 電子發(fā)燒友App
電子發(fā)燒友App


本篇是利用 Python 和 PyTorch 處理面向?qū)ο蟮臄?shù)據(jù)集系列博客的第 3 篇。
第 3 部分:repetita iuvant(*):貓和狗
(*) 是一個(gè)拉丁語(yǔ)詞組,意為“水滴石穿,功到自成”
在本篇博文中,我們將在“貓和狗”數(shù)據(jù)庫(kù)上重復(fù)先前第 2 部分中已完成的過(guò)程,并且我們將添加一些其它內(nèi)容。
通常,簡(jiǎn)單的數(shù)據(jù)集都是按文件夾來(lái)組織的。例如,貓、狗以及每個(gè)類別的“訓(xùn)練”、“驗(yàn)證”和“測(cè)試”文件夾。
通過(guò)將數(shù)據(jù)集組織為單一對(duì)象,即可避免文件夾樹的復(fù)雜性。在此應(yīng)用中,所有圖片都保存到同一個(gè)文件夾內(nèi)。
我們只需 1 個(gè)標(biāo)簽文件來(lái)標(biāo)明哪個(gè)是狗,哪個(gè)是貓即可。
以下包含了用于自動(dòng)創(chuàng)建標(biāo)簽文件的代碼。即使每張圖片名稱本身就包含了標(biāo)簽,我們也特意創(chuàng)建 1 個(gè)專用 label.txt 文件:其中每行都包含文件名和標(biāo)簽:貓 (cat) = 0 狗 (dog) = 1。
在此示例最后,我們將回顧使用 PyTorch 拆分?jǐn)?shù)據(jù)集的 2 種方法,并訓(xùn)練 1 個(gè)非常簡(jiǎn)單的模型。
輸入 [ ]:
data_path = './raw_data/dogs_cats/all'
import os
files = [f for f in os.listdir(data_path) ]
#for f in files:
# print(f)
with open(data_path + '/'+ "labels.txt", "a") as myfile:
for f in files:
if f.split('.')[0]=='cat':
label = 0
elif f.split('.')[0]=='dog':
label = 1
else:
print("ERROR in recognizing file " + f + "label")
myfile.write(f + ' ' + str(label) + '\n')
輸入 [106]:
raw_data_path = './raw_data/dogs_cats/all'
im_example_cat = Image.open(raw_data_path + '/' + 'cat.1070.jpg')
im_example_dog = Image.open(raw_data_path + '/' + 'dog.1070.jpg')
fig, axs = plt.subplots(1, 2, figsize=(10, 3))
axs[0].set_title('should be a cat')
axs[0].imshow(im_example_cat)
axs[1].set_title('should be a dog')
axs[1].imshow(im_example_dog)
plt.show()
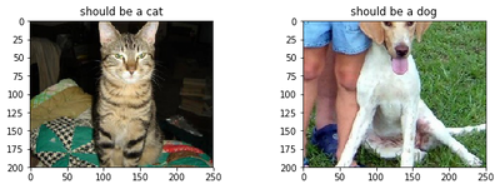
請(qǐng)務(wù)必刷新樣本列表:
輸入 [ ]:
del sample_list
@functools.lru_cache(1)
def getSampleInfoList(raw_data_path):
sample_list = []
with open(str(raw_data_path) + '/labels.txt', mode = 'r') as f:
reader = csv.reader(f, delimiter = ' ')
for i, row in enumerate(reader):
imgname = row[0]
label = int(row[1])
sample_list.append(DataInfoTuple(imgname, label))
sample_list.sort(reverse=False, key=myFunc)
# print("DataInfoTouple: samples list length = {}".format(len(sample_list)))
return sample_list
數(shù)據(jù)集對(duì)象創(chuàng)建非常簡(jiǎn)單,只需 1 行代碼即可:
輸入 [114]:
mydataset = MyDataset(isValSet_bool = None, raw_data_path = raw_data_path, norm = False, resize = True, newsize = (64, 64))
如需進(jìn)行歸一化,則應(yīng)計(jì)算平均值和標(biāo)準(zhǔn)差,并重新生成歸一化后的數(shù)據(jù)集。
代碼如下,以確保代碼完整性。
輸入 [ ]:
imgs = torch.stack([img_t for img_t, _ in mydataset], dim = 3)
im_mean = imgs.view(3, -1).mean(dim=1).tolist()
im_std = imgs.view(3, -1).std(dim=1).tolist()
del imgs
normalize = transforms.Normalize(mean=im_mean, std=im_std)
mydataset = MyDataset(isValSet_bool = None, raw_data_path = raw_data_path, norm = True, resize = True, newsize = (64, 64))
將數(shù)據(jù)庫(kù)拆分為訓(xùn)練集、驗(yàn)證集和測(cè)試集。
下一步是訓(xùn)練階段所必需的。通常,整個(gè)樣本數(shù)據(jù)集已重新打亂次序,隨后拆分為三個(gè)集:訓(xùn)練集、驗(yàn)證集和測(cè)試集。
如果您已將數(shù)據(jù)集組織為數(shù)據(jù)張量和標(biāo)簽張量,那么您可使用 2 次“sklearn.model_selection.train_test_split”。
首先,將其拆分為“訓(xùn)練”和“測(cè)試”,然后再將“訓(xùn)練”拆分為“驗(yàn)證”和“訓(xùn)練”。
結(jié)果如下所示:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1)
但我們想把數(shù)據(jù)集保留為對(duì)象,而 PyTorch 則可幫助我們簡(jiǎn)化這一操作。
例如,我們僅創(chuàng)建“訓(xùn)練和驗(yàn)證”集。
方法 1:
此處,我們對(duì)索引進(jìn)行打亂次序,然后創(chuàng)建數(shù)據(jù)集
輸入 [ ]:
n_samples = len(mydataset)
# 驗(yàn)證集中將包含多少樣本
n_val = int(0.2 * n_samples)
