 電子發(fā)燒友App
電子發(fā)燒友App


構(gòu)建能夠在任何環(huán)境中無縫操作、使用各種技能處理不同物體和完成多樣化任務(wù)的通用機(jī)器人,一直是人工智能領(lǐng)域的長期目標(biāo)。然而,不幸的是,大多數(shù)現(xiàn)有的機(jī)器人系統(tǒng)受到限制——它們被設(shè)計用于特定任務(wù)、在特定數(shù)據(jù)集上進(jìn)行訓(xùn)練,并在特定環(huán)境中部署。這些系統(tǒng)通常需要大量標(biāo)注數(shù)據(jù),依賴于特定任務(wù)的模型,在現(xiàn)實世界場景中部署時存在諸多泛化問題,并且難以對分布變化保持魯棒性。
受到網(wǎng)絡(luò)規(guī)模大容量預(yù)訓(xùn)練模型(即基礎(chǔ)模型)在自然語言處理(NLP)和計算機(jī)視覺(CV)等研究領(lǐng)域開放集表現(xiàn)和內(nèi)容生成能力印象深刻的啟發(fā),我們將本綜述(survey)致力于探索(i)如何將現(xiàn)有的NLP和CV領(lǐng)域的基礎(chǔ)模型應(yīng)用于機(jī)器人技術(shù)領(lǐng)域,以及(ii)專門針對機(jī)器人技術(shù)的基礎(chǔ)模型將會是什么樣子。我們首先概述了傳統(tǒng)機(jī)器人系統(tǒng)的構(gòu)成及其普遍適用性的基本障礙。
接著,我們建立了一個分類體系,討論了當(dāng)前利用現(xiàn)有基礎(chǔ)模型進(jìn)行機(jī)器人技術(shù)探索和開發(fā)針對機(jī)器人技術(shù)的模型的工作。最后,我們討論了使用基礎(chǔ)模型啟用通用機(jī)器人系統(tǒng)的關(guān)鍵挑戰(zhàn)和有前景的未來發(fā)展方向。我們鼓勵讀者查看我們的“活動”GitHub倉庫,其中包括本綜述中審閱的論文以及相關(guān)項目和用于開發(fā)機(jī)器人技術(shù)基礎(chǔ)模型的倉庫資源:https://robotics-fm-survey.github.io/。 ?
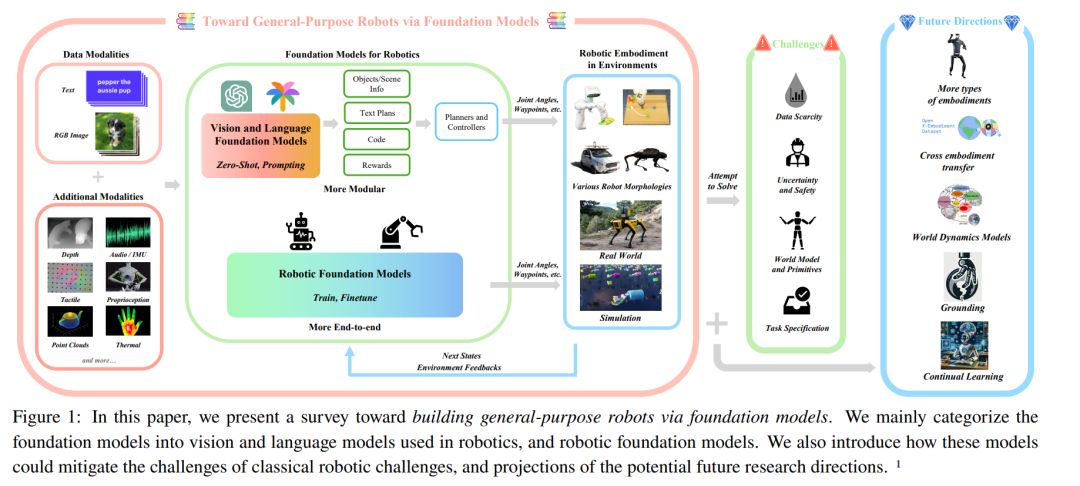
?

