 電子發(fā)燒友App
電子發(fā)燒友App


所謂報文內(nèi)容過濾,顧名思義是對IP包數(shù)據(jù)段的載荷進行過濾,過濾規(guī)則是字符串形式的數(shù)據(jù)內(nèi)容。以IDS系統(tǒng)為例,管理員根據(jù)所掌握的入侵情況事先為系統(tǒng)設(shè)定入侵規(guī)則,這些規(guī)則的一個重要組成部分就是IP數(shù)據(jù)載荷的某些內(nèi)容,具體表現(xiàn)為字符串。當系統(tǒng)接收到一個IP包后,IDS的內(nèi)容過濾部分就會用自身的系統(tǒng)算法將規(guī)則庫中的字符串逐一和包的內(nèi)容匹配,一旦匹配了某個字符串,則證明匹配了相應(yīng)的規(guī)則。
隨著網(wǎng)絡(luò)信息復雜化以及安全需求多樣化,對報文內(nèi)容過濾的需求也更加迫切。首先從安全角度來看,防火墻和入侵監(jiān)測系統(tǒng)急需高效率的報文內(nèi)容過濾算法。由于當今的入侵行為和攻擊方式更具有復雜性,主要表現(xiàn)在數(shù)據(jù)載荷的內(nèi)容中出現(xiàn)特征字符串,例如蠕蟲病毒“Nimda”、“Code Red”、“Slammer”都包含特殊的字符串;從網(wǎng)絡(luò)應(yīng)用來看,應(yīng)用于深度報文分類的路由設(shè)備、流量控制等同樣需要獲得并且對IP數(shù)據(jù)內(nèi)容分類,例如一些多媒體數(shù)據(jù)、P2P數(shù)據(jù)都含有特定的字符串信息作為本身的標識;另外從信息獲取的角度來看,技偵領(lǐng)域和數(shù)據(jù)挖掘如何從海量數(shù)據(jù)中發(fā)掘有用信息和情報資源,同樣需要內(nèi)容過濾。
1、內(nèi)容過濾的代表算法
1.1 AC算法
AC算法即由Aho和Corasick提出的多模式匹配算法(即一次搜索查找可以判定多個字符串匹配問題)。簡單地說,AC 算法使用了有限自動機的結(jié)構(gòu)來接收并存儲規(guī)則庫中所有的字符串。自動機是結(jié)構(gòu)化的,這樣每個前綴都可用唯一的狀態(tài)來標識,甚至是那些多個模式的前綴,這樣復雜的前綴就可以簡單的轉(zhuǎn)化為狀態(tài)機中的一個狀態(tài)。當文本T中下一個字符不是模式中預期的下個字符中的一個時,會有一條失敗鏈指向那個狀態(tài),代表最長的模式前綴,同時也是當前狀態(tài)的相應(yīng)后綴。在實踐中,我們設(shè)定三個函數(shù):狀態(tài)轉(zhuǎn)移函數(shù)goto()、成功匹配輸出函數(shù)output()、匹配失敗跳轉(zhuǎn)函數(shù)failure()。
1.2 王的多模式匹配算法
王永成教授等人設(shè)計了更多關(guān)注了多模式匹配過程中字串之間的相互關(guān)系,對AC算法進行了改進0。算法在自動狀態(tài)機思想的基礎(chǔ)上,應(yīng)用了BM算法0的跳轉(zhuǎn)思想,即利用了匹配過程中匹配失敗的信息,跳過盡可能多的字符。實現(xiàn)了快速的多模式匹配算法。在匹配的過程中,同樣使用goto()函數(shù)轉(zhuǎn)移當前狀態(tài),在找到匹配結(jié)果之后output()函數(shù)輸出成功信息。而在匹配失敗的時候,使用skip函數(shù)大幅度劃文本T,減少goto()函數(shù)的調(diào)用次數(shù),從而提高過濾效率。
1.3 Bloom Filter算法