# 重要!對(duì)數(shù)據(jù)集進(jìn)行打亂次序。首先對(duì)索引進(jìn)行打亂次序。
shuffled_indices = torch.randperm(n_samples)
# 第一步是拆分索引
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
train_indices, val_indices
輸入 [ ]:
from torch.utils.data.sampler import SubsetRandomSampler
batch_size = 64
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(val_indices)
train_loader = torch.utils.data.DataLoader(mydataset, batch_size=batch_size, sampler=train_sampler)
validation_loader = torch.utils.data.DataLoader(mydataset, batch_size=batch_size, sampler=valid_sampler)
方法 2
以下是直接對(duì)數(shù)據(jù)庫(kù)進(jìn)行打亂次序的示例。代碼風(fēng)格更抽象:
輸入 [116]:
train_size = int(0.9 * len(mydataset))
valid_size = int(0.1 * len(mydataset))
train_dataset, valid_dataset = torch.utils.data.random_split(mydataset, [train_size, valid_size])
# 如需“測(cè)試”數(shù)據(jù)集,則請(qǐng)取消注釋
#test_size = valid_size
#train_size = train_size - test_size
#train_dataset, test_dataset = torch.utils.data.random_split(train_dataset, [train_size, test_size])
len(mydataset), len(train_dataset), len(valid_dataset)
輸出 [116]:
(25000, 22500, 2500)
模型定義
輸入 [41]:
import torch.nn as nn
import torch.nn.functional as F
n_out = 2
輸入 [ ]:
# NN 極小
# 期望的精確度為 0.66
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding = 1)
self.conv2 = nn.Conv2d(16, 8, kernel_size=3, padding = 1)
self.fc1 = nn.Linear(8*16*16, 32)
self.fc2 = nn.Linear(32, 2)
def forward(self, x):
out = F.max_pool2d(torch.tanh(self.conv1(x)), 2)
out = F.max_pool2d(torch.tanh(self.conv2(out)), 2)
#print(out.shape)
out = out.view(-1,8*16*16)
out = torch.tanh(self.fc1(out))
out = self.fc2(out)
return out
輸入 [131]:
# 模型更深 - 但訓(xùn)練時(shí)間在我的 CPU 上開始變得有些難以承受
class ResBlock(nn.Module):
def __init__(self, n_chans):
super(ResBlock, self).__init__()
self.conv = nn.Conv2d(n_chans, n_chans, kernel_size=3, padding=1)
self.batch_norm = nn.BatchNorm2d(num_features=n_chans)
def forward(self, x):
out = self.conv(x)
out = self.batch_norm(out)
out = torch.relu(out)
return out + x
輸入 [177]:
class Net(nn.Module):
def __init__(self, n_chans1=32, n_blocks=10):
super(Net, self).__init__()
self.n_chans1 = n_chans1
self.conv1 = nn.Conv2d(3, n_chans1, kernel_size=3, padding=1)
self.conv3 = nn.Conv2d(n_chans1, n_chans1, kernel_size=3, padding=1)
self.resblocks = nn.Sequential(* [ResBlock(n_chans=n_chans1)] * n_blocks)
self.fc1 = nn.Linear(n_chans1 * 8 * 8, 32)
self.fc2 = nn.Linear(32, 2)
def forward(self, x):
out = F.max_pool2d(torch.relu(self.conv1(x)), 2)
out = self.resblocks(out)
out = F.max_pool2d(torch.relu(self.conv3(out)), 2)
out = F.max_pool2d(torch.relu(self.conv3(out)), 2)
out = out.view(-1, self.n_chans1 * 8 * 8)
out = torch.relu(self.fc1(out))
out = self.fc2(out)
return out
model = Net(n_chans1=32, n_blocks=5)
讓我們來(lái)顯示模型大小:
輸入 [178]:
model = Net()
numel_list = [p.numel() for p in model.parameters() if p.requires_grad == True]
sum(numel_list), numel_list
輸出 [178]:
(85090, [864, 32, 9216, 32, 9216, 32, 32, 32, 65536, 32, 64, 2])
簡(jiǎn)單且聰明的竅門來(lái)檢查圖片 shape 的不匹配和錯(cuò)誤:訓(xùn)練模型前先執(zhí)行正向運(yùn)行來(lái)進(jìn)行檢查:
輸入 [180]:
model(mydataset[0][0].unsqueeze(0))
# 需要解壓縮才能添加維度并對(duì)批次進(jìn)行仿真
輸出 [180]:
tensor([[0.7951, 0.6417]], grad_fn=)
成功了!
