 電子發(fā)燒友App
電子發(fā)燒友App


愛爾蘭貝爾實(shí)驗(yàn)室的研究人員用高性能 FPGA 開發(fā)出一款用于通用 MIMO 無(wú)線通信系統(tǒng)的頻變預(yù)編碼內(nèi)核。
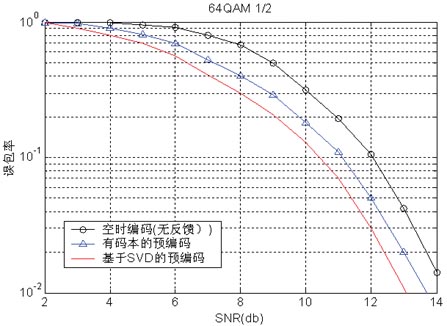
作為首選的 5G 無(wú)線網(wǎng)絡(luò)基礎(chǔ)架構(gòu),大規(guī)模 MIMO 無(wú)線系統(tǒng)現(xiàn)已領(lǐng)跑整個(gè)行業(yè)。低時(shí)延預(yù)編碼實(shí)現(xiàn)方案是充分利用多輸入多輸出 (MIMO) 方案多傳輸架構(gòu)內(nèi)在優(yōu)勢(shì)的關(guān)鍵。我們的團(tuán)隊(duì)利用賽靈思 System Generator 和簡(jiǎn)單可擴(kuò)展的 Vivado? Design Suite 構(gòu)建了一款高速、低時(shí)延預(yù)編碼內(nèi)核。
借其固有的多用戶空分復(fù)用傳輸能力,大規(guī)模 MIMO 系統(tǒng)可顯著提高傳統(tǒng)單天線用戶設(shè)備和升級(jí)版多天線用戶終端的信號(hào)干擾噪聲比(SINR)。這樣不僅可獲得更大的網(wǎng)絡(luò)容量、更高的數(shù)據(jù)吞吐量,而且還能提高頻譜利用率。
但是,大規(guī)模 MIMO 技術(shù)自身仍存在一些挑戰(zhàn)。要使用該技術(shù),電信工程師需要構(gòu)建多個(gè) RF 收發(fā)器和多個(gè)基于輻射式相控陣天線。他們還需要使用數(shù)字資源來(lái)執(zhí)行所謂的預(yù)編碼功能。
我們的解決方案是構(gòu)建低時(shí)延、可擴(kuò)展的頻變預(yù)編碼 IP;可以按照 Lego 方式將該 IP 核用于集中式和分布式 大規(guī)模 MIMO 架構(gòu)。這個(gè) DSP 研發(fā)項(xiàng)目的關(guān)鍵是高性能賽靈思 7 系列 FPGA以及帶有 System Generator 和 MATLAB?/Simulink? 的賽靈思 Vivado Design Suite 2015.1 版本。
通用 MIMO 系統(tǒng)中的預(yù)編碼
在蜂窩網(wǎng)絡(luò)中,特定頻率下每個(gè)發(fā)送器與接收器之間所謂的信道響應(yīng)將在空中對(duì)普通 MIMO 發(fā)送器中輻射出來(lái)的用戶數(shù)據(jù)流進(jìn)行“重塑”。換句話說(shuō),不同數(shù)據(jù)流通往空域另一端的接收器的路徑不同。由于頻域中的“經(jīng)歷”不同,即使是相同的數(shù)據(jù)流有時(shí)也會(huì)有不同表現(xiàn)。
這種固有的無(wú)線傳輸現(xiàn)象等同于將具有特定頻率響應(yīng)的有限脈沖響應(yīng) (FIR) 濾波器應(yīng)用于每個(gè)數(shù)據(jù)流,這樣無(wú)線信道就會(huì)產(chǎn)生頻率“失真”,進(jìn)而導(dǎo)致系統(tǒng)性能不佳。如果我們將無(wú)線信道視為一個(gè)大型黑盒,那么在系統(tǒng)級(jí)只有輸入(發(fā)送器輸出)和輸出(接收器輸入)是顯而易見的。我們可在 MIMO 發(fā)送器側(cè)添加一個(gè)具有逆信道響應(yīng)的預(yù)均衡黑盒,以預(yù)先補(bǔ)償信道的黑盒效應(yīng),然后,級(jí)聯(lián)系統(tǒng)會(huì)在接收器設(shè)備上提供合理的“校正”數(shù)據(jù)流。