Bloom Filter法最初多用于數(shù)據(jù)庫存儲和查詢結(jié)構(gòu),近年來也應(yīng)用于IP包內(nèi)容過濾等領(lǐng)域。Bloom Filter算法的原理是找到k個hash函數(shù),其值域都是{1,2,…,m}同時設(shè)定一個模式矢量M,其長度為m。對于規(guī)則庫P中的每個模式,計算 hash1(p)、……、hashk(p) ,每次計算所得的 hashx(p)根據(jù)其數(shù)值對應(yīng)到模式矢量的相應(yīng)位置。這樣,一個模式經(jīng)過k個hash函數(shù)計算所得k個值,進而對應(yīng)到模式矢量的k個位置,形成一個模式矢量。在查找的過程中,在文本中取出同p相同長度的字符串,經(jīng)過k個hash函數(shù)計算后生成其相應(yīng)的模式矢量,用這個模式矢量和庫中的各個模式矢量比較,可以確定是否匹配。
1.4 Dharmapurikar的算法
Dharmapurikar 等人修改了基本的AC算法,并引入了Bloom filter,設(shè)計了基于硬件的匹配方案。該算法拓展了AC狀態(tài)機的輸入帶寬,從1byte擴展到Gbyte。相應(yīng)的狀態(tài)機內(nèi)部對一個狀態(tài)變化也要判斷一組Gbyte的數(shù)據(jù)。而對于文本T尾部不足Gbyte的部分,采用并行的G-1個過濾單元,專用于過濾剩余長度為1、2、……、G-1的部分。而在狀態(tài)轉(zhuǎn)移的過程中,使用了Bloom Filter過濾掉了不可能產(chǎn)生狀態(tài)轉(zhuǎn)移的輸入,極大地提高了匹配效率。而對于數(shù)量很少的狀態(tài)轉(zhuǎn)移操作,通過查找off-chip的存儲單元中的hash表來確定狀態(tài)轉(zhuǎn)移和相應(yīng)的匹配結(jié)果。本文在此基礎(chǔ)上作進一步研究。
2、內(nèi)容過濾算法描述
2.1 算法的并行結(jié)構(gòu)
對于字符串匹配而言,一個匹配單元是1-byte,這樣一個匹配模塊一次的輸入為1byte。如果可以將輸入帶寬從1-byte拓展到G-byte的話那么過濾速率顯然也相應(yīng)的提高了G倍。
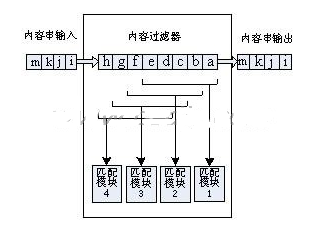
圖1 一個G=4的內(nèi)容過濾器
圖1以一個G=4的實例說明了并行內(nèi)容過濾器的算法結(jié)構(gòu)。過濾器由四個完全相同的過濾模塊并行組成,其中每個模塊一次接收一定長度(B)的字串,進行過濾計算,下個周期接收下一組B長的字串。而對于整個過濾器而言,每個周期流入Gbyte的數(shù)據(jù),流出Gbyte的數(shù)據(jù)。以過濾模塊1為例,當前窗口接收串為“abcde”,下一個周期窗口內(nèi)的串為“efghi”。雖然對于每個模塊而言,每次會改變G=4個字節(jié),但是因為存在了并行的4個模塊,且每個模塊的判斷窗口都間隔1byte,這樣就不會漏掉數(shù)據(jù)流中的任何一個位置。如果規(guī)則集中含有字符串“cdefg”的話,那么顯然模塊3對當前窗口過濾之后會給出一個匹配結(jié)果,而其他三個模塊都不會有匹配結(jié)果產(chǎn)生。這樣的并行結(jié)構(gòu)通過使用處理位置上相互比鄰的G個匹配模塊,解決了自動狀態(tài)機模型中對于輸入字串1byte的限制,展寬了過濾帶寬,進而提高了過濾速率。
2.2 匹配模塊的內(nèi)部結(jié)構(gòu)
圖1中的一個匹配模塊是一個獨立的內(nèi)容過濾單元,也是一個獨立的狀態(tài)機轉(zhuǎn)換單元。其內(nèi)部根據(jù)輸入的G-byte的字串計算狀態(tài)轉(zhuǎn)移以及匹配的命中結(jié)果。下面介紹一個匹配模塊的原理結(jié)構(gòu)。