模型訓(xùn)練
雖然這并非本文的目標(biāo),但既然有了模型,何不試試訓(xùn)練一下,更何況 Pytorch 還免費(fèi)提供了 DataLoader。
DataLoader 的任務(wù)是通過(guò)靈活的采樣策略對(duì)來(lái)自數(shù)據(jù)集的 mini-batch 進(jìn)行采樣。將自動(dòng)把數(shù)據(jù)集打亂,然后再加載 mini-batch。如需獲取參考信息,請(qǐng)?jiān)L問 https://pytorch.org/docs/stable/data.html
輸入 [181]:
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
print("Training on device {}.".format(device))
Training on device cpu.
輸入 [182]:
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=64, shuffle=False) # 注:此處無(wú)需亂序
輸入 [183]:
def training_loop(n_epochs, optimizer, model, loss_fn, train_loader):
for epoch in range(1, n_epochs + 1):
loss_train = 0.0
for imgs, labels in train_loader:
outputs = model(imgs)
loss = loss_fn(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_train += loss.item()
if epoch == 1 or epoch % 5 == 0:
print('{} Epoch {}, Training loss {}'.format(
datetime.datetime.now(), epoch, float(loss_train)))
輸入 [184]:
model = Net()
# 預(yù)訓(xùn)練的模型 models_data_path = './raw_data/models' model.load_state_dict(torch.load(models_data_path + '/cats_dogs.pt'))
輸入 [185]:
optimizer = optim.SGD(model.parameters(), lr=1e-2)
loss_fn = nn.CrossEntropyLoss()
training_loop(
n_epochs = 20,
optimizer = optimizer,
model = model,
loss_fn = loss_fn,
train_loader = train_loader,
)
2020-09-15 19:33:03.105620 Epoch 1, Training loss 224.0338312983513
2020-09-15 20:01:35.993491 Epoch 5, Training loss 153.11289536952972
2020-09-15 20:36:51.486071 Epoch 10, Training loss 113.09166505932808
2020-09-15 21:11:37.375586 Epoch 15, Training loss 85.17814277857542
2020-09-15 21:46:05.792975 Epoch 20, Training loss 59.60428727790713
輸入 [189]:
for loader in [train_loader, valid_loader]:
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in loader:
outputs = model(imgs)
_, predicted = torch.max(outputs, dim=1)
total += labels.shape[0]
correct += int((predicted == labels).sum())
print("Accuracy: %f" % (correct / total))
Accuracy: 0.956756
Accuracy: 0.830800
性能一般,但目的只是為了測(cè)試組織為 Python 對(duì)象的數(shù)據(jù)集是否有效,并測(cè)試我們能否訓(xùn)練一般模型。
此外還需要注意,為了能夠以我的 CPU 來(lái)加速訓(xùn)練,所有圖像都降采樣到 64x64。
輸入 [187]:
models_data_path = './raw_data/models'
torch.save(model.state_dict(), models_data_path + '/cats_dogs.pt')
輸入 [ ]:
# 如需加載先前保存的模型
model = Net()
model.load_state_dict(torch.load(models_data_path + 'cats_dogs.pt'))
附錄
認(rèn)識(shí) DIM
理解 pytorch sum 或 mean 中的“dim”的方法是,它會(huì)折疊所指定的維度。因此,當(dāng)它折疊維度 0(行),它會(huì)變?yōu)閮H 1 行(它在整列范圍內(nèi)進(jìn)行操作)。
輸入 [ ]:
a = torch.randn(2, 3)
a
輸入 [ ]:
torch.mean(a)
輸入 [ ]:
torch.mean(a, dim=0) # now collapsing rows, only one row will result
輸入 [ ]:
torch.mean(a, dim=1) # now collapsing columns, only one column will remain
審核編輯 黃昊宇













 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論