? 我們在開發(fā)能夠適應(yīng)不同環(huán)境并在其中運作的自治機(jī)器人系統(tǒng)方面仍面臨許多挑戰(zhàn)。以往的機(jī)器人感知系統(tǒng)利用傳統(tǒng)深度學(xué)習(xí)方法,通常需要大量標(biāo)記數(shù)據(jù)來訓(xùn)練監(jiān)督學(xué)習(xí)模型[1-3];與此同時,為這些大型數(shù)據(jù)集構(gòu)建眾包標(biāo)記過程仍然相當(dāng)昂貴。此外,由于傳統(tǒng)監(jiān)督學(xué)習(xí)方法的泛化能力有限,訓(xùn)練出的模型通常需要精心設(shè)計的領(lǐng)域適應(yīng)技術(shù)才能將這些模型部署到特定場景或任務(wù)[4, 5],這往往需要進(jìn)一步的數(shù)據(jù)收集和標(biāo)記。
類似地,傳統(tǒng)的機(jī)器人規(guī)劃和控制方法通常需要精確建模世界、自主體的動力學(xué)和/或其他代理的行為[6-8]。這些模型針對每個特定環(huán)境或任務(wù)建立,并且在發(fā)生變化時通常需要重新構(gòu)建,暴露了它們的有限可遷移性[8];事實上,在許多情況下,構(gòu)建有效模型要么太昂貴,要么不切實際。盡管基于深度(強化)學(xué)習(xí)的運動規(guī)劃[9, 10]和控制方法[11-14]可以幫助緩解這些問題,但它們也仍然受到分布變化和泛化能力降低的困擾[15, 16]。 ?
在構(gòu)建具有泛化能力的機(jī)器人系統(tǒng)所面臨的挑戰(zhàn)的同時,我們也注意到自然語言處理(NLP)和計算機(jī)視覺(CV)領(lǐng)域的顯著進(jìn)步——引入了大型語言模型(LLMs)[17]用于NLP,使用擴(kuò)散模型進(jìn)行高保真圖像生成[18, 19],以及使用大容量視覺模型和視覺語言模型(VLMs)實現(xiàn)CV任務(wù)的零次/少次學(xué)習(xí)泛化[20-22]。
這些被稱為“基礎(chǔ)模型”[23],或簡稱為大型預(yù)訓(xùn)練模型(LPTMS),這些大容量視覺和語言模型也已應(yīng)用于機(jī)器人技術(shù)領(lǐng)域[24-26],有潛力賦予機(jī)器人系統(tǒng)開放世界的感知、任務(wù)規(guī)劃甚至運動控制能力。除了直接應(yīng)用現(xiàn)有的視覺和/或語言基礎(chǔ)模型于機(jī)器人任務(wù)之外,我們也看到了開發(fā)更多針對機(jī)器人的特定模型的相當(dāng)潛力,例如用于操控的動作模型[27, 28]或用于導(dǎo)航的運動規(guī)劃模型[29]。這些機(jī)器人基礎(chǔ)模型在不同任務(wù)甚至不同實體上顯示出了極大的泛化能力。
視覺/語言基礎(chǔ)模型也已直接應(yīng)用于機(jī)器人任務(wù)[30, 31],顯示了將不同機(jī)器人模塊融合為單一統(tǒng)一模型的可能性。盡管我們看到將視覺和語言基礎(chǔ)模型應(yīng)用于機(jī)器人任務(wù)以及開發(fā)新的機(jī)器人基礎(chǔ)模型的有前景的應(yīng)用,但許多機(jī)器人技術(shù)的挑戰(zhàn)仍然難以企及。從實際部署的角度來看,模型通常無法復(fù)制,缺乏多實體泛化能力,或者無法準(zhǔn)確捕捉環(huán)境中可行(或可接受)的情況。此外,大多數(shù)出版物利用基于Transformer的架構(gòu),專注于物體和場景的語義感知、任務(wù)級規(guī)劃或控制[28];其他可能受益于跨領(lǐng)域泛化能力的機(jī)器人系統(tǒng)組成部分尚未被充分探索——例如,用于世界動力學(xué)的基礎(chǔ)模型或可以進(jìn)行符號推理的基礎(chǔ)模型。最后,我們想強調(diào)需要更多大規(guī)模實際數(shù)據(jù)以及具有多樣化機(jī)器人任務(wù)的高保真模擬器。 ?
