與npu上嵌入式軟件開發(fā)的比較。來源:Cadence
Fraunhofer的Heinig說,大多數(shù)時候,優(yōu)化代碼的工作是手工完成的。“當涉及到并行使用硬件時,高級編程模型通常會失敗。但是,當然,使用具有基本高度優(yōu)化功能的庫是可能的。”
開發(fā)一個人工智能模型是非常不同的。需要幾個步驟。“首先是識別和準備,”新思科技的本哈姆說。“在確定適合由人工智能解決的問題后,選擇正確的模型并收集將在該過程中使用的數(shù)據(jù)非常重要。其次是模特培訓。訓練模型意味著使用大量的訓練數(shù)據(jù)來優(yōu)化模型,提高性能并確保準確性。第三是推理。人工智能模型部署在生產(chǎn)環(huán)境中,用于根據(jù)可用數(shù)據(jù)快速做出結(jié)論、預測和推斷。”
還有其他不同之處。大多數(shù)DSP都是矢量處理器,其架構(gòu)針對高效并行處理數(shù)據(jù)陣列進行了調(diào)整。“為了有效地使用硬件,數(shù)據(jù)需要矢量化,”新思科技高級產(chǎn)品經(jīng)理Markus Willems說。“當從標量代碼開始時,優(yōu)化編譯器可以應用某種程度的自動向量化。然而,對于絕大多數(shù)用例來說,獲得最佳結(jié)果需要程序員使用專用的矢量數(shù)據(jù)類型,以矢量化的方式編寫代碼。”
Willems建議,為了充分利用指令集的全部功能,通常使用內(nèi)部函數(shù)。與普通的匯編編碼不同,內(nèi)建函數(shù)將寄存器分配留給編譯器,這允許代碼重用和移植
此外,對于大多數(shù)DSP算法,設計從MATLAB開始分析功能性能(即檢查算法是否解決了問題)。對于越來越多的DSP,有一種直接的方法可以將MATLAB算法映射到矢量化DSP代碼,即使用MATLAB嵌入式編碼器和處理器專用DSP庫。
但為了充分利用處理器,海尼格說,有必要共同優(yōu)化硬件和軟件。否則,你的解決方案將會失敗,因為你意識到設計的硬件并不完全符合問題規(guī)范時已經(jīng)太晚了。如果要并行執(zhí)行越來越多的操作,尤其如此。”
對于一個SoC架構(gòu)師來說,它從什么是目標市場和目標應用開始,因為這將驅(qū)動硬件和軟件架構(gòu)。
“在可編程性和固定硬件之間做出選擇總是一個挑戰(zhàn),”Desai解釋道。“決策是由成本(SoC面積)、功耗、性能、上市時間和未來需求驅(qū)動的。如果您了解您的目標應用,并希望優(yōu)化功耗和面積,固定硬件是最佳選擇。一個例子是H.264解碼器。]神經(jīng)網(wǎng)絡是不斷變化的,因此可編程性是必須的,但一種架構(gòu),其中一些功能在固定功能(硬件加速器,如NPU)中,一些在可編程CPU或DSP中,是人工智能的最佳選擇。”
劃分處理
所有這些都變得更加復雜,因為不同的設計者/程序員可能負責不同的代碼。
“我們在談論推理應用,但我們也在談論一個系統(tǒng)公司制造一個系統(tǒng),”德賽說。“由于SoC是通用的,可能會有人工智能開發(fā)人員開發(fā)特定的神經(jīng)網(wǎng)絡來解決特定的問題,例如,為麥克風降低噪聲的降噪網(wǎng)絡,為安全攝像頭提供人員檢測網(wǎng)絡等。這個網(wǎng)絡需要轉(zhuǎn)換為可以在SoC上運行的代碼,因此您將擁有知道如何使用工具將神經(jīng)網(wǎng)絡轉(zhuǎn)換為可以在具有CPU/DSP/NPU的SoC上啟動的代碼的程序員。但是,如果是實時應用程序,您還需要知道如何使用實時操作系統(tǒng)、處理器級系統(tǒng)軟件等的系統(tǒng)軟件工程師。此外,如果這是消費類設備,可能會有高級軟件開發(fā)人員開發(fā)GUI或用戶界面。”
