 電子發(fā)燒友App
電子發(fā)燒友App


?
1.1 計算機(jī)視覺概述
計算機(jī)視覺(Computer Vision)又稱機(jī)器視覺(Machine Vision),是一門讓機(jī)器學(xué)會如何去“看”的學(xué)科,是深度學(xué)習(xí)技術(shù)的一個重要應(yīng)用領(lǐng)域,被廣泛應(yīng)用到安防、工業(yè)質(zhì)檢和自動駕駛等場景。具體的說,就是讓機(jī)器去識別攝像機(jī)拍攝的圖片或視頻中的物體,檢測出物體所在的位置,并對目標(biāo)物體進(jìn)行跟蹤,從而理解并描述出圖片或視頻里的場景和故事,以此來模擬人腦視覺系統(tǒng)。因此,計算機(jī)視覺也通常被叫做機(jī)器視覺,其目的是建立能夠從圖像或者視頻中“感知”信息的人工系統(tǒng)。
計算機(jī)視覺的發(fā)展歷程要從生物視覺講起。對于生物視覺的起源,目前學(xué)術(shù)界尚沒有形成定論。有研究者認(rèn)為最早的生物視覺形成于距今約7億年前的水母之中,也有研究者認(rèn)為生物視覺產(chǎn)生于距今約5億年前寒武紀(jì)【1, 2】。寒武紀(jì)生物大爆發(fā)的原因一直是個未解之謎,不過可以肯定的是在寒武紀(jì)動物具有了視覺能力,捕食者可以更容易地發(fā)現(xiàn)獵物,被捕食者也可以更早的發(fā)現(xiàn)天敵的位置。視覺能力加劇了獵手和獵物之間的博弈,也催生出更加激烈的生存演化規(guī)則。視覺系統(tǒng)的形成有力地推動了食物鏈的演化,加速了生物進(jìn)化過程,是生物發(fā)展史上重要的里程碑。經(jīng)過幾億年的演化,目前人類的視覺系統(tǒng)已經(jīng)具備非常高的復(fù)雜度和強(qiáng)大的功能,人腦中神經(jīng)元數(shù)目達(dá)到了1000億個,這些神經(jīng)元通過網(wǎng)絡(luò)互相連接,這樣龐大的視覺神經(jīng)網(wǎng)絡(luò)使得我們可以很輕松的觀察周圍的世界,如?圖1?所示。
?
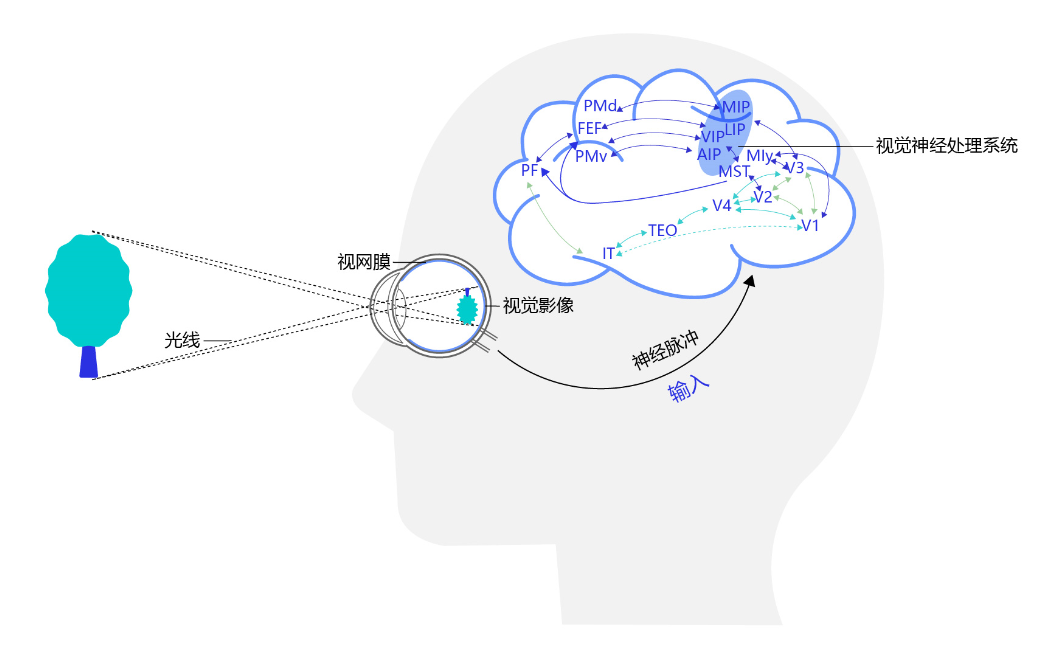
圖1:人類視覺感知
1.2 計算機(jī)視覺應(yīng)用場景
計算機(jī)視覺技術(shù)經(jīng)過幾十年的發(fā)展,已經(jīng)在交通(車牌識別、道路違章抓拍)、安防(人臉閘機(jī)、小區(qū)監(jiān)控)、金融(刷臉支付、柜臺的自動票據(jù)識別)、醫(yī)療(醫(yī)療影像診斷)、工業(yè)生產(chǎn)(產(chǎn)品缺陷自動檢測)等多個領(lǐng)域應(yīng)用,影響或正在改變?nèi)藗兊娜粘I詈凸I(yè)生產(chǎn)方式。未來,隨著技術(shù)的不斷演進(jìn),必將涌現(xiàn)出更多的產(chǎn)品和應(yīng)用,為我們的生活創(chuàng)造更大的便利和更廣闊的機(jī)會。
?
