 電子發燒友App
電子發燒友App


在做數據分析時你有沒有遇到這些問題:
數據量大,怎么也找不到特定日期的文件
老板要看某年某月的銷售數據,你要從百萬量級數據中一條條尋找
……
要是使用永洪BI,會不會有一種方法,讓我們在百萬量級的數據中,一眼鎖定要找的那一條?有的,那便是文件過濾。
首先,我們來說一下什么是meta,什么是文件過濾。
01 什么是meta
meta是集市文件上打的標簽,可以大致理解為這個集市文件的屬性。
比如,某個集市數據,我們是按天入的,每天生成的集市文件是前一天的數據,給這個集市文件添加了一個屬性(屬性名:date,屬性值:昨天的日期),這個就叫做meta。
這個舉個常見例子,有某個部門的銷售數據,每天的銷售數據存儲在一個excel中,這個excel的文件名上帶上這天的日期。集市文件的meta就相當于excel文件的文件名上的日期。
02 什么是文件過濾
先說說文件,這里的“文件”,指的是增量任務生成的集市文件,這個文件是存儲在m節點,安裝目錄/Yonghong/cloud下,也就是存儲在m節點磁盤上的。
文件過濾,接著上面excel的比喻講,大致就是每天的銷售數據,存儲在一個excel文件中,這個excel的文件名還帶上了這天的日期。
要查詢某天的銷售數據就很快了,根據日期直接定位到要查詢的這天,快速準確找到這天的數據,不需要所有的excel數據都打開去查一下。
回到文件過濾也是類似的效果,給每個集市文件打上了meta,meta的值是每個集市文件對應的數據的日期,那么要查詢某天,或者某段時間的數據,就可以快速定位并查詢,不需要所有的集市文件都查一遍,然后去找到想要的日期的數據。
說到這里是不是有個大概的概念,接下來說說為什么要什么文件過濾。
03 為什么做文件過濾
舉個例子,某個部門的銷售數據,每天大概有100萬左右,一年大概就是3億+。如果存儲在excel中,一個excel文件假設存儲的是100萬左右,那么1年就有365個excel。
如果不把每天的數據存儲在同一個excel,且文件名上標上每天的日期,那么當要查某天,或者某段時間的數據,是不是一個很大的工作量,需要把這365個excel都打開查一遍。
對應到產品的集市中也是一樣,一個集市文件最大存儲的行數大概100萬行,如果這些數據都是按天增量的,且在集市文件生成的時候就給這些文件打上了meta。
meta值是數據對應的日期,那么當查詢某一天的數據的時候,就可根據meta的值進行過濾,只查meta值為這天的這一個集市文件,那么計算量就是100萬。
再來看一下如果不使用文件過濾,就需要把這365個集市文件都查詢一遍,最終再過濾出這一天的數據,計算量是3億+。
使用文件過濾是為了減少實際計算量,減少計算量后計算需要的時間也可以大幅減少,那么報表打開也就更快了。
下面做個比較,可以看到使用文件過濾與否,查詢相同的時間的數據,實際的后臺計算量和計算時間的巨大差別。
| 場景 | 是否使用文件過濾 | 計算文件個數 | 計算數據量 | 假設一個集市文件(100萬)計算時長 | 計算需要時間 |
| 某部門銷售數據每天100萬,1年365百萬,默認查詢昨天的數據 | 是 | 1 | 1百萬 | 100ms | 100ms |
| 否 | 365 | 365百萬 | 365000ms=36s | ||
| 某部門銷售數據每天100萬,1年365百萬,默認查詢上個月的數據 | 是 | 30 | 30百萬 | 100ms | 3000ms=3s |
| 是 | 365 | 365百萬 | 365000ms=36s | ||
| 備注:這里的計算時間是按照m節點的計算能力為1計算,實際情況不止1,但是實際也不會只有一個組件,每個組件都會有這樣一個集市查詢 | |||||
前面已經了解了,文件過濾是什么以及為什么要用文件過濾,接下來就是文件過濾怎么用?