在本文中,我們調(diào)查了基礎(chǔ)模型在機(jī)器人技術(shù)中的應(yīng)用,并旨在理解基礎(chǔ)模型如何幫助緩解核心機(jī)器人技術(shù)挑戰(zhàn)。我們使用“機(jī)器人技術(shù)基礎(chǔ)模型”一詞來包括兩個不同的方面:(1)將現(xiàn)有的(主要是)視覺和語言模型應(yīng)用于機(jī)器人技術(shù),主要通過零樣本學(xué)習(xí)和情境學(xué)習(xí);以及(2)使用機(jī)器人生成的數(shù)據(jù)開發(fā)和利用專門針對機(jī)器人任務(wù)的機(jī)器人基礎(chǔ)模型。我們總結(jié)了機(jī)器人技術(shù)基礎(chǔ)模型論文的方法論,并對我們調(diào)查的論文的實驗結(jié)果進(jìn)行了元分析。 ?
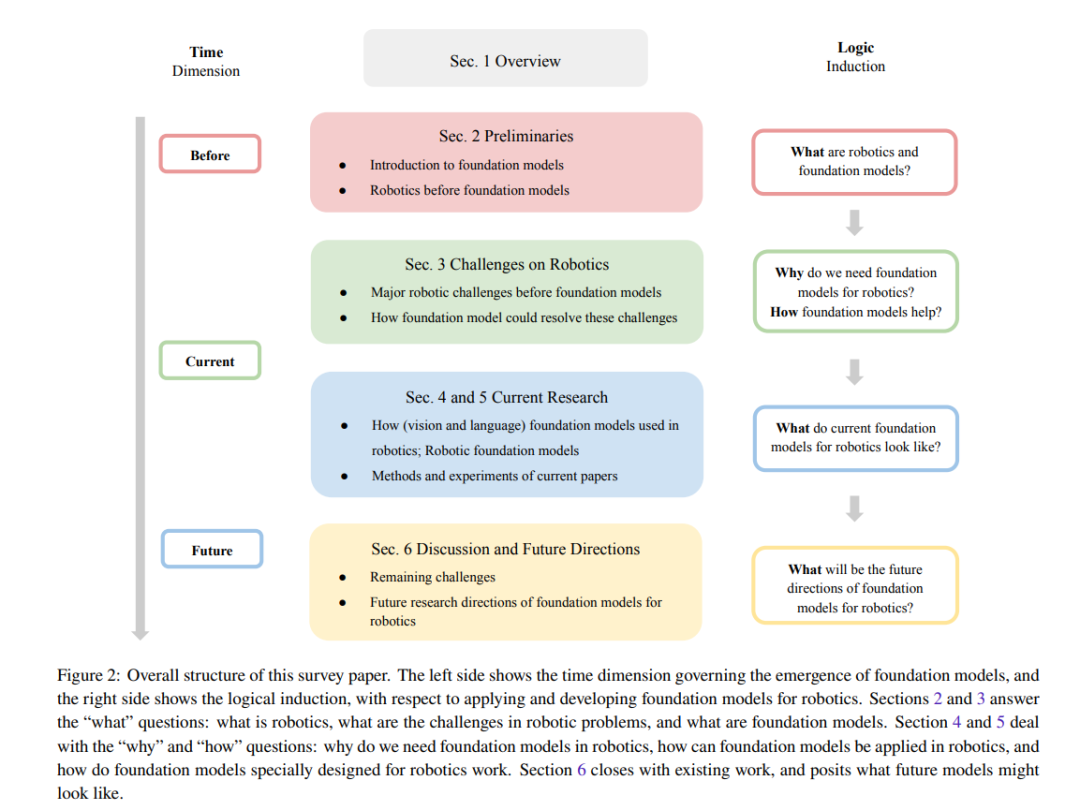
本文的主要組成部分在圖1中進(jìn)行了總結(jié)。本文的整體結(jié)構(gòu)如圖2所述。在第2節(jié)中,我們簡要介紹了基礎(chǔ)模型時代之前的機(jī)器人研究,并討論了基礎(chǔ)模型的基礎(chǔ)知識。