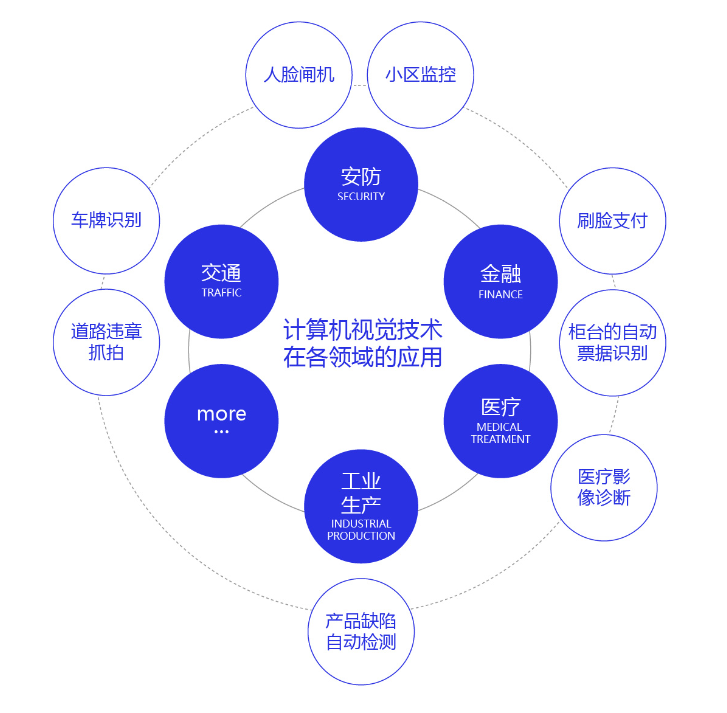
圖2:計算機(jī)視覺技術(shù)在各領(lǐng)域的應(yīng)用
1.3 計算機(jī)視覺任務(wù)的挑戰(zhàn)
對人類來說,識別貓和狗是件非常容易的事。但對計算機(jī)來說,即使是一個精通編程的高手,也很難輕松寫出具有通用性的程序(比如:假設(shè)程序認(rèn)為體型大的是狗,體型小的是貓,但由于拍攝角度不同,可能一張圖片上貓占據(jù)的像素比狗還多)。計算機(jī)視覺任務(wù)在許多方面都具有挑戰(zhàn)性,物體外觀和所處環(huán)境往往變化很大,目標(biāo)被遮擋、目標(biāo)尺寸變化、目標(biāo)變形、背景嘈雜、環(huán)境光照變化。
除此之外,計算機(jī)視覺任務(wù)還面臨數(shù)據(jù)量有限、數(shù)據(jù)類別不均衡、速度實時需求等挑戰(zhàn)。
2 常見的計算機(jī)視覺任務(wù)簡介和基礎(chǔ)概念
計算機(jī)視覺任務(wù)依賴于圖像特征(圖像信息),圖像特征的質(zhì)量在很大程度上決定了視覺系統(tǒng)的性能。傳統(tǒng)方法通常采用SIFT、HOG等算法提取圖像特征,再利用SVM等機(jī)器學(xué)習(xí)算法對這些特征進(jìn)一步處理來解決視覺任務(wù)。行人檢測就是判斷圖像或視頻序列中是否存在行人并給予精確定位,最早采用的方法是HOG特征提取+SVM分類器,檢測流程如下:
利用滑動窗口對整張圖像進(jìn)行遍歷,獲得候選區(qū)域
提取候選區(qū)域的HOG特征
利用SVM分類器對特征圖進(jìn)行分類(判斷是否是人)
