 電子發燒友App
電子發燒友App


本文的主要目的,是簡單介紹時下流行的深度學習算法的基礎知識,本人也看過許多其他教程,感覺其中大部分講的還是太過深奧,于是便有了寫一篇科普文的想法。博主也是現學現賣,文中如有不當之處,請各位指出,共同進步。
本文的目標讀者是對機器學習和神經網絡有一定了解的同學(包括:梯度下降、神經網絡、反向傳播算法等),機器學習的相關知識。
深度學習簡介
深度學習是指多層神經網絡上運用各種機器學習算法解決圖像,文本等各種問題的算法集合。深度學習從大類上可以歸入神經網絡,不過在具體實現上有許多變化。深度學習的核心是特征學習,旨在通過分層網絡獲取分層次的特征信息,從而解決以往需要人工設計特征的重要難題。深度學習是一個框架,包含多個重要算法:
Convolutional Neural Networks(CNN)卷積神經網絡
AutoEncoder自動編碼器
Sparse Coding稀疏編碼
Restricted Boltzmann Machine(RBM)限制波爾茲曼機
Deep Belief Networks(DBN)深信度網絡
Recurrent neural Network(RNN)多層反饋循環神經網絡神經網絡
對于不同問題(圖像,語音,文本),需要選用不同網絡模型才能達到更好效果。
此外,最近幾年增強學習(Reinforcement Learning)與深度學習的結合也創造了許多了不起的成果,AlphaGo就是其中之一。
人類視覺原理
深度學習的許多研究成果,離不開對大腦認知原理的研究,尤其是視覺原理的研究。
1981 年的諾貝爾醫學獎,頒發給了 David Hubel(出生于加拿大的美國神經生物學家) 和TorstenWiesel,以及 Roger Sperry。前兩位的主要貢獻,是“發現了視覺系統的信息處理”,可視皮層是分級的。
人類的視覺原理如下:從原始信號攝入開始(瞳孔攝入像素 Pixels),接著做初步處理(大腦皮層某些細胞發現邊緣和方向),然后抽象(大腦判定,眼前的物體的形狀,是圓形的),然后進一步抽象(大腦進一步判定該物體是只氣球)。下面是人腦進行人臉識別的一個示例:

對于不同的物體,人類視覺也是通過這樣逐層分級,來進行認知的:

我們可以看到,在最底層特征基本上是類似的,就是各種邊緣,越往上,越能提取出此類物體的一些特征(輪子、眼睛、軀干等),到最上層,不同的高級特征最終組合成相應的圖像,從而能夠讓人類準確的區分不同的物體。
那么我們可以很自然的想到:可以不可以模仿人類大腦的這個特點,構造多層的神經網絡,較低層的識別初級的圖像特征,若干底層特征組成更上一層特征,最終通過多個層級的組合,最終在頂層做出分類呢?答案是肯定的,這也是許多深度學習算法(包括CNN)的靈感來源。
卷積網絡介紹
卷積神經網絡是一種多層神經網絡,擅長處理圖像特別是大圖像的相關機器學習問題。
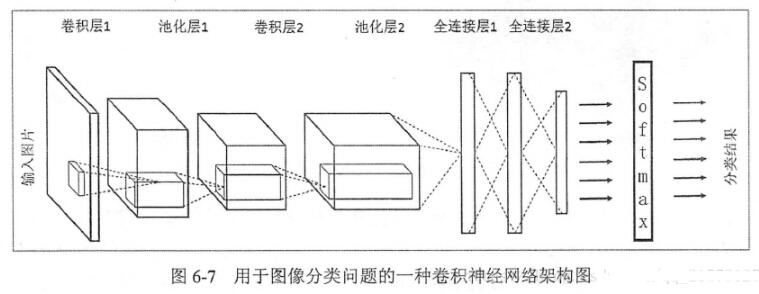
卷積網絡通過一系列方法,成功將數據量龐大的圖像識別問題不斷降維,最終使其能夠被訓練。CNN最早由Yann LeCun提出并應用在手寫字體識別上(MINST)。LeCun提出的網絡稱為LeNet,其網絡結構如下:

這是一個最典型的卷積網絡,由卷積層、池化層、全連接層組成。其中卷積層與池化層配合,組成多個卷積組,逐層提取特征,最終通過若干個全連接層完成分類。
卷積層完成的操作,可以認為是受局部感受野概念的啟發,而池化層,主要是為了降低數據維度。
綜合起來說,CNN通過卷積來模擬特征區分,并且通過卷積的權值共享及池化,來降低網絡參數的數量級,最后通過傳統神經網絡完成分類等任務。
降低參數量級
為什么要降低參數量級?從下面的例子就可以很容易理解了。
如果我們使用傳統神經網絡方式,對一張圖片進行分類,那么,我們把圖片的每個像素都連接到隱藏層節點上,那么對于一張1000x1000像素的圖片,如果我們有1M隱藏層單元,那么一共有10^12個參數,這顯然是不能接受的。(如下圖所示)

但是我們在CNN里,可以大大減少參數個數,我們基于以下兩個假設:
1)最底層特征都是局部性的,也就是說,我們用10x10這樣大小的過濾器就能表示邊緣等底層特征
2)圖像上不同小片段,以及不同圖像上的小片段的特征是類似的,也就是說,我們能用同樣的一組分類器來描述各種各樣不同的圖像
基于以上兩個,假設,我們就能把第一層網絡結構簡化如下:

我們用100個10x10的小過濾器,就能夠描述整幅圖片上的底層特征。
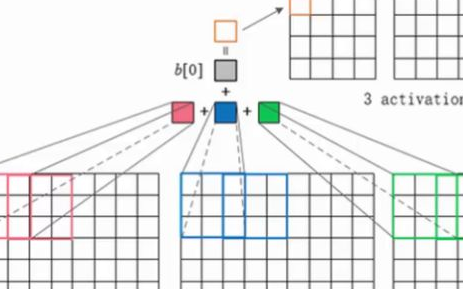
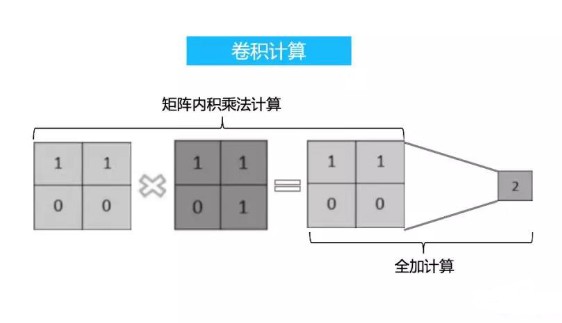
卷積(Convolution)
卷積運算的定義如下圖所示:

如圖所示,我們有一個5x5的圖像,我們用一個3x3的卷積核:
1 0 1
0 1 0
1 0 1
來對圖像進行卷積操作(可以理解為有一個滑動窗口,把卷積核與對應的圖像像素做乘積然后求和),得到了3x3的卷積結果。
這個過程我們可以理解為我們使用一個過濾器(卷積核)來過濾圖像的各個小區域,從而得到這些小區域的特征值。
在實際訓練過程中,卷積核的值是在學習過程中學到的。
在具體應用中,往往有多個卷積核,可以認為,每個卷積核代表了一種圖像模式,如果某個圖像塊與此卷積核卷積出的值大,則認為此圖像塊十分接近于此卷積核。如果我們設計了6個卷積核,可以理解:我們認為這個圖像上有6種底層紋理模式,也就是我們用6中基礎模式就能描繪出一副圖像。以下就是24種不同的卷積核的示例:
池化(Pooling)
池化聽起來很高深,其實簡單的說就是下采樣。池化的過程如下圖所示:

上圖中,我們可以看到,原始圖片是20x20的,我們對其進行下采樣,采樣窗口為10x10,最終將其下采樣成為一個2x2大小的特征圖。
之所以這么做的原因,是因為即使做完了卷積,圖像仍然很大(因為卷積核比較小),所以為了降低數據維度,就進行下采樣。
之所以能這么做,是因為即使減少了許多數據,特征的統計屬性仍能夠描述圖像,而且由于降低了數據維度,有效地避免了過擬合。
在實際應用中,池化根據下采樣的方法,分為最大值下采樣(Max-Pooling)與平均值下采樣(Mean-Pooling)。
LeNet介紹
下面再回到LeNet網絡結構:

這回我們就比較好理解了,原始圖像進來以后,先進入一個卷積層C1,由6個5x5的卷積核組成,卷積出28x28的圖像,然后下采樣到14x14(S2)。
接下來,再進一個卷積層C3,由16個5x5的卷積核組成,之后再下采樣到5x5(S4)。
注意,這里S2與C3的連接方式并不是全連接,而是部分連接,如下圖所示:

其中行代表S2層的某個節點,列代表C3層的某個節點。
我們可以看出,C3-0跟S2-0,1,2連接,C3-1跟S2-1,2,3連接,后面依次類推,仔細觀察可以發現,其實就是排列組合:
0 0 0 1 1 1
0 0 1 1 1 0
0 1 1 1 0 0
...
1 1 1 1 1 1
我們可以領悟作者的意圖,即用不同特征的底層組合,可以得到進一步的高級特征,例如:/ + = ^ (比較抽象O(∩_∩)O~),再比如好多個斜線段連成一個圓等等。
最后,通過全連接層C5、F6得到10個輸出,對應10個數字的概率。
最后說一點個人的想法哈,我認為第一個卷積層選6個卷積核是有原因的,大概也許可能是因為0~9其實能用以下6個邊緣來代表:
是不是有點道理呢,哈哈
然后C3層的數量選擇上面也說了,是從選3個開始的排列組合,所以也是可以理解的。
其實這些都是針對特定問題的trick,現在更加通用的網絡的結構都會復雜得多,至于這些網絡的參數如何選擇,那就需要我們好好學習了。
訓練過程
卷積神經網絡的訓練過程與傳統神經網絡類似,也是參照了反向傳播算法。
第一階段,向前傳播階段:
a)從樣本集中取一個樣本(X,Yp),將X輸入網絡;
b)計算相應的實際輸出Op。
在此階段,信息從輸入層經過逐級的變換,傳送到輸出層。這個過程也是網絡在完成訓練后正常運行時執行的過程。在此過程中,網絡執行的是計算(實際上就是輸入與每層的權值矩陣相點乘,得到最后的輸出結果):
第二階段,向后傳播階段
a)算實際輸出Op與相應的理想輸出Yp的差;
b)按極小化誤差的方法反向傳播調整權矩陣。
以上內容摘自其他博客,由于我也沒有仔細了解這一塊,建議直接參考原博客。
參考資料
Deep Learning(深度學習)學習筆記整理系列之(七)?
Deep Learning論文筆記之(四)CNN卷積神經網絡推導和實現
卷積神經網絡(一):LeNet5的基本結構
UFLDL Tutorial?
文章轉載自:Alex Cai













 工商網監
工商網監
評論