我們將這種預(yù)均衡方法稱為預(yù)編碼,從根本上說(shuō),就是在發(fā)送器鏈上應(yīng)用一組“重塑”系數(shù)。例如,如果我們用NTX (發(fā)送器數(shù)量)天線發(fā)送 NRX 個(gè)獨(dú)立數(shù)據(jù)流,那么我們?cè)趯?NTX 個(gè) RF 信號(hào)輻射到空中之前需要通過(guò)N 次臨時(shí)復(fù)數(shù)線性卷積運(yùn)算及相應(yīng)的合并運(yùn)算來(lái)執(zhí)行預(yù)均衡編碼。
復(fù)數(shù)線性卷積的直接、低時(shí)延實(shí)現(xiàn)方法是使用時(shí)域中的復(fù)數(shù) FIR 離散數(shù)字濾波器。
系統(tǒng)功能要求
在低時(shí)延預(yù)編碼 IP 的創(chuàng)建過(guò)程中, 我的團(tuán)隊(duì)面臨一系列基本要求。
1、我們必須用不同系數(shù)組將一個(gè)數(shù)據(jù)流預(yù)編碼為多分支的并行數(shù)據(jù)流。
2、我們需要在每個(gè)分支上放置一個(gè) 100 + 抽頭長(zhǎng)度的復(fù)數(shù)非對(duì)稱 FIR 函數(shù),以提供合適的預(yù)編碼性能。以提供合適的預(yù)編碼性能。
3、需要經(jīng)常對(duì)預(yù)編碼系數(shù)進(jìn)行更新。
4、所設(shè)計(jì)的內(nèi)核必須易于更新和擴(kuò)展,以支持不同的可擴(kuò)展系統(tǒng)架構(gòu)。
5、在給定資源約束下,預(yù)編碼時(shí)延應(yīng)該盡可能低。
此外,除了注意滿足特定設(shè)計(jì)的功能要求以外,我們還要考慮硬件資源約束。換句話說(shuō),建立節(jié)約資源的算法實(shí)現(xiàn)方案對(duì)于有限的關(guān)鍵硬件資源(例如賽靈思 FPGA 上的專用硬件乘法器 DSP48s)大有裨益。
高速、低時(shí)延預(yù)編碼 (HLP) 內(nèi)核設(shè)計(jì)
本質(zhì)上講,在開發(fā)具備該特質(zhì)的設(shè)計(jì)之前必須先滿足可擴(kuò)展性這個(gè)關(guān)鍵特性。可擴(kuò)展設(shè)計(jì)能確保長(zhǎng)期的基礎(chǔ)架構(gòu)可持續(xù)演進(jìn),并在短期實(shí)現(xiàn)最佳的低成本部署策略。可擴(kuò)展性源自模塊化。依照這個(gè)理論,我們使用賽靈思 System Generator 在 Simulink 中創(chuàng)建了一個(gè)模塊化的通用復(fù)數(shù) FIR 濾波器評(píng)估平臺(tái)。
圖 1 所示為頂層系統(tǒng)架構(gòu)。Simulink_HLP_Core 在 Simulink 中用離散數(shù)字濾波器模塊描述多分支復(fù)數(shù) FIR 濾波器;FPGA_HLP_Core 在System Generator 中用賽靈思資源模塊實(shí)現(xiàn)多分支復(fù)數(shù) FIR 濾波器,如圖 2 所示。