使用滑動窗口會出現(xiàn)重復(fù)區(qū)域,利用NMS(非極大值)對重復(fù)的區(qū)域進(jìn)行過濾
分類的結(jié)果強(qiáng)依賴于手工特征提取方法,往往只有經(jīng)驗豐富的研究者才能完成。
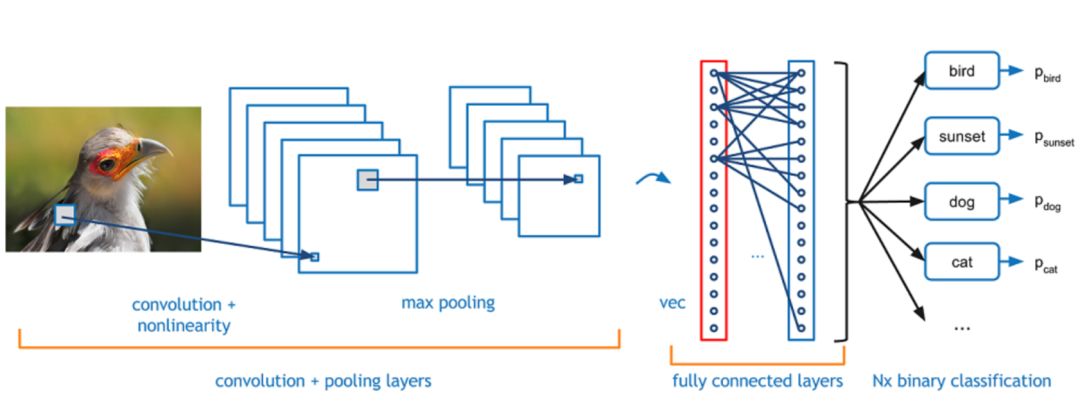
在這種背景下,基于神經(jīng)網(wǎng)絡(luò)的特征提取方法應(yīng)運(yùn)而生。Yann LeCun是1998年第一次將卷積神經(jīng)網(wǎng)絡(luò)應(yīng)用到圖像識別領(lǐng)域的,其主要邏輯是使用卷積神經(jīng)網(wǎng)絡(luò)提取圖像特征,并對圖像所屬類別進(jìn)行預(yù)測,通過訓(xùn)練數(shù)據(jù)不斷調(diào)整網(wǎng)絡(luò)參數(shù),最終形成一套能自動提取圖像特征并對這些特征進(jìn)行分類的網(wǎng)絡(luò)LeNet[1]。這一方法在手寫數(shù)字識別任務(wù)上取得了極大的成功,但在接下來的時間里,卻沒有得到很好的發(fā)展。其主要原因一方面是數(shù)據(jù)集不完善,只能處理簡單任務(wù),在大尺寸的數(shù)據(jù)上容易發(fā)生過擬合;另一方面是硬件瓶頸,網(wǎng)絡(luò)模型復(fù)雜時,計算速度會特別慢。
2012年Alex Krizhevsky等人在提出了AlexNet[2], 并應(yīng)用在大尺寸圖片數(shù)據(jù)集ImageNet上,獲得2012年ImageNet比賽冠軍,極大的推動了卷積神經(jīng)網(wǎng)絡(luò)在計算機(jī)視覺領(lǐng)域的發(fā)展。
如?圖所示。
?