圖2所示的是一個4byte寬的狀態(tài)機模型,狀態(tài)的每次轉(zhuǎn)移都需要4byte的數(shù)據(jù)(≤4)。例如,判斷S6=“elephant”,在當前狀態(tài)q0的情況下,輸入串為“elep”時,狀態(tài)轉(zhuǎn)移q0—〉q4,接著輸入“hant”,狀態(tài)轉(zhuǎn)移到q7,此時有匹配的結(jié)果輸出。而普通的狀態(tài)機,需要8次的狀態(tài)轉(zhuǎn)移。
在過濾的過程中更多的規(guī)則串并不是B的倍數(shù),例如“phone”,在第一次狀態(tài)轉(zhuǎn)移中由于“phon”的存在由q0轉(zhuǎn)移到q3,此后至需要判斷下個輸入中是不是后綴“e***”就可以判斷是否命中了s5,同樣還有“technically”中的后綴“l(fā)ly”等。對長度為1到B-1之間的后綴,采用并行的B-1個后綴判斷子模塊。同時注意到對于長度恰好是B的整數(shù)倍的規(guī)則串,可以理解成有一個長度為0的后綴,這樣便于同上述并行的B-1個后綴判斷子模塊一同組成B個并行的運算結(jié)構(gòu)。圖3給出了一個B=4的情況下的一個匹配模塊的結(jié)構(gòu),其中4個Bloom Filter分別處理后綴長度為0、1、2、3的情況。然后通過查表得到狀態(tài)轉(zhuǎn)移關(guān)系以及結(jié)果輸出情況。

圖2 一個4byte寬(B=4)的狀態(tài)機
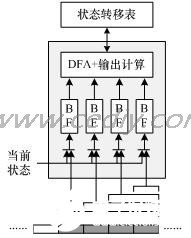
圖3 B=4情況下的一個匹配模塊
2.3 使用Bloom Filter
如前文所述,由于狀態(tài)轉(zhuǎn)移表占用很大的存儲空間,需要使用off-chip的RAM來保存。而通常情況下外部存儲器的讀取帶寬很小,不能支持一個模塊的B個查表要求。其實在真實情況中只有很少的情況下才會有狀態(tài)的轉(zhuǎn)換,這時使用Bloom Filter來濾掉大量的不會產(chǎn)生狀態(tài)變化的輸入。一個狀態(tài)轉(zhuǎn)移關(guān)系可以表示成:
《當前狀態(tài),輸入字串》 ==〉《下個狀態(tài),輸出信息》
所以可以對2元組《當前狀態(tài),輸入字串》進行hash運算,用結(jié)果搜索狀態(tài)轉(zhuǎn)移hash表,找到2元組《下個狀態(tài),輸出信息》。Bloom Filter的作用就是濾掉大量不會查找到結(jié)果的元組,只在當前《當前狀態(tài),輸入字串》有可能在hash表中查到結(jié)果的時候才允許對應(yīng)項查找狀態(tài)轉(zhuǎn)移表。這樣極大地減少了查表次數(shù),提高了算法速率。
2.4 Hash函數(shù)的硬件實現(xiàn)方法
對于Bloom Filter中使用的hash函數(shù),要求易于硬件,占用盡可能少的時鐘周期。H3算法提供了一個很好的解決方案。設(shè)子串的第i個字節(jié)為《bi1、bi2、……、bi8》,則這個位置上的一個hash值為:
hi=di1?bi1⊕di2?bi2⊕……⊕di8?bi8
其中dij是一個預設(shè)的隨機矩陣的一個值。這樣,從1到i的hash值為:
Hi=Hi-1⊕hi
可見,位置i上的hash函數(shù)可以通過i-1位置上的hash函數(shù)簡單的算出。并且如果dij=di+1j的話,可見t時刻的hi和t+1時刻的hi-1是相同的,這樣所有Hi就可以通過并行的移位結(jié)構(gòu)在一個時鐘周期內(nèi)完成,而不用等待Hi-1的計算結(jié)果。相應(yīng)的結(jié)構(gòu)如圖4所示,算法可以在一個時鐘周期內(nèi)算出所有Hi的值,非常便捷。