在第3節(jié)中,我們列舉了機(jī)器人研究中的挑戰(zhàn),并討論了基礎(chǔ)模型可能如何緩解這些挑戰(zhàn)。在第4節(jié)中,我們總結(jié)了機(jī)器人技術(shù)中基礎(chǔ)模型的當(dāng)前研究現(xiàn)狀。最后,在第6節(jié)中,我們提出了可能對這一研究交叉領(lǐng)域產(chǎn)生重大影響的潛在研究方向。 ?
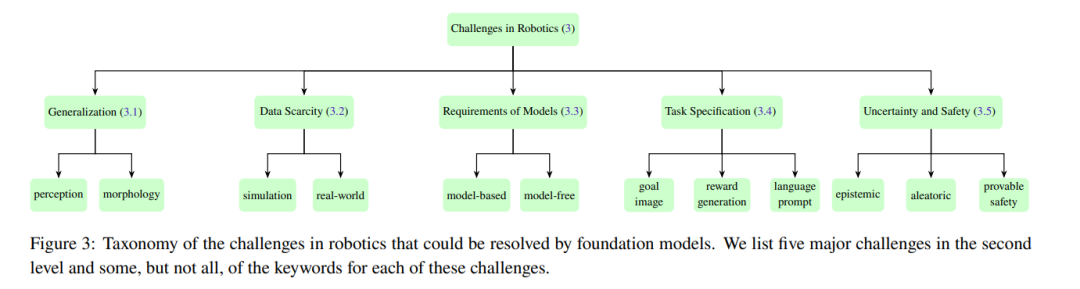
? 機(jī)器人技術(shù)中的挑戰(zhàn)? ? 在本節(jié)中,我們總結(jié)了典型機(jī)器人系統(tǒng)中各種模塊面臨的五個核心挑戰(zhàn),每個挑戰(zhàn)都在以下小節(jié)中詳細(xì)介紹。盡管類似的挑戰(zhàn)已在先前文獻(xiàn)中討論過(見第1.2節(jié)),但本節(jié)主要關(guān)注那些可能通過適當(dāng)利用基礎(chǔ)模型來解決的挑戰(zhàn),這一點從當(dāng)前研究結(jié)果中得到了證據(jù)。我們還在本節(jié)中描述了分類法,以便在圖3中更容易回顧。 ?
?