?

?
不同的 FIR 實(shí)現(xiàn)架構(gòu)會(huì)產(chǎn)生不同的 FPGA 資源使用。表 1 對(duì)不同實(shí)現(xiàn)架構(gòu)中 128 抽頭復(fù)數(shù)非對(duì)稱 FIR 濾波器中所使用的復(fù)數(shù)乘法器 (CM) 進(jìn)行了比較。我們假設(shè) IQ 數(shù)據(jù)速率是 30.72Msps(20 MHz 帶寬 LTE-Advanced 信號(hào))。

?
全并行實(shí)現(xiàn)架構(gòu)非常簡(jiǎn)單直接,可輕松地映射至直接型 FIR 架構(gòu),但這種實(shí)現(xiàn)架構(gòu)需要使用大量 CM 資源。全串行實(shí)現(xiàn)架構(gòu)使用的 CM 資源數(shù)量最少,得益于其能以時(shí)分復(fù)用 (TDM) 方式與 128 個(gè)操作共享相同的 CM 單元。但其運(yùn)行時(shí)鐘速率是最先進(jìn)的 FPGA 都不可能達(dá)到的。
比較現(xiàn)實(shí)的解決方案是選用部分并行實(shí)現(xiàn)架構(gòu),該架構(gòu)將連續(xù)的長(zhǎng)濾波器鏈分成幾段并行級(jí)。表 1 給出了兩個(gè)實(shí)例。我們選擇使用方案 A,因?yàn)樵摲桨傅?CM 使用量最少,而且時(shí)鐘速率合理。事實(shí)上,我們可以通過(guò)控制數(shù)據(jù)速率、時(shí)鐘速率和連續(xù)級(jí)數(shù)來(lái)決定最終的架構(gòu)
其中 N 和 N 代表濾波器長(zhǎng)度和連續(xù)級(jí)的數(shù)量。然后,我們創(chuàng)建三個(gè)主要模塊:
1、系數(shù)存儲(chǔ)模塊:我們使用高性能雙端口 Block RAM 來(lái)存儲(chǔ)需要加載到 FIR 系數(shù) RAM 中的 IQ 系數(shù)。用戶可以選擇何時(shí)將系數(shù)上載到存儲(chǔ)設(shè)備中以及何時(shí)通過(guò) wr 和 rd 控制信號(hào)來(lái)更新 FIR 濾波器的系數(shù)。
2、數(shù)據(jù) TDM 管線化模塊:我們將采樣率為 30.72 MHz 的輸入 IQ 數(shù)據(jù)進(jìn)行多路復(fù)用,以生成采樣率更高的 8 個(gè)流水線 (NSS = 8)(采樣率較高,為 30.72×128÷8 = 491.52 MHz)。然后,我們將這些數(shù)據(jù)流送入四分支的線性卷積 (4B-LC) 模塊。
3、4B-LC 模塊:該模塊包含四條獨(dú)立的復(fù)數(shù) FIR 濾波器鏈,每條都利用相同的部分并行架構(gòu)實(shí)現(xiàn)。例如,圖 3 中給出的分支 1。 分支 1 包含四個(gè)被寄存器隔離以獲得更好時(shí)序特性的子處理級(jí):FIR 系數(shù) RAM (cRAM) 順序?qū)懭牒筒⑿凶x取級(jí);復(fù)數(shù)乘法級(jí);復(fù)數(shù)加法級(jí);以及分段累積和下采樣級(jí)。
為了把內(nèi)核的 I/O 數(shù)量降到最低,我們的第一級(jí)就需要?jiǎng)?chuàng)建順序?qū)懭氩僮饕员阋?TDM 方式從存儲(chǔ)設(shè)備向 FIR cRAM 加載系數(shù)(每個(gè) cRAM 包含 16 = 128/8 個(gè) IQ 系數(shù))。我們?cè)O(shè)計(jì)了并行讀取操作用以同時(shí)將 FIR 系數(shù)送至 CM 內(nèi)核。
在復(fù)數(shù)乘法級(jí),為將 DSP48 使用量減至最少,我們選擇高效的、完全管線化的三重乘法器架構(gòu)來(lái)執(zhí)行復(fù)數(shù)乘法運(yùn)算,代價(jià)是產(chǎn)生六倍的時(shí)延周期。
接下來(lái),復(fù)數(shù)加法級(jí)將 CM 的輸出聚合成單個(gè)數(shù)據(jù)流。最后,分段累積和下采樣級(jí)在 16 個(gè)時(shí)間周期內(nèi)累積臨時(shí)子流,以導(dǎo)出 128 抽頭 FIR 濾波器的相應(yīng)線性卷積結(jié)果,并降低高速數(shù)據(jù)流的采樣速度以匹配本系統(tǒng)的數(shù)據(jù)采樣率,即 30.72 MHz。
設(shè)計(jì)驗(yàn)證
我們分兩步執(zhí)行 IP 驗(yàn)證。首先,我們將 FPGA_HLP_Core 的輸出與 Simulink 中的參考雙精度多分支 FIR 內(nèi)核進(jìn)行比較。我們發(fā)現(xiàn),在 16 位分辨率版本中,我們已成功實(shí)現(xiàn)小于 0.04% 的相對(duì)幅值誤差。較大的數(shù)據(jù)寬度能提供更好的性能,但代價(jià)是消耗更多資源。
功能驗(yàn)證完成后,就需要驗(yàn)證芯片性能。因此,我們的第二個(gè)步驟是在 Vivado 設(shè)計(jì)套件 2015.1 中針對(duì) Zynq?-7000 All Programmable SoC 的 FPGA 架構(gòu)(相當(dāng)于一個(gè) Kintex? xc7k325tffg900-2)對(duì)所創(chuàng)建的 IP 進(jìn)行綜合與實(shí)現(xiàn)。憑借工具的綜合與默認(rèn)實(shí)現(xiàn)設(shè)置中具備的完整層級(jí),我們創(chuàng)建了一個(gè)具有清晰注冊(cè)層級(jí)的完全管線化設(shè)計(jì),因而在 491.52 MHz 的內(nèi)部處理時(shí)鐘速率下不難實(shí)現(xiàn)所要求的時(shí)序。