文件過濾的使用前提:數據已經通過增量的方式入到集市中,且在入的時候已經按照日期打好meta。
首先來看一下咱們增量且已經打好meta的集市數據。
|
集市文件夾:咖啡銷售數據 下的集市文件 |
數據對應月份 | meta名 | meta值 |
| 2020年銷售數據.6cb2f7790.0.0.zb | 2020-01 | _Date_Range_ | 2020-01 |
| 2020年銷售數據.6cb2f7790.1.0.zb | 2020-02 | 2020-02 | |
| 2020年銷售數據.6cb2f7790.2.0.zb | 2020-03 | 2020-03 | |
| 2020年銷售數據.6cb2f7790.3.0.zb | 2020-04 | 2020-04 | |
| 2020年銷售數據.6cb2f7790.4.0.zb | 2020-05 | 2020-05 | |
| 2020年銷售數據.6cb2f7790.5.0.zb | 2020-06 | 2020-06 | |
| 2020年銷售數據.6cb2f7790.6.0.zb | 2020-07 | 2020-07 | |
| 2020年銷售數據.6cb2f7790.7.0.zb | 2020-08 | 2020-08 | |
| 2020年銷售數據.6cb2f7790.8.0.zb | 2020-09 | 2020-09 | |
| 2020年銷售數據.6cb2f7790.9.0.zb | 2020-10 | 2020-10 | |
| 2020年銷售數據.6cb2f7790.10.0.zb | 2020-11 | 2020-11 | |
| 2020年銷售數據.6cb2f7790.11.0.zb | 2020-12 | 2020-12 | |
|
2020年銷售數據 是增量的時候設置的文件名 6cb2f7790 是隨機碼 0.0-11.0 是集市文件編號 .zb 是集市文件后綴 |
|||