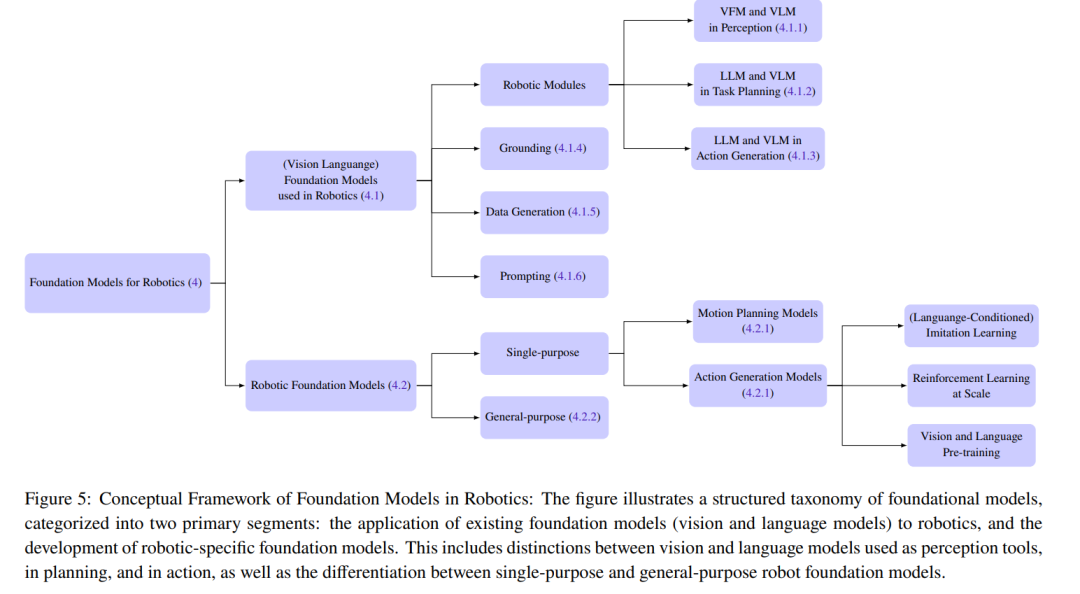
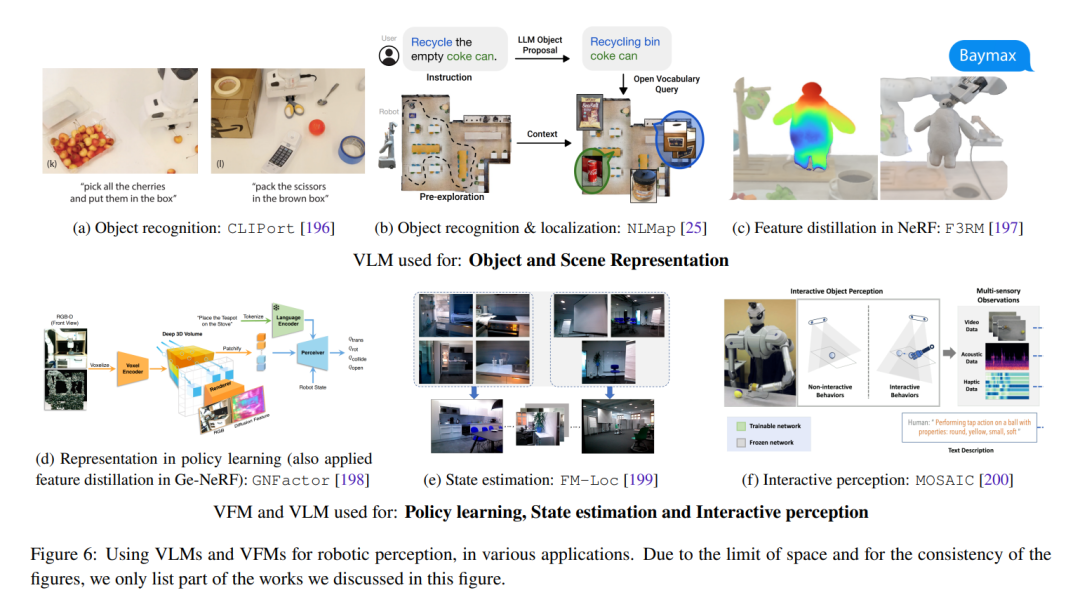
? 用于機(jī)器人技術(shù)的基礎(chǔ)模型 ? 在本節(jié)中,我們重點討論在機(jī)器人技術(shù)中零次學(xué)習(xí)應(yīng)用視覺和語言基礎(chǔ)模型。這主要包括用于機(jī)器人感知的VLMs的零樣本學(xué)習(xí)部署,在任務(wù)級別和運動級別規(guī)劃以及動作生成方面的LLMs的情境學(xué)習(xí)。我們在圖6中展示了一些代表性的工作。 ?