圖5:早期的卷積神經(jīng)網(wǎng)絡(luò)處理圖像任務(wù)示意
全連接:也稱為多層感知機(jī)。
卷積:在卷積神經(jīng)網(wǎng)絡(luò)中,卷積層的實現(xiàn)方式是數(shù)學(xué)中定義的互相關(guān)運(yùn)算。
池化:池化是使用某一位置的相鄰輸出的總體統(tǒng)計特征代替網(wǎng)絡(luò)在該位置的輸出。
dropout:是深度學(xué)習(xí)中一種常用的抑制過擬合的方法,通過隨機(jī)刪除一部分神經(jīng)元。
3 常見的計算機(jī)視覺任務(wù)快速實踐
目前,隨著互聯(lián)網(wǎng)技術(shù)的不斷進(jìn)步,數(shù)據(jù)量呈現(xiàn)大規(guī)模的增長,越來越豐富的數(shù)據(jù)集不斷涌現(xiàn)。另外,得益于硬件能力的提升,計算機(jī)的算力也越來越強(qiáng)大。不斷有研究者將新的模型和算法應(yīng)用到計算機(jī)視覺領(lǐng)域。由此催生了越來越豐富的模型結(jié)構(gòu)和更加準(zhǔn)確的精度,同時計算機(jī)視覺所處理的問題也越來越豐富,包括分類、檢測、分割、場景描述、圖像生成和風(fēng)格變換等,甚至還不僅僅局限于2維圖片,包括視頻處理技術(shù)和3D視覺等,應(yīng)用的領(lǐng)域也越來越廣泛。目前主流的計算機(jī)視覺任務(wù),主要包括圖像分類、目標(biāo)檢測、圖像分割、OCR、視頻分析和圖像生成等。接下來我們介紹每個任務(wù),并通過PaddleHub工具快速進(jìn)行實踐。
首先安裝PaddleHub:
In [?]
!pip install paddlehub --upgrade -i https://mirror.baidu.com/pypi/simple
通過以下指令導(dǎo)入依賴包。
In [1]
import paddlehub as hub import cv2 from PIL import Image import matplotlib.pyplot as plt %matplotlib inline
3.1 圖像分類
圖像分類利用計算機(jī)對圖像進(jìn)行定量分析,把圖像或圖像中的像元或區(qū)域劃分為若干個類別中的某一種。
圖像分類是計算機(jī)視覺中重要的基本問題,也是圖像檢測、圖像分割、物體跟蹤、行為分析等其他高層視覺任務(wù)的基礎(chǔ),在很多領(lǐng)域有廣泛應(yīng)用,包括安防領(lǐng)域的人臉識別和智能視頻分析等,交通領(lǐng)域的交通場景識別,互聯(lián)網(wǎng)領(lǐng)域基于內(nèi)容的圖像檢索和相冊自動歸類,醫(yī)學(xué)領(lǐng)域的圖像識別等。
我們通過第一章講解的PaddleHub快速實現(xiàn)圖像分類,使用resnet50_vd_dishes模型識別如下美食圖片,更多模型及實現(xiàn)請參考PaddleHub模型庫
In [22]
classifier = hub.Module(name="resnet50_vd_dishes") result = classifier.classification(images=[cv2.imread('imgs/test1.jpg')]) print('result:{}'.format(result))
[2022-06-28 1755,454] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
result:[{'白灼蝦': 0.4448080360889435}]
上面介紹了ResNet模型實現(xiàn)了美食分類,除此之外,圖像分類還包含豐富的模型,主要分為CNN骨干網(wǎng)絡(luò)模型和Transformer骨干網(wǎng)絡(luò)模型,每一類又分為部署到服務(wù)器端的高精度模型和部署到手機(jī)等移動端平臺的輕量級系列模型,具有更快的預(yù)測速度,如?圖8?所示:
?

圖:圖像分類算法
注:如果想了解更多分類模型細(xì)節(jié),請參考圖像分類開發(fā)套件PaddleClas
3.2 目標(biāo)檢測
對計算機(jī)而言,能夠“看到”的是圖像被編碼之后的數(shù)字,但它很難理解高層語義概念,比如圖像或者視頻幀中出現(xiàn)的目標(biāo)是人還是物體,更無法定位目標(biāo)出現(xiàn)在圖像中哪個區(qū)域。目標(biāo)檢測的主要目的是讓計算機(jī)可以自動識別圖片或者視頻幀中所有目標(biāo)的類別,并在該目標(biāo)周圍繪制邊界框,標(biāo)示出每個目標(biāo)的位置。目標(biāo)檢測應(yīng)用場景覆蓋廣泛,如安全帽檢測、火災(zāi)煙霧檢測、人員摔倒檢測、電瓶車進(jìn)電梯檢測等等。
我們使用PaddleHub檢測模型yolov3_darknet53_vehicles進(jìn)行車輛檢測。
In [24]
vehicles_detector = hub.Module(name="yolov3_darknet53_vehicles")
result = vehicles_detector.object_detection(images=[cv2.imread('imgs/test2.jpg')], visualization=True)
# 結(jié)果保存在'yolov3_vehicles_detect_output/'目錄,可以觀察可視化結(jié)果
img = Image.open(result[0]['save_path'])
plt.figure(figsize=(15,8))
plt.imshow(img)
plt.show()
[2022-06-28 1517,573] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
上面使用單階段目標(biāo)檢測模型YOLOv3實現(xiàn)了車輛檢測,目前目標(biāo)檢測主要分為Anchor based(兩階段和單階段)、Anchor free模型、Transformer系列如?圖?所示:
?