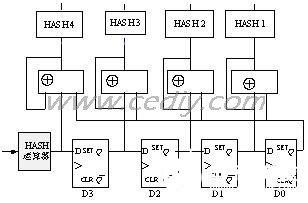
圖4 硬件Hash函數(shù)的邏輯結(jié)構(gòu)
3、FPGA實現(xiàn)
本文的實驗系統(tǒng)使用的是Altera公司StratixII系列的EP2S60FPGA芯片。該芯片擁有2.5Mb的片內(nèi)RAM空間,可以支持最多兩個獨立off-chip的DDR或QDR單元。輸入信號是經(jīng)過前端處理的POS信號,解為整載的IP報文數(shù)據(jù)。規(guī)則隨機地取自IDS系統(tǒng)SNORT的2000條規(guī)則。
在實現(xiàn)的過程中使用8個并行的過濾模塊,也就是每次輸入8byte的數(shù)據(jù)。雖然更高的并行數(shù)量會提高系統(tǒng)的處理帶寬,但是也相應(yīng)需要占用更多的RAM空間,這里考慮到SNORT的規(guī)則相對較短(多分布在5-15byte),采用8byte并行的算法。Bloom Filter由6個并行的hash函數(shù)構(gòu)成,每個hash函數(shù)對應(yīng)的hash表采用2kbit,這樣一共占用了2kbit*6*8*8=768kbit的片內(nèi)RAM資源,約占總量的30%。經(jīng)過計算,這樣的Bloom Filter設(shè)計可以保證經(jīng)過過濾操作之后,只有6e-10的假匹配存在(即對應(yīng)的hash值表明當前元組《當前狀態(tài),輸入字串》可以產(chǎn)生正確的狀態(tài)轉(zhuǎn)移,然而在off-chip的RAM中找不到對應(yīng)項)。這里需要提一下,由于8個并行模塊是同構(gòu)的,其hash表也是相同的,如果使用時分的hash表查找方法或者Lucent memory core可以占用更少的RAM資源。
當實驗系統(tǒng)FPGA工作在77MHz的情況下的時候,可以正確無誤的過濾2.5Gpbs的IP報文數(shù)據(jù)。由于該算法使用的RAM和時鐘頻率都沒有達到額定值,同時,內(nèi)部Bloom Filter和狀態(tài)轉(zhuǎn)移表的構(gòu)成同樣有待進一步優(yōu)化,所以本文算法具有進一步升級的潛力。
4、結(jié)論
本文針對目前網(wǎng)絡(luò)傳播速率急劇增加,數(shù)據(jù)處理規(guī)則規(guī)模龐大的特點,提出了基于FPGA的IP報文內(nèi)容過濾算法。本文在當前多種優(yōu)秀的內(nèi)容過濾技術(shù)的基礎(chǔ)上,充分利用了FPGA芯片高速并行處理和流水線操作的特點,提出使用并行的移位模塊來拓展過濾算法的處理帶寬,使得算法支持的IP報文速率得到了很大的提高。同時,為解決off-chip的RAM讀取帶寬受限的瓶頸,以及在狀態(tài)轉(zhuǎn)移過程中讀取下一個狀態(tài)需要占用額外的時鐘周期的問題,提出了用Bloom Filter過濾掉不會產(chǎn)生狀態(tài)轉(zhuǎn)移的輸入字串,進一步提高處理速率。另外,設(shè)計了僅需要一個時鐘周期就可以完成hash計算的硬件電路,并且通過改進,可以在一個時鐘周期內(nèi)得到所有后綴長度的hash值,使得算法在FPGA中的流水性能增強。最后通過在實驗系統(tǒng)中的測試,在77MHz的時鐘下可以正確的過濾2.5Gbps的IP報文,并且有進一步升級的潛力。
責任編輯:gt














 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論