? 機(jī)器人基礎(chǔ)模型(RFMs)
隨著包含真實機(jī)器人的狀態(tài)-動作對的機(jī)器人數(shù)據(jù)集數(shù)量的增加,機(jī)器人基礎(chǔ)模型(RFMs)的類別也變得越來越可行[28, 29, 176]。這些模型的特點是使用機(jī)器人數(shù)據(jù)來訓(xùn)練,以解決機(jī)器人任務(wù)。在本小節(jié)中,我們總結(jié)并討論了不同類型的RFMs。我們首先介紹能夠在第2.1節(jié)中的一個機(jī)器人模塊內(nèi)執(zhí)行一組任務(wù)的RFMs,這被定義為單一目的的機(jī)器人基礎(chǔ)模型。例如,一個能夠生成用于控制機(jī)器人的低級動作的RFM,或一個能夠生成更高級別運動規(guī)劃的模型。之后,我們介紹能夠在多個機(jī)器人模塊中執(zhí)行任務(wù)的RFMs,因此它們是能夠執(zhí)行感知、控制甚至非機(jī)器人任務(wù)的通用模型[30, 31]。
? 如何利用基礎(chǔ)模型解決機(jī)器人技術(shù)挑戰(zhàn)?
? 在第3節(jié)中,我們列出了機(jī)器人技術(shù)中的五個主要挑戰(zhàn)。在本節(jié)中,我們總結(jié)了基礎(chǔ)模型——無論是視覺和語言模型還是機(jī)器人基礎(chǔ)模型——如何以更有組織的方式幫助解決這些挑戰(zhàn)。? ? 所有與視覺信息相關(guān)的基礎(chǔ)模型,如VFMs、VLMs和VGMs,都用于機(jī)器人技術(shù)中的感知模塊。而LLMs則更加多功能,可以應(yīng)用于規(guī)劃和控制領(lǐng)域。我們還在這里列出了RFMs,這些機(jī)器人基礎(chǔ)模型通常用于規(guī)劃和動作生成模塊。我們在表1中總結(jié)了基礎(chǔ)模型如何解決前述的機(jī)器人技術(shù)挑戰(zhàn)。從這個表中我們可以看出,所有基礎(chǔ)模型都擅長于各種機(jī)器人模塊任務(wù)的泛化。此外,LLMs尤其擅長于任務(wù)規(guī)范化。另一方面,RFMs擅長處理動力學(xué)模型的挑戰(zhàn),因為大多數(shù)RFMs是無模型方法。?
? 對于機(jī)器人感知,泛化能力和模型的挑戰(zhàn)是相互聯(lián)系的,因為,如果感知模型已經(jīng)具有非常好的泛化能力,那么就沒有必要為了領(lǐng)域適應(yīng)或額外的微調(diào)而獲取更多數(shù)據(jù)。此外,解決安全挑戰(zhàn)的呼聲在很大程度上缺失,我們將在第6節(jié)中討論這個特殊問題。用于泛化的基礎(chǔ)模型 零次泛化是當(dāng)前基礎(chǔ)模型的最顯著特征之一。機(jī)器人技術(shù)幾乎在所有方面和模塊都受益于基礎(chǔ)模型的泛化能力。首先,VLM和VFM作為默認(rèn)的機(jī)器人感知模型在感知方面的泛化能力是一個很好的選擇。第二方面是任務(wù)級規(guī)劃的泛化能力,由LLMs[24]生成任務(wù)計劃的細(xì)節(jié)。第三個方面是運動規(guī)劃和控制方面的泛化能力,通過利用RFMs的力量。?
? 用于數(shù)據(jù)稀缺的基礎(chǔ)模型?