圖:目標(biāo)檢測算法
其中Anchor是預(yù)先設(shè)定好比例的一組候選框集合,Anchor based方法就是使用Anchor提取候選目標(biāo)框,在特征圖上的每一個點對Anchor進(jìn)行分類和回歸。兩階段模型表示模型分為兩個階段,第一個階段使用anchor回歸候選目標(biāo)框,第二階段使用候選目標(biāo)框進(jìn)一步回歸和分類,輸出最終目標(biāo)框和對應(yīng)的類別。單階段模型無候選框提取過程,直接在輸出層回歸bbox的位置和類別,速度比兩階段模型塊,但是可能造成精度損失。由于需要手工設(shè)計Anchor,并且Anchor匹配對不同尺寸大小的物體不友好,因此發(fā)展出Anchor free模型,不再使用預(yù)先設(shè)定的anchor,通常通過預(yù)測目標(biāo)的中心或者角點,對目標(biāo)進(jìn)行檢測。
注:如果想了解更多目標(biāo)檢測模型細(xì)節(jié),請參考目標(biāo)檢測開發(fā)套件PaddleDetection
3.3 圖像分割
圖像分割指的是將數(shù)字圖像細(xì)分為多個圖像子區(qū)域的過程,即對圖像中的每個像素加標(biāo)簽,這一過程使得具有相同標(biāo)簽的像素具有某種共同視覺特性。圖像分割的目的是簡化或改變圖像的表示形式,使得圖像更容易理解和分析。圖像分割通常用于定位圖像中的物體和邊界(線,曲線等)。圖像分割的領(lǐng)域非常多,人像分割、車道線分割、無人車、地塊檢測、表計識別等等。
我們通過PaddleHub快速實現(xiàn)圖像分割,使用deeplabv3p_xception65_humanseg預(yù)訓(xùn)練模型進(jìn)行人像分割。
In [25]
human_seg = hub.Module(name="deeplabv3p_xception65_humanseg")
result = human_seg.segmentation(images=[cv2.imread('./imgs/test3.jpg')], visualization=True)
# 結(jié)果保存在'humanseg_output/'目錄,可以觀察可視化結(jié)果
img_ori = Image.open('./imgs/test3.jpg')
img = Image.open(result[0]['save_path'])
fig = plt.figure(figsize=(8,8))
# 顯示原圖
ax = fig.add_subplot(1,2,1)
ax.imshow(img_ori)
# 顯示人像分割圖
ax = fig.add_subplot(1,2,2)
ax.imshow(img)
plt.show()
[2022-06-28 1845,298] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
上面使用deeplabv3p識別實現(xiàn)了人像分割,除此之外,圖像分割還包含如?圖所示算法:
?
 圖12:圖像分割算法
圖12:圖像分割算法
?
注:如果想了解更多圖像分割模型細(xì)節(jié),請參考圖像分割開發(fā)套件PaddleSeg
3.4 OCR
OCR(Optical Character Recognition,光學(xué)字符識別)是計算機(jī)視覺重要方向之一。傳統(tǒng)定義的OCR一般面向掃描文檔類對象,即文檔場景文字識別(Document Analysis & Recognition,DAR),現(xiàn)在我們常說的OCR一般指場景文字識別(Scene Text Recognition,STR),主要面向自然場景。OCR技術(shù)有著豐富的應(yīng)用場景,如卡證票據(jù)信息抽取錄入審核、工廠自動化、政府工作醫(yī)院等文檔電子化、在線教育等。
?