使用步驟:
1、在“創建數據集”模塊,新建數據集市數據集,選擇增量任務中設置的文件夾名稱,就得到一個數據集市數據集。
2、在數據集市數據集添加文件過濾,比如查詢某一天的數據,對應的文件過濾如下:
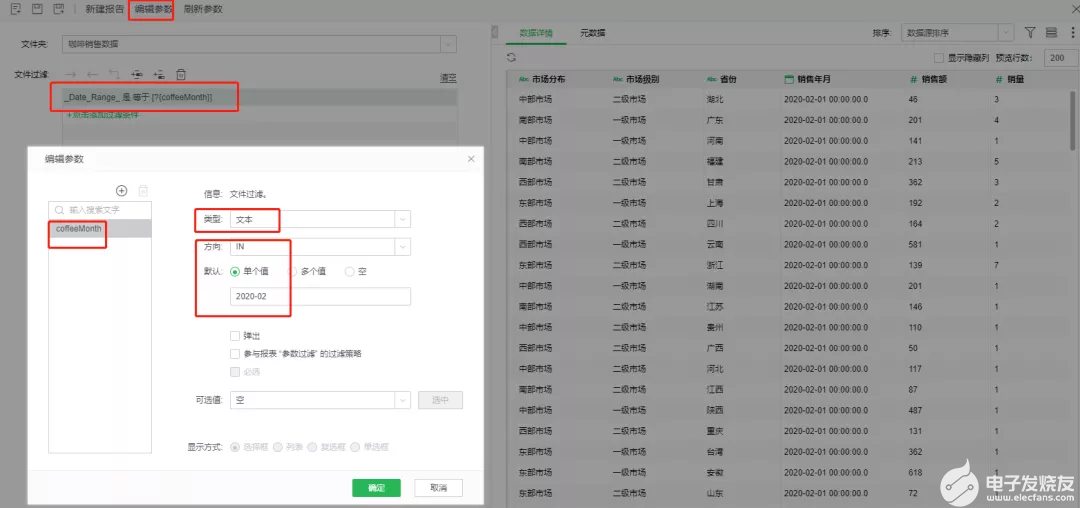
3、使用這個數據集市數據集制作報告,并將步驟2中定義的參數coffeeMonth的值,在報告中傳遞到數據集使用。
注意:參數的數據類型和格式一定要跟meta的數據類型和格式一致,如果不一致需要腳本處理。
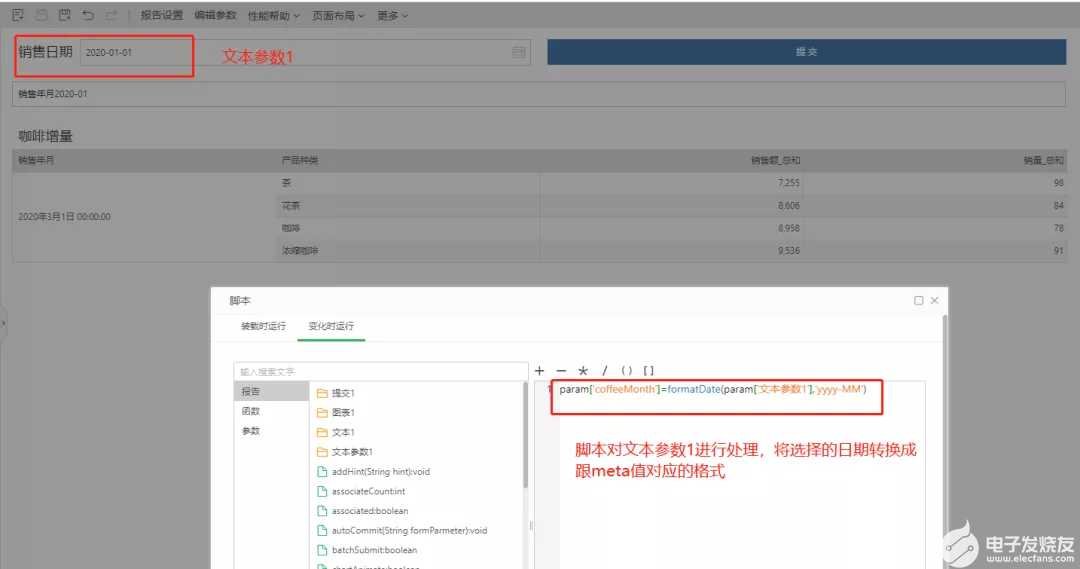
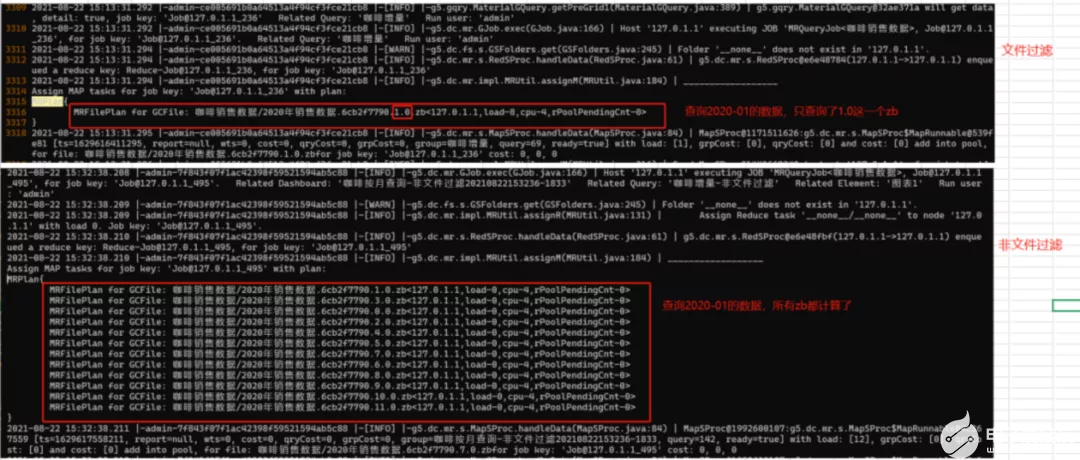
4、保存報告并查看效果,在報告中篩選選擇某個月,實際底層查詢的集市文件只查詢這個月對應,而不是集市文件。
查詢效果見下圖,底層實際計算情況見截圖(查詢2020-01月的數據,使用文件過濾和不使用文件過濾的對比)。
?
什么時候適合用文件過濾?
集市查詢數據量大的時候;查詢的時候咱們只查詢部分數據,而不是全量數據;希望提升查詢性能;能夠有用于增量同步的字段,比如日期,或者有經常篩選的字段用于打meta后的文件過濾。
舉個例子,一個查詢包含的數據量很大,時間跨度比較大(比如有3年的數據),每次查詢的范圍不是太大(比如每次查詢大概3個月的數據,查詢范圍不定),這種就比較適合用文件過濾,將每次實際計算的計算量從3年縮減到三個月。
真正實現前臺篩選多長時間范圍,后臺計算的就是多長時間的數據,而不是這個查詢所有的數據計算完成再來篩選時間范圍。
最后總結一下,集市查詢,相對直連的情況一般對于報告的查詢速度,是有顯著的優化的,但是一個查詢的總數據量很大的時候,實際查詢的并不是全部時間段的情況下,用文件過濾能進一步優化查詢性能。
fqj














































 工商網監
工商網監
評論