基礎(chǔ)模型在解決機(jī)器人技術(shù)中的數(shù)據(jù)稀缺問題上至關(guān)重要。它們?yōu)槭褂米钌俚奶囟〝?shù)據(jù)學(xué)習(xí)和適應(yīng)新任務(wù)提供了堅實的基礎(chǔ)。例如,最近的方法利用基礎(chǔ)模型生成數(shù)據(jù)來幫助訓(xùn)練機(jī)器人,如機(jī)器人軌跡[236]和仿真[237]。這些模型擅長從少量示例中學(xué)習(xí),使機(jī)器人能夠使用有限的數(shù)據(jù)快速適應(yīng)新任務(wù)。從這個角度來看,解決數(shù)據(jù)稀缺問題相當(dāng)于解決機(jī)器人技術(shù)中的泛化能力問題。除此之外,基礎(chǔ)模型——尤其是LLMs和VGMs——可以生成用于訓(xùn)練感知模塊[238](見上面的4.1.5節(jié))和任務(wù)規(guī)范化[239]的機(jī)器人技術(shù)數(shù)據(jù)集。? ?
用于減輕模型要求的基礎(chǔ)模型
正如第3.3節(jié)所討論的,建立或?qū)W習(xí)一個模型——無論是環(huán)境地圖、世界模型還是環(huán)境動力學(xué)模型——對于解決機(jī)器人技術(shù)問題至關(guān)重要,尤其是在運動規(guī)劃和控制方面。然而,基礎(chǔ)模型展現(xiàn)的強大的少/零次泛化能力可能會打破這一要求。這包括使用LLMs生成任務(wù)計劃[24],使用RFMs學(xué)習(xí)無模型的端到端控制策略[27, 256]等。? ?
用于任務(wù)規(guī)范化的基礎(chǔ)模型?
任務(wù)規(guī)范化作為語言提示[24, 27, 28],目標(biāo)圖像[181, 272],展示任務(wù)的人類視頻[273, 274],獎勵[26, 182],軌跡粗略草圖[239],政策草圖[275]和手繪圖像[276],使目標(biāo)規(guī)范化以一種更自然、類人的格式實現(xiàn)。多模態(tài)基礎(chǔ)模型允許用戶不僅指定目標(biāo),還可以通過對話解決歧義。最近在理解人機(jī)交互領(lǐng)域中的信任和意圖識別方面的工作開辟了我們理解人類如何使用顯式和隱式線索傳達(dá)任務(wù)規(guī)范化的新范式。雖然取得了顯著進(jìn)展,但最近在LLMs提示工程方面的工作表明,即使只有一個模態(tài),也很難生成相關(guān)輸出。視覺-語言模型被證明在任務(wù)規(guī)范化方面尤其擅長,顯示出解決機(jī)器人技術(shù)問題的潛力。擴(kuò)展基于視覺-語言的任務(wù)規(guī)范化的理念,崔等人[181]探索了使用更自然的輸入,如從互聯(lián)網(wǎng)獲取的圖像,實現(xiàn)多模態(tài)任務(wù)規(guī)范化的方法。Brohan等人[27]進(jìn)一步探索了從任務(wù)無關(guān)數(shù)據(jù)進(jìn)行零次轉(zhuǎn)移的這一理念,提出了一個具有擴(kuò)展模型屬性的新型模型類。該模型將高維輸入和輸出,包括攝像頭圖像、指令和馬達(dá)命令編碼成緊湊的令牌表示,以實現(xiàn)移動操縱器的實時控制。? ?
用于不確定性和安全的基礎(chǔ)模型?
盡管不確定性和安全是機(jī)器人技術(shù)中的關(guān)鍵問題,但使用機(jī)器人技術(shù)基礎(chǔ)模型解決這些問題仍然未被充分探索。現(xiàn)有的工作,如KNOWNO[187],提出了一種測量和對齊基于LLM的任務(wù)規(guī)劃器不確定性的框架。最近在鏈?zhǔn)剿伎继崾綶277]、開放詞匯學(xué)習(xí)[278]和LLMs中幻覺識別[279]方面的進(jìn)展可能為解決這些挑戰(zhàn)開辟新途徑。? ?
審核編輯:黃飛
?







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論