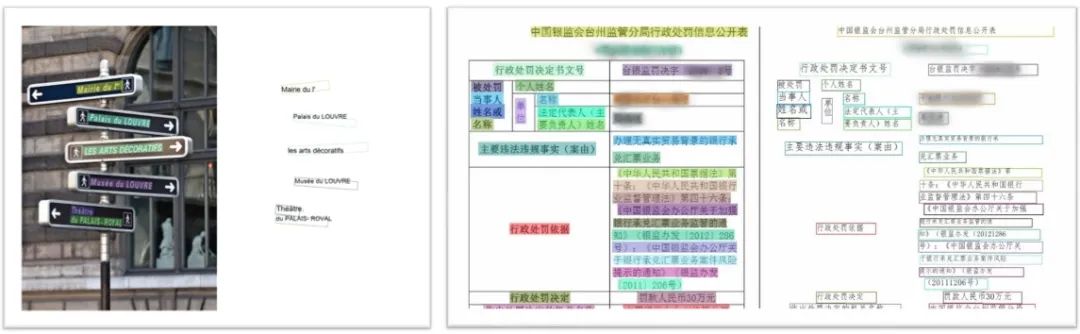
圖:文字識別示意圖
我們通過PaddleHub快速實現(xiàn)OCR任務(wù),使用chinese_ocr_db_crnn_mobile模型進(jìn)行文字識別。
In [24]
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
result = ocr.recognize_text(images=[cv2.imread('./imgs/test4.jpg')], visualization=True)
# 結(jié)果保存在'ocr_result/'目錄,可以觀察可視化結(jié)果
img = Image.open(result[0]['save_path'])
plt.figure(figsize=(20,20))
plt.imshow(img)
plt.show()
[2022-06-28 1756,761] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object [2022-06-28 1757,665] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
?
?

?
上面使用DBNet檢測模型和CRNN識別實現(xiàn)了文字識別,可以看到上述OCR實現(xiàn)過程分為檢測和識別2個模型,我們稱之為兩階段算法,除此之外還有端到端算法,使用一個模型同時完成文字檢測和文字識別。文檔分析能夠幫助開發(fā)者更好地完成文檔理解相關(guān)任務(wù),通常OCR算法和文檔分析算法結(jié)合使用。
?

圖14:OCR算法
其中,版面分析識別文檔中的圖像、文本、標(biāo)題和表格等區(qū)域,然后對文本、標(biāo)題等區(qū)域進(jìn)行OCR的檢測識別,如?圖15(a)?所示。表格識別對文檔中表格區(qū)域進(jìn)行結(jié)構(gòu)化分析,最終結(jié)果輸出Excel文件,如?圖15(b)?所示。關(guān)鍵信息提取算法,將每個檢測到的文本區(qū)域分類為預(yù)定義的類別,如訂單ID、發(fā)票號碼,金額等,如?圖15(c)?所示。文檔視覺問答DocVQA包括語義實體識別SER 和關(guān)系抽取RE任務(wù)。基于SER任務(wù),可以完成對圖像中的文本識別與分類;基于RE任務(wù),可以完成對圖象中的文本內(nèi)容的關(guān)系提取,如判斷問題對(pair),如?圖15(d)?所示。PP-Structure包含了版面分析、表格識別、視覺問答等功能,支持模型訓(xùn)練、測試等,如?圖15(e)?所示。
?

圖15:文檔分析算法
注:如果想了解更多OCR模型細(xì)節(jié),請參考OCR開發(fā)套件PaddleOCR
3.5 視頻分析
視頻分析旨在通過智能分析技術(shù),自動化地對視頻中的內(nèi)容進(jìn)行識別和解析。視頻是動態(tài)的按照時間排序的圖片序列,然后圖片幀間有著密切的聯(lián)系,存在上下文聯(lián)系;視頻有音頻信息,部分視頻也有文本信息,視頻分析常見子任務(wù)如?圖16?所示:
?