?
可擴(kuò)展性演示
我們?cè)O(shè)計(jì)的 HLP IP 便于用來(lái)創(chuàng)建更大的大規(guī)模 MIMO 預(yù)編碼內(nèi)核。表 2 列出了一些應(yīng)用方案以及重要資源的使用情況。

?
您需要一個(gè)額外的聚合級(jí)以提交最后的預(yù)編碼結(jié)果。例如圖 4 所示,通過(guò)插入四個(gè) HLP 內(nèi)核以及一個(gè)額外管線化數(shù)據(jù)聚合級(jí),很容易構(gòu)建一個(gè) 4x4 預(yù)編碼內(nèi)核。

?
高效和可擴(kuò)展
我們已經(jīng)介紹了如何利用賽靈思 System Generator 和 Vivado 設(shè)計(jì)工具快速構(gòu)建 大規(guī)模 MIMO 預(yù)編碼內(nèi)核形式的高效、可擴(kuò)展的DSP 線性卷積應(yīng)用。
您既可以在部分并行架構(gòu)中使用更多順序級(jí),也可以合理地增大處理時(shí)鐘速率以更快速地實(shí)現(xiàn)任務(wù)操作,從而對(duì)該內(nèi)核進(jìn)行擴(kuò)展,以便支持更長(zhǎng)抽頭的 FIR 應(yīng)用。對(duì)于第二種情況,針對(duì)實(shí)際的實(shí)現(xiàn)架構(gòu)找到目標(biāo)器件的瓶頸和關(guān)鍵路徑應(yīng)該會(huì)有所幫助。然后,更好的方法將會(huì)是對(duì)硬件和算法進(jìn)行協(xié)同優(yōu)化以調(diào)節(jié)系統(tǒng)性能,例如針對(duì)硬件的使用開發(fā)出更小型預(yù)編碼算法。











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論