 電子發燒友App
電子發燒友App


大數據分析的概念
大數據分析是指對規模巨大的數據進行分析。大數據可以概括為5個V, 數據量大(Volume)、速度快(Velocity)、類型多(Variety)、價值(Value)、真實性(Veracity)。
大數據作為時下最火熱的IT行業的詞匯,隨之而來的數據倉庫、數據安全、數據分析、數據挖掘等等圍繞大數據的商業價值的利用逐漸成為行業人士爭相追捧的利潤焦點。隨著大數據時代的來臨,大數據分析也應運而生。
 大數據分析包含那些方面
大數據分析包含那些方面
1. 可視化分析
不管是對數據分析專家還是普通用戶,數據可視化是數據分析工具最基本的要求。可視化可以直觀的展示數據,讓數據自己說話,讓觀眾聽到結果。
2. Data Mining Algorithms(數據挖掘算法)
可視化是給人看的,數據挖掘就是給機器看的。集群、分割、孤立點分析還有其他的算法讓我們深入數據內部,挖掘價值。這些算法不僅要處理大數據的量,也要處理大數據的速度。
3. Predictive Analytic Capabilities(預測性分析能力)
數據挖掘可以讓分析員更好的理解數據,而預測性分析可以讓分析員根據可視化分析和數據挖掘的結果做出一些預測性的判斷。
4. Semantic Engines(語義引擎)
我們知道由于非結構化數據的多樣性帶來了數據分析的新的挑戰,我們需要一系列的工具去解析,提取,分析數據。語義引擎需要被設計成能夠從“文檔”中智能提取信息。
5. Data Quality and Master Data Management(數據質量和數據管理)
數據質量和數據管理是一些管理方面的最佳實踐。通過標準化的流程和工具對數據進行處理可以保證一個預先定義好的高質量的分析結果。
假如大數據真的是下一個重要的技術革新的話,我們最好把精力關注在大數據能給我們帶來的好處,而不僅僅是挑戰。
6.數據存儲,數據倉庫
數據倉庫是為了便于多維分析和多角度展示數據按特定模式進行存儲所建立起來的關系型數據庫。在商業智能系統的設計中,數據倉庫的構建是關鍵,是商業智能系統的基礎,承擔對業務系統數據整合的任務,為商業智能系統提供數據抽取、轉換和加載(ETL),并按主題對數據進行查詢和訪問,為聯機數據分析和數據挖掘提供數據平臺。
大數據分析的常用方法
1、聚類分析(Cluster Analysis)
聚類分析指將物理或抽象對象的集合分組成為由類似的對象組成的多個類的分析過程。聚類是將數據分類到不同的類或者簇這樣的一個過程,所以同一個簇中的對象有很大的相似性,而不同簇間的對象有很大的相異性。聚類分析是一種探索性的分析,在分類的過程中,人們不必事先給出一個分類的標準,聚類分析能夠從樣本數據出發,自動進行分類。聚類分析所使用方法的不同,常常會得到不同的結論。不同研究者對于同一組數據進行聚類分析,所得到的聚類數未必一致。
2、因子分析(Factor Analysis)
因子分析是指研究從變量群中提取共性因子的統計技術。因子分析就是從大量的數據中尋找內在的聯系,減少決策的困難。因子分析的方法約有10多種,如重心法、影像分析法,最大似然解、最小平方法、阿爾發抽因法、拉奧典型抽因法等等。這些方法本質上大都屬近似方法,是以相關系數矩陣為基礎的,所不同的是相關系數矩陣對角線上的值,采用不同的共同性□2估值。在社會學研究中,因子分析常采用以主成分分析為基礎的反覆法。
3、相關分析(Correlation Analysis)
相關分析(correlation analysis),相關分析是研究現象之間是否存在某種依存關系,并對具體有依存關系的現象探討其相關方向以及相關程度。相關關系是一種非確定性的關系,例如,以X和Y分別記一個人的身高和體重,或分別記每公頃施肥量與每公頃小麥產量,則X與Y顯然有關系,而又沒有確切到可由其中的一個去精確地決定另一個的程度,這就是相關關系。
4、對應分析(Correspondence Analysis)
對應分析(Correspondence analysis)也稱關聯分析、R-Q型因子分析,通過分析由定性變量構成的交互匯總表來揭示變量間的聯系。可以揭示同一變量的各個類別之間的差異,以及不同變量各個類別之間的對應關系。對應分析的基本思想是將一個聯列表的行和列中各元素的比例結構以點的形式在較低維的空間中表示出來。
5、回歸分析
研究一個隨機變量Y對另一個(X)或一組(X1,X2,?,Xk)變量的相依關系的統計分析方法。回歸分析(regression analysis)是確定兩種或兩種以上變數間相互依賴的定量關系的一種統計分析方法。運用十分廣泛,回歸分析按照涉及的自變量的多少,可分為一元回歸分析和多元回歸分析;按照自變量和因變量之間的關系類型,可分為線性回歸分析和非線性回歸分析。
6、方差分析(ANOVA/Analysis of Variance)
又稱“變異數分析”或“F檢驗”,是R.A.Fisher發明的,用于兩個及兩個以上樣本均數差別的顯著性檢驗。由于各種因素的影響,研究所得的數據呈現波動狀。造成波動的原因可分成兩類,一是不可控的隨機因素,另一是研究中施加的對結果形成影響的可控因素。方差分析是從觀測變量的方差入手,研究諸多控制變量中哪些變量是對觀測變量有顯著影響的變量。
以上是思邁特軟件Smartbi的分享,更多行業干貨可關注我們下一期的分享。思邁特軟件Smartbi是知名國產BI品牌,專注于商業智能BI與大數據BI分析平臺軟件產業的研發及服務。經過多年持續自主研發,凝聚大量商業智能最佳實踐經驗,整合了各行業的數據分析和決策支持的功能需求。滿足最終用戶在企業級報表、數據可視化分析、自助探索分析、數據挖掘建模、AI智能分析等大數據分析需求。
現個人版提供全模塊長期免費使用,有興趣的小伙伴可登陸官網免費試用。
責任編輯:tzh




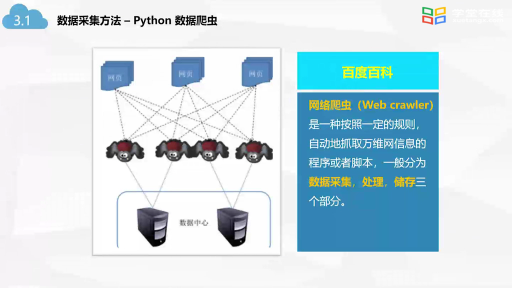








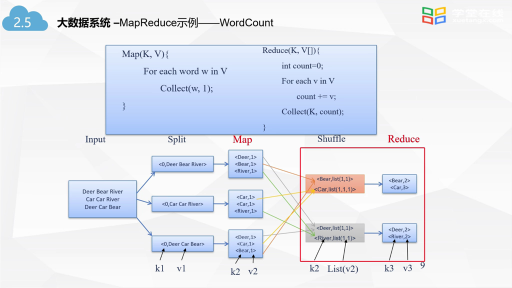




























































 工商網監
工商網監
評論