對于NPU,有幾個注意事項。“首先,NPU必須設計為加速人工智能工作負載,”本哈姆說。“人工智能/神經(jīng)網(wǎng)絡工作負載由深度學習算法組成,這些算法在許多層中需要大量的數(shù)學和多重矩陣乘法,因此需要并行架構(gòu)。”
他解釋說,一個好的NPU的關(guān)鍵特征之一是處理數(shù)據(jù)和快速完成操作的能力,性能以TOPS/MAC衡量。“功率/性能/面積(成本)之間的典型半導體權(quán)衡也與NPU設計密切相關(guān)。對于自動駕駛汽車的使用,NPU的延遲是至關(guān)重要的,特別是當決定何時踩下汽車剎車是生死攸關(guān)的事情時。這也與功能安全設計考慮有關(guān)。設計團隊還必須考慮NPU設計是否符合安全要求。”
程序員需要考慮的另一個關(guān)鍵問題是開發(fā)和編程工具。
“如果沒有合適的軟件開發(fā)工具,能夠輕松地從流行的人工智能框架中導入NN/AI模型,編譯,優(yōu)化它,并自動利用包括內(nèi)存設計考慮在內(nèi)的NPU架構(gòu),那么構(gòu)建一個偉大的NPU是不夠的,”他說。“提供一種檢查模型準確性的方法以及模擬工具也很重要,這樣程序員可以在硬件存在之前就開始軟件開發(fā)和驗證。這是上市時間的一個重要考慮因素。”
庫珀同意了。“npu比DSP更接近于定制加速器,尤其是GPU或CPU,它們完全靈活。您可能不會選擇添加NPU,除非您在相當長的時間內(nèi)強烈需要NN性能。我們的客戶只需要一點點人工智能,他們使用矢量DSP來實現(xiàn)DSP性能,并在需要時對其進行重新配置以處理人工智能,從而確保其芯片面積的最大靈活性。這很好,但不會像專用NPU那樣節(jié)能或節(jié)省面積。”
最后,當試圖確定圖的哪些子集適合NPU,哪些不適合時,編程挑戰(zhàn)就來了。[參見上面圖1的左側(cè)]
Quadric公司的羅迪說:“如果它不運行,它就必須在別的地方運行,所以代碼必須被拆分。”與此同時,還有一個存儲在內(nèi)存中的輔助命令流生成器或鏈表生成器,NPU知道足夠多的信息來獲取它的命令。雖然這一部分非常簡單,但是所有不在系統(tǒng)上運行的部分呢?那些運營商該往哪里跑?有沒有已經(jīng)存在的機器學習操作符的高效實現(xiàn)?如果是,它是在DSP上,還是在CPU上,如果它不存在?必須有人去創(chuàng)造一個新的版本。你在DSP上這樣做是因為你希望它具有高性能。現(xiàn)在你必須在DSP上編碼,很多DSP缺乏好的工具,尤其是那些專門為機器學習而構(gòu)建的工具。通用版本的DSP——音頻DSP或基本通用DSP——可能有兩個MAC或四個MAC類型的東西。為機器學習而構(gòu)建的DSP將是非常廣泛的DSP。超寬DSP可以成為非常廣泛的激活和標準化以及數(shù)據(jù)科學中發(fā)生的事情的良好目標,但它們是新的,因此可能沒有可靠的編譯器。”
結(jié)論
在過去,這些編程世界是獨立的學科。但隨著人工智能計算越來越多地包含在設備中,以及隨著系統(tǒng)變得越來越異構(gòu),軟件開發(fā)人員至少需要更多地了解其他領域正在發(fā)生的事情。
最終,這可能成為單一硬件/軟件架構(gòu)的驅(qū)動因素,允許工程團隊編寫和運行復雜的C++代碼,而不必在兩三種類型的處理器之間進行劃分。但是,如果要做到這一點,從現(xiàn)在到那時還有許多工作要做。鑒于人工智能和硬件架構(gòu)的發(fā)展速度,尚不完全清楚該架構(gòu)在準備就緒時是否仍然相關(guān)。
? ? ? 審核編輯:黃飛











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論