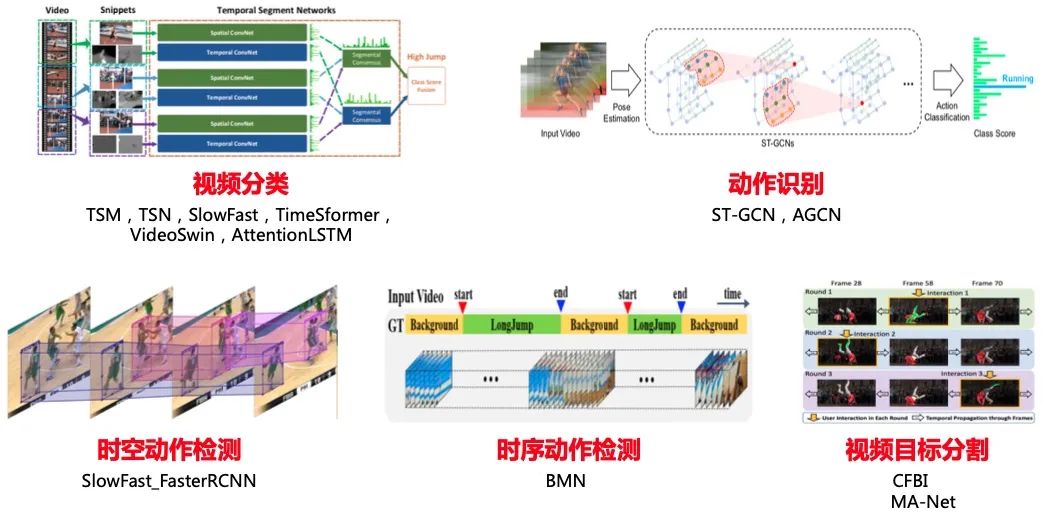
圖16:視頻分析子任務(wù)示意圖
我們通過PaddleHub快速實現(xiàn)視頻分類任務(wù),使用videotag_tsn_lstm預(yù)訓(xùn)練模型
In [2]
videotag = hub.Module(name="videotag_tsn_lstm") result = videotag.classify(paths=["imgs/dance.mp4"]) print(result)
[2022-06-28 1527,292] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
[{'path': 'imgs/dance.mp4', 'prediction': {'舞蹈': 0.8504236936569214}}]
上面使用TSN模型實現(xiàn)了視頻分類,根據(jù)視頻分析的應(yīng)用領(lǐng)域,分為以下算法,
?

圖18:視頻分析算法
注:如果想了解更多視頻分析模型細(xì)節(jié),請參考視頻分析開發(fā)套件PaddleVideo
3.6 圖像生成
GAN的全稱是Generative Adversarial Networks,即生成對抗網(wǎng)絡(luò),由Ian J. Goodfellow等人提出。一般一個GAN網(wǎng)絡(luò)包括了一個生成器(Generator)和一個判別器(Discriminator),生成器用于生成越來越接近實際標(biāo)簽的數(shù)據(jù),判別器用來區(qū)分生成器的生成結(jié)果和實際標(biāo)簽。生成模型和判別模型構(gòu)成了一個動態(tài)的“博弈過程”,最終的平衡點即納什均衡點,即生成模型所生成數(shù)據(jù)(G(z))無限接近真實數(shù)據(jù)(x)。GAN模型應(yīng)用也非常廣泛,可應(yīng)用于圖像生成、風(fēng)格遷移、超分辨率、影像上色、人臉屬性編輯、人臉融合、動作遷移等。
In [21]
import cv2
import paddlehub as hub
model = hub.Module(name='UGATIT_100w')
# 結(jié)果保存在'output/'目錄,可以觀察可視化結(jié)果
result = model.style_transfer(images=[cv2.imread('imgs/test6.jpg')], visualization=True)
img_ori = Image.open('./imgs/test6.jpg')
img = cv2.cvtColor(result[0], cv2.COLOR_BGR2RGB)
img = Image.fromarray(img)
fig = plt.figure(figsize=(8,8))
# 顯示原圖
ax = fig.add_subplot(1,2,1)
ax.imshow(img_ori)
# 顯示生成漫畫圖
ax = fig.add_subplot(1,2,2)
ax.imshow(img)
plt.show()
[2022-06-28 1724,765] [ WARNING] - The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
上面使用U-GAT-IT模型實現(xiàn)了人像動漫化,根據(jù)GAN的應(yīng)用領(lǐng)域,分為以下算法,
?

圖20:圖像生成算法
注:如果想了解更多圖像生成模型細(xì)節(jié),請參考圖像生成開發(fā)套件PaddleGAN
4 總結(jié)
本章我們主要介紹了計算機(jī)視覺概念、應(yīng)用場景和挑戰(zhàn),然后介紹了目前常見的計算機(jī)視覺任務(wù)(圖像分類、目標(biāo)檢測、圖像分割、OCR、視頻分析、圖像生成),并通過PaddleHub快速實現(xiàn)。
編輯:黃飛
?














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論